一、功能点
1.审计功能
分片审计功能是针对数据库分片场景下对执行的 SQL 语句进行审计操作。分片审计既可以进行拦截操作,拦截系统配置的非法 SQL 语句,也可以是对 SQL 语句进行统计操作。
目前ShardingSphere内置的分片审计算法只有一个,DML_SHARDING_CONDITIONS。他的功能是要求对逻辑表查询时,必须带上分片键。
# 分片审计规则: SQL查询必须带上分片键
spring.shardingsphere.rules.sharding.tables.course.audit-strategy.auditor-names[0]=course_auditor
spring.shardingsphere.rules.sharding.tables.course.audit-strategy.allow-hint-disable=true
spring.shardingsphere.rules.sharding.auditors.course_auditor.type=DML_SHARDING_CONDITIONS
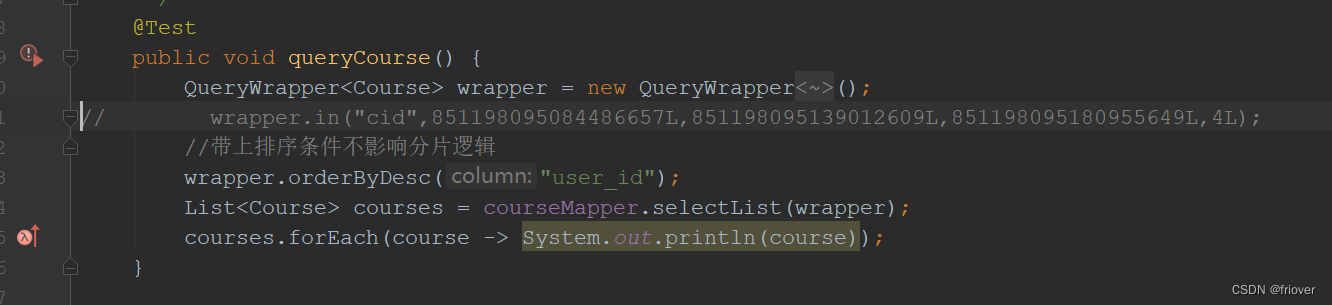
当该查询没有带上分片id时,就会报错
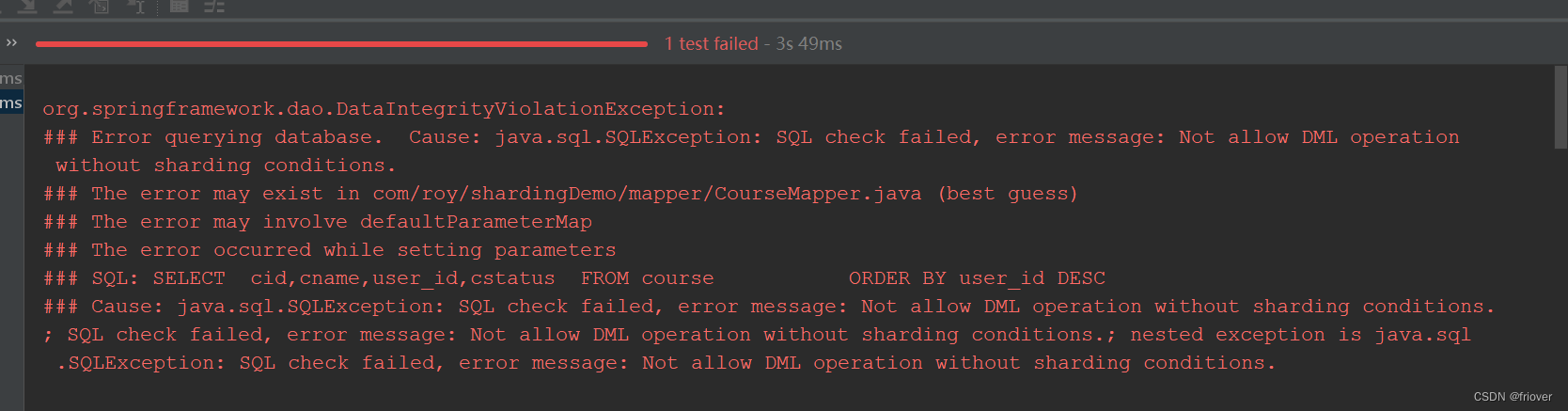
带上分片id时,没有问题
2.加密
ShardingSphere内置了多种加密算法,可以用来快速对关键数据进行加密。
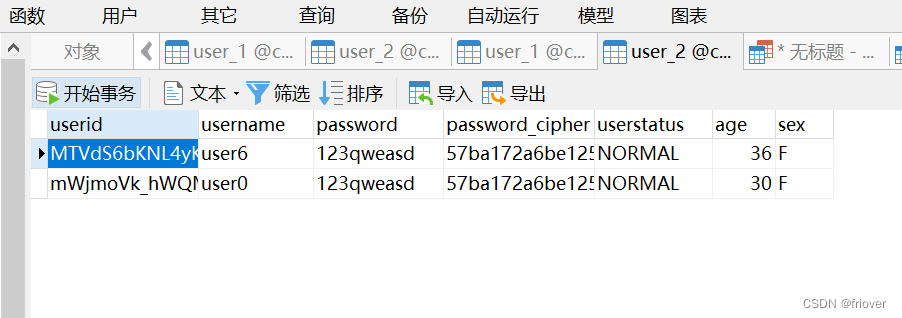
实际这里是对password这个字段存储明文,对password_cipher这个字段储存密文,指定对应的加密器
# 打印SQL
spring.shardingsphere.props.sql-show = true
spring.main.allow-bean-definition-overriding = true
# ----------------数据源配置
# 指定对应的库
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#------------------------分布式序列算法配置
# 生成字符串类型分布式主键。
spring.shardingsphere.rules.sharding.key-generators.user_keygen.type=NANOID
#spring.shardingsphere.rules.sharding.key-generators.user_keygen.type=UUID
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.user.key-generate-strategy.column=userid
spring.shardingsphere.rules.sharding.tables.user.key-generate-strategy.key-generator-name=user_keygen
#-----------------------配置实际分片节点
spring.shardingsphere.rules.sharding.tables.user.actual-data-nodes=m$->{0..1}.user_$->{1..2}
# HASH_MOD分库
spring.shardingsphere.rules.sharding.tables.user.database-strategy.standard.sharding-column=userid
spring.shardingsphere.rules.sharding.tables.user.database-strategy.standard.sharding-algorithm-name=user_db_alg
spring.shardingsphere.rules.sharding.sharding-algorithms.user_db_alg.type=HASH_MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.user_db_alg.props.sharding-count=2
# HASH_MOD分表
spring.shardingsphere.rules.sharding.tables.user.table-strategy.standard.sharding-column=userid
spring.shardingsphere.rules.sharding.tables.user.table-strategy.standard.sharding-algorithm-name=user_tbl_alg
spring.shardingsphere.rules.sharding.sharding-algorithms.user_tbl_alg.type=INLINE
# 字符串类型要先hashcode转为long,再取模。但是Grovvy的 "xxx".hashcode%2 不知道为什么会产生 -1,0,1三种结果
#spring.shardingsphere.rules.sharding.sharding-algorithms.user_tbl_alg.props.algorithm-expression=user_$->{Math.abs(userid.hashCode()%2) +1}
# 用户信息分到四个表
spring.shardingsphere.rules.sharding.sharding-algorithms.user_tbl_alg.props.algorithm-expression=user_$->{Math.abs(userid.hashCode()%4).intdiv(2) +1}
# 数据加密:对password字段进行加密
# 存储明文的字段
spring.shardingsphere.rules.encrypt.tables.user.columns.password.plainColumn = password
# 存储密文的字段
spring.shardingsphere.rules.encrypt.tables.user.columns.password.cipherColumn = password_cipher
# 加密器
spring.shardingsphere.rules.encrypt.tables.user.columns.password.encryptorName = user_password_encry
# AES加密器
#spring.shardingsphere.rules.encrypt.encryptors.user_password_encry.type=AES
#spring.shardingsphere.rules.encrypt.encryptors.user_password_encry.props.aes-key-value=123456
# MD5加密器
#spring.shardingsphere.rules.encrypt.encryptors.user_password_encry.type=MD5
# SM3加密器
spring.shardingsphere.rules.encrypt.encryptors.user_password_encry.type=SM3
spring.shardingsphere.rules.encrypt.encryptors.user_password_encry.props.sm3-salt=12345678
# sm4加密器
#spring.shardingsphere.rules.encrypt.encryptors.user_password_encry.type=SM4
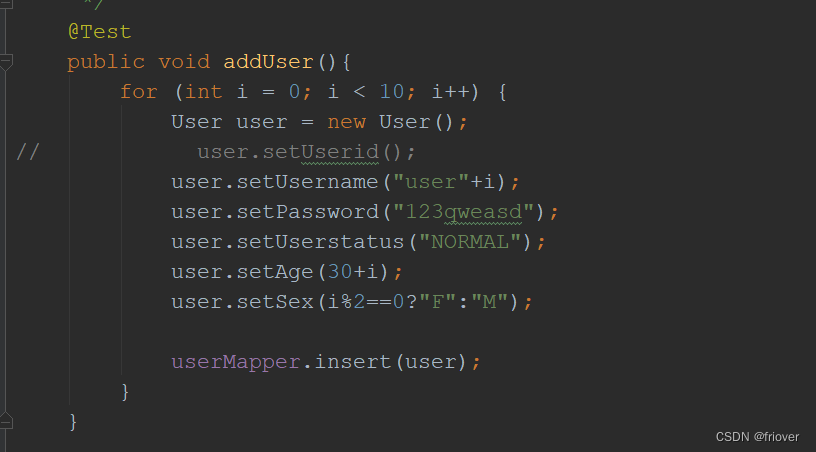
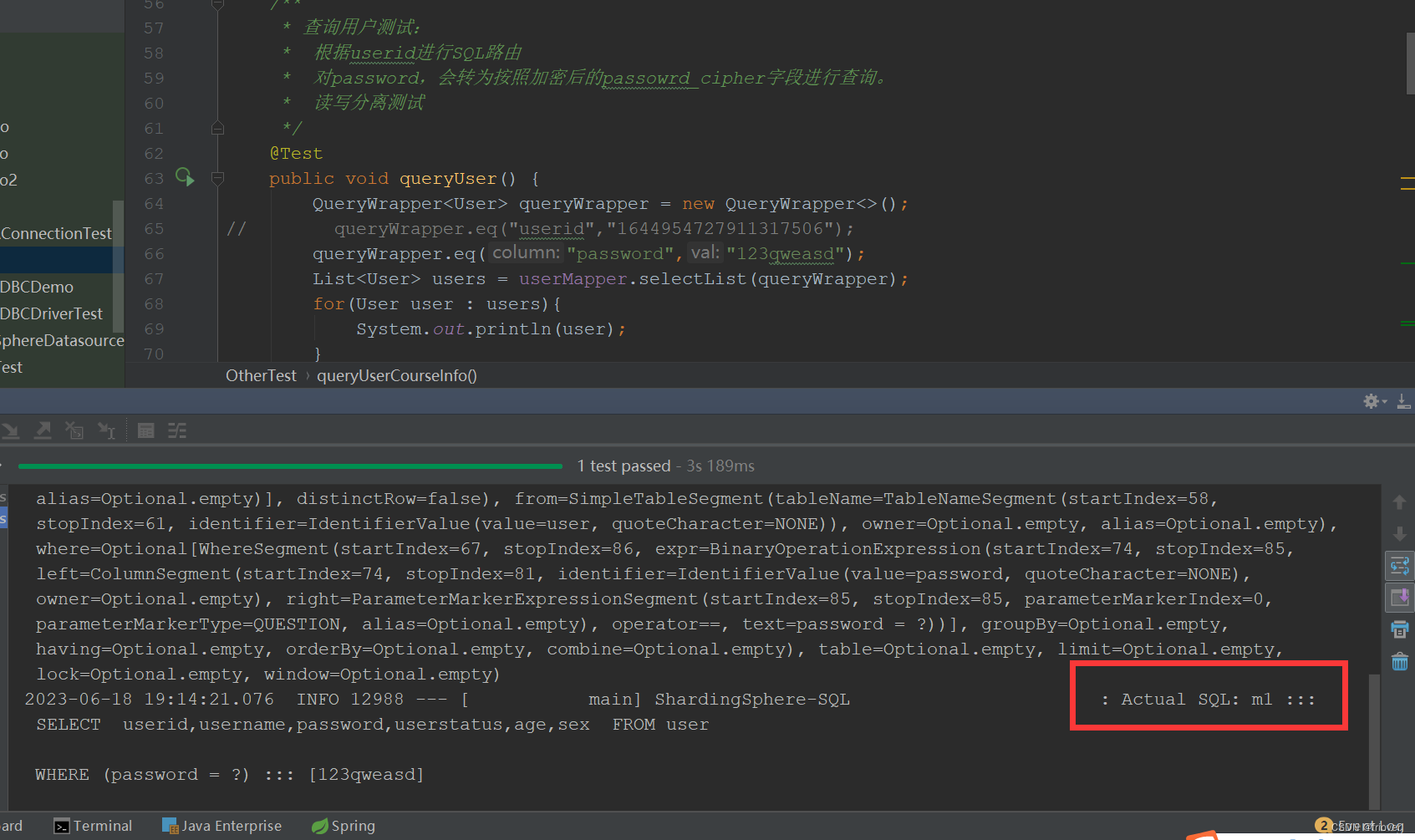
接下来在查询时,可以主动传入password_cipher查询字段,按照密文进行查询。同时,针对password字段的查询,也会转化成为密文查询。查询案例
@Test
public void queryUser() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// queryWrapper.eq("userid","1644954727911317506");
queryWrapper.eq("password","123qweasd");
//
queryWrapper.eq("password_cipher","c7d79d9c0898f7c4e252cd1ec19ed0c5c91aae0b0bc8bafc5f38322
418215d38");
List<User> users = userMapper.selectList(queryWrapper);
for(User user : users){
System.out.println(user);
}

3、读写分离
在ShardingSphere中,实现读写分离也非常简单。只需要创建一个
类型为readwrite-splitting的分片规则即可。我们就用之前建立的user表来快速配置一个读写分离示例。
# 打印SQL
spring.shardingsphere.props.sql-show = true
spring.main.allow-bean-definition-overriding = true
# ----------------数据源配置
# 指定对应的库
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#------------------------分布式序列算法配置
# 生成字符串类型分布式主键。
spring.shardingsphere.rules.sharding.key-generators.user_keygen.type=NANOID
#spring.shardingsphere.rules.sharding.key-generators.user_keygen.type=UUID
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.user.key-generate-strategy.column=userid
spring.shardingsphere.rules.sharding.tables.user.key-generate-strategy.key-generator-name=user_keygen
#-----------------------配置读写分离
# 要配置成读写分离的虚拟库
spring.shardingsphere.rules.sharding.tables.user.actual-data-nodes=userdb.user
# 配置读写分离虚拟库 主库一个,从库多个
spring.shardingsphere.rules.readwrite-splitting.data-sources.userdb.static-strategy.write-data-source-name=m0
spring.shardingsphere.rules.readwrite-splitting.data-sources.userdb.static-strategy.read-data-source-names[0]=m1
# 指定负载均衡器
spring.shardingsphere.rules.readwrite-splitting.data-sources.userdb.load-balancer-name=user_lb
# 配置负载均衡器
# 按操作轮训
spring.shardingsphere.rules.readwrite-splitting.load-balancers.user_lb.type=ROUND_ROBIN
# 按事务轮训
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.user_lb.type=TRANSACTION_ROUND_ROBIN
# 按操作随机
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.user_lb.type=RANDOM
# 按事务随机
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.user_lb.type=TRANSACTION_RANDOM
# 读请求全部强制路由到主库
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.user_lb.type=FIXED_PRIMARY
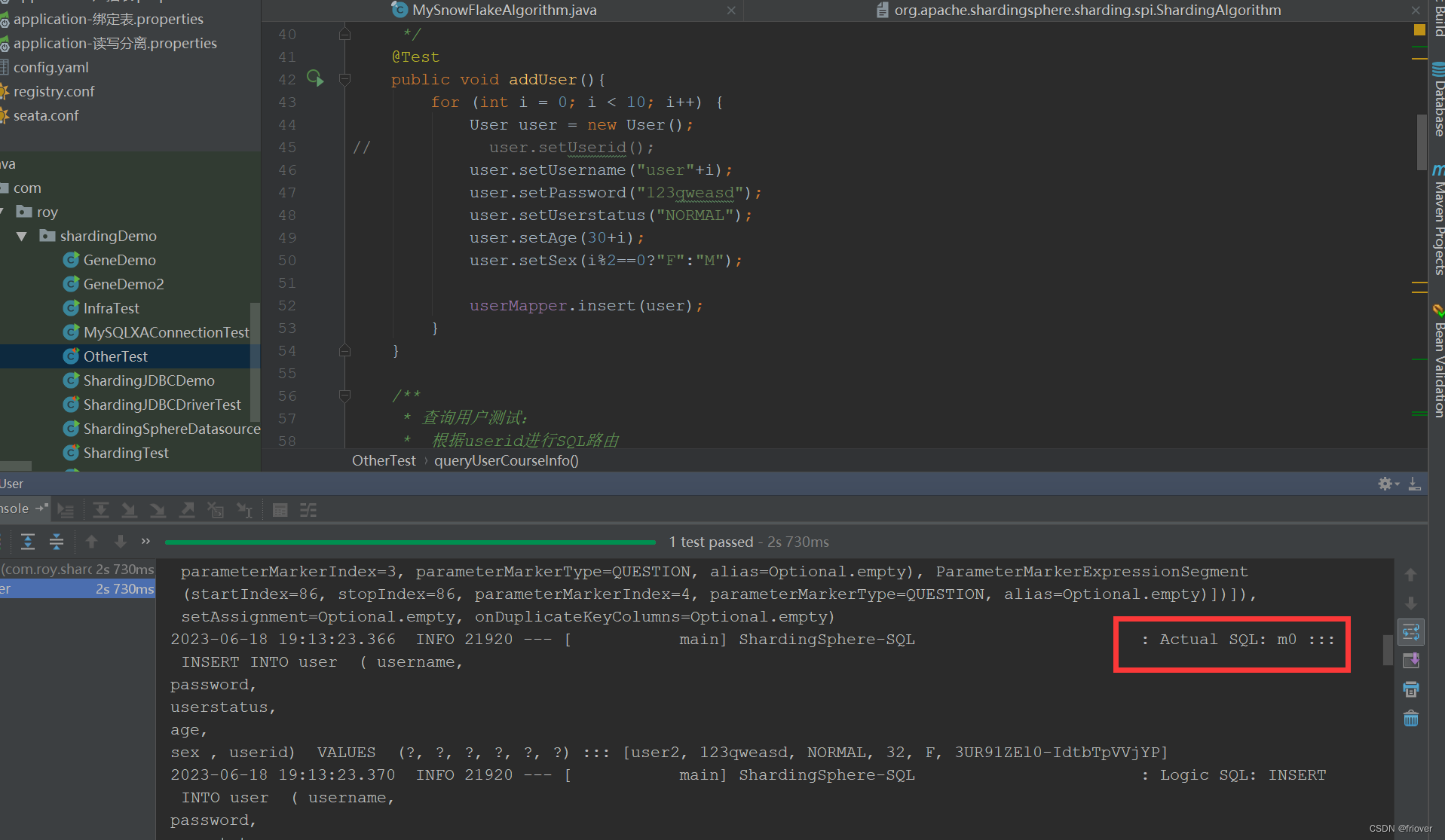
插入的是m0库,读取的是m1库
4、广播表
广播表表指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
实际广播表理解就是将同一个表插入到所有库里
# 打印SQL
spring.shardingsphere.props.sql-show = true
spring.main.allow-bean-definition-overriding = true
# ----------------数据源配置
# 指定对应的库
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#------------------------分布式序列算法配置
# 生成字符串类型分布式主键。
spring.shardingsphere.rules.sharding.key-generators.dict_keygen.type=SNOWFLAKE
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.dict.key-generate-strategy.column=dictId
spring.shardingsphere.rules.sharding.tables.dict.key-generate-strategy.key-generator-name=dict_keygen
#-----------------------配置读写分离
# 要配置成读写分离的虚拟库
#spring.shardingsphere.rules.sharding.tables.dict.actual-data-nodes=m$->{0..1}.dict_$->{1..2}
spring.shardingsphere.rules.sharding.tables.dict.actual-data-nodes=m$->{0..1}.dict
# 指定广播表。广播表会忽略分表的逻辑,只往多个库的同一个表中插入数据。
spring.shardingsphere.rules.sharding.broadcast-tables=dict
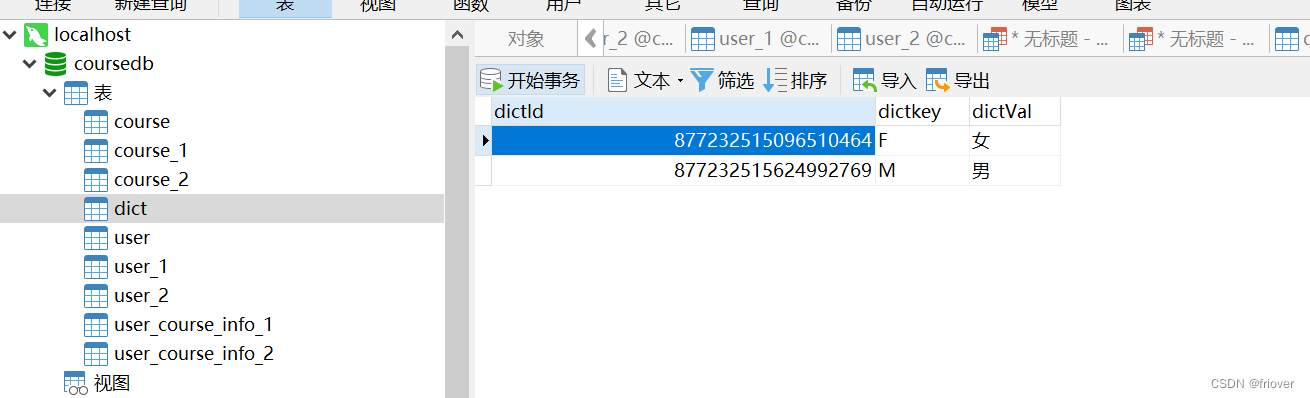
5、绑定表
绑定表指分片规则一致的一组分片表。使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。比如我们另外创建一张用户信息表,与用户表一起来演示这种情况
# 打印SQL
spring.shardingsphere.props.sql-show = true
spring.main.allow-bean-definition-overriding = true
# ----------------数据源配置
# 指定对应的库
spring.shardingsphere.datasource.names=m0
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
#------------------------分布式序列算法配置
# 生成字符串类型分布式主键。
spring.shardingsphere.rules.sharding.key-generators.usercourse_keygen.type=SNOWFLAKE
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.user_course_info.key-generate-strategy.column=infoid
spring.shardingsphere.rules.sharding.tables.user_course_info.key-generate-strategy.key-generator-name=usercourse_keygen
# ----------------------配置真实表分布
spring.shardingsphere.rules.sharding.tables.user.actual-data-nodes=m0.user_$->{1..2}
spring.shardingsphere.rules.sharding.tables.user_course_info.actual-data-nodes=m0.user_course_info_$->{1..2}
# ----------------------配置分片
spring.shardingsphere.rules.sharding.tables.user.table-strategy.standard.sharding-column=userid
spring.shardingsphere.rules.sharding.tables.user.table-strategy.standard.sharding-algorithm-name=user_tbl_alg
spring.shardingsphere.rules.sharding.tables.user_course_info.table-strategy.standard.sharding-column=userid
spring.shardingsphere.rules.sharding.tables.user_course_info.table-strategy.standard.sharding-algorithm-name=usercourse_tbl_alg
# ----------------------配置分表策略
spring.shardingsphere.rules.sharding.sharding-algorithms.user_tbl_alg.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.user_tbl_alg.props.algorithm-expression=user_$->{Math.abs(userid.hashCode()%4).intdiv(2) +1}
spring.shardingsphere.rules.sharding.sharding-algorithms.usercourse_tbl_alg.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.usercourse_tbl_alg.props.algorithm-expression=user_course_info_$->{Math.abs(userid.hashCode()%4).intdiv(2) +1}
# 指定绑定表
spring.shardingsphere.rules.sharding.binding-tables[0]=user,user_course_info
可以看到配置绑定表之后,只查询两个sql,但是如果没有配置的话就会出现笛卡尔积的查询


二、ShardingJDBC内核工作原理解读
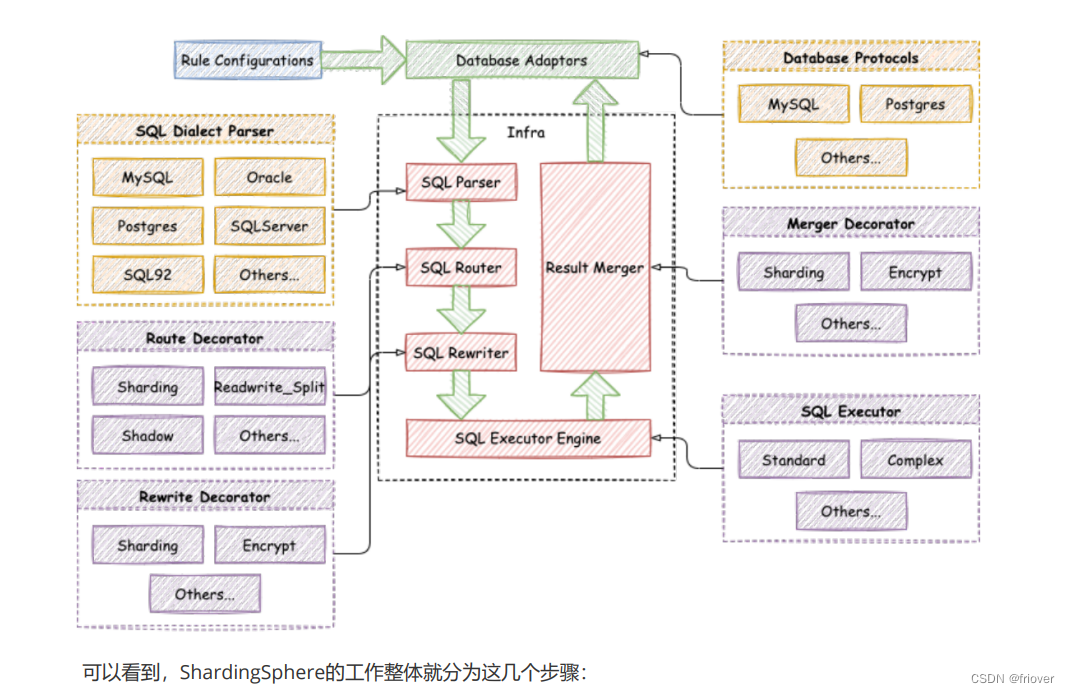
0、配置管控
在进入ShardingSphere的内核之前,ShardingSphere做了大量的配置信息管控。不光是将应用的配置信息进行解析,同时ShardingSphere还支持将这些配置信息放到第三方的注册中心,从而可以实现应用层的水平扩展。
1、SQL Parser: SQL解析引擎
解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字量和操作符。 再使用语法解析器将SQL转换为抽象语法树
SQL解析是整个分库分表产品的核心,其性能和兼容性是最重要的衡量指标。
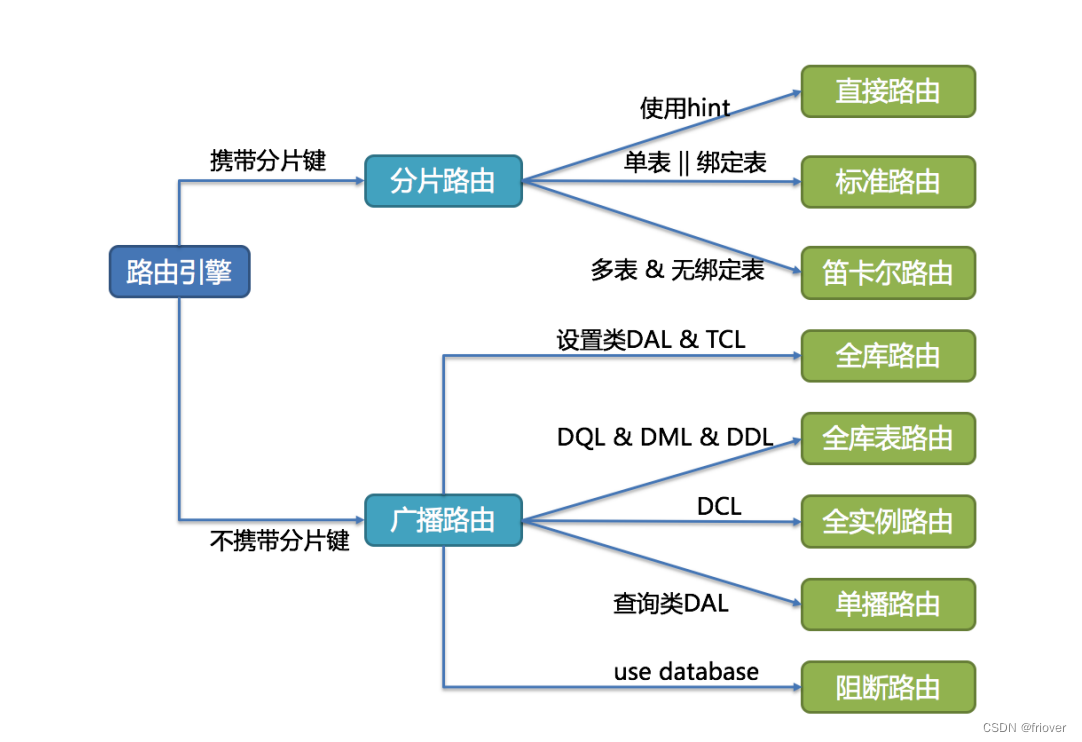
2、SQL Router- SQL 路由引擎
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。对于携带分片键的 SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是 IN)和范围路由(分片键
的操作符是 BETWEEN)。不携带分片键的 SQL 则采用广播路由。
分片策略通常可以采用由数据库内置或由用户方配置。数据库内置的方案较为简单,内置的分片策略大致可分为尾数取模、哈希、范围、标签、时间等。由用户方配置的分片策略则更加灵活,可以根据使用方需求定制复合分片策略。

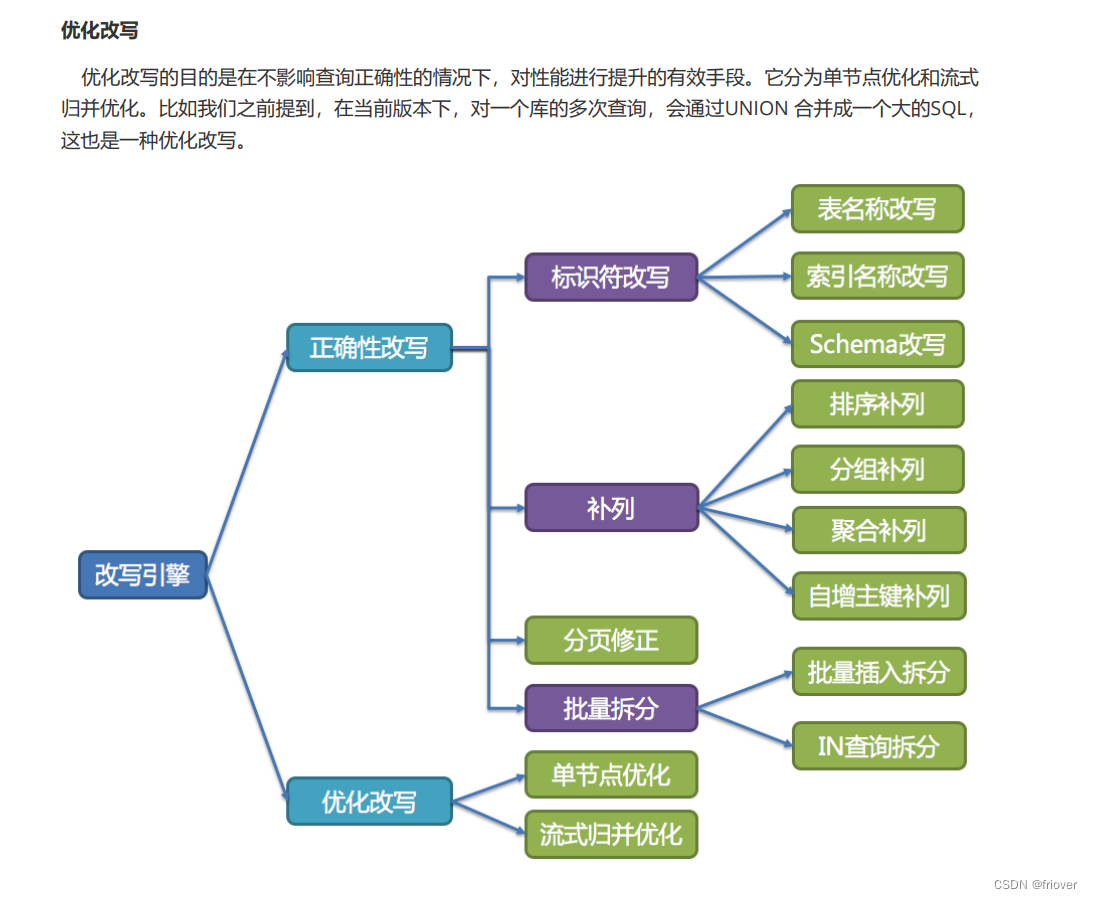
3、SQL Rewriter : SQL 优化引擎
首先,在数据方言方面。Apache ShardingSphere 提供了 SQL 方言翻译的能力,能否实现数据库方言之间的自动转换。例如,用户可以使用 MySQL 客户端连接 ShardingSphere 并发送基于 MySQL 方言的SQL,ShardingSphere 能自动识别用户协议与存储节点类型自动完成 SQL 方言转换,访问 PostgreSQL 等异构存储节点
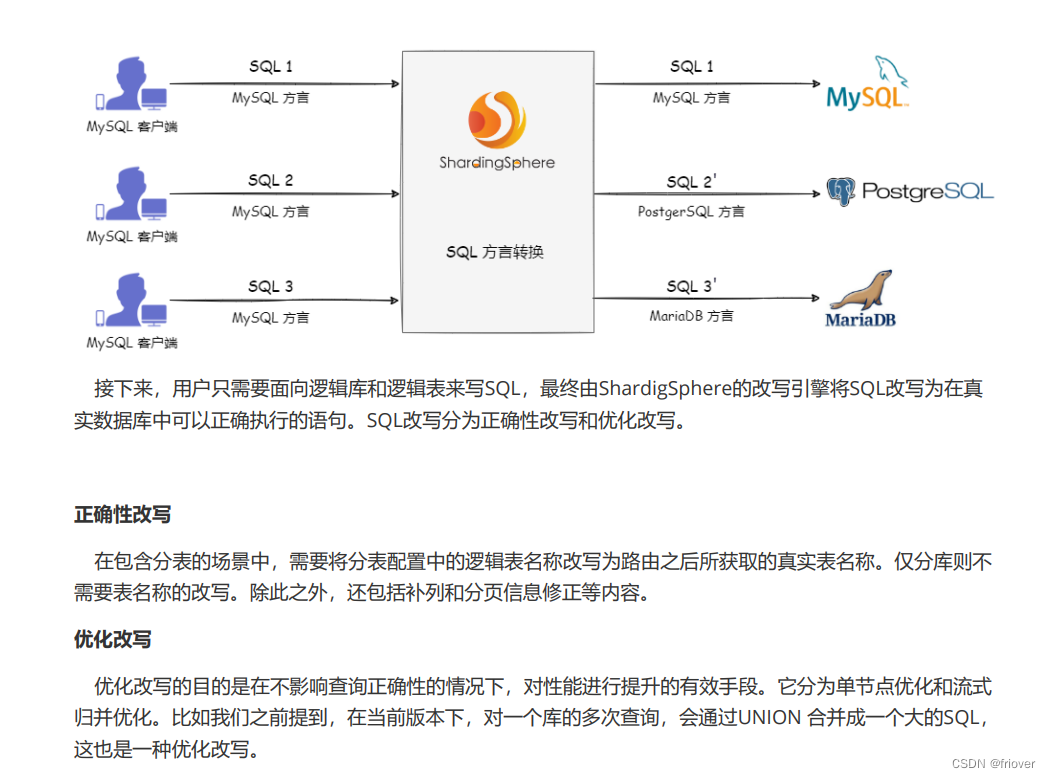
4、SQL Executor : SQL执行引擎
ShardingSphere 采用一套自动化的执行引擎,负责将路由和改写完成之后的真实 SQL 安全且高效发送到底层数据源执行。它不是简单地将 SQL 通过 JDBC 直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。执行引擎的目标是自动化的平衡资源控制与执行效率。
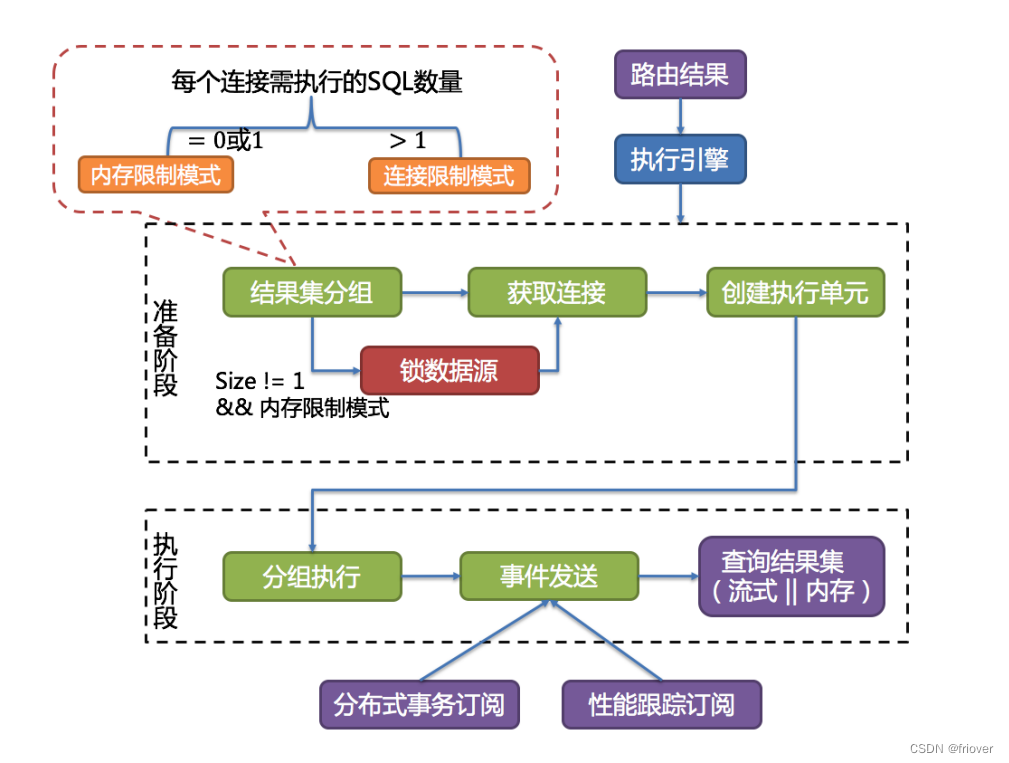
这里主要是理解内存限制模式和连接限制模式。简单理解
- 内存限制模式只需要保持一个JDBC连接,单线程即可完成某一个真实库的所有数据访问。
- 连接限制模式就需要保持多个JDBC连接,也就需要多线程并发完成某一个真实库的所有数据访问。
5、Result Merger: 结果归并
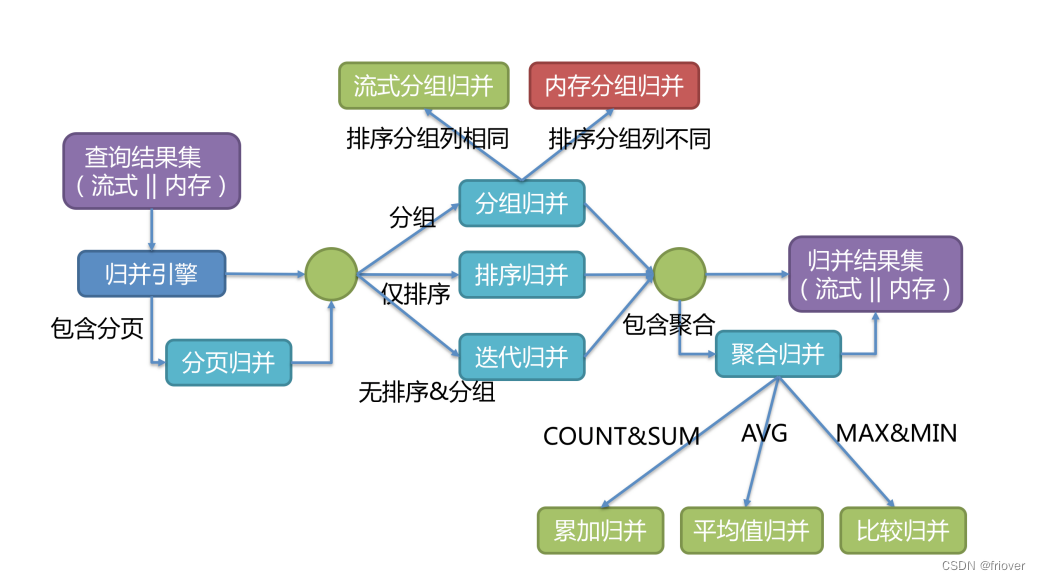
- 流式归并是指每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种。通常内存限制模式就可以使用流式归并,比较适合OLTP场景
- 内存归并则是需要将结果集的所有数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回。。通常连接限制模式就可以使用内存归并,比较适合OLAP场景。








![C国演义 [第四章]](https://img-blog.csdnimg.cn/fe8be4c13ca342d8a694a40fb0891f08.png)