Class4:深度学习预训练与MMPretrain
课程链接:深度学习预训练与MMPretrain_哔哩哔哩_bilibili
相关repo:open-mmlab/mmpretrain: OpenMMLab Pre-training Toolbox and Benchmark (github.com)
文章目录
MMpretrain介绍
what?
MMPretrain 是一个全新升级的预训练开源算法框架,旨在提供各种强大的预训练主干网络, 并支持了不同的预训练策略。MMPretrain 源自著名的开源项目 MMClassification 和 MMSelfSup,并开发了许多令人兴奋的新功能。

主要特性
- 支持多样的主干网络与预训练模型
- 支持多种训练策略(有监督学习,无监督学习,多模态学习等)
- 提供多种训练技巧
- 大量的训练配置文件
- 高效率和高可扩展性
- 功能强大的工具箱,有助于模型分析和实验
- 支持多种开箱即用的推理任务
- 图像分类
- 图像描述(Image Caption)
- 视觉问答(Visual Question Answering)
- 视觉定位(Visual Grounding)
- 检索(图搜图,图搜文,文搜图)

数据流
数据流首先是数据,例如图像文件,标注文件等等,通过dataloader对数据进行读取,以及对数据进行增强等操作,接下来从dataloader之后,我们就获得了input和data samples,inputs为torchtensor为图片的张量表达,data sample则是其他相关的信息;在之后我们将所需要的数据送入到模型当中,如果是在训练,则会计算得到loss,然后送入到优化器,最后得到梯度,然后将反向传播,对模型进行更新以及优化;如果是在预测阶段,一般我们会输出预测的结果,然后送到evaluator当中进行matrix的计算,并且输出相关的结果。
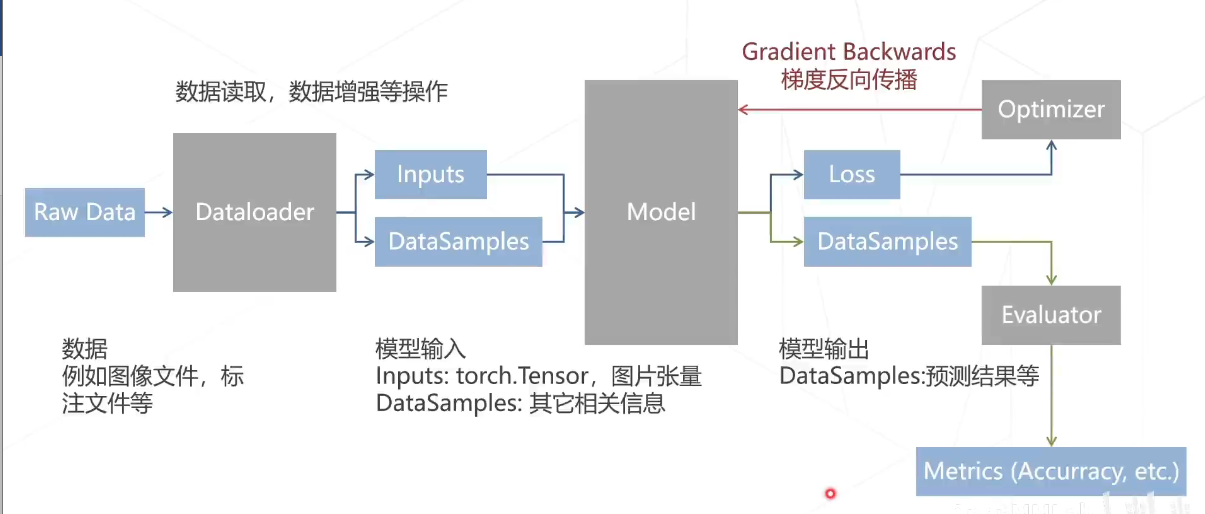
数据加载器与模型之间的数据流
数据加载器 (dataloader) 和模型 (model)之间的数据流一般可以分为如下三个步骤 :
- i) 使用
PackSelfSupInputs将转换完成的数据打包成为一个字典; - ii) 使用
collate_fn将各个张量集成为一个批处理张量; - iii) 数据预处理器把以上所有数据迁移到 GPUS 等目标设备,并在数据加载器中将之前打包的字典解压为一个元组,该元祖包含输入图像与对应的元信息(
SelfSupDataSample)。
经典Backbone
我们可以把模型看作算法的特征提取器或者损失生成器。在 MMpretrain 中,模型主要包括以下几个部分:
- 算法,包括模型的全部模块和构造算法时需要用到的子模块。
- 主干,里面是每个算法的支柱,比如 MAE 中的 VIT 和 SimMIM 中的 Swin Transformer。
- 颈部,指一些特殊的模块,比如解码器,它直接增加脊柱部分的输出结果。
- 头部,指一些特殊的模块,比如多层感知器的层,它增加脊柱部分或者颈部部分的输出结果。
- 记忆,也就是一些算法中的存储体或者队列,比如 MoCo v1/v2。
- 损失,用于算输出的预测值和目标之间的损失。
- 目标生成器,为自监督学习生成优化目标,例如 HOG,其它模块抽取的特征(DALL-E,CLIP)等.
这部分内容已经比较熟了,可参考之前的博客
模型库统计 — MMPretrain 1.0.0rc8 文档
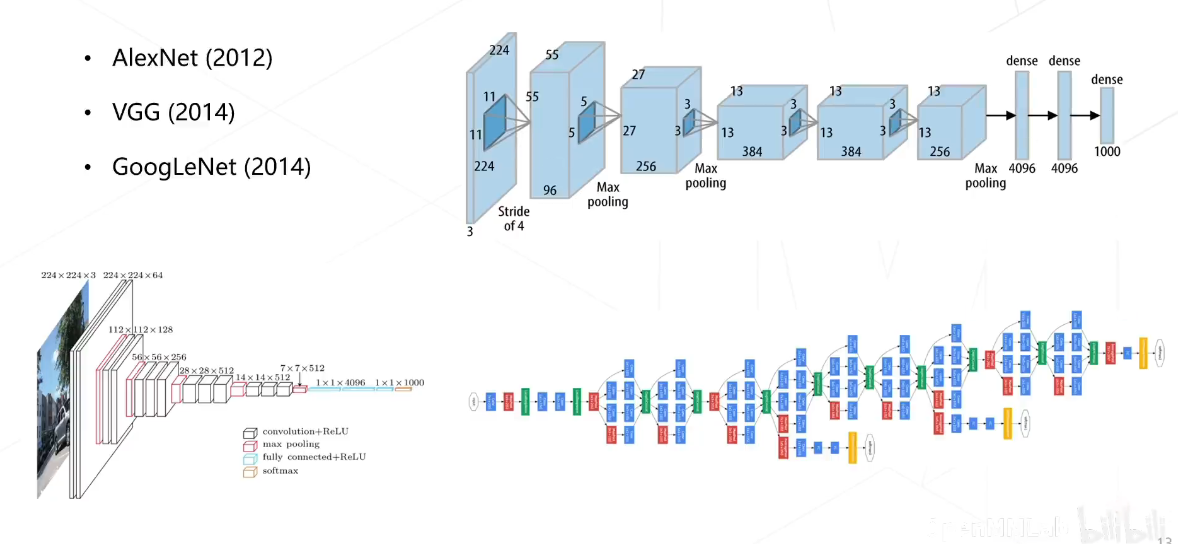
ResNet

VGG
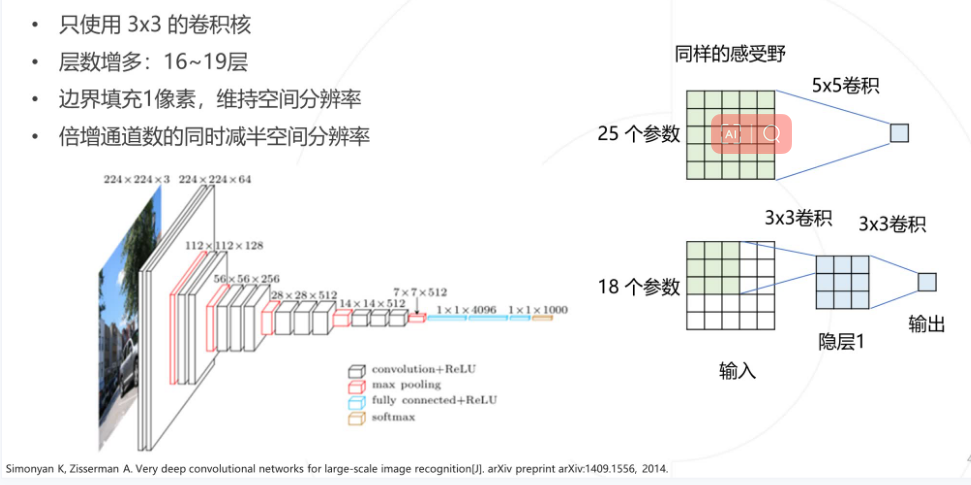
注意力机制
最重要的之一就是注意力机制,注意力机制主要为了对不同的特征进行一个有权重的选取,实现层次化特征,后层特征是空间领域内的前层特征的加权求和,权重越大,则对应位置的特征就越重要。
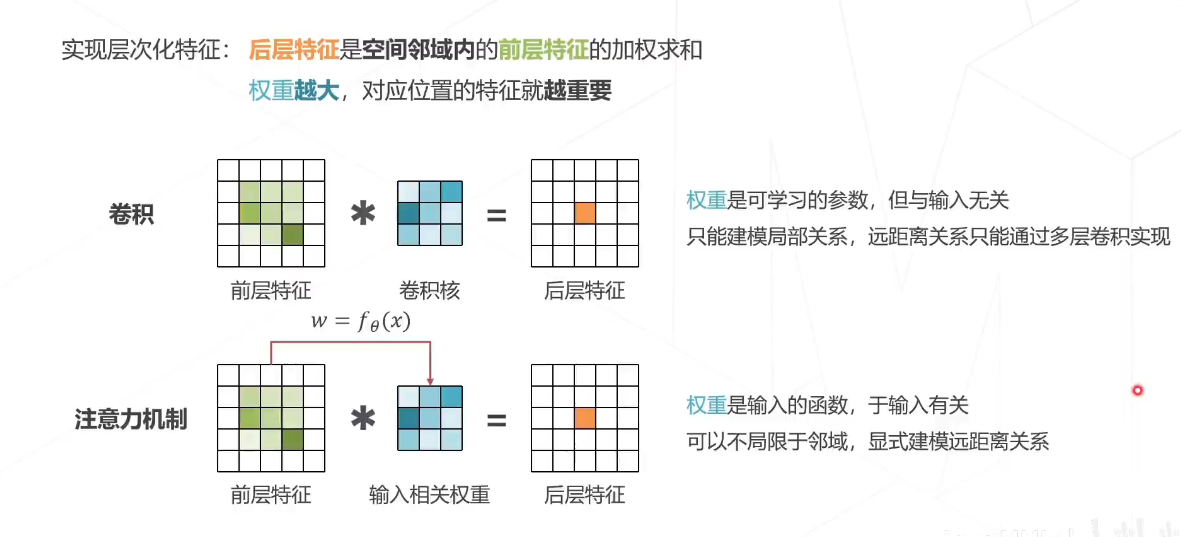
我们可以看到,在原始的卷积中,权重只是一个可学习的参数,与句与输入无关,而且只能进行局部的建模关系,远距离的关系只能通过多层卷积来进行实现,而在注意力机制当中,该权重则是输入的一个函数,与输入有关,可以不局限于领域显示的建模,远距离的关系,不同的图像所产生的权重是不一样的,会和图像的位置相关,而且并不是对所有图像都要使用相同的权重。
自监督学习
自监督学习(Self-supervised learning, SSL)是一种极具潜力的学习范式,它旨在使用海量的无标注数据来进行表征学习。在SSL中,我们通过构造合理的预训练任务(可自动生成标注,即自监督)来进行模型的训练,学习到一个具有强大建模能力的预训练模型。基于自监督学习获得的训练模型,我们可以提升各类下游视觉任务(图像分类,物体检测,语义分割等)的性能。
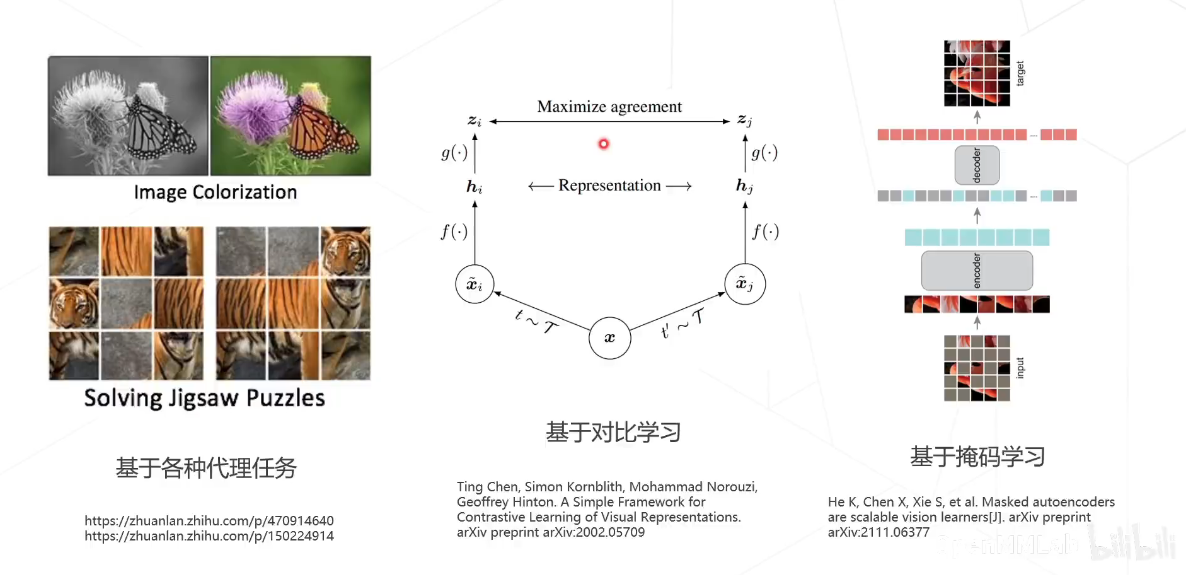
对比学习-SimCLR
简单来说,对比学习的思路就是:一张图片,经过不同的数据增强,被神经网络所提取的特征,仍应具有高度的一致性。
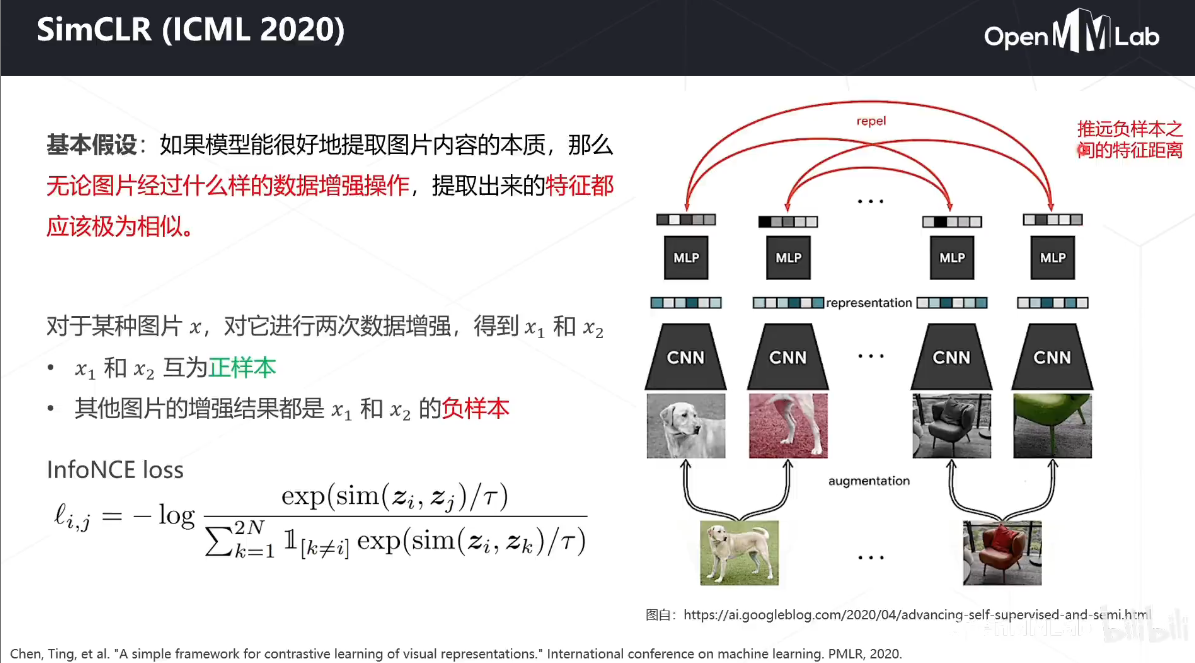
SimCLR 提出四大结论:
- 对比学习中,强大的数据增强至关重要,相比于有监督学习,对比学习从中受益更多
- 在网络学习到的特征和损失函数计算之间,添加可学习的非线性层有助于特征的学习
- 归一化的 embeddings 和合适的 temperature 参数有助于特征表示的学习
- 越大的 batch size 和越久的训练时间有助于对比学习获得更好的结果,另外和监督学习一样,大网络可以取得更好的结果
MIM-MAE
Masked Autoencoders (MAE) 是一篇非常具有影响力的文章。MAE 相比于 BEiT,简化了整体训练逻辑,利用随机掩码处理输入的图像块,以及直接重建掩码图像块来进行训练。MAE 基于两大主要设计:一是采用了非对称结构的编码-解码器,其中编码器只计算非掩码图像块,同时采用了轻量化的解码器设计;二是遮盖大部分的图像块,如掩码概率为 75%,可以获得更加具有意义的自监督训练任务。
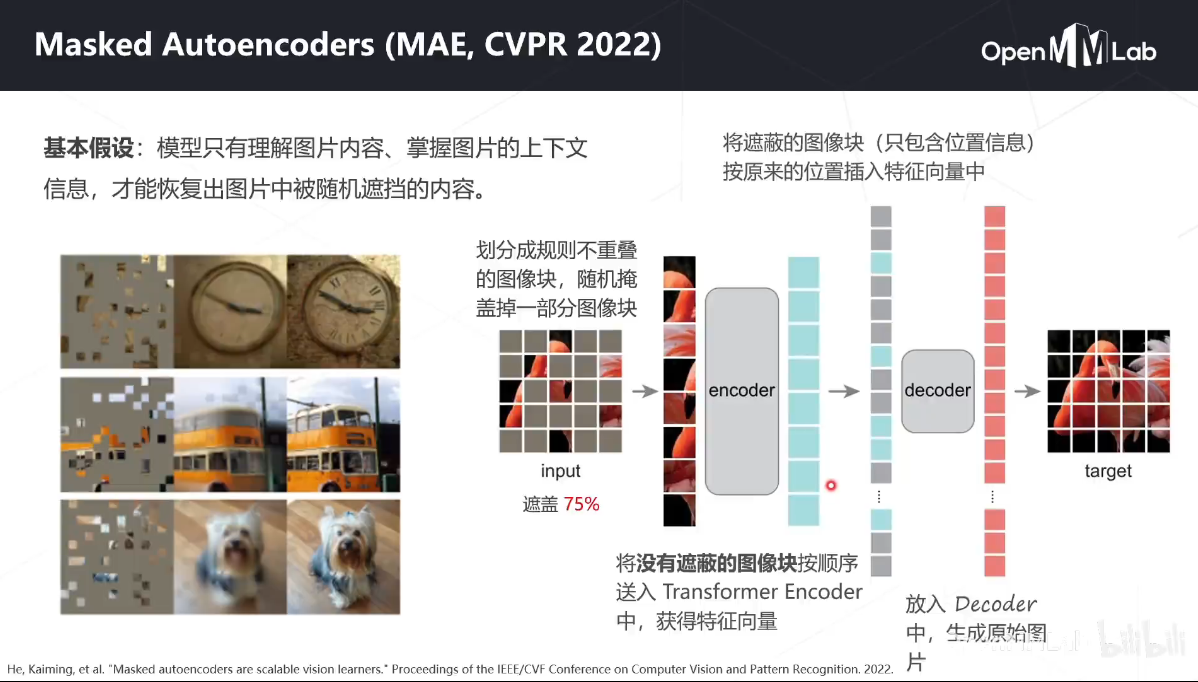
目前已支持的算法
- Relative Location (ICCV’2015)
- Rotation Prediction (ICLR’2018)
- DeepCluster (ECCV’2018)
- NPID (CVPR’2018)
- ODC (CVPR’2020)
- MoCo v1 (CVPR’2020)
- SimCLR (ICML’2020)
- MoCo v2 (arXiv’2020)
- BYOL (NeurIPS’2020)
- SwAV (NeurIPS’2020)
- DenseCL (CVPR’2021)
- SimSiam (CVPR’2021)
- Barlow Twins (ICML’2021)
- MoCo v3 (ICCV’2021)
- BEiT (ICLR’2022)
- MAE (CVPR’2022)
- SimMIM (CVPR’2022)
- MaskFeat (CVPR’2022)
- CAE (arXiv’2022)
- MILAN (arXiv’2022)
- BEiT v2 (arXiv’2022)
- EVA (CVPR’2023)
- MixMIM (ArXiv’2022)
- PixMIM (ArXiv’2023)
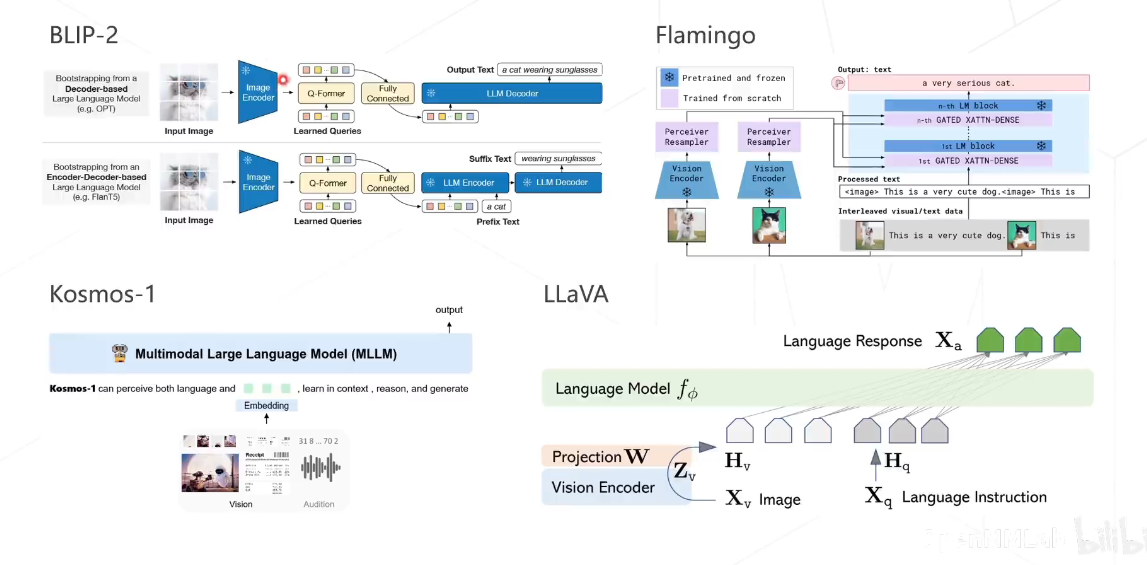
多模态算法
CLIP
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
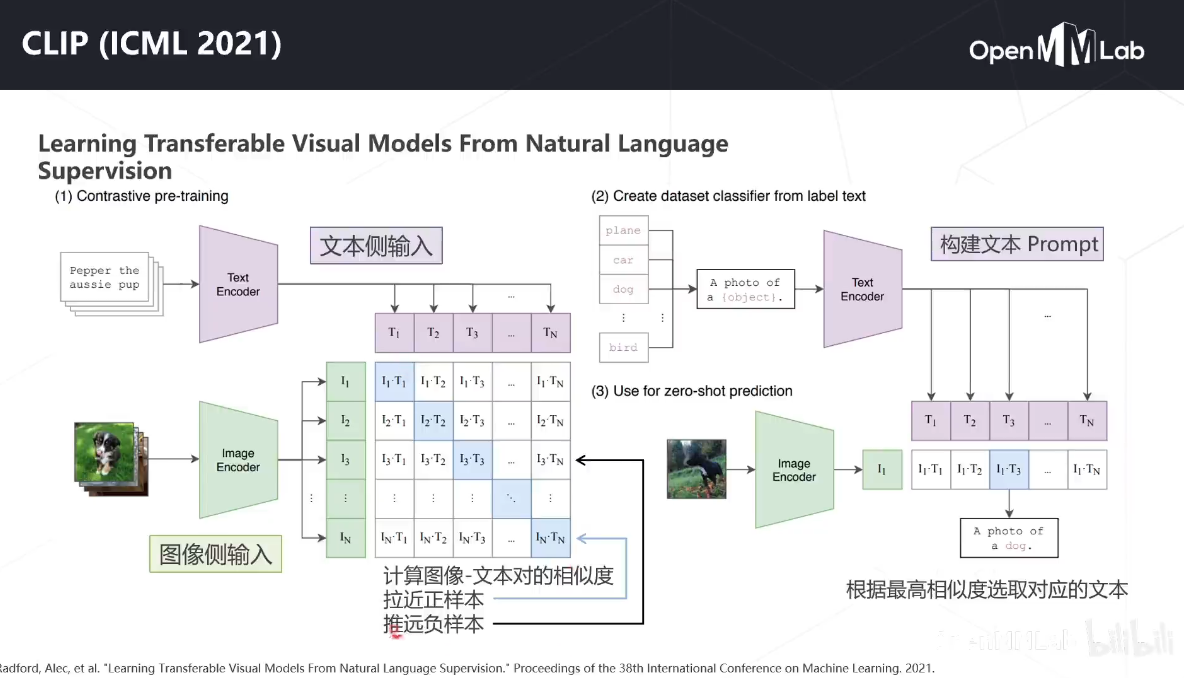
- 在大规模数据集上使用NLP监督预训练图像分类器,证明了简单的预训练任务,即预测图像和文本描述是否相匹配,是一种有效的、可扩展的方法
- 用4亿对来自网络的图文数据对,将文本作为图像标签,进行训练。进行下游任务时,只需要提供和图像对应的文本描述,就可以进行zero-shot transfer,并取得可观的结果
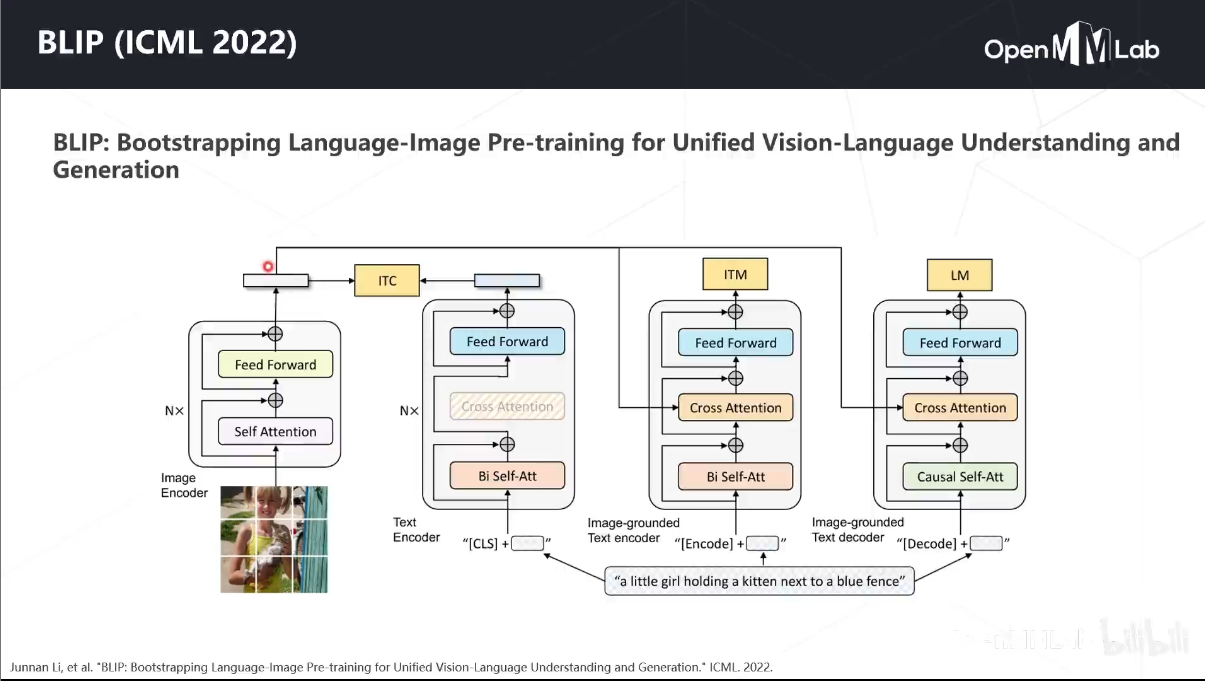
BLIP
BLIP,这是一个新的VLP框架,可以灵活地转换到视觉语言理解和生成任务。BLIP通过引导字幕有效地利用了嘈杂的web数据,其中字幕器(captioner)生成合成字幕,而过滤器(filter)则删除了嘈杂的字幕。作者在广泛的视觉语言任务上获得了最先进的结果,例如图像文本检索 ,图像字幕和VQA。当以zero-shot方式直接转移到视频语言任务时,BLIP还表现出很强的泛化能力。
其它算法
方式直接转移到视频语言任务时,BLIP还表现出很强的泛化能力。
其它算法