PostGIS数据测试-一百万点要素
小小测试一下,看看单表百万数据的情况
服务器配置
- 系统版本:Centos7.9.2009
- CPU:两颗Intel® Xeon® Gold 6226R CPU @ 2.90GHz处理器,共32核心
- 内存:DDR4 256G
- 硬盘:Raid5 共24T
- 数据库版本:PostgreSQL13+PostGIS3.0
创建表
不添加GIS索引
create table geo_point_one_million_without_index
(
uid uuid default uuid_generate_v4() not null
constraint geo_point_one_million_without_index_pk
primary key,
geom geometry
);
comment on table geo_point_one_million_without_index is '点测试(一百万_没有geo索引)表';
comment on column geo_point_one_million_without_index.geom is '地理坐标';
alter table geo_point_one_million_without_index
owner to postgres;
添加GIS索引
create table geo_point_one_million
(
uid uuid default uuid_generate_v4() not null
constraint geo_point_one_million_pk
primary key,
geom geometry
);
comment on table geo_point_one_million is '点测试(一百万)表';
comment on column geo_point_one_million.geom is '地理坐标';
alter table geo_point_one_million
owner to postgres;
create index idx_geom_geo_point_one_million
on geo_point_one_million using gist (geom);
ST_GeneratePoints
这里我们使用PostGIS的ST_GeneratePoints函数来创建随机点。
ST_GeneratePoints官方介绍
格式
geometry ST_GeneratePoints( g geometry , npoints integer );
geometry ST_GeneratePoints( geometry g , integer npoints , integer seed );
描述
ST_GeneratePoints生成位于输入区域内的给定数量的伪随机点。可选的 seed 用于重新生成确定性的点序列,并且必须大于零。
可用性:2.3.0
增强:3.0.0,添加种子参数
示例
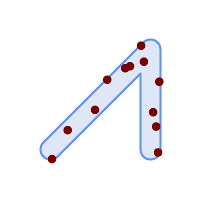
使用随机种子值1996生成了覆盖在原始面顶部的12个点
SELECT ST_GeneratePoints(geom, 12, 1996)
FROM (
SELECT ST_Buffer(
ST_GeomFromText(
'LINESTRING(50 50,150 150,150 50)'),
10, 'endcap=round join=round') AS geom
) AS s;
生成数据
不添加索引的数据
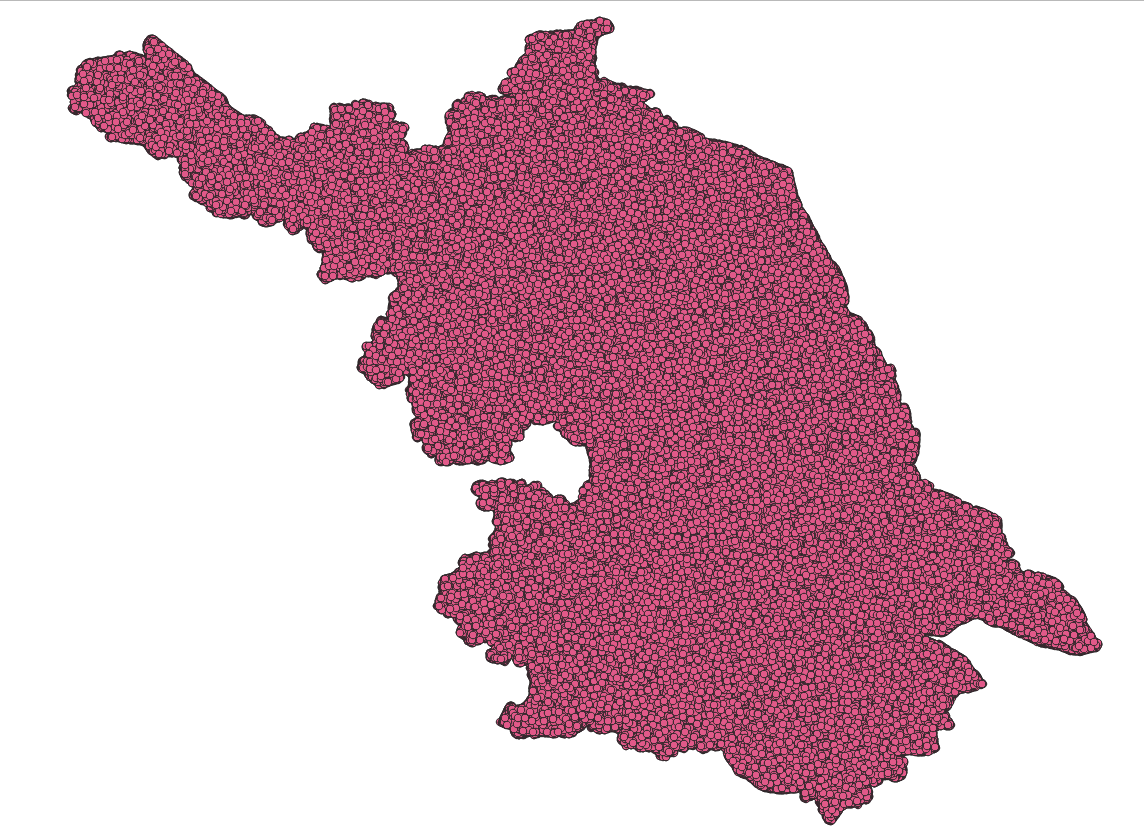
以江苏省范围为边界,随机生成一百一十万个点
insert into geo_point_one_million_without_index (geom)
SELECT (
ST_Dump(
ST_GeneratePoints(bound.geom, 1100000)
)).geom AS geom
FROM (
select geom
from province
) bound;
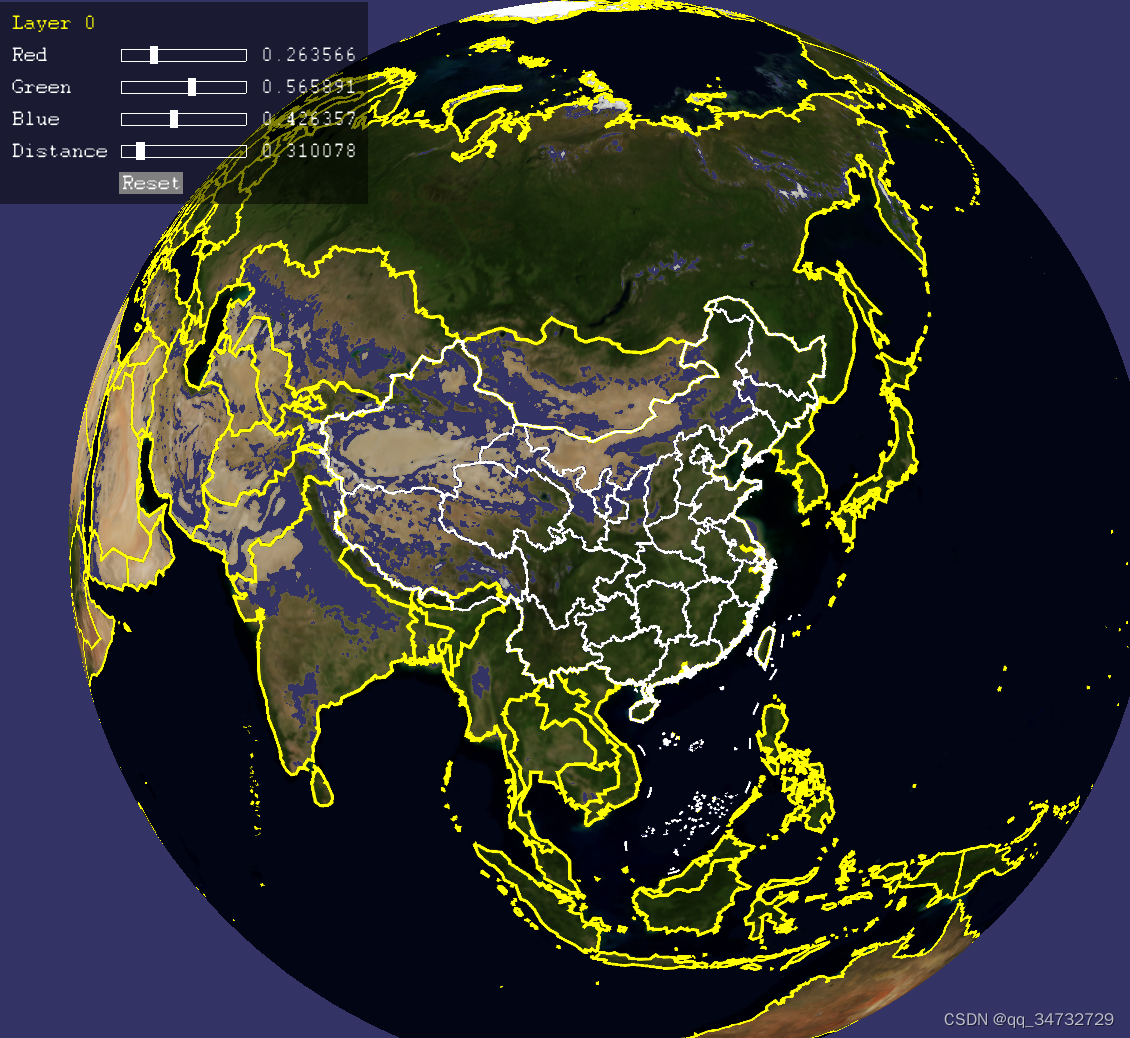
查看数据库总数如下:
加载到地图上如下所示,
添加索引的数据
以江苏省范围为边界,随机生成一百一十万个点
insert into geo_point_one_million (geom)
SELECT (
ST_Dump(
ST_GeneratePoints(bound.geom, 1100000)
)).geom AS geom
FROM (
select geom
from province
) bound;
效果如上图所示
数据查询效率比较
使用统一范围进行查询,查询范围内的点数据
查询没有索引的表
select geom
from geo_point_one_million_without_index
where ST_Intersects(geom,
st_transform(st_setsrid(st_geomfromewkt(
'POLYGON ((119.72706893295168 33.459312148850884, 119.72395052277068 33.44938433824096, 119.72271659870063 33.4495696575886, 119.7178056612509 33.424791447676355, 119.74576996445631 33.42143309794773, 119.74810254818226 33.42089897286719, 119.75342279140625 33.44529968061062, 119.75459464757762 33.45337738499248, 119.72706893295168 33.459312148850884))'),
4326)
, 4490));
如图所示:

经过多次测试,查询时间分布在460ms~550ms左右
查询有索引的表
select geom
from geo_point_one_million
where ST_Intersects(geom,
st_transform(st_setsrid(st_geomfromewkt(
'POLYGON ((119.72706893295168 33.459312148850884, 119.72395052277068 33.44938433824096, 119.72271659870063 33.4495696575886, 119.7178056612509 33.424791447676355, 119.74576996445631 33.42143309794773, 119.74810254818226 33.42089897286719, 119.75342279140625 33.44529968061062, 119.75459464757762 33.45337738499248, 119.72706893295168 33.459312148850884))'),
4326)
, 4490));
如图所示:

经过多次测试,查询时间分布在60ms~110ms左右
结果分析
初略对比进行分析,以110万点数据为例,可以看到添加索引后,查询速度提升了4~5倍。表数据越大或查询范围越大,提升的效果越明显。




![Java高效率复习-MySQL上篇[MySQL]](https://img-blog.csdnimg.cn/53b1cf967a2b409ba856f2e0e908d02a.png)