K-Means++代码实现
数据集
https://download.csdn.net/download/qq_43629083/87246495
import pandas as pd
import numpy as np
import random
import math
%matplotlib inline
from matplotlib import pyplot as plt
# 按文件名读取整个文件
data = pd.read_csv('data.csv')
class MyKmeansPlusPlus:
def __init__(self, k, max_iter = 10):
self.k = k
# 最大迭代次数
self.max_iter = max_iter
# 训练集
self.data_set = None
# 结果集
self.labels = None
'''
计算两点间的欧拉距离
'''
def euler_distance(self, point1, point2):
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
'''
计算样本中的每一个样本点与已经初始化的聚类中心之间的距离,并选择其中最短的距离
'''
def nearest_distance(self, point, cluster_centers):
min_distance = math.inf
dim = np.shape(cluster_centers)[0]
for i in range(dim):
# 计算point与每个聚类中心的距离
distance = self.euler_distance(point, cluster_centers[i])
# 选择最短距离
if distance < min_distance:
min_distance = distance
return min_distance
'''
初始化k个聚类中心
'''
def get_centers(self):
dim_m, dim_n = np.shape(self.data_set)
cluster_centers = np.array(np.zeros(shape = (self.k, dim_n)))
#随机初始化第一个聚类中心点
index = np.random.randint(0, dim_m)
cluster_centers[0] = self.data_set[index]
# 初始化一个距离序列
distances = [0.0 for _ in range(dim_m)]
for i in range(1, self.k):
print("i = ", i)
sum_all = 0.0
for j in range(dim_m):
# 对每一个样本找到最近的聚类中心点
distances[j] = self.nearest_distance(self.data_set[j], cluster_centers[0:i])
# 将所有最短距离相加
sum_all += distances[j]
# 取得sum_all之间的随机值
sum_all *= random.random()
# 以概率获得距离最远的样本点作为聚类中心
for id, dist in enumerate(distances):
sum_all -= dist
if sum_all > 0:
continue
cluster_centers[i] = self.data_set[id]
break;
return cluster_centers
'''
确定非中心点与哪个中心点最近
'''
def get_closest_index(self, point, centers):
# 初始值设为最大
min_dist = math.inf
label = -1
# enumerate() 函数同时列出数据和数据下标
for i, center in enumerate(centers):
dist = self.euler_distance(center, point)
if dist < min_dist:
min_dist = dist
label = i
return label
'''
更新中心点
'''
def update_centers(self):
# k类点分别存
points_label = [[] for i in range(self.k)]
for i, label in enumerate(self.labels):
points_label[label].append(self.data_set[i])
centers = []
for i in range(self.k):
centers.append(np.mean(points_label[i], axis = 0))
return centers
'''
判断是否停止迭代,新中心点与旧中心点一致或者达到设置的迭代最大值则停止
'''
def stop_iter(self, old_centers, centers, step):
if step > self.max_iter:
return True
return np.array_equal(old_centers, centers)
'''
模型训练
'''
def fit(self, data_set):
self.data_set = data_set.drop(['labels'], axis = 1)
self.data_set = np.array(self.data_set)
point_num = np.shape(data_set)[0]
# 初始化结果集
self.labels = data_set.loc[:, 'labels']
self.labels = np.array(self.labels)
# 初始化k个聚类中心点
centers = self.get_centers()
# 保存上一次迭代的中心点
old_centers = []
# 当前迭代次数
step = 0
flag = False
while not flag:
# 存储 旧的中心点
old_centers = np.copy(centers)
# 迭代次数+1
step += 1
print("current iteration: ", step)
print("current centers: ", old_centers)
# 本次迭代 各个点所属类别(即该点与哪个中心点最近)
for i, point in enumerate(self.data_set):
self.labels[i] = self.get_closest_index(point, centers)
# 更新中心点
centers = self.update_centers()
# 迭代是否停止的标志
flag = self.stop_iter(old_centers, centers, step)
centers = np.array(centers)
fig = plt.figure()
label0 = plt.scatter(self.data_set[:, 0][self.labels == 0], self.data_set[:, 1][self.labels == 0])
label1 = plt.scatter(self.data_set[:, 0][self.labels == 1], self.data_set[:, 1][self.labels == 1])
label2 = plt.scatter(self.data_set[:, 0][self.labels == 2], self.data_set[:, 1][self.labels == 2])
plt.scatter(old_centers[:, 0], old_centers[:, 1], marker='^', edgecolor='black', s=128)
plt.title('labeled data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2), ('label0', 'label1', 'label2'))
plt.show()
myKmeansPP = MyKmeansPlusPlus(3)
myKmeansPP.fit(data)
current iteration: 1
current centers:
[[55.97659 75.71833 ]
[43.75808 67.45812 ]
[71.72321 -7.872746]]
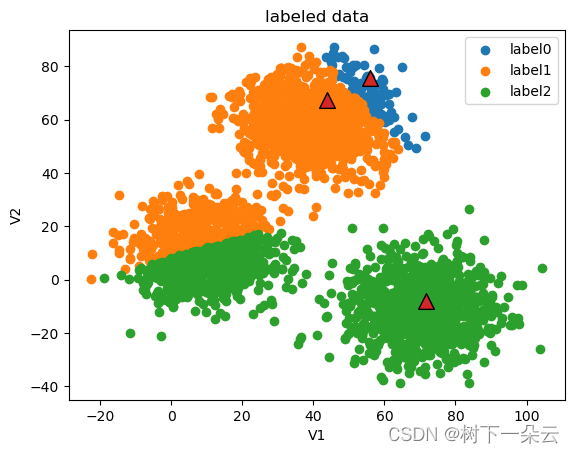
current iteration: 2
current centers:
[[55.83404759 70.21560931]
[30.35261288 47.71518861]
[50.15798861 -5.34769581]]
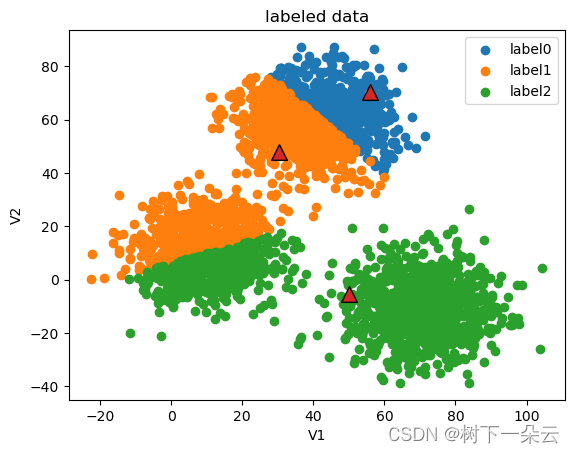
current iteration: 3
current centers:
[[47.66230967 65.1238036 ]
[22.93488 39.05383154]
[52.52023009 -6.18734425]]
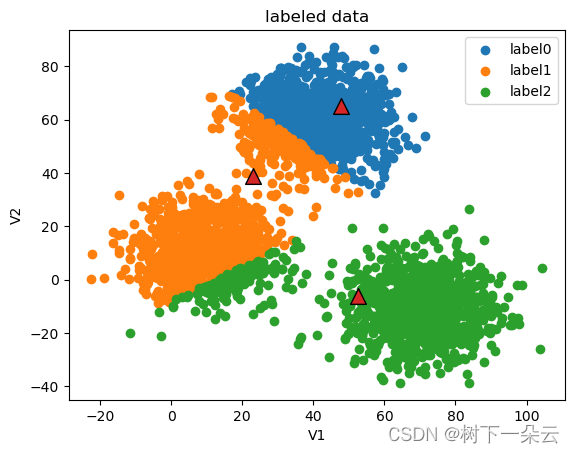
current iteration: 4
current centers:
[[42.96329079 61.70702396]
[12.28521822 20.36196405]
[63.73622886 -9.02914858]]

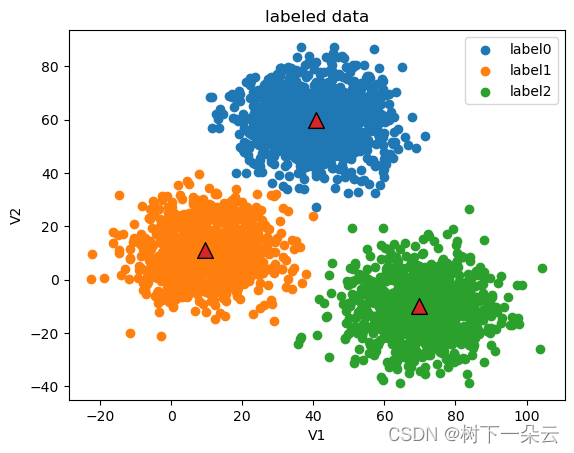
current iteration: 5
current centers:
[[ 40.8388755 59.95703427]
[ 9.62033389 11.15366963]
[ 69.77599323 -10.09654797]]

![[附源码]Python计算机毕业设计Django校园订餐系统](https://img-blog.csdnimg.cn/fb183291893647f988f0ab9c95bef7be.png)

![[附源码]Python计算机毕业设计Django校园运动会管理系统](https://img-blog.csdnimg.cn/3b9426cb92ee4597b741e30dcdd16e0c.png)


![[附源码]JAVA毕业设计砂石矿山管理系统(系统+LW)](https://img-blog.csdnimg.cn/b5c4c64c4e7a49fab7ca33bb905d49eb.png)