目录
- hash类型命令
- hset
- hget
- hmset
- hmget
- hgetall
- hsetnx
- hdel
- hexits
- hincrby与hincrbyfloat
- hkeys与hvals
- hlen
- hstrlen
- 有序set型命令
- zadd
- zrange 与zrevrange
- zrangebyscore与zrevrangebyscore
- zcard
- zcount
- zscore
- zincrby
- zrank 与 zrevrank
- zrem
- zremrangebyrank
- zremrangebyscore
- zrangebylex
- zlexcount
- zremrangebylex
- Hash与ZSet的底层数据结构
- 压缩列表zipList与redis7.0的listPack
- ziplist
- head
- entries
- entry
- end
- listPack
- head
- entries
- entry
- end
- 跳跃列表skipList
hash类型命令
hset
格式:HSET key field value
功能:将哈希表 key 中的域 field 的值设为 value 。
说明:如果 key 不存在,一个新的哈希表被创建并进行 HSET 操作。如果域 field 已
经存在于哈希表中,旧值将被覆盖。如果 field 是哈希表中的一个新建域,并且值设置
成功,返回 1 。如果哈希表中域 field 已经存在且旧值已被新值覆盖,返回0。
hget
格式:HGET key field
功能:返回哈希表 key 中给定域 field 的值。
说明:当给定域不存在或是给定 key 不存在时,返回 nil 。
hmset
格式:HMSET key field value [field value …]
功能:同时将多个 field-value (域-值)对设置到哈希表 key 中。
说明:此命令会覆盖哈希表中已存在的域。如果 key 不存在,一个空哈希表被创建并执行 HMSET 操作。如果命令执行成功,返回 OK 。当 key 不是哈希表(hash)类型时,返回一个错误。
hmget
格式:HMGET key field [field …]
功能:按照给出顺序返回哈希表 key 中一个或多个域的值。
说明:如果给定的域不存在于哈希表,那么返回一个 nil 值。因为不存在的 key 被当作一个空哈希表来处理,所以对一个不存在的 key 进行 HMGET 操作将返回一个只带有 nil 值的表。
hgetall
格式:HGETALL key
功能:返回哈希表 key 中所有的域和值。
说明:在返回值里,紧跟每个域名(field name)之后是域的值(value),所以返回值的长度是哈希表大小的两倍。若 key 不存在,返回空列表。若 key 中包含大量元素,则该命令可能会阻塞 Redis 服务。所以生产环境中一般不使用该命令,而使用 hscan 命令代替。
hsetnx
格式:HSETNX key field value
功能:将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在。
说明:若域 field 已经存在,该操作无效。如果 key 不存在,一个新哈希表被创建并执行 HSETNX 命令。
hdel
格式:HDEL key field [field …]
功能:删除哈希表 key 中的一个或多个指定域,不存在的域将被忽略。
说明:返回被成功移除的域的数量,不包括被忽略的域。
hexits
格式:HEXISTS key field
功能:查看哈希表 key 中给定域 field 是否存在。
说明:如果哈希表含有给定域,返回 1 。如果不含有给定域,或 key 不存在,返回 0 。
hincrby与hincrbyfloat
格式:HINCRBY key field increment
功能:为哈希表 key 中的域 field 的值加上增量 increment 。hincrby 命令只能增加整数值,而 hincrbyfloat 可以增加小数值。
说明:增量也可以为负数,相当于对给定域进行减法操作。如果 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。如果域 field 不存在,那么在执行命令前,域的值被初始化为 0。对一个储存字符串值的域 field 执行 HINCRBY 命令将造成一个错误。
hkeys与hvals
格式:HKEYS key 或 HVALS key
功能:返回哈希表 key 中的所有域/值。
说明:当 key 不存在时,返回一个空表。
hlen
格式:HLEN key
功能:返回哈希表 key 中域的数量。
说明:当 key 不存在时,返回 0 。
hstrlen
格式:HSTRLEN key field
功能:返回哈希表 key 中, 与给定域 field 相关联的值的字符串长度(string length)。
说明:如果给定的键或者域不存在, 那么命令返回 0 。
有序set型命令
zadd
格式:ZADD key score member [[score member] [score member] …]
功能:将一个或多个 member 元素及其 score 值加入到有序集 key 中的适当位置。
说明:score 值可以是整数值或双精度浮点数。如果 key 不存在,则创建一个空的有序集并执行 ZADD 操作。当 key 存在但不是有序集类型时,返回一个错误。如果命令执行成功,则返回被成功添加的新成员的数量,不包括那些被更新的、已经存在的成员。若写入的 member 值已经存在,但 score 值不同,则新的 score 值将覆盖老 score。
zrange 与zrevrange
格式:ZRANGE key start stop [WITHSCORES] 或 ZREVRANGE key start stop [WITHSCORES]
功能:返回有序集 key 中,指定区间内的成员。zrange 命令会按 score 值递增排序,zrevrange命令会按score递减排序。具有相同 score 值的成员按字典序/逆字典序排列。可以通过使用WITHSCORES 选项,来让成员和它的 score 值一并返回。
说明:下标参数从 0 开始,即 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。也可以使用负数下标,-1 表示最后一个成员,-2 表示倒数第二个成员,以此类推。超出范围的下标并不会引起错误。例如,当 start 的值比有序集的最大下标还要大,或是 start > stop 时,ZRANGE 命令只是简单地返回一个空列表。再比如 stop 参数的值比有序集的最大下标还要大,那么 Redis 将 stop 当作最大下标来处理。
若 key 中指定范围内包含大量元素,则该命令可能会阻塞 Redis 服务。所以生产环境中如果要查询有序集合中的所有元素,一般不使用该命令,而使用 zscan 命令代替。
zrangebyscore与zrevrangebyscore
格式:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
功能:返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或max )的成员。有序集成员按 score 值递增/递减次序排列。具有相同 score 值的成员按字典序/逆字典序排列。可选的 LIMIT 参数指定返回结果的数量及区间(就像 SQL 中的SELECT LIMIT offset, count ),注意当 offset 很大时,定位 offset 的操作可能需要遍历整个有序集,此过程效率可能会较低。可选的 WITHSCORES 参数决定结果集是单单返回有序集的成员,还是将有序集成员及其 score 值一起返回。
说明:min 和 max 的取值是正负无穷大的。默认情况下,区间的取值使用闭区间 (小于等于或大于等于),也可以通过给参数前增加左括号“(”来使用可选的开区间 (小于或大于)。
zcard
格式:ZCARD key
功能:返回集合的长度
说明:当 key 不存在时,返回 0 。
zcount
格式:ZCOUNT key min max
功能:返回有序集 key 中,score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量。
zscore
格式:ZSCORE key member
功能:返回有序集 key 中,成员 member 的 score 值。
说明:如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil 。
zincrby
格式:ZINCRBY key increment member
功能:为有序集 key 的成员 member 的 score 值加上增量 increment 。increment 值可以是整数值或双精度浮点数。
说明:可以通过传递一个负数值 increment ,让 score 减去相应的值。当 key 不存在,或 member 不是 key 的成员时, ZINCRBY key increment member 等同于 ZADD key increment member 。当 key 不是有序集类型时,返回一个错误。命令执行成功,则返回 member 成员的新 score 值。
zrank 与 zrevrank
格式:ZRANK key member 或 ZREVRANK key member
功能:返回有序集 key 中成员 member 的排名。zrank 命令会按 score 值递增排序,zrevrank 命令会按 score 递减排序。
说明:score 值最小的成员排名为 0 。如果 member 不是有序集 key 的成员,返回 nil 。
zrem
格式:ZREM key member [member …]
功能:移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
说明:当 key 存在但不是有序集类型时,返回一个错误。执行成功,则返回被成功移除的成员的数量,不包括被忽略的成员。
zremrangebyrank
格式:ZREMRANGEBYRANK key start stop
功能:移除有序集 key 中,指定排名(rank)区间内的所有成员。
说明:排名区间分别以下标参数 start 和 stop 指出,包含 start 和 stop 在内。排名区间参数从 0 开始,即 0 表示排名第一的成员, 1 表示排名第二的成员,以此类推。也可以使用负数表示,-1 表示最后一个成员,-2 表示倒数第二个成员,以此类推。命令执行成功,则返回被移除成员的数量。
zremrangebyscore
格式:ZREMRANGEBYSCORE key min max
功能:移除有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或max )的成员。
说明:命令执行成功,则返回被移除成员的数量。
zrangebylex
格式:ZRANGEBYLEX key min max [LIMIT offset count]
功能:该命令仅适用于集合中所有成员都具有相同分值的情况。当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的字典序(lexicographical ordering)来进行排序。即这个命令返回给定集合中元素值介于 min 和 max 之间的成员。如果有序集合里面的成员带有不同的分值, 那么命令的执行结果与 zrange key 效果相同。
说明:合法的 min 和 max 参数必须包含左小括号“(”或左中括号“[”,其中左小括号“(”表示开区间, 而左中括号“[”则表示闭区间。min 或 max 也可使用特殊字符“+”和“-”,分别表示正无穷大与负无穷大。
zlexcount
格式:ZLEXCOUNT key min max
功能:该命令仅适用于集合中所有成员都具有相同分值的情况。该命令返回该集合中元素值本身(而非 score 值)介于 min 和 max 范围内的元素数量。
zremrangebylex
格式:ZREMRANGEBYLEX key min max
功能:该命令仅适用于集合中所有成员都具有相同分值的情况。该命令会移除该集合中元素值本身介于 min 和 max 范围内的所有元素。
Hash与ZSet的底层数据结构
用户写入不同的数据,系统会自动使用不同的实现。只有同时满足以配置文件 redis.conf 中相关集合元素数量阈值与元素大小阈值两个条件,使用的就是压缩列表 zipList,只要有一个条件不满足使用的就是跳跃列表 skipList。
例如,对于ZSet 集合中这两个条件如下:
-
集合元素个数小于 redis.conf 中 zset-max-ziplist-entries 属性的值,其默认值为 128
-
每个集合元素大小都小于 redis.conf 中 zset-max-ziplist-value 属性的值,其默认值为 64字节
这些值可以设置,如果设置超过ziplist两字节,表示元素个数的变量就失去了意义。只能通过遍历来确定元素个数了。
压缩列表zipList与redis7.0的listPack
ziplist
zipList,通常称为压缩列表,是一个经过特殊编码的用于存储字符串或整数的双向链表。其底层数据结构由三部分构成:head、entries 与 end。这三部分在内存上是连续存放的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TLumo2OU-1670316760581)(redis.assets/image-20221206155303071.png)]](https://img-blog.csdnimg.cn/a207adef6bf14b659b82db4c61ea765a.png)
head
head 又由三部分构成:
-
zlbytes:占 4 个字节,用于存放 zipList 列表整体数据结构所占的字节数,包括 zlbytes本身的长度。
-
zltail:占 4 个字节,用于存放 zipList 中最后一个 entry 在整个数据结构中的偏移量(字节)。该数据的存在可以快速定位列表的尾 entry 位置,以方便操作。
-
zllen:占 2 字节,用于存放列表包含的 entry 个数。由于其只有 16 位,所以 zipList 最多可以含有的 entry 个数为 2 16 -1 = 65535 个。
entries
entries 是真正的列表,由很多的列表元素 entry 构成。由于不同的元素类型、数值的不同,从而导致每个 entry 的长度不同。
entry
entry 由三部分构成:
-
prevlength:该部分用于记录上一个 entry 的长度,以实现逆序遍历。默认长度为 1 字节,只要上一个 entry 的长度<254 字节,prevlength 就占 1 字节,否则其会自动扩展为 3 字节长度。
-
encoding:该部分用于标志后面的 data 的具体类型。如果 data 为整数类型,encoding固定长度为 1 字节。如果 data 为字符串类型,则 encoding 长度可能会是 1 字节、2 字节或 5 字节。data 字符串不同的长度,对应着不同的 encoding 长度。(固定长度的1字节前两位用来表示是整型还是字符串类型,后六位表示多少字节的整型)
-
data:真正存储的数据。数据类型只能是整数类型或字符串类型。不同的数据占用的字节长度不同。
end
end 只包含一部分,称为 zlend。占 1 个字节,值固定为 255,即二进制位为全 1,表示一个 zipList 列表的结束。
listPack
ziplist每个 entry 中包含前一个 entry 的长度,这样会导致在 ziplist 中间修改或者插入 entry 时需要进行级联更新,也就是类似连锁反应其他值跟着变,影响效率。
在 Redis 7.0 中,已经将 zipList 全部替换为了 listPack,但为了兼容性,在配置中也保留了 zipList 的相关属性。
listPack 也是一个经过特殊编码的用于存储字符串或整数的双向链表。其底层数据结构也由三部分构成:head、entries 与 end,且这三部分在内存上也是连续存放的。
listPack与zipList的重大区别在head与每个entry的结构上,表示列表结束的end与zipList的 zlend 是相同的,占一个字节,且 8 位全为 1。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l3L8ryoq-1670316760582)(redis.assets/image-20221206161231252.png)]](https://img-blog.csdnimg.cn/68f4695beb274b9cbd7890d4944bf980.png)
head
head 由两部分构成:
-
totalBytes:占 4 个字节,用于存放 listPack 列表整体数据结构所占的字节数,包括totalBytes 本身的长度。
-
elemNum:占 2 字节,用于存放列表包含的 entry 个数。其意义与 zipList 中 zllen 的相同。
entries
与 zipList 的 entry 结构相比,listPack的 entry 结构发生了较大变化。最大的变化就是没有了记录前一个 entry 长度的 prevlength,而增加了记录当前entry 长度的 element-total-len。而这个改变仍然可以实现逆序遍历,但却避免了由于在列表中间修改或插入 entry 时引发的级联更新。
entry
entry 仍由三部分构成:
-
encoding:该部分用于标志后面的 data 的具体类型。如果 data 为整数类型,encoding长度可能会是 1、2、3、4、5 或 9 字节。不同的字节长度,其标识位不同。如果 data为字符串类型,则 encoding 长度可能会是 1、2 或 5 字节。data 字符串不同的长度,对应着不同的 encoding 长度。
-
data:真正存储的数据。数据类型只能是整数类型或字符串类型。不同的数据占用的字节长度不同。
-
element-total-len:该部分用于记录当前 entry 的长度,用于实现逆序遍历。由于其特殊的记录方式,使其本身占有的字节数据可能会是 1、2、3、4 或 5 字节。
end
end 只包含一部分,称为 zlend。占 1 个字节,值固定为 255,即二进制位为全 1,表示一个 zipList 列表的结束。
跳跃列表skipList
skipList,跳跃列表,简称跳表,是一种随机化的数据结构,基于并联的链表,实现简单,查找效率较高。简单来说跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能。也正是这个跳跃功能,使得在查找元素时,能够提供较高的效率。
skipList 采用了随机分配层级方式。即在确定了总层级后,每添加一个新的元素时会自动为其随机分配一个层级。这种随机性就解决了节点序号与层级间的固定关系问题。
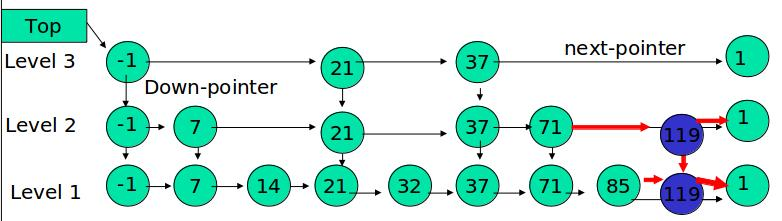
skipList 指的就是除了最下面第 1 层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针跳过了一些节点,并且越高层级的链表跳过的节点越多。在查找数据的时先在高层级链表中进行查找,然后逐层降低,最终可能会降到第 1 层链表来精确地确定数据位置。在这个过程中由于跳过了一些节点,从而加快了查找速度。




![[附源码]Python计算机毕业设计Django校园订餐系统](https://img-blog.csdnimg.cn/fb183291893647f988f0ab9c95bef7be.png)

![[附源码]Python计算机毕业设计Django校园运动会管理系统](https://img-blog.csdnimg.cn/3b9426cb92ee4597b741e30dcdd16e0c.png)