前言
ClickHouse广泛用于用户和系统日志查询场景中,主要针对于OLAP场景,为业务方提供稳定高效的查询服务。在业务场景下,数据以不同的格式、途径写入到clickhouse。用传统JOIN方式查询海量数据,通常有如下痛点:
-
每个查询的代码冗长,有的长达1500行、2000行sql,使用和理解上特别痛苦
-
性能上无法满足业务诉求,数据量大会内存不足;
-
事实表就一张,可是维度表却有多张,关联数据量暴增
-
重复计算
如何将这些数据进行整合,以类似ClickHouse宽表的方式呈现给上层使用,用户可以在一张表中查到所需的所有指标,避免提供多表带来的代码复杂度和性能开销问题?
这里将重点介绍如何通过物化视图有效解决上述场景的问题。在介绍之前,先看一下什么是物化视图,以及如何创建、使用,如何增加维度和指标,结合字典增维等场景。
原理篇
物化视图
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db].[table]] [ENGINE = engine] [POPULATE] AS SELECT ...注意事项
-
创建不带[[db].[table]]的物化视图时,必须指定ENGINE。
-- 创建本地表
CREATE TABLE download (
when DateTime,
userid UInt32,
bytes Float32
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (userid, when);
-- 往本地表插入数据
INSERT INTO download
SELECT
now() + number * 60 as when,
25,
rand() % 100000000
FROM system.numbers
LIMIT 5000;
-- 创建物化视图
CREATE MATERIALIZED VIEW download_daily_mv
ENGINE = SummingMergeTree -- 指定engine
PARTITION BY toYYYYMM(day) ORDER BY (userid, day)
POPULATE
AS SELECT
toStartOfDay(when) AS day,
userid,
count() as downloads,
sum(bytes) AS bytes
FROM download
GROUP BY userid, day
-- 查询物化视图
SELECT * FROM download_daily_mv
ORDER BY day, userid
LIMIT 5
SELECT
toStartOfMonth(day) AS month,
userid,
sum(downloads),
sum(bytes)
FROM download_daily_mv
GROUP BY userid, month WITH TOTALS
ORDER BY userid, month-
使用[[db].[table]]的物化视图时,官方推荐不使用POPULTE
-
若使用POPULATE,会将现有的数据插入到表中
-
不使用POPULATE,查询仅包含创建视图后插入表中的数据
-
不推荐使用理由:官方说明是因为在创建视图期间插入表中的数据不会插入其中
-
对于实际业务场景来说,历史数据不可少,可以通过查询条件方式进行数据同步
-
--明细表
CREATE TABLE counter (
when DateTime DEFAULT now(),
device UInt32,
value Float32
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (device, when)
--插入模拟数据
INSERT INTO counter
SELECT
toDateTime('2023-06-19 00:00:00') + toInt64(number/10) AS when,
(number % 10) + 1 AS device,
(device * 3) + (number/10000) + (rand() % 53) * 0.1 AS value
FROM system.numbers LIMIT 1000000
--目标表(统计表)
CREATE TABLE counter_daily (
day DateTime,
device UInt32,
count UInt64,
max_value_state AggregateFunction(max, Float32),
min_value_state AggregateFunction(min, Float32),
avg_value_state AggregateFunction(avg, Float32)
)
ENGINE = SummingMergeTree()
PARTITION BY tuple()
ORDER BY (device, day)
--创建视图,注意通过条件解决新旧数据
CREATE MATERIALIZED VIEW counter_daily_mv
TO counter_daily -- 无须指定engine,跟表engine一致
AS SELECT
toStartOfDay(when) as day,
device,
count(*) as count,
maxState(value) AS max_value_state,
minState(value) AS min_value_state,
avgState(value) AS avg_value_state
FROM counter
WHERE when >= toDate('2023-06-19 00:00:00')
GROUP BY device, day
ORDER BY device, day
--视图创建后,插入新数据
INSERT INTO counter
SELECT
toDateTime('2023-06-19 00:00:00') + toInt64(number/10) AS when,
(number % 10) + 1 AS device,
(device * 3) + (number / 10000) + (rand() % 53) * 0.1 AS value
FROM system.numbers LIMIT 1000000
--视图创建后,插入历史数据
INSERT INTO counter_daily
SELECT
toStartOfDay(when) as day,
device,
count(*) AS count,
maxState(value) AS max_value_state,
minState(value) AS min_value_state,
avgState(value) AS avg_value_state
FROM counter
WHERE when < toDateTime('2023-06-19 00:00:00')
GROUP BY device, day
ORDER BY device, day
--查询数据(查询目标表与查询物化视图是一样的)
SELECT
device,
sum(count) AS count,
maxMerge(max_value_state) AS max,
minMerge(min_value_state) AS min,
avgMerge(avg_value_state) AS avg
FROM counter_daily
GROUP BY device
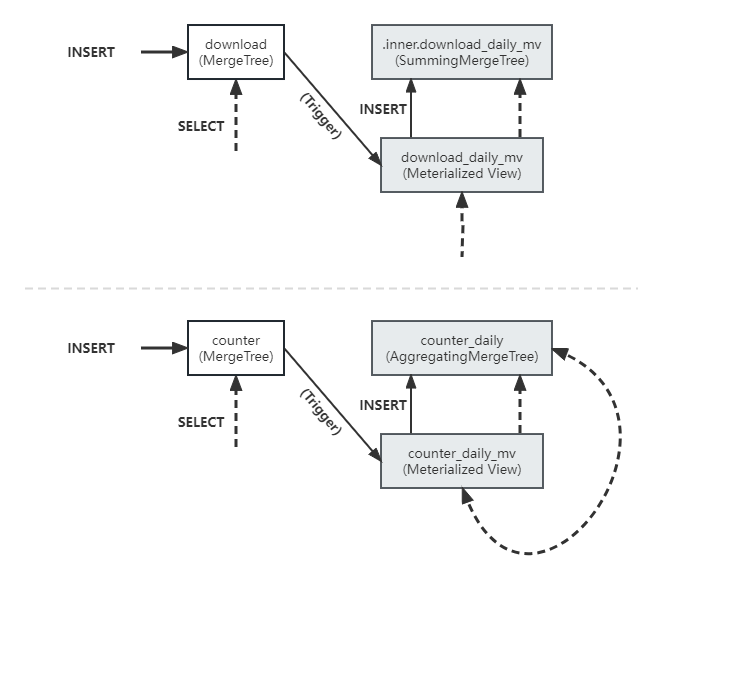
ORDER BY device ASC源表、物化视图、目标表的关系
结论
-
物化视图是源表的查询结果集的一份持久化存储,用于报告聚合数据和解析
-
产生物化视图的过程就叫做“物化”(materialization),如 as select ... from ...
-
物化视图是数据库中的预计算逻辑+显式缓存,典型的空间换时间思路
物化视图工作原理
-
当向SELECT中指定的源表插入了新行时,这些新行也会发送到该源表的所有物化视图,类似插入触发器,但是同步时机上受限于更新策略
-
数据更新策略:
-
设置刷新机制:ALTER MATERIALIZED VIEW my_view; UPDATE EVERY 1 HOUR;
-
使用视图前手动刷新视图,触发同步,保证数据准确性:REFRESH MATERIALIZED VIEW my_view;
-
创建视图时配置:SETTINGS refresh_interval = 3600,单位秒;0:表示禁用自动刷新;>0:表示间隔多久自动刷新;效果同 UPDATE EVERY 1 HOUR;
-
-
历史数据同步策略:
-
全量数据同步,通过查询条件控制:WHERE when < toDateTime('2023-06-19 00:00:00')
-
设置数据过期时间,保证数据一致性: TTL 30 DAYS
-
手动清理过期数据,保证数据一致性:CLEANUP TTL my_view IN blocking;注意:可能会导致一定的服务停止时间或查询延迟
-
-
-
相对于物化视图,插入不是原子的。因此:同步执行对物化视图的插入,并非所有物化视图都已完全更新并可用于查询
-
链式/级联物化视图的插入也是非原子的,同上
-
对源表现有数据的任何更改(如更新、删除、删除分区等)都不会更改物化视图。
-
代码导航,感兴趣可源码走读
1. 添加视图 OutputStream, InterpreterInsertQuery.cpp (https://github.com/ClickHouse/ClickHouse/blob/cb4644ea6d04b3d5900868b4f8d686a03082379a/src/Interpreters/InterpreterInsertQuery.cpp#L313)
if (table->noPushingToViews() && !no_destination) out = table->write(query_ptr, metadata_snapshot, context); else out = std::make_shared<PushingToViewsBlockOutputStream>(table, metadata_snapshot, context, query_ptr, no_destination);2.构造 Insert , PushingToViewsBlockOutputStream.cpp (https://github.com/ClickHouse/ClickHouse/blob/cb4644ea6d04b3d5900868b4f8d686a03082379a/src/DataStreams/PushingToViewsBlockOutputStream.cpp#L85)
ASTPtr insert_query_ptr(insert.release()); InterpreterInsertQuery interpreter(insert_query_ptr, *insert_context); BlockIO io = interpreter.execute(); out = io.out;3.物化新增数据:PushingToViewsBlockOutputStream.cpp (https://github.com/ClickHouse/ClickHouse/blob/cb4644ea6d04b3d5900868b4f8d686a03082379a/src/DataStreams/PushingToViewsBlockOutputStream.cpp#L331)
Context local_context = *select_context; local_context.addViewSource( StorageValues::create( storage->getStorageID(), metadata_snapshot->getColumns(), block, storage->getVirtuals())); select.emplace(view.query, local_context, SelectQueryOptions()); in = std::make_shared<MaterializingBlockInputStream>(select->execute().getInputStream()
使用篇
背景
在实际使用中,经常遇到一个维度关联的问题,比如将物品的类别、用户的画像信息等带入场景计算;这里简单列举下clickhouse中做维度补全的操作。模拟用户维度数据和物品维度数据生成字典(字典有很多种存储结构,这里主要列举hashed模式)
字典
--创建 用户维度数据 字典
CREATE DICTIONARY dim.dict_user_dim on cluster cluster (
uid UInt64 ,
platform String default '' ,
country String default '' ,
province String default '' ,
isp String default '' ,
app_version String default '' ,
os_version String default '',
mac String default '' ,
ip String default '',
gender String default '',
age Int16 default -1
) PRIMARY KEY uid
SOURCE(
CLICKHOUSE(
HOST 'localhost' PORT 9000 USER 'default' PASSWORD '' DB 'dim' TABLE 'user_dim_dis'
)
) LIFETIME(MIN 1800 MAX 3600) LAYOUT(HASHED());
--创建 物品维度数据 字典
CREATE DICTIONARY dim.dict_item_dim on cluster cluster (
item_id UInt64 ,
type_id UInt32 default 0,
price UInt32 default 0
) PRIMARY KEY item_id
SOURCE(
CLICKHOUSE(
HOST 'localhost' PORT 9000 USER 'default' PASSWORD '' DB 'dim' TABLE 'item_dim_dis'
)
) LIFETIME(MIN 1800 MAX 3600) LAYOUT(HASHED())注意事项
-
语法不做详细介绍,想要更深了解可以参考官方文档
-
字典的数据是冗余在所有节点的,默认字典的加载方式是惰性加载,也就是需要至少一次查询才能将字典记载到内存,避免一些不使用的字典对集群带来影响。
-
也可以通过hash分片的方式将用户指定到某个shard,那么字典也可以实现通过hash分片的方式存储在每个节点,间接实现分布式字典,减少数据存储
使用方式
-
一种是通过dictGet;如果只查询一个key,建议使用dicGet,代码复杂可读性高,同时字典查的value可以作为另一个查询的key
-
另外一种方式是通过join
--单value方法1:
SELECT
dictGet('dim.dict_user_dim', 'platform', toUInt64(uid)) AS platform,
uniqCombined(uid) AS uv
FROM dws.user_product_dis
WHERE day = '2023-06-19'
GROUP BY platform
Query id: 52234955-2dc9-4117-9f2a-45ab97249ea7
┌─platform─┬───uv─┐
│ android │ 9624 │
│ ios │ 4830 │
└──────────┴──────┘
2 rows in set. Elapsed: 0.009 sec. Processed 49.84 thousand rows, 299.07 KB (5.37 million rows/s., 32.24 MB/s.)
--多value方法1:
SELECT
dictGet('dim.dict_user_dim', 'platform', toUInt64(uid)) AS platform,
dictGet('dim.dict_user_dim', 'gender', toUInt64(uid)) AS gender,
uniqCombined(uid) AS uv
FROM dws.user_product_dis
WHERE day = '2023-06-19'
GROUP BY
platform,
gender
Query id: ed255ee5-9036-4385-9a51-35923fef6e48
┌─platform─┬─gender─┬───uv─┐
│ ios │ 男 │ 2236 │
│ android │ 女 │ 4340 │
│ android │ 未知 │ 941 │
│ android │ 男 │ 4361 │
│ ios │ 女 │ 2161 │
│ ios │ 未知 │ 433 │
└──────────┴────────┴──────┘
6 rows in set. Elapsed: 0.011 sec. Processed 49.84 thousand rows, 299.07 KB (4.70 million rows/s., 28.20 MB/s.)
--单value方法2:
SELECT
t2.platform AS platform,
uniqCombined(t1.uid) AS uv
FROM dws.user_product_dis AS t1
INNER JOIN dim.dict_user_dim AS t2 ON toUInt64(t1.uid) = t2.uid
WHERE day = '2023-06-19'
GROUP BY platform
Query id: 8906e637-475e-4386-946e-29e1690f07ea
┌─platform─┬───uv─┐
│ android │ 9624 │
│ ios │ 4830 │
└──────────┴──────┘
2 rows in set. Elapsed: 0.011 sec. Processed 49.84 thousand rows, 299.07 KB (4.55 million rows/s., 27.32 MB/s.)
--多value方法2:
SELECT
t2.platform AS platform,
t2.gender AS gender,
uniqCombined(t1.uid) AS uv
FROM dws.user_product_dis AS t1
INNER JOIN dim.dict_user_dim AS t2 ON toUInt64(t1.uid) = t2.uid
WHERE day = '2023-06-19'
GROUP BY
platform,
gender
Query id: 88ef55a6-ddcc-42f8-8ce3-5e3bb639b38a
┌─platform─┬─gender─┬───uv─┐
│ ios │ 男 │ 2236 │
│ android │ 女 │ 4340 │
│ android │ 未知 │ 941 │
│ android │ 男 │ 4361 │
│ ios │ 女 │ 2161 │
│ ios │ 未知 │ 433 │
└──────────┴────────┴──────┘
6 rows in set. Elapsed: 0.015 sec. Processed 49.84 thousand rows, 299.07 KB (3.34 million rows/s., 20.07 MB/s.)结论
从查询结果来看,dictGet要更快一些,同时在代码可读性上也要更好一些,可以结合场景使用。
-
如果在业务开发过程中,遗漏了维度或者指标,则可以通过修改字典和视图来实现,实现方式
-- 新增字典维度
alter table dim.dict_user_dim on cluster cluster modify column if exists gender String default '未知' comment '性别' after item_id;
-- 修改物化视图
alter table my_view_table on cluster cluster_name add column if not exists new_measure AggregateFunction(uniqCombined,UInt32) comment 'new_measure';实践经验
-
如果业务表有较频繁的删除或修改,物化视图本地表的引擎需要使用CollapsingMergeTree或VersionedCollapsingMergeTree
-
如果物化视图是由两表join产生的,则仅有在左表插入数据时才更新。如果只有右表插入数据,则不更新
--创建本地表
CREATE TABLE IF NOT EXISTS ods.click_log_local
ON CLUSTER cluster_01 (
click_date Date,
click_time DateTime,
user_id Int64,
event_type String,
city_id Int64,
product_id Int64
)
ENGINE = ReplicatedMergeTree('/ch/tables/ods/click_log/{shard}','{replica}')
PARTITION BY click_date
ORDER BY (click_date,toStartOfHour(click_time),city_id,event_type)
TTL click_date + INTERVAL 1 MONTH
SETTINGS index_granularity = 8192,
use_minimalistic_part_header_in_zookeeper = 1,
merge_with_ttl_timeout = 86400;
--创建分布式表
CREATE TABLE IF NOT EXISTS ods.click_log_all
ON CLUSTER cluster_01 AS ods.click_log_local
ENGINE = Distributed(cluster_01,ods,click_log_local,rand());--创建本地表
CREATE MATERIALIZED VIEW IF NOT EXISTS ods.city_product_stat_local
ON CLUSTER cluster_01
ENGINE = ReplicatedSummingMergeTree('/ch/tables/ods/city_product_stat/{shard}','{replica}')
PARTITION BY click_date
ORDER BY (click_date,ts_hour,city_id,product_id)
SETTINGS index_granularity = 8192, use_minimalistic_part_header_in_zookeeper = 1
AS SELECT
click_date,
toStartOfHour(click_time) AS ts_hour,
city_id,
product_id,
count() AS visit
FROM ods.click_log_local
GROUP BY click_date,ts_hour,city_id,product_id;
--创建分布式表
CREATE TABLE IF NOT EXISTS ods.city_product_stat_all
ON CLUSTER cluster_01 AS ods.city_product_stat_local
ENGINE = Distributed(cluster_01,ods,city_product_stat_local,rand());--在查询前针对指定分区,手工触发merge
optimize table city_product_stat_local on cluster cluster_01
partition '2021-12-01' FINAL DEDUPLICATE by click_date,ts_hour,city_id,product_id
select * from city_product_stat_all mspsa order by click_date 参考链接
https://clickhouse.com/docs/en/sql-reference/statements/create/view#materialized-view
https://clickhouse.com/docs/knowledgebase/are_materialized_views_inserted_asynchronously
https://clickhouse.com/docs/en/guides/developer/cascading-materialized-views
https://clickhouse.com/docs/en/operations/settings/settings#wait-for-async-insert
https://clickhouse.com/docs/en/operations/settings/settings#optimize-on-insert
https://clickhouse.com/docs/en/integrations/data-formats/json#using-materialized-views
https://clickhouse.com/docs/en/whats-new/changelog/2020#bug-fix-27