本篇文章将深入探讨如何在Stable Diffusion WebUI上进行各项参数的调整。将以txt2img为主要讨论对象,探讨诸如基本设定Sampling method以及CFG scale等参数的调整,以及这些参数之间的相互影响。
对于还未安装Stable Diffusion WebUI的小伙伴,可以参阅上一篇文章 Stable Diffusion WebUI 本地安装教学 以获得安装和运行的具体步骤。
而本篇文章将直接讨论和解析WebUI的各项参数。
文章目录
- Stable Diffusion Checkpoint 模型选择
- Prompt 关键词
- Negative Prompt 负面词
- Sampling method 采样方法
- Sampling steps 采样步数
- Width、Height 图片尺寸
- Batch size、Batch count 生成批次
- CFG Scale 词相关性
- Seed 种子
- Restore faces 面部修复
- Tiling 平铺
- Hires. fix 高清修复
Stable Diffusion Checkpoint 模型选择
选择下拉菜单中的基础计算模型。新增模型后,点击旁侧的刷新按钮,菜单将自动更新选项。
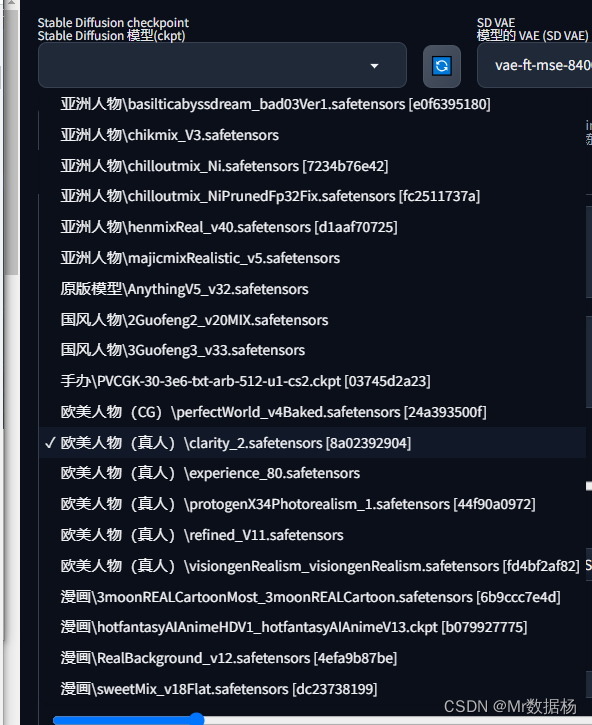
对于模型的下载地址可以访问 Civitai ,也就是传说中的C站进行下载。
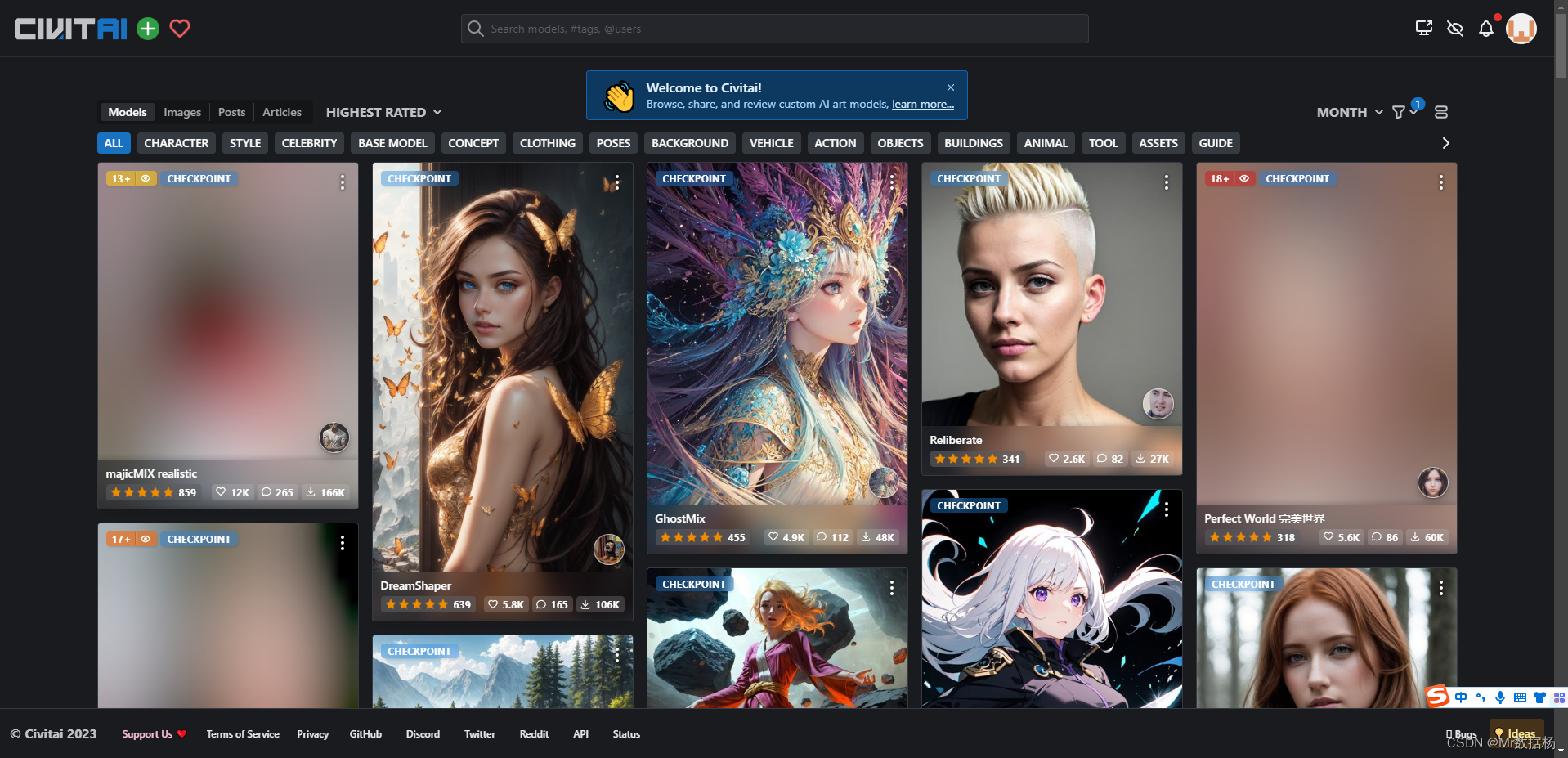
例如点击其中 GhostMix模型页面进入之后。点击右边的Donwnload即可下载。
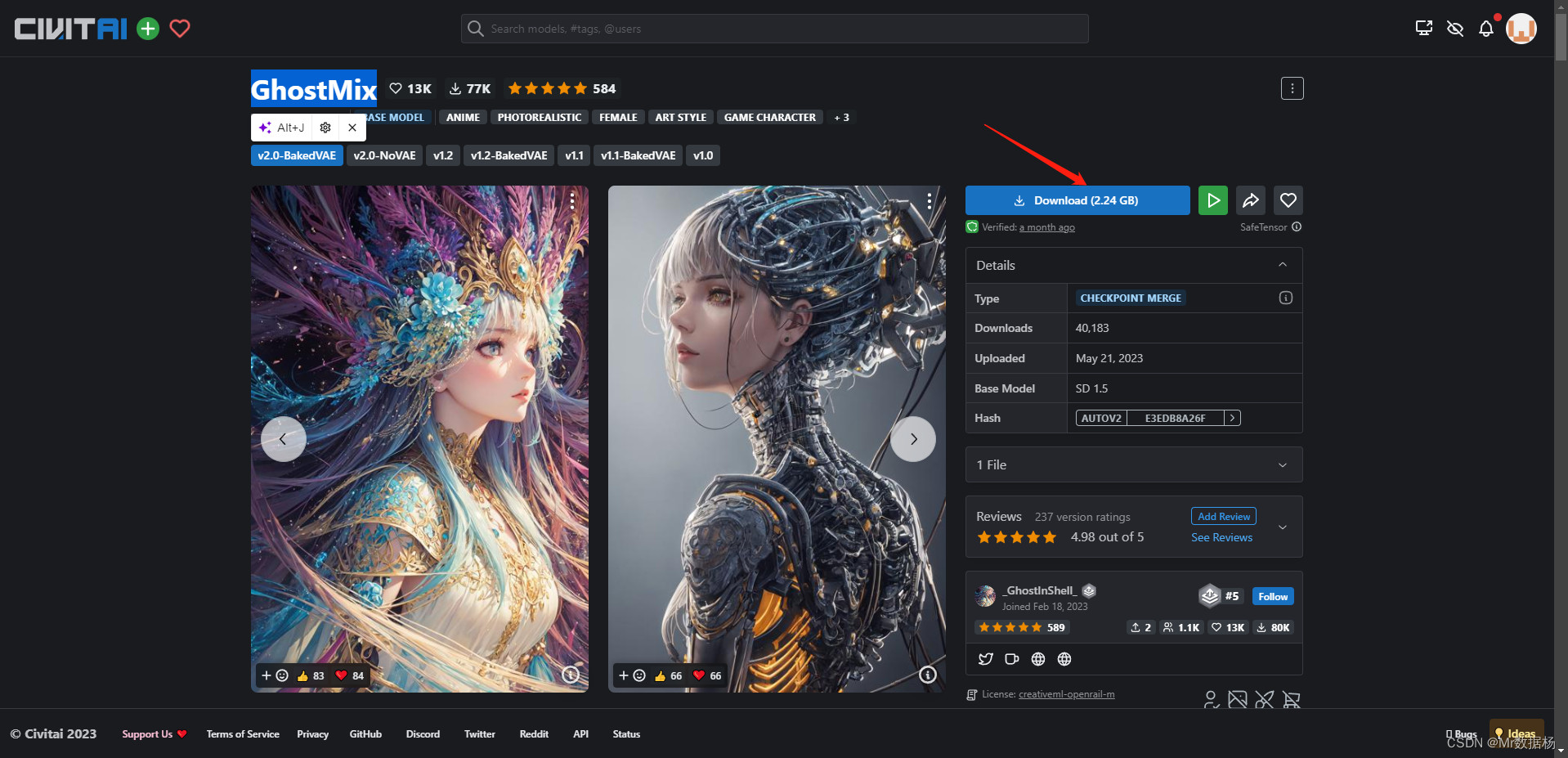
下载之后将下载好的模型文件移动到你的SD目录下models\Stable-diffusion即可。

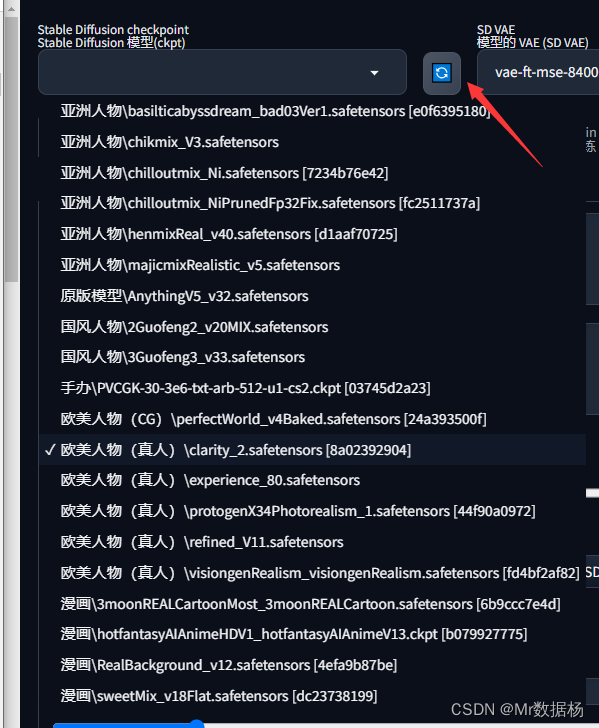
然后点击刷新按钮就可以看到你刚下载好的模型文件了。
Prompt 关键词
输入关键字用户需要提供描述想要生成的图像的关键字。例如 “夕阳下的海滩”、
当然这个关键词要用英文表示,中文是无法识别的。
例如 “夕阳下的海滩” A beach at sunset

例如 “雪山上的滑雪者” Skiers on Snowy Mountains
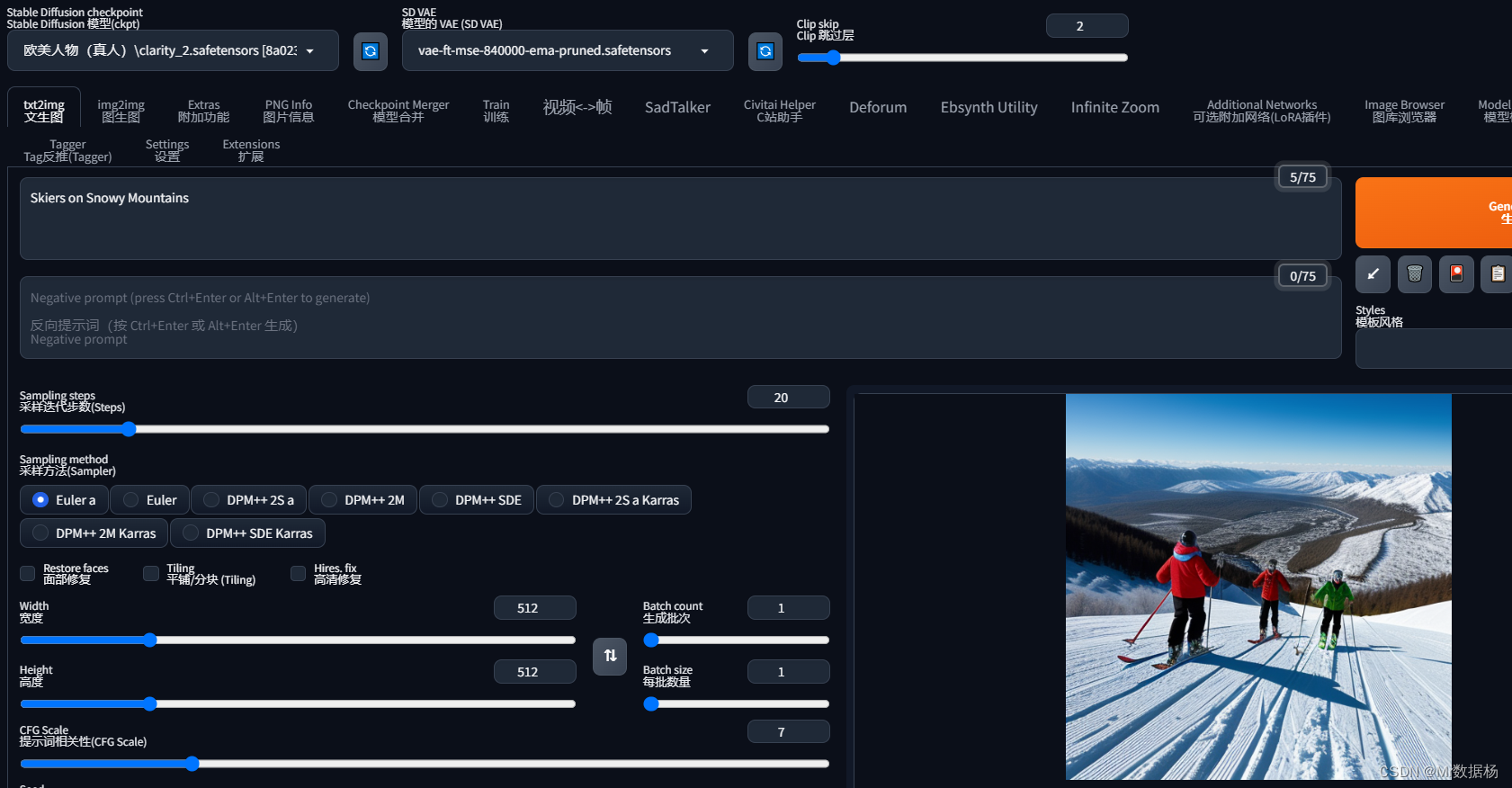
关键字下发与模型训练相关性,关键字的下发过程与模型的训练密切相关。因此不同的模型所采用的提示(prompt)可能会有很大的不同。某些关键字可能不被模型识别,这可能会导致最终的输出结果并不理想。
因此强烈推荐参考 Civitai 各个模型的专页,从中提取使用示例并进行相应的修改。这将有助于获取更优质的输出结果。

在搜索关键字外,特殊符号如圆括号 () 可调整关键字权重,或中括号 [] 可在过程中变换权重。
简单提示关键字方向:
物体:希望在画面中展现的元素,例如人物、动物、物品等。可描述有哪些物品,也可添加物品的形容词,如人物的穿着、动作、年龄等描述。例如英文描述 Envision a scene bustling with life, where an array of elements come together in harmony. An elderly man, wrinkles etched by time, sits tranquilly at a worn wooden table, engrossed in a book. Beside him, a ginger cat, basking in the afternoon sun, eyes half-closed in contentment. Scattered around the room, everyday objects - a chipped ceramic mug filled with steaming tea, a battered leather-bound journal, an antique brass lamp casting a warm glow. Each item, rich with history and stories, adds depth to the scene, painting a vivid picture of life's simple pleasures.

位置:物体所处位置,也可以理解为画面背景,向 Stable Diffusion 描述背景内容(否则它会自由发挥)。例如英文描述In the heart of a bustling city, the object takes center stage. Towers of steel and glass rise in the background, their reflective surfaces sparkling under the midday sun. The object is surrounded by the hurried blur of pedestrians, each absorbed in their own world, forming a dynamic backdrop for Stable Diffusion to illustrate.

风格:通知 Stable Diffusion 呈现图像的风格,是某位画家的风格?还是照片?需要注意的是,并非每个模型都有对应风格的关键字,有时直接更换模型或 LoRA 可能更快达到目标。例如英文描述Direct Stable Diffusion to render an image in a certain style. Is it in the style of a specific artist or a photograph? Keep in mind that not every model necessarily has keywords for each style. Sometimes, switching models or employing LoRA can be a quicker way to achieve the desired effect

角度:想象"镜头"从哪个角度拍摄?或是人物视线的方向。例如英文描述Envision the scene from a bird's eye view, capturing the intricate details of the landscape below. The focal point is a lone figure standing at the edge of a cliff, gazing into the vast ocean that stretches into the horizon. The person's sight is directed towards the setting sun, their silhouette bathed in the warm, golden glow.

初始生成的图像可能不尽如人意,但通过这些指导原则组合 Prompt,逐步迭代出理想中的画面,也是一种创作过程。需要注意的是 prompt 受资源限制影响,也就是你机器的GPU性能。
Negative Prompt 负面词
当输入文字使Stable Diffusion进行图像生成时,可以通过输入特定关键字来避免生成带有某些特定特征的图像。
通常为了提高生成图像的质量,人们会添加如"worst quality"、“grayscale”、“low quality"等关键字。如果不希望图像中出现某些元素,例如"fused fingers”(融合的手指)、“bad anatomy”(错误的解剖结构)或"missing fingers"(缺失的手指),也可以通过添加这些关键字来实现。
下面这是一组通用的负面关键词填写。
(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),(((missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet
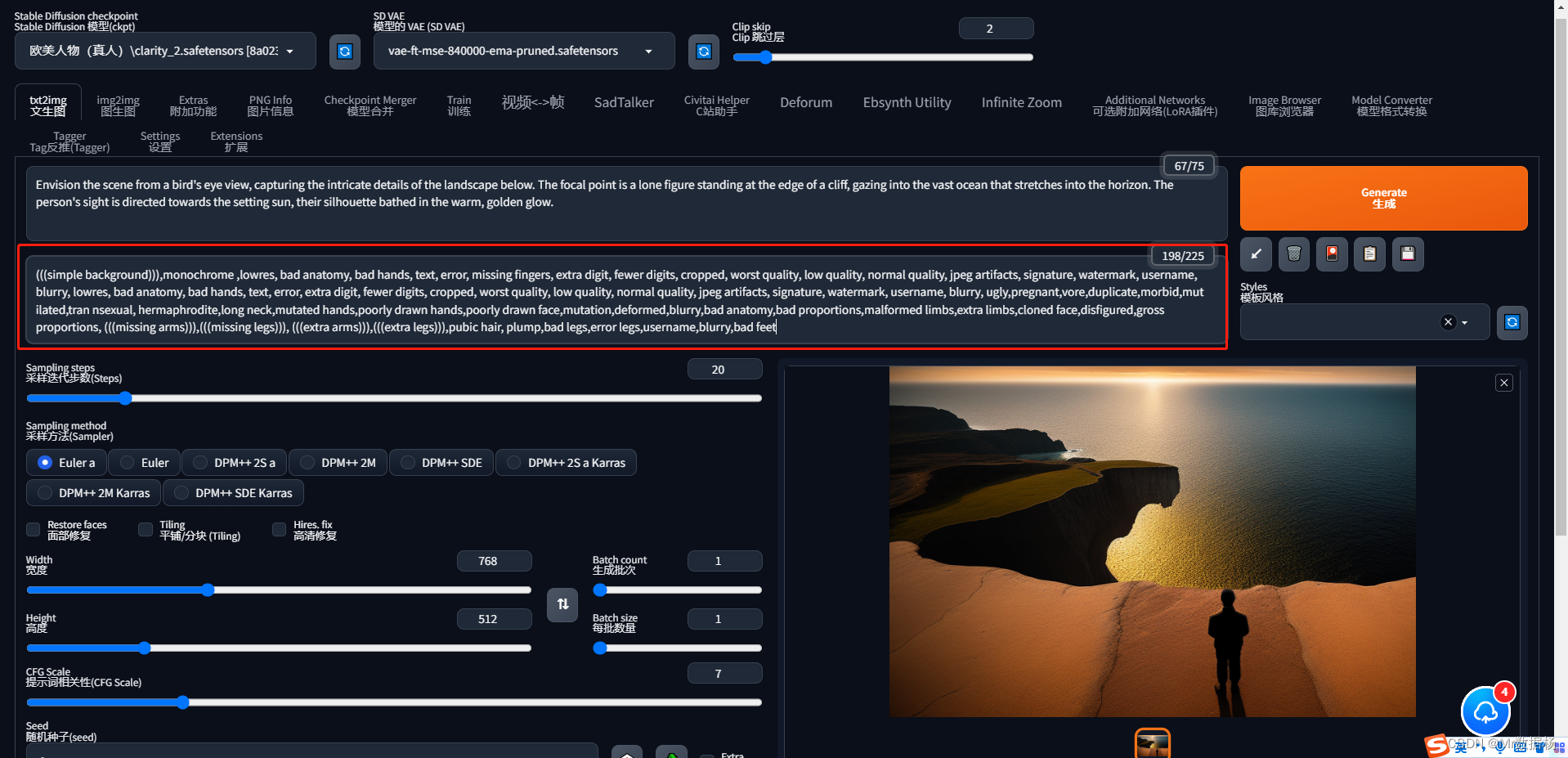
Civitai 的模型专页也列出了一些negative prompt(负向提示),大部分都是以上提到的这些关键字,可以作为参考。

Sampling method 采样方法
采样方法(Sampling Method)是与模型设计的数学原理紧密相连的概念。对此,只需把握大体的理解即可。试想象这是在模型计算过程中,通过不同的手段来逼近答案的一种方式。这会对计算的结果和质量产生影响。不同的采样方法可能需要的计算时间也会有所不同。

实际应用中,我经常使用的是DPM++ 2M Karras、DPM++ SDE Karras和Euler这几种采样方法。选择它们的主要原因是,这几种算法计算出的图像质量相对较好,且大多数模型演示图也是使用这几种参数生成的。
Sampling steps 采样步数
Stable Diffusion 的步骤选择,步数与画质、细节呈正相关。然而,正相关并不意味着步数越高,画质就越好。通常步数在 15~30 步区间,步数越大对画质影响越小,如何选择和使用的 Model 以及 Sampling method 也很关键。
步数越多,所需时间越多。值得注意的是,不同的 Sampling steps 可能会产生不同的图像(例如角色姿势差异等)。实际操作中需要多少步数,除了上述原则外,很多取决于经验和感觉。
下面是一个10,20,30,50,100,150步数效果,步数越多图片更佳细致。

Width、Height 图片尺寸
图像尺寸是最直观的元素,决定了图像结果的长宽。尽管这看似简单,但实际上,它会产生其他的影响或限制。模型限制和长宽选择,根据模型设计的限制,图像的最小长宽需要设置为512 x 512。通常情况下,可以把其中一边改成768,以得到2:3的图像。
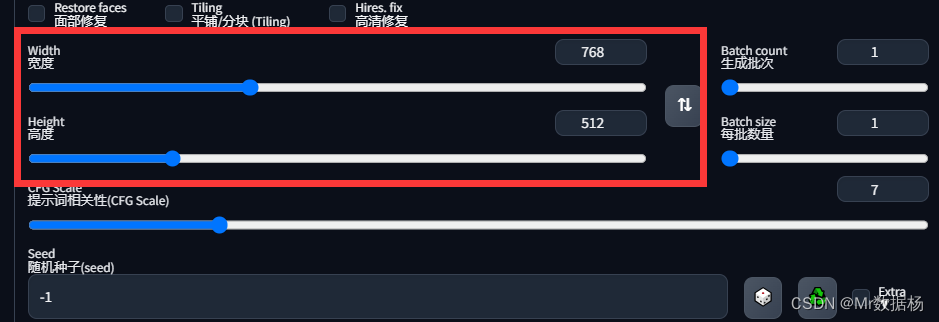
如果出现超大尺寸和多头怪现象,同样是受模型限制,如果设定过大的长宽,或长宽比例悬殊,可能会出现“多头怪”的现象。

若需要高清图片,此时可以先将大小调至适当的范围内,然后使用后文将介绍的"Hires. fix"方法解决。也可以在生成图像后使用"Extra"页面中的"Upscalling"功能放大图片。

Batch size、Batch count 生成批次
Batch size与Batch count他们有所不同:
Batch size决定在一次计算过程中,需要同时输出的图片数量(一个批次或一次计算过程称为一个Batch)。Batch count决定开始计算后,总共需要进行多少次计算(即多少个Batch)。
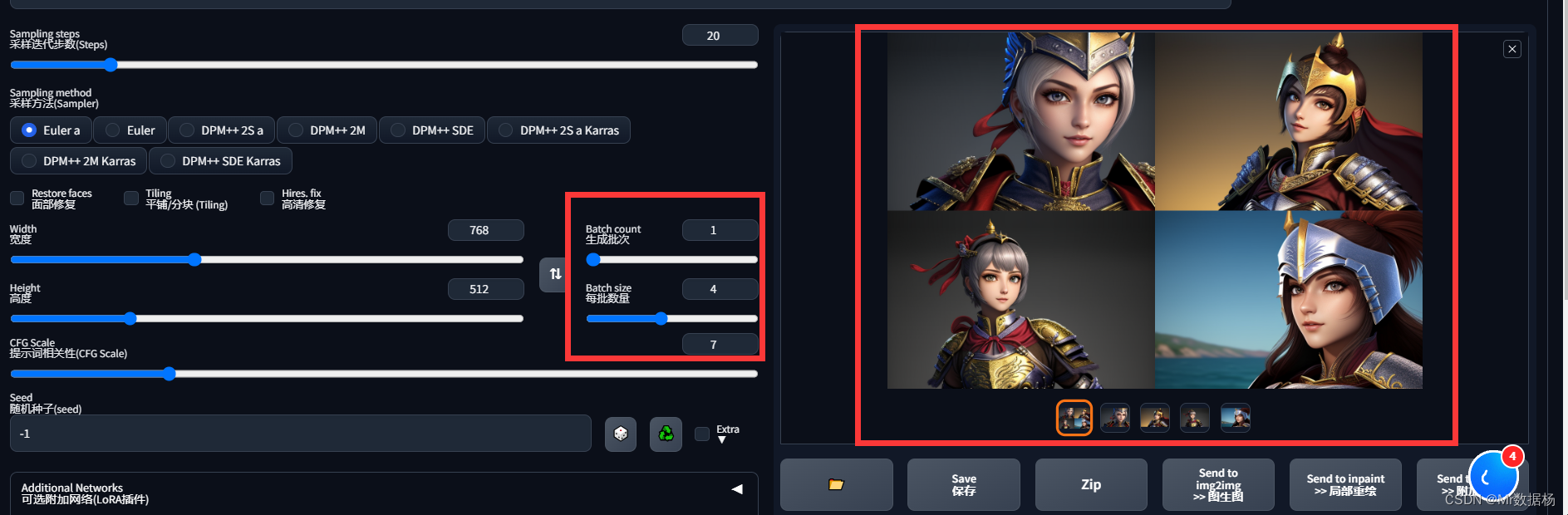
简单理解,如果Batch size较大,则GPU需要同时处理更多的图片,这将消耗更多的内存,但能够同时得到多个不同的结果。如果显卡内存足够,可以考虑提高Batch count,增加每次计算结果的选择性,而无需浪费时间。若内存不足,只能以时间换取空间,提高Batch size,让计算过程重复进行,产生更多的结果供选择。
CFG Scale 词相关性
此参数用于设定AI的倾听程度(Prompt),常见的设定范围如下:
| CFG Scale | 说明 |
|---|---|
| 1 | AI全权决定,忽略用户输入 |
| 3 | AI会加入部分自主想法 |
| 7 | 实现AI自主性与用户指示的平衡 |
| 1 | AI主要依赖用户输入 |
| 30 | 完全依照用户输入执行 |
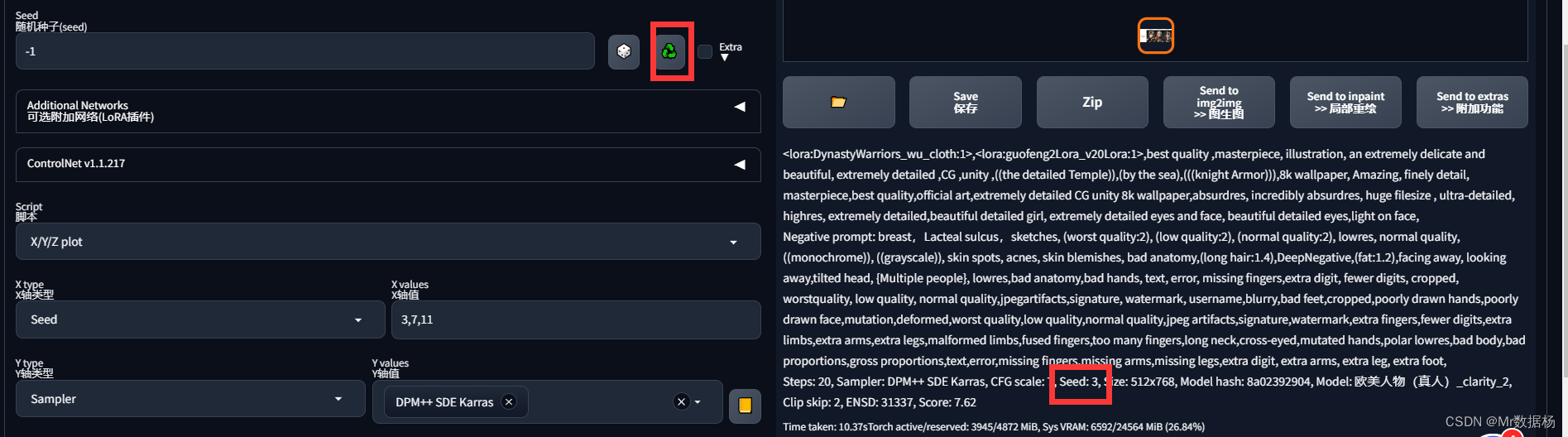
通过实际测试,分别以CFG Scale = 3、7、11 、15 、30为例。
假设Prompt为<lora:DynastyWarriors_wu_cloth:1>,<lora:guofeng2Lora_v20Lora:1>,best quality ,masterpiece, illustration, an extremely delicate and beautiful, extremely detailed ,CG ,unity ,((the detailed Temple)),(by the sea),(((knight Armor))),8k wallpaper, Amazing, finely detail, masterpiece,best quality,official art,extremely detailed CG unity 8k wallpaper,absurdres, incredibly absurdres, huge filesize , ultra-detailed, highres, extremely detailed,beautiful detailed girl, extremely detailed eyes and face, beautiful detailed eyes,light on face,

为使算法图像接近目标效果,主要通过调整Prompt,配合CFG Scale作辅助。尝试替换几个关键词,或者添加更具体的关键词以实现目标。CFG Scale建议保持在7左右(避免过大或过小),以获得更好的图像质量。
Seed 种子
从学术角度讲,Seed可以理解为在隐藏空间(latent space)中产生初始随机张量(tensor)的值。想要直观理解,可以将Seed看作生成图像的“源头”。只要更改Seed,即使Prompt、CFG Scale、Width、Height等参数保持不变,也能生成完全不同的图像。
这里有三张图,它们使用不同的Seed生成,但其他参数完全相同。

默认情况下 Stable Diffusion WebUI的种子(Seed)设置为-1。这意味着每次进行图像计算时,系统都会自动产生不同的种子值。这样的设计便于使用者利用相同的提示(Prompt)生成各种不同的图像结构,以满足多样化的选择需求。
假设今天找到一幅满意的图形,希望在保持布局不变的同时调整其他参数。这时只需点击Seed输入框旁边的"回收"按钮,WebUI会自动填入当前的Seed值并将其固定,这样图形的布局就可以保持不变。
Restore faces 面部修复
如在图像生成结果中,人物面部五官呈现奇异状态,这个选择有可能帮助解决这个问题。

在SD页面中点击人脸修复设置。
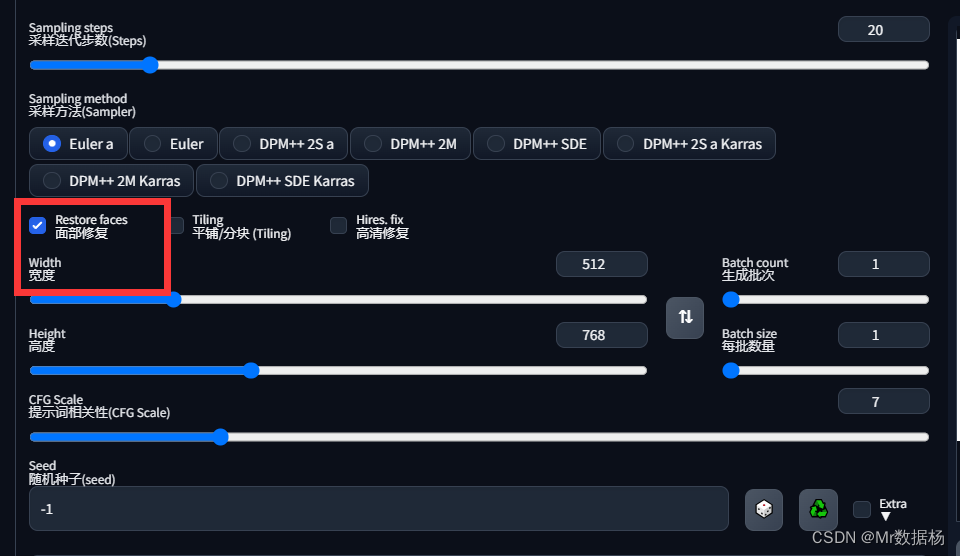
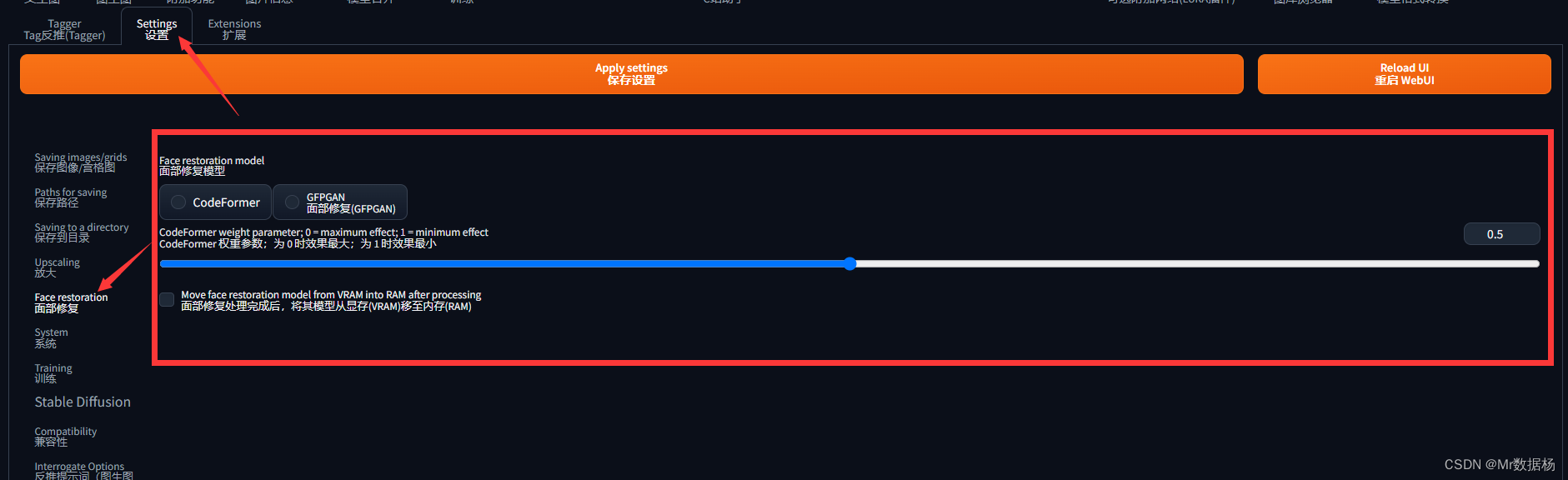
然后切换到 “Settings” 选项卡,点击左侧 “Face restoration” 选项,在屏幕中间选择 “CodeFormer”。滑动下方滑块来调整恢复强度。其中 0 表示最强的恢复效果,而1 表示最弱的。默认设置为 0.5,可以根据需要进行调整。
Tiling 平铺
此功能使得计算图结果能够无缝叠加,无限复制。常见应用包括创建基础图案元素,或制作二维游戏的背景单元图。
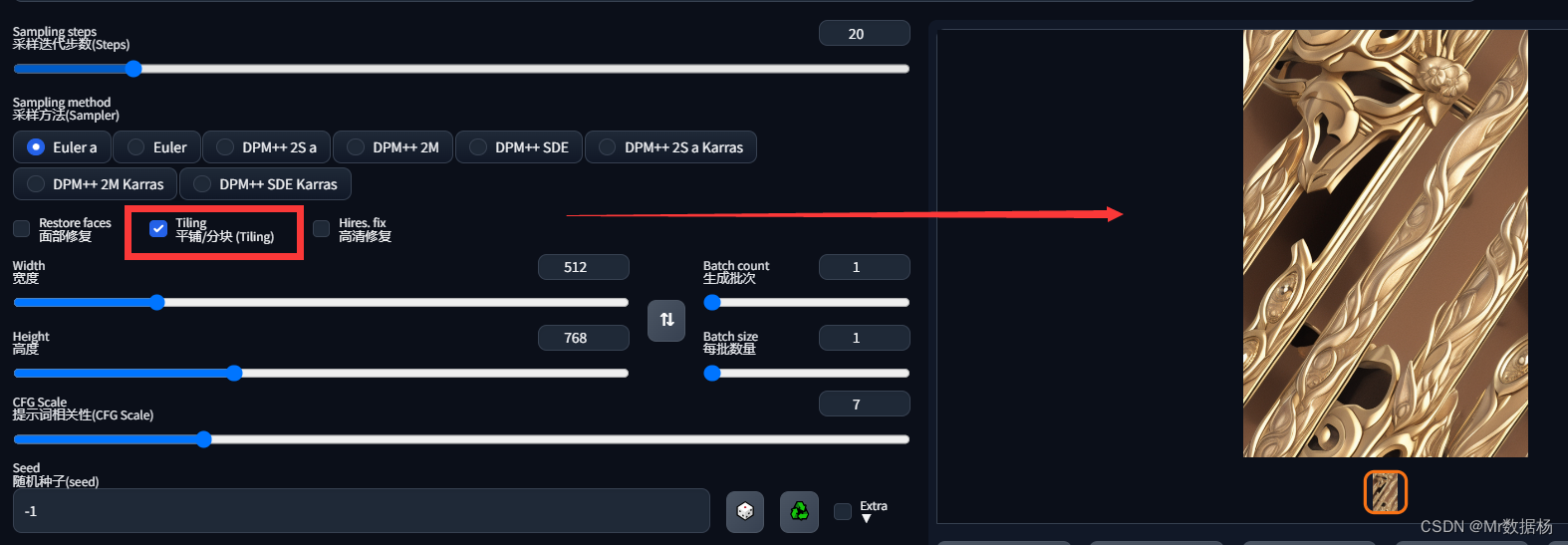
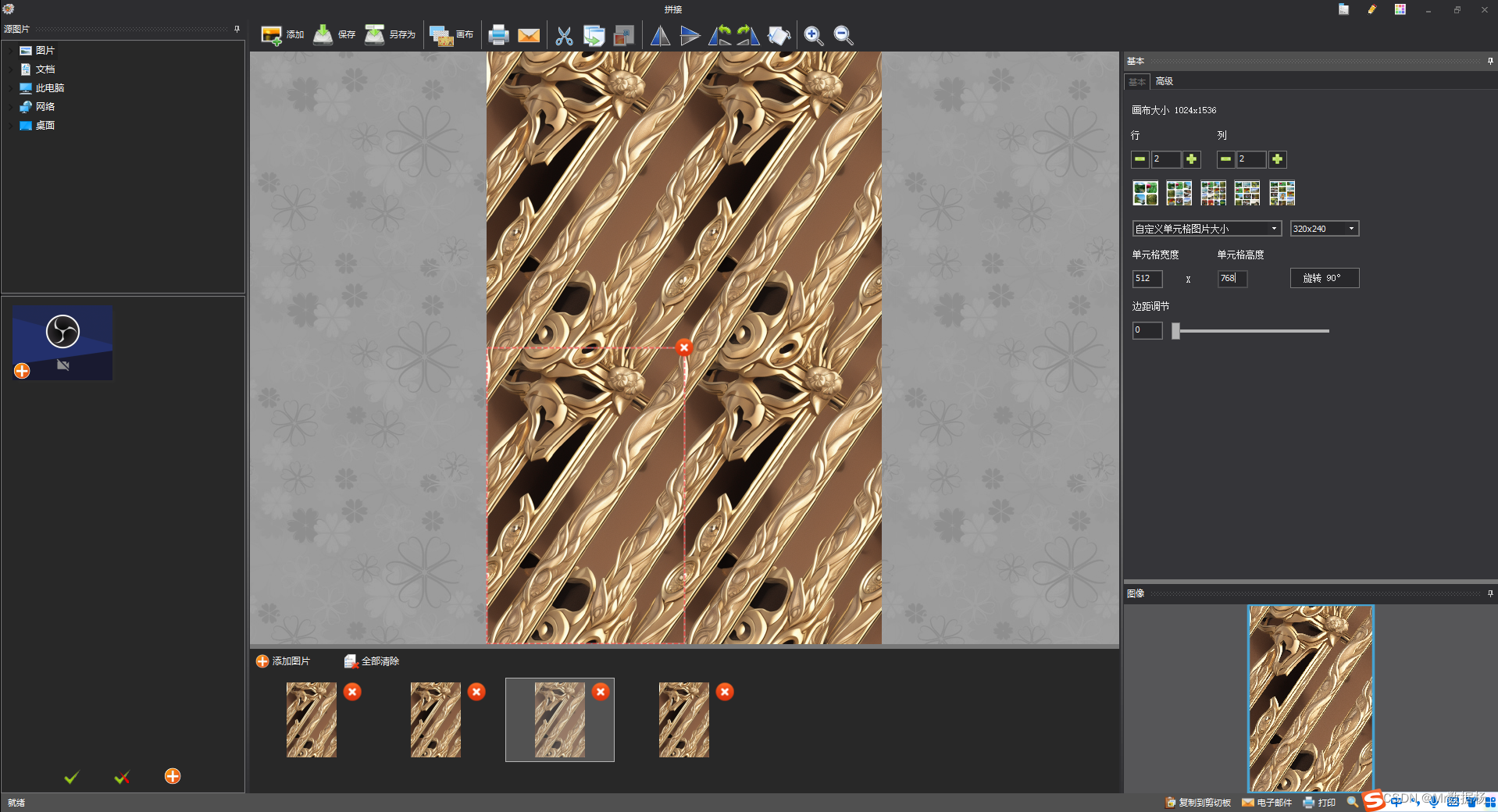
利用“Tiling”功能,该图像可以无缝地在中复制并堆叠,从而形成一幅更大的图像。
Hires. fix 高清修复
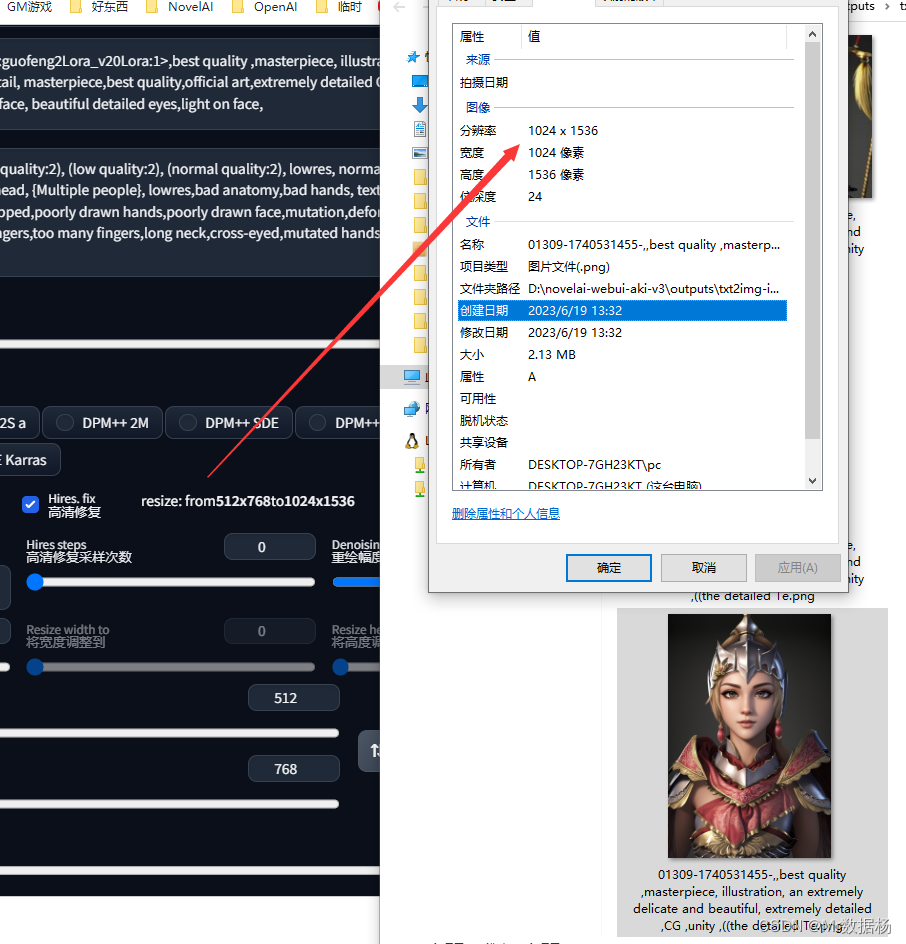
一旦选择了Hires. fix功能,系统会首先按照设定的宽度和高度进行渲染,然后通过Upscaler使用选择的方法将其分辨率放大Upscale by设置的倍数。
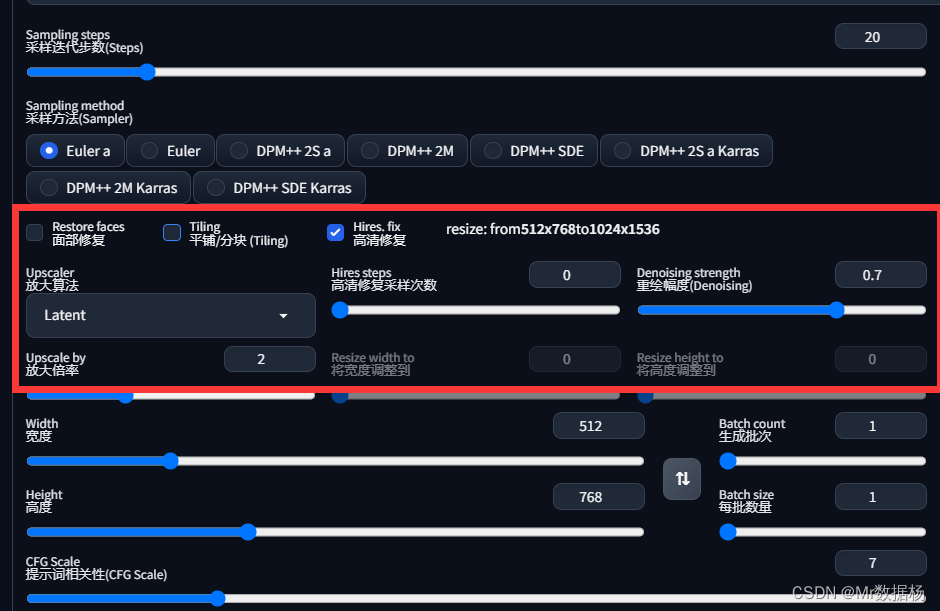
例如如下图所示,原先设置为 512 x 784,启动Hires. fix,选用Latent方法将分辨率放大1.5倍,最终得到的图片为 1049 x 1607的大小。