1 Spark的任务执行流程
第一种standalone模式
-
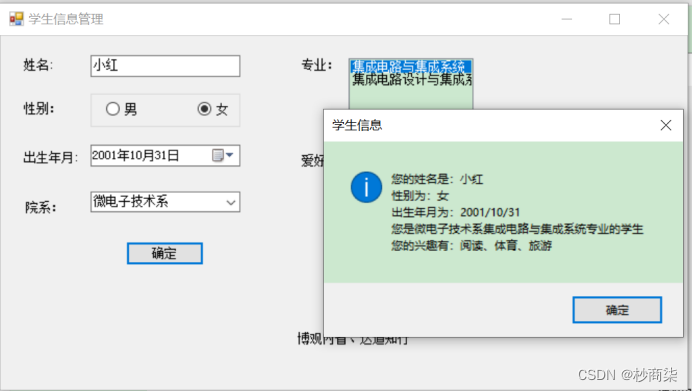
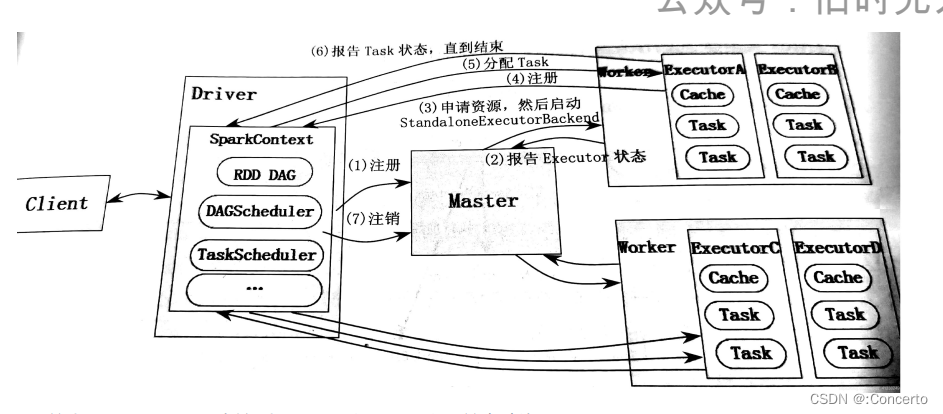
整体:driver中有sparkcontext,RDD DAG和DAGScheduler和taskscheduler,master是资源管理,worker中executor,executor中有多个task
-
构建一个application环境,driver创建sparkcontext
-
sparkcontext中的taskcheduler连接到集群管理器master申请资源,此时worker也会向master定期发送心跳信息以及executor的状态
-
master根据sparkcontext的资源申请和worker的心跳信息决定在哪一个worker分配资源,被选中的worker启动standaloneexecutorbackend并向sparkcontext反向注册,这样driver就知道哪些excutor是可以进行服务的
-
sparkcontext开始执行代码,spark RDD通过transaction操作,形成了RDD血缘关系,构建DAG有向无环图,最后遇到action算子调用,触发job并调度,生成两个调度器DAGschedule和taskscheduler。
-
DAGschedule负责分解stage,主要将job切分为若干个stage,具体划分:窄依赖RDD会被划分到一个stage中,宽依赖会被划分多个stage,为并为每一个stage组装一批task组成taskset
- 宽依赖:指的是多个子RDD的分区会依赖同一个父RDD的分区
- 窄依赖:每一个父RDD的分区最多被一个子RDD的分区使用
- job,stage,task的关系:一个job含有多个stage,一个stage含有多个task,stage的数量=宽依赖数量+1
-
然后将taskset交给taskscheduler,taskscheduler会将taskset封装成tasksetmanager加入到调度队列中,调度过程中schedulerbackend负责提供可用资源,schedulerbackend也会定期询问taskscheduler是否有任务要运行。最后taskscheduler将taskset分配给到worker。
-
worker中的excutor执行进行反序列化,会将driver发送过来的taskset封装进去一个taskrunner的线程,放到本地线程池,调度我们的作业
-
资源注销
第二种yarn cluster模式
-
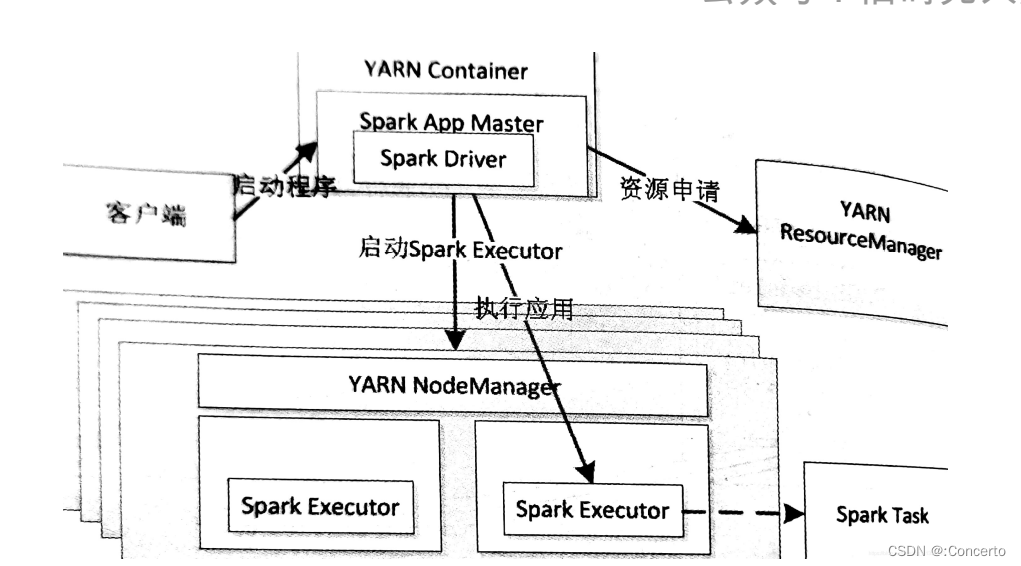
yarn集群中,driver是运行在applicationmaster上的,applicationmaster进程同时负责驱动application和从yarn申请资源。
-
client向yarn中提交应用程序,
-
resourcemanager在某一个nodemanager中启动container,并将applicationmaster分配到该nodemanager上
-
nodemanager收到resourcemanager分配后,启动application master进行sparkcontext的初始化,这个时候nodemanager相当于driver
-
applicationmaster向resourcemanager注册,用户可以直接通过applicationmaster查看应用程序的与运行状态,然后它将采用的轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到结束
-
申请到资源的applicationmaster向nodemanager进行通信,要求nodemanager启动coarsegrainedexecutorbackend并向applicationmaster中sparkcontext注册并申请
-
applicationmaster中sparkcontext分配task给coarsegrainedexecutorbackend执行
-
excutor向nodemanager上的applicationmaster注册汇报并完成相应的任务。
-
applicationmaster和resourcemanager申请注销并关闭自己
作业调度
- driver的主要是初始化sparkcontext对象,准备运行所需要的上下文
- 一方面和applicationmaster的RPC连接,通过applicationmaster申请资源
- 另一方面根据业务逻辑调度任务,将任务下放到空闲的excutor上
第三种 yarn-client和yarn-cluster的区别
- yarn-cluster模式下,driver在applicationmaster中负责资源申请以及监督作业。用户提交作业,可以关闭client,作业会继续在yarn运行,但是不适合运行交互类型的作业
- yarn-client模式下,applicationmaster仅仅向yarn请求executor,client会和container通信,yarn不能离开
2 spark的特点
- 快
- spark实现了DAG执行引擎,可以基于内存处理数据流。与MR基于磁盘比快了很多
- 计算的中间结果是存在于内存中的,减少低效磁盘io。和hadoop中间写入磁盘比快
- jvm优化,MR是一个task启动一个jvm,spark是一个executor启动jvm,task是在线程复用的
- 基于DAG高效的调度算法
- 缓存方式:cache
- 易用
- shell/python/scala/java都可以使用
- 通用
- sparksql,spark streaming,spark core等,还有spark mllib和图计算
- 兼容性
- 和yarn和mesos作为资源管理和调度,和其他开源产品融合使用
3 spark源码的任务调度
- DAG产生:叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据依赖关系将DAG划分为不同的stage,对于宽依赖来说,由于存在shuffle,因此只能在parent RDD处理后完成。
- 宽依赖:指的是多个子RDD的分区会依赖同一个父RDD的分区
- 窄依赖:每一个父RDD的分区最多被一个子RDD的分区使用
4 spark的yarn-cluster涉及的参数有哪些

5 spark处理数据的具体流程/如何从kafka读数据/双流join/怎么保证数据不丢失/数据持久化/exactly once
spark streaming 处理数据流程
待补充
6 spark的join分类
- broadcast hash join:使用小表很小的
- broadcast阶段:将小表广播分发到大表的分区,先给到driver,driver再统一给到executor
- hash join阶段:大表的分区在内存中和executor上的小表join
- shuffle hash join:按照相同join key进行分区,将大表划分为小表的join,再利用集群并行化处理。
- shuffle阶段:分别将两张表按照join key进行分区,相同的分布到同一个节点。默认分区200
- hash join:在分区节点执行单机hash join
- sort-merge join:适用于两个表都特别大
- shuffle阶段:按照相同join key进行分区,散布到集群,利用分布式处理
- sort阶段:对单个分区节点的两张表,进行排序
- merge阶段:对排好序的两张分区表进行join操作
7 map join 原理
-
将小份RDD直接通过collect算子拉取到driver加载到内存中,对其创建一个broadcast变量。
-
对另一个RDD执行map类算子,并从broadcast变量获取较少的RDD全量数据,与当前RDDkey值相同的话,就直接进行join
-
常用场景:
-
小表建立索引,然后建立map表,用rdd.collectAsMap算子,但是value不可重复,需要另算。
-
还得注意driver的节点内存充足。可以在任务提交的时候参数写大一些。
-
executor需要处理广播过来的数据,因此也需要确保executor内存足够。
8 什么时候会产生spark shuffle?
- repartition类的操作:repartition、coalesce、repartitionAndSortWithinPartitions(分组然后排序)
- bykey:reducebykey、groupbykey、sortbykey
- join:join、cogroup(计算区内元素个数)
9 spark shuffle以及优缺点
- hash shuffle
- 取余操作
- 优化过后的hashshuffle
- 合并机制是使用复用butter,相同的key值的放在同一个butter缓冲中,然后写入封装成core为单位的本地磁盘文件,对应参数:spark.shuffle.consolidateFiles
- 优点:和sort的优化比是省略不必要的排序开销以及排序内存开销
- 缺点:写到磁盘本地文件的话,会带来一定的磁盘以及文件系统的开销,以及和内存交互,对内存也是有压力的。
- sort shuffle
- 数据写入内存缓冲,并对key值进行排序,内存满了后分批溢写入磁盘
- 合并操作,最后的task合并刚刚的磁盘文件并写道最终文件磁盘,并创建单独的索引文件
- bypass sortshuffle
- 条件:小于默认分区200+不是聚合类的算子
- 优化过后的hashshuffle+最终的合并
- 合并:最后的task合并刚刚的磁盘文件并写道最终文件磁盘,并创建单独的索引文件。
- tungsten sort shuffle
- 条件:没有聚合操作+PartitionId<2的24次方+Serializer序列化器支持relocation序列化值重定向
- 排序+内存溢写磁盘
- 优点:使用UnSafe API不用进行序列化以及反序列化
- 缺点:map端以及记录本身的排序耗性能
10 spark数据倾斜
- 表现:不同key值数量导致不同task的数据量处理问题,有的task显示很慢或者直接表现为内存溢出OOM
- 避免shuffle过程:map join的办法,使join在map段解决
- 增大key值粒度
- 过滤倾斜的key值或者单独处理倾斜的key值后续放回去
- 提高reduce的并行度,增加reducetask的数量,使每一个task处理的数据量少了,shuffle的算子中可以传入一个并行度的设置参数,例如reducebykey(500)
- 并行度:各个stage的task数量,可以说是等于RDD的一个分区
- 使用随机key实现双重聚合
- 给每个key值添加上随机数前缀,进行第一次聚合
- 去掉key值得随机数前缀再次聚合
- 适用:join的shuffle操作
11 spark的stage的划分
- stage的产生:job按照RDD之间的依赖关系分为宽依赖,由DAGscheduler划分为一个stage
- result stage:使action操作后得到的计算结果
- shuffle map stage:在shuffle之前出现
12 spark的内存模型
- 堆内内存:默认堆内内存
- executor内存:用户存放shuffle,sort等计算过程中的中间临时文件
- storage内存:存放spark的cache的数据,例如RDD的缓存,broadcast的数据
- 用户内存:主要存储RDD转换操作所需要的数据,RDD依赖
- 预留内存:系统预留内存,用来存储spark的内部对象
- 堆外内存:
- 表示分配在java虚拟机的堆以外的内存,表示spark是可以直接操作操作系统的内存的,减少了不必要的开销体现在可以精确的申请和释放,而不是jvm内存清理的不明确时间点。
13 spark的RDD、DataFrame、DateSet和DateStream区别
- RDD:分布式弹性数据集
- DateFrame:
- 与RDD的区别是,前者带有schema元信息,即二位数据集的每一列都带有名称以及类型。
- 允许不用必须去注册临时表或者生成sql表达式
- 拥有内存管理[二进制存储]和查询优化器
- 创建:使用toDF/createdataframe创建DateFrame
- DataSet:
- 是DateFrame的拓展,由更好的lambda函数能力以及sparksql的优化执行引擎
- 比DateFrame比,是可以知道字段以及字段类型的
- 类型和比DateFrame比是安全的,是强类型Dataset[Car]
- spark SQL
- SQL查询和spark程序无缝连接使用
- sql进行语法解释器、分析器以及优化器都可以定义
14 spark的容错机制
-
spark是记录更新的方式,即血缘容错
-
血缘容错记录了较粗粒度的操作:例如filter、map、join,当rdd的部分分区数据丢失的时候,可以通过血缘来重新运算以及恢复丢失的分区。
-
如果是窄依赖:只要把丢失的父依赖的分区重新计算即可;但是是宽依赖:需要恢复父依赖的分区并且重新计算,开销会大。
-
因此有了checkpoint机制:将内存的变化持久化到磁盘持久存储,可以把RDD保存在hdfs的namenode中元数据edit log中并刷新到磁盘fsimage,斩断所需的依赖链,如果没有才往前追溯。
-
一般可以通过冗余数据和日志记录更新操作。
-
cache机制:将RDD的结果写入内存,运行后缓存自动消失
-
persist机制:将结果写入磁盘
15 sparkbatchsize中小文件问题
- 窄依赖计算结果会出现大量小文件,因此采用coalese方法和repartition方法最后返回一个特定分区的RDD。
- 降低spark的并行度,生成的文件就会少一些
- 新增一个任务专门合并小文件
- 将原来任务写道一个临时分区,在其一个并行度为1的文件
- 要用group by的原因是利用宽依赖形成一个分区
insert overwrite 目标表 select * from 临时分区 group by *
16 spark参数(性能)调优
- 常规性能调优:在写submit提交的时候
- 设置executor的个数:50~100
- 配置driver的内存(1-5G)和executor的内存(6-10)
- 配置executor的cpu core的数量:3核
- RDD优化
-
减少RDD的重复使用:例如使用完全多次窄依赖后再划分宽依赖
-
RDD持久化:
- 当多次对同一个RDD执行算子操作的时候,需要对RDD之前的父RDD重新计算一次,因此会对多次使用的RDD进行持久化,存入内存或者磁盘中(采用序列化方式减少空间),下次计算直接取数据
-
RDD尽早的filter操作:尽早的使用filter算子过滤掉不需要的数据,减少对内存的占用
- 并行度调节
- spark官方推荐,task的数量应该设置为spark作业总CPU数量的2~3倍。一般没有将task的个数和cpu核数一样是因为有的task执行的快,就会出现cpu的空闲情况
- 调节本地化等待时常
- 适当调节本地化等级,调长时间的目的是希望task能够运行在它要计算数据的节点上,减少数据的网络传输。
- 算子调优
- 使用mappartition代替map算子,优势是是对每一个分区进行操作,而不是对每条数据进行操作,function并且一次接收所有partition的数据,只执行一次,但是要防止mappartition内存溢出
- foreachpartition代替foreach优化数据库操作,也是对RDD的每个分区进行操作,只需要和分区的数据建立数据库连接而不是和每条数据
- filter和coalesce的配合使用:filter之后每个数据量不同程度的变少了,后续的task计算资源可能浪费,因此进行重新分区合并或者拆分分区(确保个分区均衡),使用coalesce算子
- repartition解决sparkSQL的低并行度问题:前面的并行度调节对sparksql不生效,因此使用repartition重新分区为多个partition提高并行度
- reducebykey预聚合替代其他聚合:reduceby的特点是会在map端进行预聚合,替代例如groupbykey
- shuffle优化
- 调节map/reduce端的缓冲区大小,以防溢写到磁盘,增加磁盘io
- 调节reduce端拉取数据重试次数以及重试后等待间隙:增加重试次数防止jvm的full gc或者网络不稳定的情况,增加等待时间保证shuffle的平稳,省的重启
- jvm调优
- 堆内内存:storage内存主要缓存RDD数据和broadcast数据,降低storage中的内存比例,方便executor内存避免不必要的频繁的full gc
- executor内存主要缓存shuffle的中间数据,不用考虑,如果shuffle的过程过大,会自动占用storage的内存区域
- 堆外内存:提高对外内存的大小,可以从300调到1G以上,在submit的时候提交
17 完整介绍一下RDD
- 含义:弹性分布式数据集
- 特点:
- RDD间存在依赖关系,宽依赖窄依赖
- 分区:是RDD的基本组成单位,切分成partition
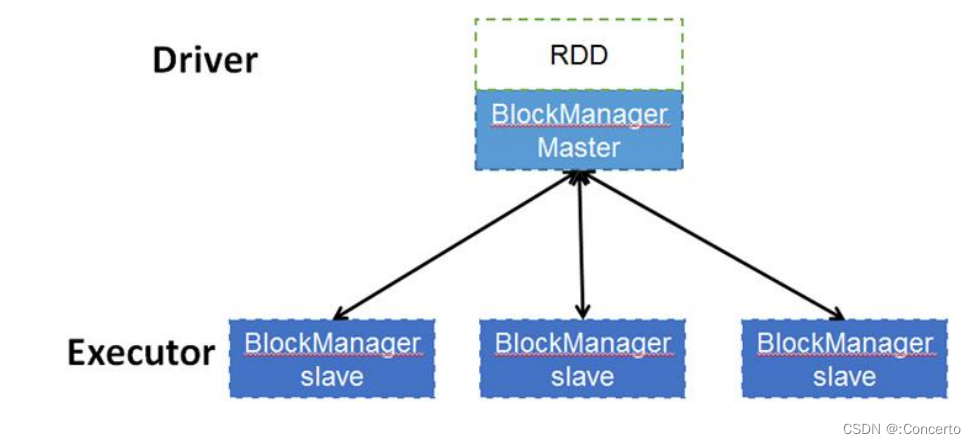
- 底层存储:每个RDD的数据都以block的形式存储与多台机器上,executor会存储启动一个blockmanagerslave并管理部分block,block而元数据是放在driver的blockmanagermaster保存。blockmanagerslave生成之后是向blockmanagermaster注册该block,blockmanagermaster是负责管理block与RDD的关系,如果RDD不需要这个block,则由blockmanagermaster发送指令删除对应的block。
18 广播变量
- 条件:当任务跨多个stage并且需要同样的数据+以反序列化的形式缓存数据时候
- 特征:会在每一个worker节点保留一份副本,以供task使用
- 步骤:把普通变量转换成广播变量
- 原理:
- 在driver的sparcontext创建后,会分成多个数据块,保存到driver的blockmanager中
- 只有executor需要广播变量的时候才会向driver获取,只要有一个worker的executor获取到了某一个block,其他的executor不需要获取了,其他executor向这个获取到的executor获取
19 sparksql的自定义函数
- UDF:基本自定义函数,to_date,to_char
- UDAF:多成一,用户自定义聚合函数,groupby
- UDTF:一对多,用户自定义生成函数,flatmap
- 实现
- 将代码打包成udf.jar,放在hadoop/lib下
- 第一种:启动spark-sql是通过–jars指定
- 第二种:启动sparksql后add jar
- 第三种:使用thrift jdbc使用udf
20 hashpartition和rangepartition
- spark分区器
- hashpartition:对于给出的key值取余
- rangepartition:抽样分区
21 算子区别:map和flatmap/cache和persist
- map函数:输入后返回的是一个对象
- flatmap是操作的:先输入后返回对象,再将所有的对象合并为一个对象
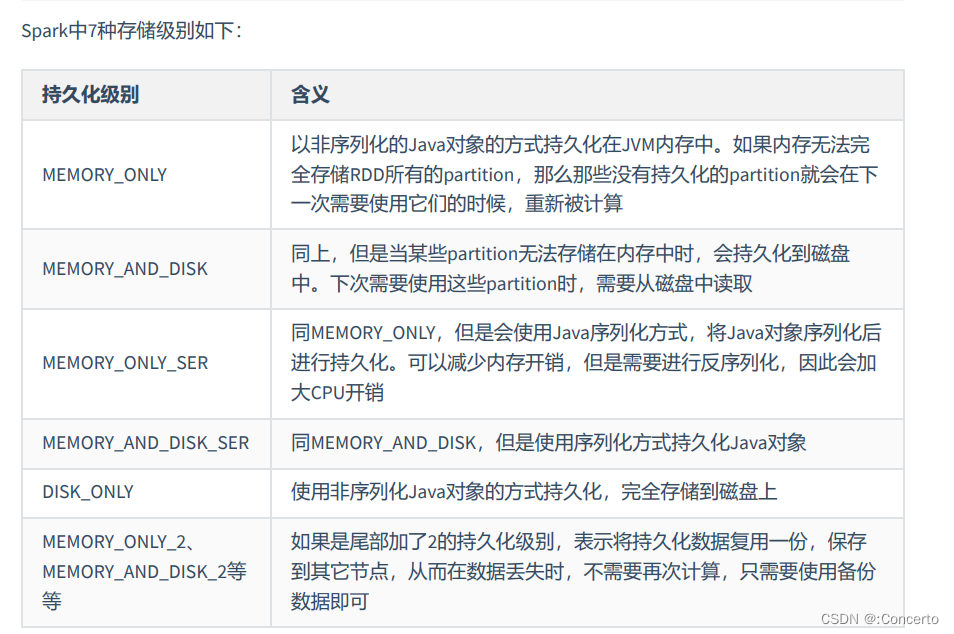
- cache调用了persist,persist比cache可以设置各种缓存级别,cache默认缓存级别是momery_only
22 spark的block管理
- 内容:RDDblock,shuffleblock,taskresultid
- 实现类:memorystore,blockmanager
23 streaming连接kafka的方式/streaming怎么保证数据不丢失
- Receiver
-
Receiver-based
-
- 使用 Kafka 高级消费者 API 来实现 Receiver
- 从 Kafka topic分区接收的数据存储在 Spark executors
- spark开启WAL 才能保证spark中 exactly-one 的处理,但是两者的exactly-one 是需要direct的api来写
- 多个Dstream实现多个Receiver并行
-
direct
- 使用简单api就可以,需要自己管kafka的offset
24 streaming的流程
- 先成batch数据,给到StreamingContext,然后封装RDD操作,然后再给到Dstream进行自己的算子操作
25 持久化
使用checkpoint机制
启动:创建streamingContext,然后调用start()方法,当Driver挂掉的时候,再从checkpoint中恢复一个streamingcontext
26 streaming的算子