概要
本文简单理顺《Differentially Private Distributed Principal Component Analysis》论文中的算法原理,它主要提出了一种基于差分隐私的分布式PCA算法,研究了该算法在实验数据以及真实数据中的表现,在参数相同的情况下本算法取得了和没有隐私保护的算法相同级别的效果。
算法原理
一些数学公式上的符号定义:
1、
S
S
S表示分布式中有
S
S
S个站点;
2、每个站点的数据集
D
×
N
s
D\times N_s
D×Ns其中
s
∈
[
S
]
s \in [S]
s∈[S]表示有
D
D
D维
N
s
N_s
Ns个样本量,样本集表示成
X
s
=
[
x
s
,
1
,
x
s
,
2
,
.
.
.
,
x
s
,
N
s
]
X_s=[x_{s,1},x_{s,2},...,x_{s,N_s}]
Xs=[xs,1,xs,2,...,xs,Ns];
3、并且样本集的样本满足对
∀
n
∈
[
N
s
]
\forall n \in [N_s]
∀n∈[Ns]都有
∣
∣
x
s
,
n
∣
∣
2
≤
1
,
∀
s
∈
[
S
]
||x_{s,n}||_2 \le 1, \forall s \in [S]
∣∣xs,n∣∣2≤1,∀s∈[S],简单说就是观察样本符合均值中心化;
4、每个站点的协方差矩阵:
A
s
=
1
N
s
X
s
X
s
T
A_s=\frac{1}{N_s}X_sX_s^T
As=Ns1XsXsT;
5、各站点的总样本数:
N
=
∑
s
=
1
S
N
s
N=\sum_{s=1}^SN_s
N=∑s=1SNs,整体样本:
X
=
[
X
1
,
X
2
,
.
.
.
,
X
S
]
∈
R
D
×
N
X=[X_1,X_2,...,X_{S}] \in \R^{D\times N}
X=[X1,X2,...,XS]∈RD×N,整体样本的协方差:
A
=
1
N
X
X
T
A=\frac{1}{N}XX^T
A=N1XXT
PCA和差分隐私的简单介绍参见:https://blog.csdn.net/superY_26/article/details/131140813
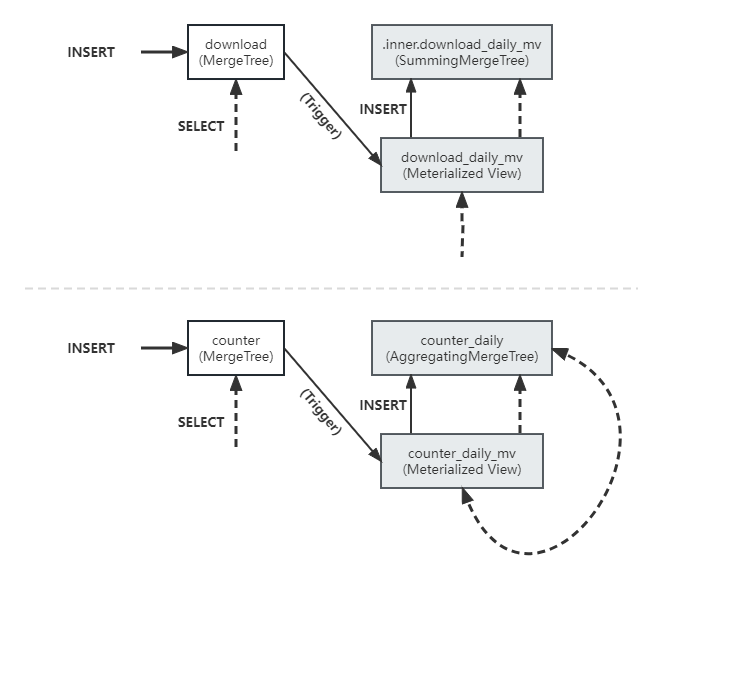
DPdisPCA算法的逻辑如下图:

1、计算各站点的协方差 A s A_s As
2、生成服从 N ( 0 , τ 2 ) N(0,τ^2) N(0,τ2)分布 τ = 1 N s ϵ 2 l o g ( 1.25 δ ) τ=\frac{1}{N_s\epsilon} \sqrt{2log(\frac{1.25}{\delta})} τ=Nsϵ12log(δ1.25)的随机噪声 E E E
3、将协方差加入噪声 A s ^ = A s + E \hat{A_s}=A_s+E As^=As+E
4、求协方差的SVD: A s ^ = U Σ U T \hat{A_s}=U\Sigma U^T As^=UΣUT
5、 计算 P s = U R Σ R 1 2 , ( K < R < < D ) P_s=U_R\Sigma_R^{\frac{1}{2}}, \scriptsize (K<R<<D) Ps=URΣR21,(K<R<<D),并将其发送给aggregator。
循环外则是aggregator的操作:
1、整合每个站点发过来的
P
s
P_s
Ps:
A
c
=
1
S
∑
s
=
1
S
P
s
P
s
T
A_c=\frac{1}{S}\sum_{s=1}^SP_sP_s^T
Ac=S1∑s=1SPsPsT
2、求
A
c
A_c
Ac的SVD:
A
c
=
V
Λ
V
T
A_c=V\Lambda V^T
Ac=VΛVT
3、按特征值排序去top K的特征向量得到
V
K
V_K
VK
算法中各站点为什么发送 P s P_s Ps给aggregator?
【原因】算法中对于各站点发送截断的P_s是因为考虑通信成本的问题,降低通信量,提升性能。
最好的发送加入噪声的协方差 A s ^ \hat {A_s} As^进行汇总,然后求SVD值。这个被证明效果会更好。
实验结果





![C国演义 [第四章]](https://img-blog.csdnimg.cn/fe8be4c13ca342d8a694a40fb0891f08.png)