
本篇为Flink的第一大部分,初识Flink,全篇参考自 尚硅谷2022版1.13系列
整个系列的目录如下:
<一>Flink简介
<二>Flink快速上手
<三>Flink 部署
<四>Flink 运行时架构
<五>DataStream API
<六>Flink 中的时间和窗口
<七>处理函数
<八>多流转换
<九>状态编程
<十>容错机制
<十一>Table API 和 SQL
<十二>Flink CEP
本文章会着重记录比较重要知识点和架构,略过不重要信息和一些代码等,需要全文可以到b站观看,顺便投俩币。
<一>Flink简介
知识点一. Flink是什么
Flink 是 Apache 基金会旗下的一个开源大数据处理框架,同时是分布式处理引擎,用于对无界和 有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和 任意规模来执行计算。 Flink 做到了精确一次(exactly-once)的一致性保障,是第一个具有一致性和准确结果的开源流 处理器。
知识点二. Flink的特点
(1)高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
(2)结果的准确性。Flink 提供了事件时间(event-time)和处理时间(processing-time) 语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
(3)精确一次(exactly-once)的状态一致性保证。
(4)可以连接到最常用的存储系统,如 Apache Kafka, HDFS 和 S3等。
(5)高可用本身高可用的设置,加上与 K8s,YARN 和 Mesos 的紧密集成,再加上从故 障中快速恢复和动态扩展任务的能力,Flink 能做到以极少的停机时间 7×24 全天候 运行。
(6)能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用 程序的状态。
知识点三. 什么叫有状态计算
参考知识点八
知识点四. 什么是无界和有界数据流
无界数据流,就是有头没尾,数据的生成和传递会开始但永远不会结束,数据没有“都到达”的 时候,对于无界数据流必须在获取数据后立即处理。另外,为了保证结果的正确性,我们必须能够做到按照顺序处理数据。
有界数据流有明确定义的开始和结束,所以我们可以通过获取 所有数据来处理有界流,有界流的处理也就是批处理。
知识点五. Flink 的主要应用场景
Flink是一个大数据流式处理引擎,处理的是流式数据,数据像水流一样, 是一组有序的数据序列,逐个到来、逐个处理。由于数据来到之后就会被即刻处理,所以流处 理的一大特点就是“快速”,也就是良好的实时性。Flink 适合的场景,其实也就是需要实时处 理数据流的场景。
具体来看,一些行业中的典型应用有:
(1). 电商和市场营销: 实时数据报表、广告投放、实时推荐
(2). 物联网(IOT): 传感器实时数据采集和显示、实时报警,交通运输业
(3). 物流配送和服务业: 订单状态实时更新、通知信息推送
(4). 银行和金融业: 实时结算和通知推送,实时检测异常行为
知识点六. 流处理和批处理的区别
流处理,数据是一个一个来的,一组有序的数据序列,处理方法为来一个就处理一个,是即时的,也叫实时处理。
批处理,与之对应,处理批量数据自然就应该一批读入、一起计算,这种方式就叫作批处理,也叫作离线处理。
流处理,是真正的即 时处理,没有“攒批”的等待时间,所以会更快、实时性更好,但同时流处理也会更加消耗内存资源。批处理,数据处理不够及时,实时性变差了。
知识点七. 事务处理架构

(1)接收的数据是持续生成的事件,比如用户的点击行为,客户下的订单
(2)处理事件时,应用程序 需要先读取远程数据库的状态,然后按照处理逻辑得到结果
(3)将响应返回给用户,并更新数据 库状态。
(4)总体上,计算层 和存储层分开
(5)传统的事务处理,系统所处理的连续不断的事件,其实就是一个数据流。 而对于每一个事件,系统都在收到之后进行相应的处理,这也是符合流处理的原则的,就是最基本的流处理架构
知识点八. 有状态的流处理及其典型应用
把需要的额外数据保存成一个“状态”,然后针对这 条数据进行处理,并且更新状态。在传统架构中,这个状态就是保存在数据库里的。这就是所 谓的“有状态的流处理”,为了加快访问速度,我们可以直接将状态保存在本地内存。
当应用收到一 个新事件时,它可以从状态中读取数据,也可以更新状态。因为在大数据场景下,采用的是一个分布式系统,所以还需要保护本地状态,防止在故障时数据丢失。我们 可以定期地将应用状态的一致性检查点(checkpoint)存盘,写入远程的持久化存储,遇到故 障时再去读取进行恢复,这样就保证了更好的容错性。

几种典型应用:
(1)事件驱动型(Event-Driven)应用
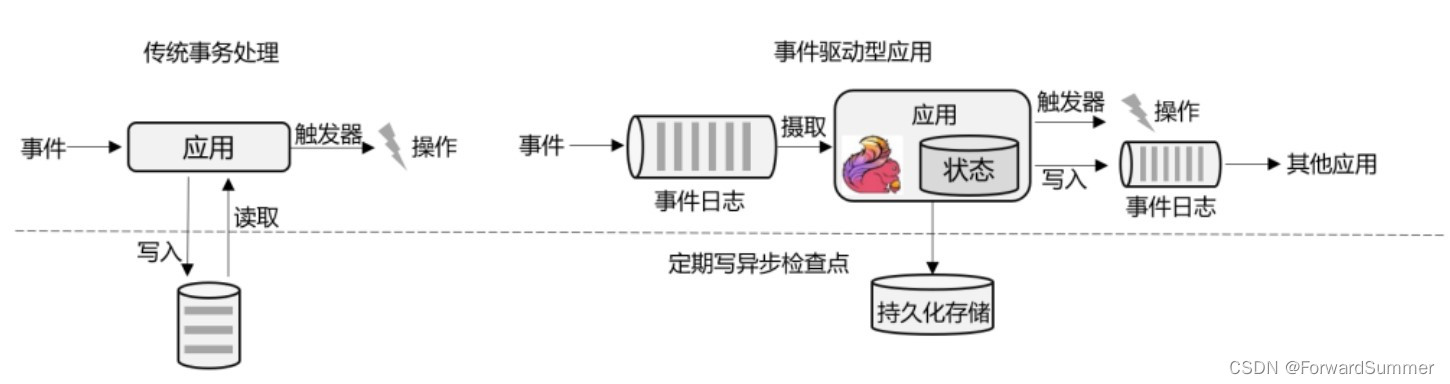
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的 事件触发计算、状态更新或其他外部动作。比较典型的就是以 Kafka 为代表的消息队列几乎都 是事件驱动型应用。这其实跟传统事务处理本质上是一样的,区别在于基于有状态流处理的事件驱动应用,不 再需要查询远程数据库,而是在本地访问它们的数据,这样在吞吐量和延迟方 面就可以有更好的性能。
(2)数据分析(Data Analysis)型应用
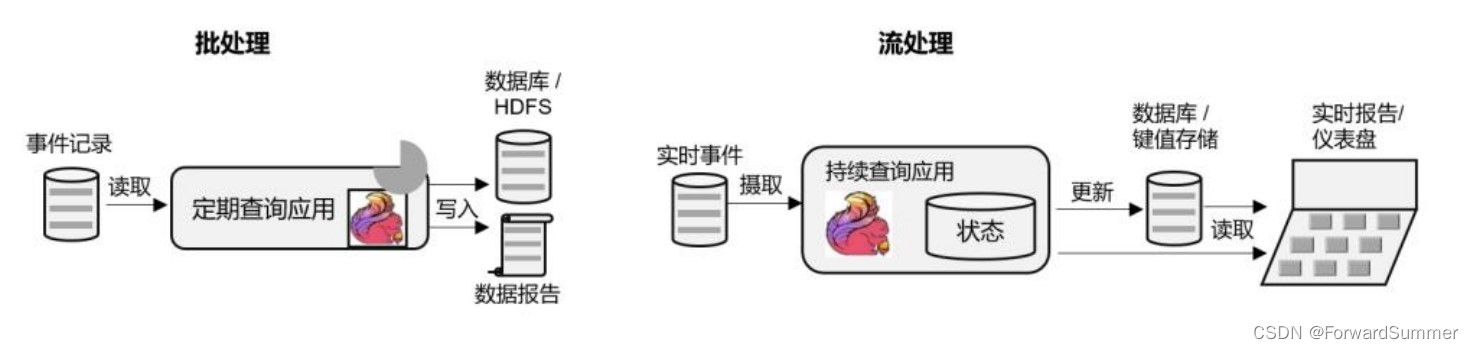
数据分析,就是从原始数据中提取信息和发掘规律。传统上,数据分析一般是先将 数据复制到数据仓库,然后进行批量查询。如果数据有了更新,必须将最 新数据添加到要分析的数据集中,然后重新运行查询或应用程序。现在的做法一般是将大量数据(如日志文件)写入 Hadoop 的分布式文件系统(HDFS)、 S3 或 HBase 等批量存储数据库,以较低的成本进行大容量存储。然后可以通过 SQL-on-Hadoop 类的引擎查询和处理数据,比如大家熟悉的 Hive。这种处理方式,是典型的批处理,特点是 可以处理海量数据,但实时性较差,所以也叫离线分析。
与批处理分析相比,流处理分析最大的优势就是低延迟,真正实现了实时。另外,流处理 不需要去单独考虑新数据的导入和处理,实时更新本来就是流处理的基本模式。当前企业对流 式数据处理的一个热点应用就是实时数仓,很多公司正是基于 Flink 来实现的。
(3)数据管道(Data Pipeline)型应用
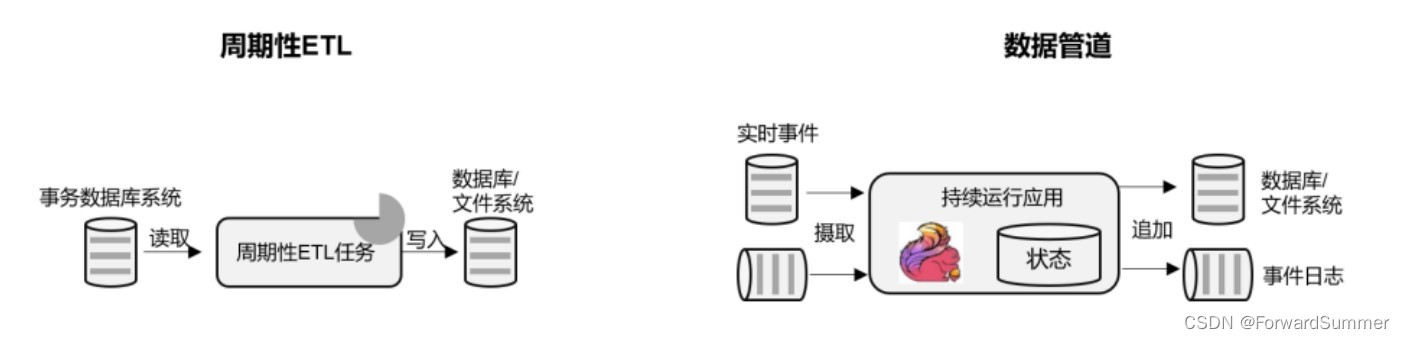
在数据分析的应用中,通常会定期触发 ETL 任务,将数据从事务数据库系统复制到分析数据 库或数据仓库。过如果我们用流处理架构来搭建数据管道,这些工作就可以连续运行,而不需要再 去周期性触发了。比如,数据管道可以用来监控文件系统目录中的新文件,将数据写入事件日 11 志。连续数据管道的明显优势是减少了将数据移动到目的地的延迟,而且更加通用,可以用于 更多的场景。
知识点九. Lambda 架构
以 Storm 为代表的第一代分布式开源流处理器,主要专注于具有毫秒延迟的事件处理,特点就是一个字“快”;而对于准确性和结果的一致性,是不提供内置支持的,因为结果有可能 取决于到达事件的时间和顺序。
另外,第一代流处理器通过检查点来保证容错性,但是故障恢 复的时候,即使事件不会丢失,也有可能被重复处理。与批处理器相比,可以说第一代流处理器牺牲了结果的准确性,用来换取更低的延迟。而 批处理器恰好反过来,牺牲了实时性,换取了结果的准确。
Lambda 架构结合了批处理和流处理的方法,同时提供快速和准确的结果。“批处理层”(Batch Layer)就是由传统 的批处理器和存储组成,而“实时层”(Speed Layer)则由低延迟的流处理器实现。数据到达 之后,两层处理双管齐下,一方面由流处理器进行实时处理,另一方面写入批处理存储空间, 等待批处理器批量计算。流处理器快速计算出一个近似结果,并将它们写入“流处理表”中。 而批处理器会定期处理存储中的数据,将准确的结果写入批处理表,并从快速表中删除不准确 的结果。最终,应用程序会合并快速表和批处理表中的结果,并展示出来。

优点非常明显,就是 兼具了批处理器和第一代流处理器的特点,同时保证了低延迟和结果的准确性。而它的缺点同 样非常明显。首先,Lambda 架构本身就很难建立和维护;而且,它需要我们对一个应用程序, 做出两套语义上等效的逻辑实现,因为批处理和流处理是两套完全独立的系统,它们的 API 也完全不同。为了实现一个应用,付出了双倍的工作量。
知识点十. Spark 和Flink的区别
(1)数据模型不同
Spark 底层数据模型是弹性分布式数据集(RDD),Spark Streaming 进行微批处理的底层 接口 DStream,实际上处理的也是一组组小批数据 RDD 的集合。可以看出,Spark 在设计上本 身就是以批量的数据集作为基准的,更加适合批处理的场景。
Flink 的基本数据模型是数据流(DataFlow),以及事件(Event)序列,以处理流式数 据作为设计目标的,更加适合流处理的场景。
(2)数据处理过程的不同
Spark 做批计算,需 要将任务对应的 DAG 划分阶段(Stage),一个完成后经过 shuffle 再进行下一阶段的计算。
Flink 是标准的流式执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处 理。
(3)适合处理的场景
在海量数据 的批处理领域,Spark 能够处理的吞吐量更大,加上其完善的生态和成熟易用的 API,Spark 基于微批处理的方式做同步总有一个“攒批”的过程,所以会有额外开销,因此无法在 流处理的低延迟上做到极致。
在低延迟流处理场景,Flink 已经有比较明显的优势。
(4)生态不同
Spark 还为批处理(Spark SQL)、流处理(Spark Streaming)、机器学习(Spark MLlib)、图计算(Spark GraphX)提供 了统一的分布式数据处理平台,生态更加成熟。
而 Flink 自 1.9 版本合并 Blink 以来,在 SQL 的表达和批处理的能力上同样有了长足的进步。
知识点十一. Flink分层 API
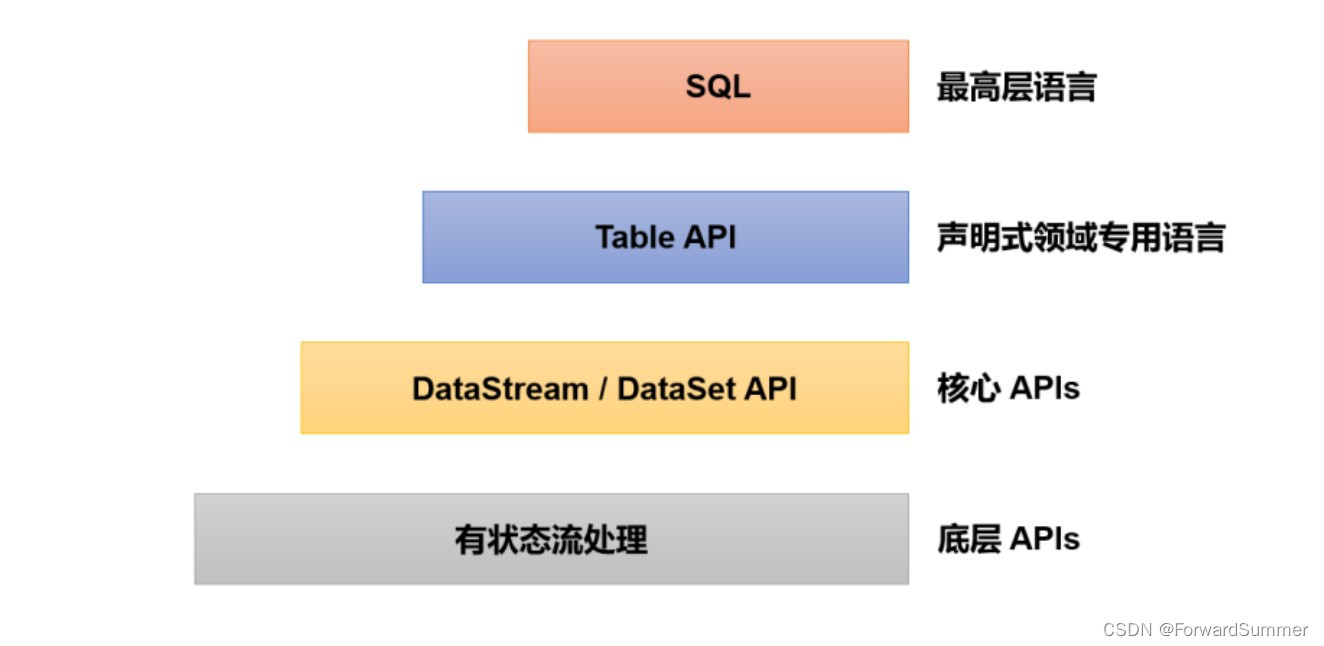
最底层:有状态流,大多数应用并不需要上述的底层抽象,开发额外需求用到。
DataStream API和DataSet API:大多数应用直接针对此层编程,拥有通用的构建模块,例如transformations,joins,aggregations,windows。
Table API:类似于关系数据库中的表,同时提供可比 较的操作,例如 select、join、group-by
SQL:与 Table API 交互密切,同时 SQL 查询 可以直接在 Table API 定义的表上执行。
![[附源码]计算机毕业设计旅游度假村管理系统Springboot程序](https://img-blog.csdnimg.cn/88c036e5de324b3e841780aee091eaba.png)






![[附源码]Python计算机毕业设计SSM家政信息管理平台(程序+LW)](https://img-blog.csdnimg.cn/3ffa0b9491834766934f6a4951f203ef.png)

