文章目录
- 一、redis
- 1.1 redis的数据结构都有哪些?
- 1.2 持久化方式有哪些?
- 1.3 怎么保证缓存和数据库数据的一致性?
- 1.4 redis缓存是什么意思?
- 二、数据库
- 2.1 基本数据类型
- 2.2 MySQL 的内连接、左连接、右连接有什么区别?
- 2.3 MySQL 问题排查都有哪些手段?
- 2.4 如何做 MySQL 的性能优化?
- 2.5 如何避免 SQL 注入?
一、redis
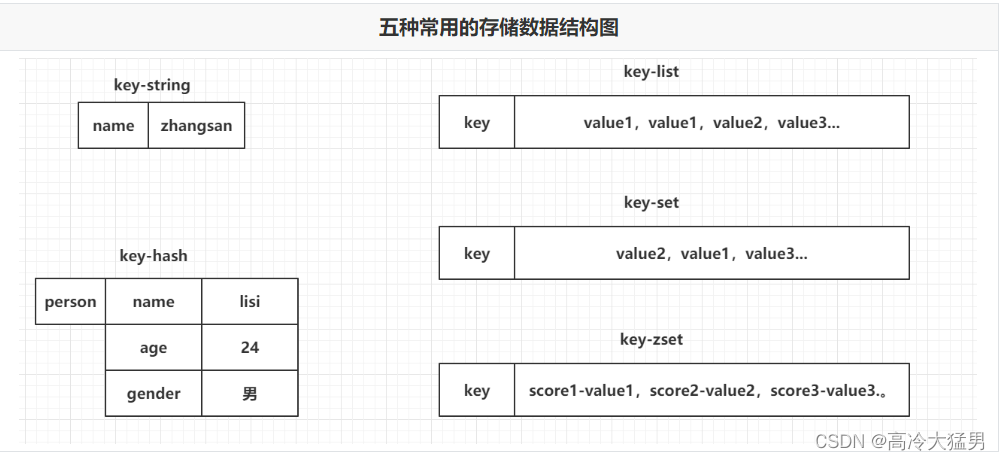
1.1 redis的数据结构都有哪些?
-
key-string:一个key对应一个值。最常用的,一般用于存储一个值。
-
key-hash:一个key对应一个Map。存储一个对象数据的。
-
key-list:一个key对应一个列表。使用list结构实现栈和队列结构。
-
key-set:一个key对应一个集合。交集,差集和并集的操作。
-
key-zset:一个key对应一个有序的集合。排行榜,积分存储等操作。
-
HyperLogLog:计算近似值的。
-
GEO:地理位置。
-
BIT:一般存储的也是一个字符串,存储的是一个byte[]。
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2SsxDAnj-1687195308369)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2SsxDAnj-1687195308369)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
1.2 持久化方式有哪些?
RDB:RDB是Redis默认的持久化机制
- RDB持久化文件,速度比较快,而且存储的是一个二进制的文件,传输起来很方便。
- RDB持久化的时机:
save 900 1:在900秒内,有1个key改变了,就执行RDB持久化。
save 300 10:在300秒内,有10个key改变了,就执行RDB持久化。
save 60 10000:在60秒内,有10000个key改变了,就执行RDB持久化。
如果300秒内 9个key改变了,也不执行持久化
- RDB无法保证数据的绝对安全。
- 假如 60秒内 执行了9999个key改变,RDB也不执行持久化,这时候数据就不是安全的
AOF:AOF持久化机制默认是关闭的,Redis官方推荐同时开启RDB和AOF持久化,更安全,避免数据丢失。
- AOF持久化的速度,相对RDB较慢的,存储的是一个文本文件,到了后期文件会比较大,传输困难。
- AOF持久化时机。
appendfsync always:每执行一个写操作,立即持久化到AOF文件中,性能比较低。 appendfsync everysec:每秒执行一次持久化。 推荐使用
appendfsync no:会根据你的操作系统不同,环境的不同,在一定时间内执行一次持久化。
- AOF相对RDB更安全,推荐同时开启AOF和RDB。
1.3 怎么保证缓存和数据库数据的一致性?
- 缓存更新策略: 在进行数据更新操作时,需要保证同时更新缓存和数据库。一种常见的策略是“先更新数据库,再更新缓存”。即在更新数据库之后,立即更新对应的缓存数据。这样可以确保缓存中的数据与数据库中的数据保持一致。
- 缓存失效策略: 当数据库中的数据发生更新时,可以通过使缓存失效来保证数据一致性。即在数据库更新操作完成后,手动使对应的缓存失效(或删除)。这样,下次读取该数据时,将从数据库中重新加载最新数据,并将其放入缓存中。
- 过期时间设置: Redis提供了设置缓存的过期时间的功能。可以根据数据的特性和业务需求,为缓存设置合适的过期时间。在过期时间到达后,缓存会自动失效,下次读取时将从数据库加载最新数据。通过合理设置过期时间,可以保证缓存中的数据与数据库中的数据保持一致,并避免数据过期导致的一致性问题。
- 读写分离: 对于一些高并发的应用场景,可以考虑使用读写分离的架构。即将读操作和写操作分别路由到不同的Redis实例或者节点上。写操作通过主节点更新数据库,并更新缓存,而读操作则通过从节点或者缓存来获取数据,从而保证数据的一致性。
1.4 redis缓存是什么意思?
使用Redis缓存的主要目的是减轻后端数据库的负载,提高系统的性能和响应时间。当应用程序需要访问某些数据时,它首先会尝试从Redis缓存中读取数据。如果缓存中存在所需的数据,应用程序就可以快速获取它,而无需查询数据库。这样可以减少对数据库的频繁访问,提高系统的吞吐量和并发能力。
二、数据库
2.1 基本数据类型
- 整数类型(Integer):用于存储整数值,如整数、长整数等。常见的整数类型有
INT、BIGINT等。 - 浮点数类型(Floating-Point):用于存储浮点数,如小数或科学计数法表示的数值。常见的浮点数类型有
FLOAT、DOUBLE等。 - 字符串类型(String):用于存储文本或字符数据。字符串类型可以是固定长度的,也可以是可变长度的。常见的字符串类型有
CHAR、VARCHAR、TEXT等。 - 布尔类型(Boolean):用于存储逻辑值,表示真或假。在某些数据库中,布尔类型可以使用1和0来表示。
- 日期和时间类型(Date and Time):用于存储日期、时间或日期时间的数值。常见的日期和时间类型有
DATE、TIME、DATETIME等。 - 二进制类型(Binary):用于存储二进制数据,如图像、音频或视频文件。二进制类型可以存储任意长度的二进制数据。
2.2 MySQL 的内连接、左连接、右连接有什么区别?
-
内连接(Inner Join):内连接返回两个表中满足连接条件的交集数据。只有在连接条件匹配的情况下,才会返回相关的行。如果某个表中的行在另一个表中没有匹配的行,则该行不会包含在结果中。
例如,如果你有两个表A和B,使用内连接查询
SELECT * FROM A INNER JOIN B ON A.id = B.id,结果将只包含那些在A和B表中都有匹配的行。 -
左连接(Left Join):左连接返回左表中的所有行,以及右表中满足连接条件的匹配行。如果右表中没有匹配的行,则会使用NULL值填充右表的列。
例如,使用左连接查询
SELECT * FROM A LEFT JOIN B ON A.id = B.id,结果将包含左表A的所有行,以及那些在B表中有匹配的行。 -
右连接(Right Join):右连接与左连接相反,它返回右表中的所有行,以及左表中满足连接条件的匹配行。如果左表中没有匹配的行,则会使用NULL值填充左表的列。
例如,使用右连接查询
SELECT * FROM A RIGHT JOIN B ON A.id = B.id,结果将包含右表B的所有行,以及那些在A表中有匹配的行。
需要注意的是,左连接和右连接通常用于连接两个表,而内连接可以用于连接多个表。使用不同类型的连接取决于你需要获取的数据和数据之间的关系。
2.3 MySQL 问题排查都有哪些手段?
- 错误日志(Error Log):MySQL会将运行时发生的错误和警告记录到错误日志中。查看错误日志可以帮助你了解数据库中发生的问题,并提供有关错误的详细信息。错误日志的位置和名称可以在MySQL配置文件中找到。
- 查询日志(Query Log):通过启用查询日志,可以记录所有进入MySQL服务器的查询语句。查询日志可以帮助你分析执行的查询语句和查询性能。但请注意,启用查询日志可能会对性能产生影响,因为它会记录每个查询。
- 慢查询日志(Slow Query Log):慢查询日志用于记录执行时间超过特定阈值的查询语句。通过分析慢查询日志,你可以找到执行时间较长的查询,并对其进行优化。
- Explain命令:Explain命令可以用于分析查询语句的执行计划。它可以告诉你查询将如何执行、使用哪些索引以及涉及的表和连接类型。使用Explain命令可以帮助你理解查询的执行过程,并识别潜在的性能问题。
- 监控工具和性能分析器:使用监控工具和性能分析器,如MySQL自带的Performance Schema、MySQL Workbench、Percona Toolkit等,可以实时监控MySQL的性能指标、查询执行时间、锁和死锁情况等。这些工具可以帮助你识别性能瓶颈和优化查询。
- 数据库配置参数:MySQL有许多配置参数,可以影响性能和行为。检查和调整这些配置参数,如缓冲区大小、连接数、并发控制等,可以优化MySQL的性能和稳定性。
- 索引和查询优化:分析查询语句的执行计划、使用合适的索引、优化查询语句的结构等,都是优化MySQL性能的重要手段。通过调整查询和表结构,可以减少查询的执行时间和资源消耗。
- 监控系统资源:监控服务器的CPU使用率、内存使用情况、磁盘I/O等系统资源,可以帮助你确定是否存在资源瓶颈,从而解决数据库性能问题。
2.4 如何做 MySQL 的性能优化?
- 优化查询语句:
- 使用合适的索引:根据查询条件和数据访问模式创建适当的索引,以加快查询速度。
- 减少查询返回的数据量:只选择需要的列,避免使用SELECT *,并使用LIMIT限制结果集的大小。
- 使用JOIN语句优化查询:避免多次单表查询,合理使用JOIN语句来连接多个表。
- 优化复杂查询:考虑重写复杂查询,拆分成多个简单查询或使用临时表等方式进行优化。
- 配置优化:
- 调整缓冲区大小:合理配置MySQL的缓冲区大小,如缓存池、查询缓存等,以提高数据读取和写入的效率。
- 调整并发连接数:根据系统负载和硬件配置,适当调整最大连接数,避免过多的并发连接导致性能下降。
- 调整其他配置参数:根据实际情况,调整MySQL的其他配置参数,如线程池、排序缓冲区、临时表大小等,以优化性能。
- 硬件和存储优化:
- 使用合适的硬件:选择合适的硬件设备,包括CPU、内存、存储等,以满足系统的需求。
- 使用合理的存储引擎:根据应用程序的特点和需求,选择合适的存储引擎,如InnoDB、MyISAM等。
- 配置文件系统和磁盘:确保文件系统和磁盘的性能良好,并遵循最佳实践进行配置。
- 数据库设计优化:
- 范式化和反范式化:根据数据的特点和查询需求,进行范式化或反范式化的设计,以提高查询效率。
- 分区和分表:对大型表进行分区或分表,可以提高查询和维护的效率。
- 垂直和水平拆分:根据业务需求,将大型数据库拆分成更小、更专注的部分,以提高性能和可扩展性。
- 定期维护和监控:
- 定期优化数据库:执行表优化、索引优化、碎片整理等操作,以保持数据库的健康状态。
- 监控和性能分析:使用监控工具和性能分析器监控MySQL的性能指标、查询执行时间等,识别潜在的性能问题,并及时进行调整和优化。
2.5 如何避免 SQL 注入?
- 使用参数化查询(Prepared Statements)或预编译语句:参数化查询是将SQL查询语句和参数分开处理,确保用户输入的数据不会被直接嵌入到查询语句中。数据库会预编译查询语句,然后将参数传递给查询,从而避免了SQL注入攻击。
- 使用存储过程(Stored Procedures):存储过程是预先定义在数据库中的一组SQL语句。通过使用存储过程,可以将数据校验和处理逻辑置于数据库层面,从而降低SQL注入的风险。
- 输入验证和过滤:对用户输入的数据进行验证和过滤,确保只接受预期的数据类型和格式。使用白名单或正则表达式等方法对输入进行限制,过滤掉非法字符或语法,从而防止恶意输入被执行为SQL语句。
- 不信任外部数据:将用户输入的数据视为不可信任的,并对其进行适当的转义或编码。使用数据库提供的转义函数或编码函数,如PDO的
quote()方法或相关编程语言的转义函数,来处理输入数据。 - 最小权限原则:将数据库用户授予最低权限,只赋予其执行必要操作的权限,限制对数据库的访问范围,从而减少潜在攻击的影响范围。
- 定期更新和维护:及时应用数据库供应商发布的安全更新和补丁,以修复已知的安全漏洞。同时,定期审查和维护应用程序的代码,修复可能存在的安全漏洞。
用户授予最低权限,只赋予其执行必要操作的权限,限制对数据库的访问范围,从而减少潜在攻击的影响范围。 - 定期更新和维护:及时应用数据库供应商发布的安全更新和补丁,以修复已知的安全漏洞。同时,定期审查和维护应用程序的代码,修复可能存在的安全漏洞。
- 安全意识培训:加强开发人员和管理员的安全意识培训,提高对SQL注入攻击的认识,遵循安全编码的最佳实践,以减少安全漏洞的风险。