点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2305.07027.pdf
项目代码:https://github.com/microsoft/Cream/tree/main/EfficientViT
计算机视觉研究院专栏
Column of Computer Vision Institute
Vision transformers由于其高建模能力而取得了巨大成功。然而,它们显著的性能伴随着沉重的计算成本,这使得它们不适合实时应用。

01
总 述
在今天分享中,研究者提出了一个名为EfficientViT的高速Vision transformers家族。我们发现,现有transformer模型的速度通常受到内存低效操作的限制,特别是MHSA中的张量整形和逐元函数。因此,研究者设计了一种具有三明治布局的新构建块,即在有效的FFN层之间使用单个存储器绑定的MHSA,这在增强信道通信的同时提高了存储器效率。
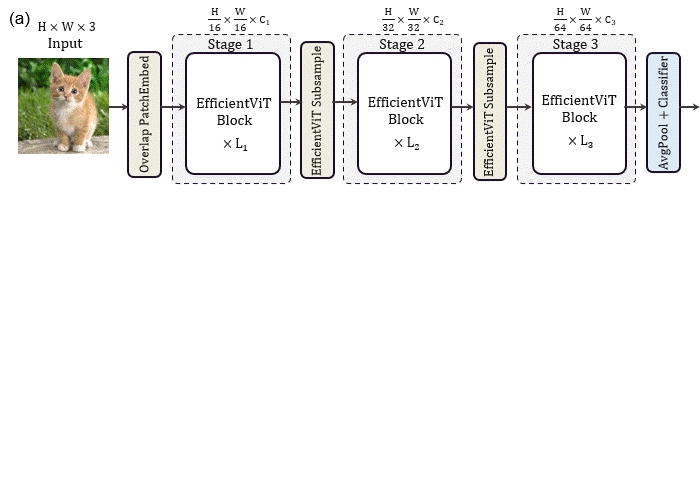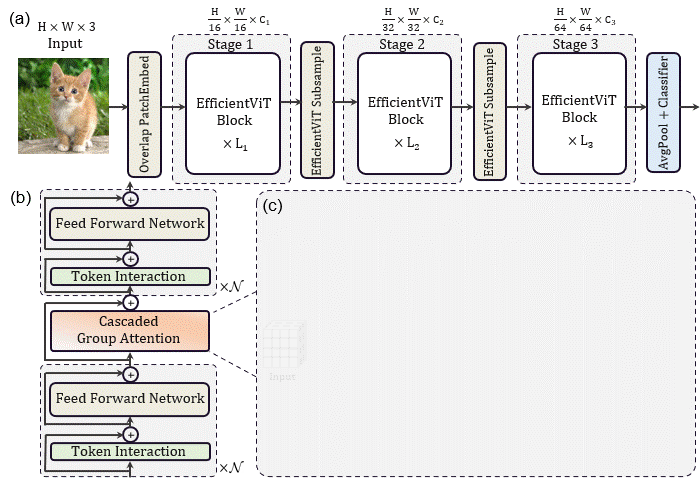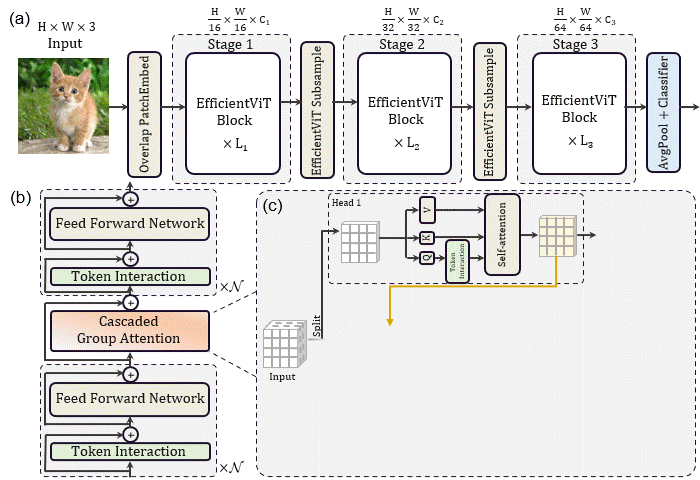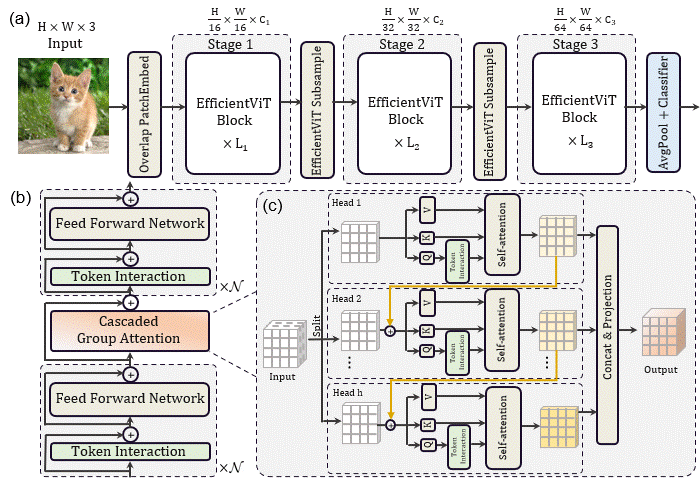
此外,研究者发现注意力图在头部之间具有高度相似性,导致计算冗余。为了解决这一问题,提出了一种级联的组注意力模块,该模块为具有不同全特征分割的注意力头提供反馈,这不仅节省了计算成本,而且提高了注意力的多样性。
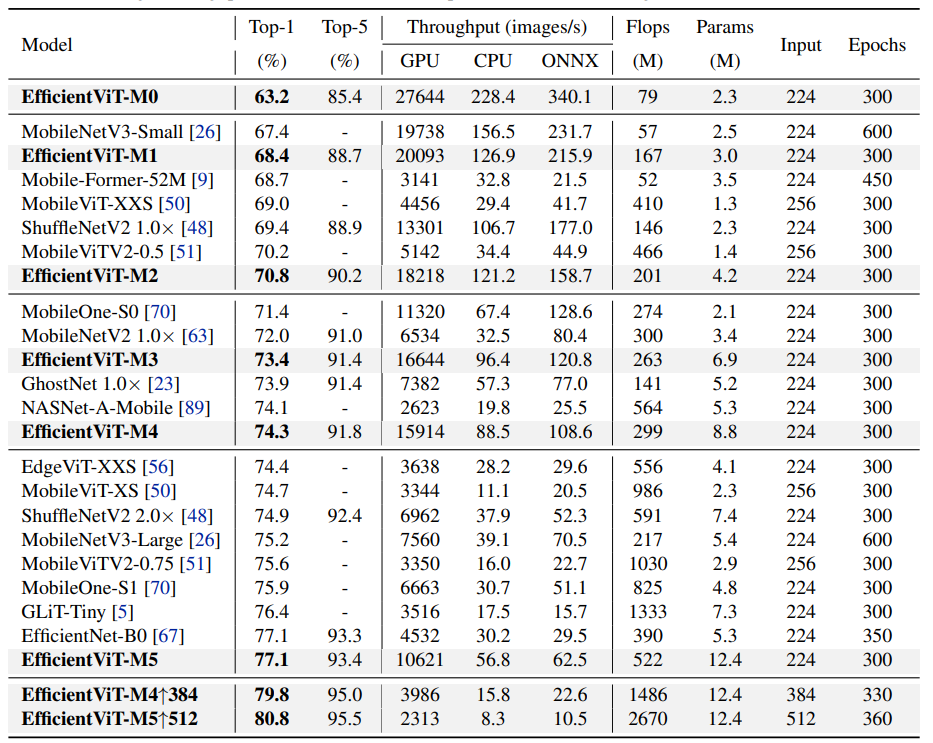
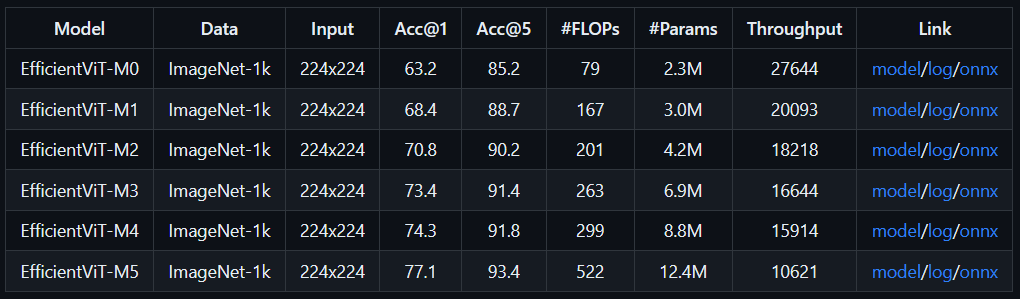
综合实验表明,EfficientViT优于现有的高效模型,在速度和准确性之间取得了良好的平衡。例如,EfficientViT-M5在精度上超过MobileNetV3 Large 1.9%,而在Nvidia V100 GPU和Intel Xeon CPU上的吞吐量分别高出40.4%和45.2%。与最近的高效型号MobileViT XXS相比,EfficientViT-M2实现了1.8%的卓越精度,同时在GPU/CPU上运行速度快5.8倍/3.7倍,转换为ONNX格式时速度快7.4倍。

02
背景
最近有几项工作设计了轻便高效的Vision transformers模型。不幸的是,这些方法大多旨在减少模型参数或Flops,这是速度的间接指标,不能反映模型的实际推理吞吐量。例如,在Nvidia V100 GPU上,使用700M浮点的MobileViT XS比使用1220M浮点的DeiT-T运行得慢得多。尽管这些方法以较少的Flops或参数获得了良好的性能,但与标准同构或分级transformer(例如DeiT和Swin)相比,它们中的许多方法并没有显示出显著的壁时钟加速,并且没有得到广泛采用。
为了解决这个问题,研究者探讨了如何更快地使用Vision transformers,试图找到设计高效transformer架构的原则。基于主流的Vision transformers DeiT和Swin,系统地分析了影响模型推理速度的三个主要因素,包括内存访问、计算冗余和参数使用。特别是,发现transformer模型的速度通常是内存限制的。
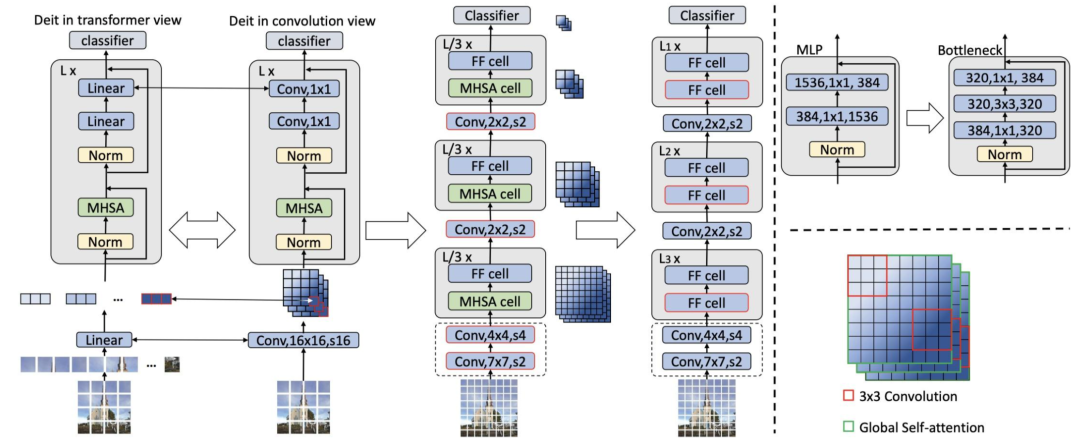
基于这些分析和发现,研究者提出了一个新的存储器高效transformer模型家族,命名为EfficientViT。具体来说,设计了一个带有三明治布局的新块来构建模型。三明治布局块在FFN层之间应用单个存储器绑定的MHSA层。它减少了MHSA中内存绑定操作造成的时间成本,并应用了更多的FFN层来允许不同信道之间的通信,这更具内存效率。然后,提出了一种新的级联群注意力(CGA)模块来提高计算效率。其核心思想是增强输入注意力头部的特征的多样性。与之前对所有头部使用相同特征的自我注意不同,CGA为每个头部提供不同的输入分割,并将输出特征级联到头部之间。该模块不仅减少了多头关注中的计算冗余,而且通过增加网络深度来提高模型容量。
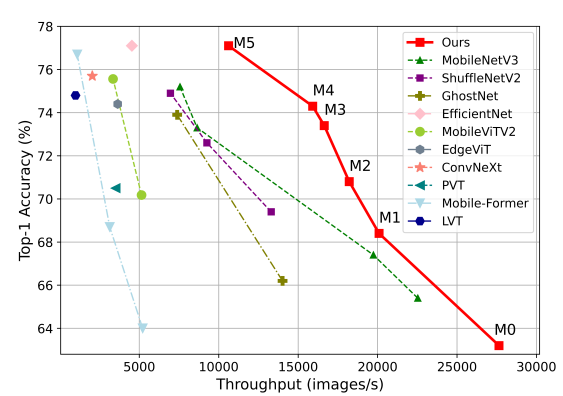
轻量级CNN和ViT模型吞吐量和精度对比的展示
最后但同样重要的是,通过扩大关键网络组件(如价值预测)的通道宽度来重新分配参数,同时缩小重要性较低的组件(如FFN中的隐藏维度)。这种重新分配最终提高了模型参数的效率。

03
动机
Vision transformers加速
Memory Efficiency
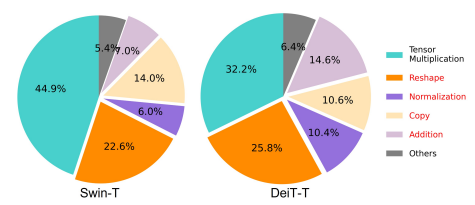
内存访问开销是影响模型速度的一个关键因素。Transformer中的许多运算符,如频繁的整形、元素相加和归一化,都是内存效率低下的,需要跨不同内存单元进行耗时的访问,如上图,尽管有一些方法通过简化标准softmax自注意的计算来解决这个问题,例如稀疏注意和低秩近似,但它们往往是以精度下降和加速度有限为代价的。
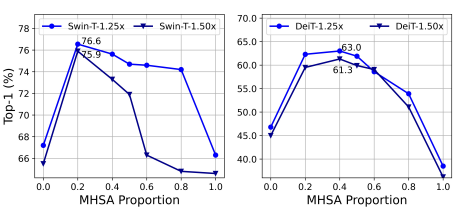
在这项工作中,研究者转而通过减少内存低效层来节省内存访问成本。最近的研究表明,内存低效操作主要位于MHSA层,而不是FFN层。然而,大多数现有的ViT使用相等数量的这两层,这可能无法实现最佳效率。因此,研究者探索了在具有快速推理的小模型中MHSA和FFN层的最优分配。具体而言,将Swin-T和DeiT-T缩减为几个推理吞吐量分别高1.25倍和1.5倍的小型子网络,并比较不同MHSA层比例的子网络的性能。
Computation Efficiency
MHSA将输入序列嵌入到多个子空间(头)中,并分别计算注意力图,这已被证明在提高性能方面是有效的。然而,注意力图的计算成本很高,研究表明,其中一些并不重要。
为了节省计算成本,探讨如何减少小型ViT模型中的冗余注意力。以1.25×推理加速训练宽度缩小的Swin-T和DeiT-T模型,并测量每个头部和每个块内剩余头部的最大余弦相似性。从下图中,观察到注意力头部之间存在高度相似性,尤其是在最后一个块中。
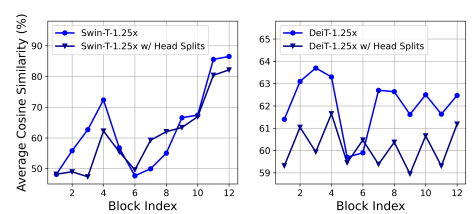
这一现象表明,许多头部学习相同完整特征的相似投影,并产生计算冗余。为了明确鼓励头部学习不同的模式,应用了一种直观的解决方案,即只向每个头部提供完整特征的一部分,这类似于DeiT-T中的组卷积思想。用改进的MHSA训练缩小模型的变体,并计算图中的保持相似性。研究表明,在不同的头部中使用不同的通道分割特征,而不是像MHSA那样对所有头部使用相同的完整特征,可以有效地减少注意力计算冗余。
Parameter Efficiency
典型的ViT主要继承了NLP transformer的设计策略,例如,使用Q、K、V投影的等效宽度,在阶段上增加水头,以及在FFN中将膨胀比设置为4。对于轻型车型,这些部件的配置需要仔细重新设计。受[Rethinking the value of network pruning]的启发,采用Taylor结构修剪来自动查找Swin-T和DeiT-T中的重要成分,并探索参数分配的基本原理。修剪方法在一定的重新源约束下去除不重要的通道,并保留最关键的通道以最好地保持准确性。它使用梯度和权重的乘积作为信道重要性,近似于去除信道时的损耗波动。

04
新框架
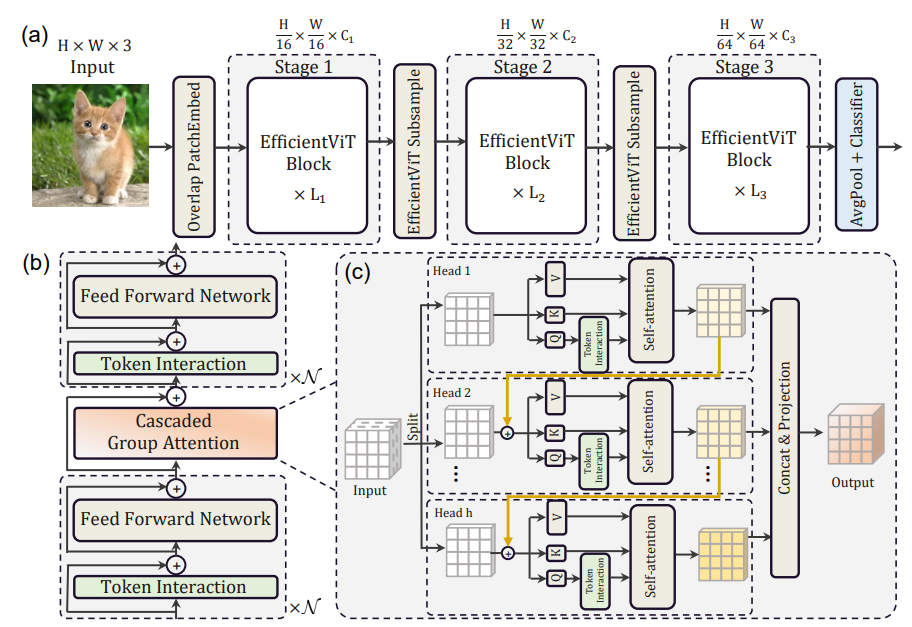
实验可视化
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!