目录
基本文件操作
创建和打开文件:open()函数
关闭文件:可以不关闭文件因为有垃圾回收功能
打开文件时使用with语句:不需要自己关闭文件,可以自己关闭
写入文件内容
file.write方法
file.writelines方法:可以向文件中写入字符串列表,但没有换行符和分隔符
读取文件有三种情况
读取指定字符
读取一行:如果文件很大一次读取全部内容到内存容易造成内存不足,通常会采用逐行读取
读取全部行
目录操作
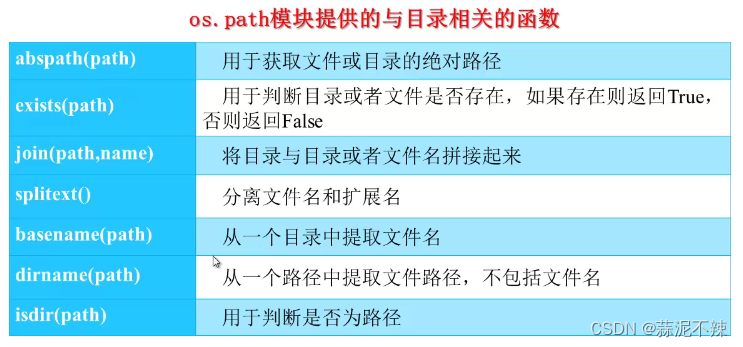
os和os.path模块
os
os.path模块是os的子模块
路径
判断文件或目录是否存在
创建目录
创建单级目录
创建多级目录
删除目录
删除空目录
删除不为空目录,需要pathon内置的标准模块shutil的rmtree函数实现
遍历目录:把指定目录下的全部目录和文件都访问一遍
高级文件操作
删除文件
重命名文件或目录
获取文件基本信息
基本文件操作
创建和打开文件:open()函数
语法:
file = open(filename[,mode[,buffering]],[encoding])
#file:返回值是一个文件对象
#mode:指定打开模式,默认为 r ,有三种基本模式可以与+号组合
r:只读模式
w:只写模式,先清空原文件内容在写入新的内容,如果文件不存在则创建文件
a:追加模式,如果文件不存在则创建文件
b:二进制模式,可以用这种方式打开音视频文件生产一个对象,我们可以用第三方模块对它进行处理
#buffering:用来指定读写文件的缓冲模式
0:不缓存
1:缓存
大于1:缓冲区大小

示例
file = open('test.txt','w',encoding = "utf-8") #只读方式打开文件如果文件不存在则创建
file = open('test.txt','r',encoding = "utf-8")
print(file.read()) #读取文件
file = open('pic.png','rb') #打开图片
print(file.read())关闭文件:可以不关闭文件因为有垃圾回收功能
只有关闭文件其他程序才能同一个文件进行写操作
对于close方法再关闭文件前他会先刷新缓冲区中还没有写入的信息,从而把没有写入的内容输出到文件中
语法:
file.close() #关闭文件
file.closed #判断文件是否被关闭,返回bool值
示例
file = open('test.txt','r',encoding = "utf-8")
print(file.read())
print(file.closed)
file.close()
print(file.closed)打开文件时使用with语句:不需要自己关闭文件,可以自己关闭
使用with语句执行open函数打开文件语法:
with expression as target:
with-body
# expression:指定要打开文件的open函数
#target:用as关键字指定一个变量来保存expression表达式的结果
#with-body:用来指定一些with语句之后的操作,例如expression中执行的是open函数就可以对打开的这个文件进行操作,如果不想操作可以用pass来代替
示例
with open('test.txt','r',encoding = "utf-8") as file:
print(file.read())
print(file.closed)写入文件内容
file.write方法
语法:
file.write(string)
注意:写入文件后必须要关闭文件或不关闭文件但执行file.flush方法把缓冲区内容输出到文件中才能保存内容
示例
file = open('test.txt','a',encoding = "utf-8")
file.write("\n学习python") #换行追加内容
file.close() #输出缓冲区file.writelines方法:可以向文件中写入字符串列表,但没有换行符和分隔符
语法:
file.writelines(ListName)
示例
import random
list = [str(i) + str(random.randint(10,100)) for i in range(10)] #生成字符串列表
list = [i + '\n' for i in list] #用列表推导式生成换行符
file = open('test.txt','w')
file.writelines(list) #把字符串列表写入文件
file.close()读取文件有三种情况
读取指定字符
语法:
file.read([size])
#size:可选参数,指定要读取的字符个数,用read读取时每个汉字也占一个字符,默认读取全部字符
注意:这个方法要求打开文件模式为 r 或者 r+
补充:
file.seek([size]):设置指针,因为file.read方法默认从头开始读取,可以通过file.seek设置起始位置
注意:file.seek的字符个数是根据编码字符个数计算例如utf-8的编码汉字为两个字符
示例
#写入文件
file = open('test.txt','w')
file.write("\n学习python")
file.close()
with open('test.txt','r',encoding = "utf-8") as file:
file.seek(4) #定义指针
string = file.read(2)
print(string)读取一行:如果文件很大一次读取全部内容到内存容易造成内存不足,通常会采用逐行读取
语法:
file.readline(size) #打开文件方式必须为 r 或 r+
#size:从行中读取的字节数
示例
import random
list = [str(i) + str(random.randint(10,100)) for i in range(10)]
list = [i + '\n' for i in list]
file = open('test.txt','w')
file.writelines(list)
file.close()
with open('test.txt','r') as file:
while True:
line = file.readline()
if line =="":
break
print(line)
print("="*20)
with open('test.txt','r') as file:
for i in range(5): #读取5行
print(file.readline(2))读取全部行
语法:
file.readlines() #打开文件方式必须为 r 或 r+,返回以每行为元素的字符串列表
示例
import random
list = [str(i) + str(random.randint(10,100)) for i in range(10)]
list = [i + '\n' for i in list]
file = open('test.txt','w')
file.writelines(list)
file.close()
with open('test.txt','r') as file:
print(file.readlines())目录操作
python中没有提供直接提供操作目录的函数或者对象,需要使用内置的OS和OS.path模块实现
os模块:是python内置的与操作系统功能和文件系统相关的模块,该模块中语句的执行结果通常与操作系统有关,在不同的操作系统运行可能得到不同的结果。
os和os.path模块
os

os.path模块是os的子模块
路径
获取当前的工作路径
语法:
os.getcwd()
获取文件的绝对路径
语法
os.path.abspath(path)
#path:文件的相对路径
示例
os.path.abspath('test.txt')拼接路径,可以拼接成相对路径和绝对路径
语法
os.path.join(path1[,path2,....])
注意:在拼接路径时python不会检查路径是否真实存在的
示例:
print(os.path.join(r'/home/python','test.txt'))判断文件或目录是否存在
语法:
os.path.exists(path) #返回为bool值
创建目录
创建单级目录
语法:
os.mkdir(path,mode=0777)
#mode:linux系统目录权限,为八进制数字,默认为0777
注意:如果要创建多级目录和目录已存在都会抛出异常
示例:
if not os.path.exists('pak'):
os.mkdir('pak',mode=755)
else:
print(os.path.abspath('pak'))创建多级目录
语法:
os.makedirs(name,mode=777)
删除目录
删除空目录
语法:
os.rmdir(path) #目录不存在或者不为空会抛出异常
示例
if os.path.exists('pak'):
os.rmdir('pak')删除不为空目录,需要pathon内置的标准模块shutil的rmtree函数实现
语法:
shutil.rmtree(path)
import shutil
if not os.path.exists('pak/test'):
os.makedirs('pak/test') #创建多级目录
print(os.path.abspath('pak/test')) #输出路径
shutil.rmtree('pak/test')
os.path.exists('pak/test') #删除多级目录遍历目录:把指定目录下的全部目录和文件都访问一遍
语法:
os.walk(top[,topdown][,onerror][,follwlinks])
#这个函数返回值为元组生成器对象每有一个子目录就会多生成一个元组对象,在这个对象中会生成包含三个元素的元组:
(dirpath,dirnames,filebames)
#dirpath:当前遍历的路径,是一个字符串
#dirnames:当前路径下包含的子目录,是一个列表
filebames:当前路径下包含的文件,是一个列表
#top:指定要变量内容的根目录,当前目录可表示为'./'
#topdown:指定遍历的顺序:
True:默认值为True,表示自上而下遍历先遍历根目录再遍历子目录
Flase:表示自下而上遍历
#onerror:用来指定错误处理方式,默认为忽略
#follwlinks:
True:表示指定在支持的系统上访问由软连接指向的目录
False:不支持
示例
import os
path = os.walk(r'./')
for root,dirs,files in path:
for i in dirs:
print(os.path.join(root,i)) #输出遍历的目录
for i in files:
print(os.path.join(root,i)) #输出遍历的文件高级文件操作
删除文件
语法:
os.remove(path) #删除不存在的文件时会抛出异常
示例
with open('pak/test.txt','w') as file: #创建文件
pass
print(os.path.exists('pak/test.txt'))
os.remove('pak/test.txt') #删除文件
print(os.path.exists('pak/test.txt'))重命名文件或目录
语法:
os.rename(src,dst)
示例:
if os.path.exists('pak/test.txt'):
os.rename('pak/test.txt','pak/test1.txt')
if os.path.exists('pak'):
os.rename('pak','pak1')获取文件基本信息
语法:
os.stat()
#返回值是一个对象,可以通过以下对象方法获取文件相关属性:
st_ctime:文件创建时间,以秒为单位
st_mtime:文件修改时间,以秒为单位
st_atime:文件最后一次访问时间,以秒为单位
st_size:文件大小,以字节单位显示
st_mode:权限
st_ino:文件索引号,linux中是inode编号
示例
fileinfo = os.stat('pak1/test1.txt')
print("\n",fileinfo.st_ino,"\n",fileinfo.st_ctime,"\n",fileinfo.st_size)示例:查询图片文件的基本属性并格式化成易读的时间和文件大小进行输出
import os # 导入os模块
def formatTime(longtime):
'''格式化日期时间的函数
longtime:要格式化的时间
'''
import time # 导入时间模块
return time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(longtime))
def formatByte(number):
'''格式化日期时间的函数
number:要格式化的字节数
'''
for (scale,label) in [(1024*1024*1024,"GB"),(1024*1024,"MB"),(1024,"KB")]:
if number>= scale: # 如果文件大小大于等于1KB
return "%.2f %s" %(number*1.0/scale,label)
elif number == 1: # 如果文件大小为1字节
return "1 字节"
else: # 处理小于1KB的情况
byte = "%.2f" % (number or 0)
return (byte[:-3] if byte.endswith('.00') else byte)+" 字节" # 去掉结尾的.00,并且加上单位“字节”
if __name__ == '__main__':
fileinfo = os.stat("/var/log/secure-20230618") # 获取文件的基本信息
print("文件完整路径:", os.path.abspath("mr.png")) # 获取文件的完整数路径
# 输出文件的基本信息
print("索引号:",fileinfo.st_ino)
print("设备名:",fileinfo.st_dev)
print("文件大小:",formatByte(fileinfo.st_size))
print("最后一次访问时间:",formatTime(fileinfo.st_atime))
print("最后一次修改时间:",formatTime(fileinfo.st_mtime))
print("最后一次状态变化时间:",formatTime(fileinfo.st_ctime))





![[元带你学: eMMC协议详解 15] 写保护(Write Protect)详解](https://img-blog.csdnimg.cn/img_convert/262abfa94e2b5642120b21810384ce4b.png)