1. 创建单向链表
例如,有“学生”这样一个链表,链表中需要包括学生的姓名、性别、学号等一些基本信息。创建这样的一个链表,链表里面包括多个学生的信息。

可以看出,“学生一”的尾结点“next”指向了下一个“学生二”的头结点学号“02”,这就是链表的特性,即上一个信息的尾结点next会指向下一个信息的头结点的内存地址。由于每个结点都包含了可以链接起来的地址信息,所以用一个变量就能够访问整个结点序列。
在上面讲解中出现了两个词:“指向”和“地址”,了解C语言的人可能会知道,这是典型的指针。没错,在C语言中,可以使用指针创建链表。但是在Python中并没有指针的概念,那么应该怎样创建链表呢?我们先来看如何使用Python交换两个值。首先是定义两个变量,代码如下:
x=13
y=14
利用Python交换两个变量代码如下:
x,y =y,x
在Python中交换值可以这样做,但在别的语言中不可以。这是因为在Python中,在定义x=13时,除了开辟一块内存给13这个值,还需要开辟一块内存用于存储13的地址,这块地址称之为x。类似地,在定义y=14时,除了开辟一块内存给14这个值,还需要开辟一块内存用于存储14的地址,这块称之为y。所以说,在Python中交换两个数的值,其实是地址的指向发生转换,类似于C语言中的指针。
在“x,y = y,x”中,我们先看右边,“y,x”的值分别为14,13。即得到“x,y =14,13”。然后x再存储14的地址,y再存储13的地址,这样就达到交换的效果。

因此,Python中的变量名保存的不是值,而是地址。同时,由于在Python中变量是隐式说明,所以Python中x可以指向任何东西。
了解地址在Python代码中的保存形式之后,就用Python代码实现利用结点创建一个链表的功能。代码如下:
"""
功能:定义类,作用是指向下一个结点。
"""
class Node():
def __init__(self,elem): # 链表元素
self.elem =elem
self.next = None # 初始设置下一结点为空
创建学生链表,具体代码如下:
"""
功能:创建学生结点类
"""
class student:
def __init__(self):
self.name = ''
self.sex = ''
self.next = None
head=student() # 建立链表头部
head.next=None # 下一个元素为空
ptr=head # 储存指针的位置
select=0 # 用来选择
while select!=2: # 不为2就循环
print("(1)添加 (2)退出程序") # 提示
select = int(input('请输入一个选项:'))
if select==1: # 选择1时,添加信息
NewData=student() # 添加下一个元素
NewData.no = input("学号:") # 添加学号
NewData.name=input("姓名:") # 添加姓名
NewData.sex=input("性别:") # 添加性别
ptr.next=NewData # 存储指针设置为新元素所在的位置
NewData.next=None # 下一个元素的next先设置为空
ptr=ptr.next # 指向下一个结点
elif select == 2: # 选择2时退出程序
break
else: # 选择其他时提示有误
print("输入有误")
接下来创建一个链表类并初始化类,代码如下:
"""
功能:定义链表
"""
class LinkList():
# 使用一个默认参数,传入头结点时则接收,没有传入时,则默认头结点为空
def __init__(self, node=None ):
self.__head = node # 表示私有属性,不对外开放
然后对这个链表进行基本的操作:
(1)在链表类中,定义一个方法is_empty(),它的功能是判断这个链表是否为空,代码如下:
"""
功能:判断链表是否为空
"""
# def is_empty(self):
return self.__head == None
(2)在链表类中,定义一个方法LinkList_length(),它的功能是求链表的长度,代码如下:
"""
功能:求链表长度
"""
def LinkList_length(self):
# cur游标,用来移动遍历结点
cur = self.__head
# count记录数量
count = 0
while cur != None:
count += 1
cur = cur.next
return count
(3)在链表类中,定义一个方法LinkList_travel(),它的功能是遍历整个链表,代码如下:
"""
功能:遍历整个链表
"""
def LinkList_travel(self):
cur = self.__head # 指向头结点
while cur != None:
print(cur.elem, end=' ') # 输出链表元素
cur = cur.next # 指向下一个结点
print()
2. 单向链表结点的添加
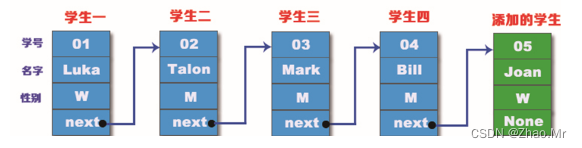
单向链表结点添加分为头结点添加、尾结点添加以及在指定位置添加结点。

头结点变成了新添加学生的结点,然后新添加的学生next结点指向“学生一”的地址。用Python实现在头结点添加的功能,具体代码如下:
"""
功能:在头部添加新数据,item是数据
"""
def add(self, item):
node = Node(item) # 添加新数据
node.next = self.__head # 新数据的next指向原来的头结点
self.__head = node # 新添加的数据变成头结点
当新添加学生的结点添加到“学生四”的结点后面,需要将链表最后的“学生四”的结点指向新添加学生的结点,接着将新添加学生的结点指向None。用Python实现在尾结点添加结点的功能,具体代码如下:
"""
功能:在尾部添加新数据,item是数据
"""
def append(self, item):
# 这里的item是一个数据,不是结点
node = Node(item) # 新添加数据的结点
# 由于特殊情况当链表为空时没有next,所以在前面要先做判断
if self.is_empty():
self.__head = node # 直接向把新添加信息给头结点
else: # 链表不为空
cur = self.__head # 初始化cur游标
while cur.next != None: # 判断游标指向空,就跳出循环
cur = cur.next
cur.next = node # 指向新添加数据的结点
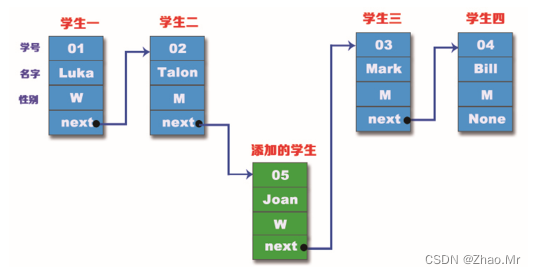
可以看出,在“学生二”的结点和“学生三”的结点之间添加新学生的结点,需要将“学生二”的结点指向“新学生”的结点,然后将“新学生”的结点指向“学生三”的结点,这样就完成了在链表的中间位置添加结点的功能。
"""
功能:在中间位置添加新数据,item是数据
"""
def insert(self, pos, item):
if pos <= 0: # 如果pos位置在0或者以前,那么都当作头插法来做
self.add(item)
elif pos > self.LinkList_length()-1: # 如果pos位置比原链表长,那么都当作尾插法来做
self.append(item)
else: # 否则,采用中间位置添加
node = Node(item) # 新数据的结点
count = 0
pre = self.__head
while count<(pos-1):
count += 1
pre = pre.next
# 当循环退出后,pre指向pos-1位置
node.next = pre.next
pre.next = node
3. 链表添加数据,具体代码如下:
"""
功能:定义结点类,作用是指向下一个结点
"""
class Node():
def __init__(self, elem):
self.elem = elem
self.next = None
"""
功能:定义链表
"""
class LinkList(object):
# 使用一个默认参数,传入头结点时则接收,没有传入时则默认头结点为空
def __init__(self,node=None):
self.__head = node # __表示私有属性,不对外开放
"""
功能:判断链表是否为空
"""
def is_empty(self):
return self.__head == None
"""
功能:求链表长度
"""
def LinkList_length(self):
# cur游标,用来移动遍历节点
cur = self.__head
# count记录数量
count = 0
while cur != None:
count += 1
cur = cur.next
return count
"""
功能:遍历整个链表
"""
def LinkList_travel(self):
cur = self.__head # 指向头结点
while cur != None:
print(cur.elem, end=' ') # 输出链表元素
cur = cur.next # 指向下一个结点
print()
"""
功能:在头部添加新数据,item是数据
"""
def add(self, item):
node = Node(item) # 添加新数据
node.next = self.__head # 新数据的next指向原来的头结点
self.__head = node # 新添加的数据变成头结点
"""
功能:在尾部添加新数据,item是数据
"""
def append(self, item):
# 这里的item是一个数据,不是节点
node = Node(item) # 新添加数据的结点
# 由于特殊情况当链表为空时没有next,所以在前面要先做判断
if self.is_empty():
self.__head = node # 直接把新添加信息给头结点
else: # 链表不为空
cur = self.__head # 初始化cur游标
while cur.next != None: # 判断游标指向空,就跳出循环
cur = cur.next
cur.next = node # 指向新添加数据的结点
"""
功能:在中间位置添加新数据,item是数据
"""
def insert(self, pos, item):
if pos <= 0: # 如果pos≤0,就调用“头部添加数据”函数
self.add(item)
# 如果pos位置比原链表长,就调用“尾部添加数据”函数
elif pos > self.LinkList_length() - 1:
self.append(item)
else: # 否则,采用中间位置添加
node = Node(item) # 新数据的结点
count = 0
pre = self.__head
while count < (pos - 1):
count += 1
pre = pre.next
# 当循环退出后,pre指向pos-1位置
node.next = pre.next
pre.next = node
LinkList_demo = LinkList() # 创建链表
LinkList_demo.add(25) # 调用add()函数在头结点添加数据
LinkList_demo.add(10) # 调用add()函数在头结点添加数据
LinkList_demo.append(39) # 调用append()函数在尾结点添加数据
LinkList_demo.insert(2, 49) # 调用insert()函数在第3个结点(结点下标从0开始)添加数据
LinkList_demo.insert(4, 54) # 调用insert()函数在第5个结点(结点下标从0开始)添加数据
LinkList_demo.insert(0, 60) # 调用insert()函数在第1个结点(结点下标从0开始)添加数据
# 调用LinkList_length()函数输出链表长度
print ("链表的长度是:",LinkList_demo.LinkList_length())
print("链表的各个数据分别是:")
LinkList_demo.LinkList_travel() # 调用LinkList_travel()函数输出链表各个数据
4. 单向链表结点的删除
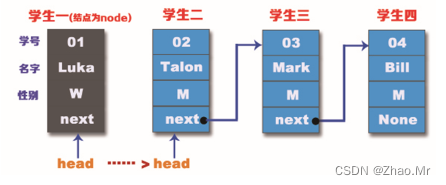
可以看出,想删除“学生一”的结点,只要把链表中“学生一”这个头结点(head)指向“学生二”的结点,把“学生二”变成头结点(head)。
例如,“学生一”的结点是node,用Python算法实现,代码如下:
node=head # 要删除的结点是头结点
head = head.next # 现在是第二个结点变成头结点
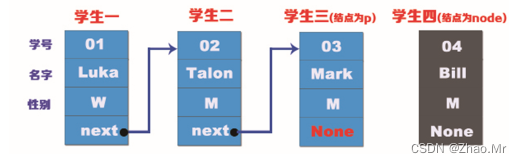
可以看出,删除最后一个结点很简单,就是将链表的倒数第二个结点(即“学生三”的结点)指向none即可。例如倒数第二个结点为p,用Python算法实现,代码如下:
p.next=none # 原来p结点指向删除的none结点
p.next=None # 现在的p结点指向None
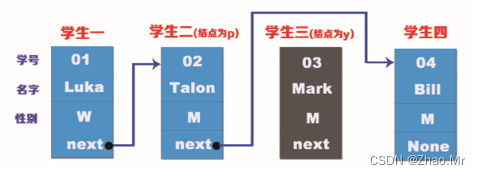
可以看出,如果要删除链表内的结点,只要将待删除结点的前一个结点p指向要删除结点的下一个结点即可。
例如,删除的结点为y,用Python算法实现代码如下:
y=p.next # 删除结点
p.next=y.next # 上一个结点等于删除结点的下一个结点
链表删除数据,具体代码如下:
import sys
"""
功能:创建链表结点
"""
class student:
def __init__(self):
self.number=0 # 学生学号
self.name='' # 学生姓名
self.sex = '' # 学生性别
self.next=None # 指向下一个结点
"""
功能:删除链表中的结点
"""
def del_ptr(head,ptr):
top=head # 指向链表头结点
if ptr.number==head.number: # 删除链表头结点
head=head.next
print('已删除学号 %d 同学 姓名:%s 性别:%s' %(ptr.number,ptr.name,ptr.sex))
else:
while top.next!=ptr: # 找到删除结点的前一个位置
top=top.next
if ptr.next==None: # 删除链表末尾的结点
top.next=None
print('已删除学号 %d 同学 姓名:%s 性别:%s' %(ptr.number,ptr.name,ptr.sex))
else:
top.next=ptr.next # 删除链表中的任意一个结点
print('已删除学号 %d 同学 姓名:%s 性别:%s' %(ptr.number,ptr.name,ptr.sex))
return head # 返回链表
findword=0
name_data=['Luck','Talon','Mark','Bill'] # 学生姓名
data=[[1,"Woman"],[2,"Man"],[3,"Man"],[4,"Man"]] # 学生学号、性别
print('学号 性别 ')
print('-----------')
for i in range(4): # 遍历输出链表数据
for j in range(1):
print('%2d %3s ' %(data[j+i][0],data[j*2+i][1]),end='')
print()
head=student() # 建立链表头部
if not head:
print('Error!! 内存分配失败!!')
sys.exit(0)
head.number=data[0][0] # 初始化头结点学号
head.name=name_data[0] # 初始化头结点姓名
head.sex=data[0][1] # 初始化头结点性别
head.next=None
ptr=head
for i in range(1,4): # 建立链表
new_node=student()
new_node.number=data[i][0]
new_node.name=name_data[i]
new_node.sex=data[i][1]
new_node.number=data[i][0]
new_node.next=None
ptr.next=new_node
ptr=ptr.next
while(True):
findword=int(input('请输入要删除的学号,输入0表示结束删除过程,请输入:'))
if(findword==0): # 循环中断条件,输入0程序结束
break
else: # 否则,根据学号删除学生
ptr=head
find=0
while ptr!=None:
if ptr.number==findword: # 判断学号是否在链表中,是则删除
ptr=del_ptr(head,ptr) # 调用删除函数
find=find+1
head=ptr
ptr=ptr.next
if find==0:
print('没有找到')
ptr=head
print('\t学号 姓名\t性别') # 打印剩余链表中的数据
print('\t----------------------------')
while(ptr!=None):
print('\t%2d\t %-5s\t%3s' %(ptr.number,ptr.name,ptr.sex))
ptr=ptr.next
print('\t----------------------------')
5. 单向链表的连接
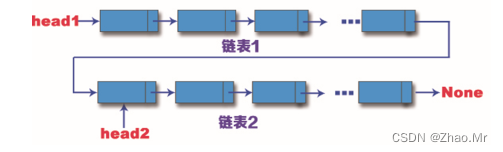
可以看出,链表的连接是将head1链表的最后一个结点连接到head2指向的链表的头结点,这样就可以完成链表的连接。
例如,p是连接两个链表之后的大链表指针,用Python代码实现连接的算法如下:
p=head1 # 指向头结点为head1的链表
while p.next!=None: # p.next直到为None时,表示head1到尾结点,跳出循环
p=p.next # 循环指向head1链表的结点
p.next=head2 # 将head1的尾结点链接到head2的头结点上
连接两个职员链表,具体代码如下:
import sys
import random
"""
功能:将两个职员链表连接
参数:head1:职员1链表头结点
head2:职员1链表头结点
"""
def connect_list(head1, head2):
p = head1 # 指向头结点为head1的链表
while p.next != None: # p.next直到为None时,表示head1到了尾结点,跳出循环
p = p.next # 循环指向head1链表的结点
p.next = head2 # 将head1的尾结点链接到head2的头结点上
return head1
class employee: # 创建职员结点
def __init__(self):
self.num = 0 # 职员工位号
self.salary = 0 # 职员薪资
self.name = '' # 职员姓名
self.next = None # 指向下一个结点
findword = 0
data = [[None] * 2 for row in range(4)] # 列表推导式
employee_data1 = ['张三', '李四', '王五', '刘六'] # 链表1职员姓名
employee_data2 = ['狗剩', '二狗', '铁蛋', '钢镚'] # 链表2职员姓名
for i in range(4): # 遍历职员
data[i][0] = i + 1
data[i][1] = random.randint(5000, 10000) # 随机在(5000, 10000)之间生成薪资
head1 = employee() # 建立第一组链表的头部
if not head1:
print('Error!! 内存分配失败!!')
sys.exit(0)
head1.num = data[0][0] # 职员1链表头部工位号
head1.name = employee_data1[0] # 职员1链表头部姓名
head1.salary = data[0][1] # 职员1链表头部薪资
head1.next = None # 指向尾结点
p = head1
for i in range(1, 4): # 建立第一组链表
new_node = employee()
new_node.num = data[i][0] # 职员1链表工位号
new_node.name = employee_data1[i] # 职员1链表姓名
new_node.salary = data[i][1] # 职员1链表薪资
new_node.next = None
p.next = new_node
p = p.next
for i in range(4):
data[i][0] = i + 5
data[i][1] = random.randint(5100, 10000)
head2 = employee() # 建立第二组链表的头部(和第一组链表一样)
if not head2:
print('Error!! 内存分配失败!!')
sys.exit(0)
head2.num = data[0][0]
head2.name = employee_data2[0]
head2.salary = data[0][1]
head2.next = None
p = head2
for i in range(1, 4): # 建立第二组链表
new_node = employee()
new_node.num = data[i][0]
new_node.name = employee_data2[i]
new_node.salary = data[i][1]
new_node.next = None
p.next = new_node
p = p.next
i = 0
p = connect_list(head1, head2) # 调用connect_list()函数将链表相连
print('两个链表相连的结果为:')
while p != None: # 打印链表的数据
print("◆",p.num," " *3,p.name," "*3,p.salary,"◇" )
print()
p = p.next
6. 单向链表的反转
了解单向链表的添加和删除操作之后,发现在链表结构中添加结点和删除结点都比较容易,从头到尾输出链表也不是什么难事。这是因为我们知道单向链表中的每个结点都会指向下一个结点,知道了一个结点的位置,整个链表的每个结点就都知道了。但是如果想反转过来输出链表,知道一个链表的位置,却不能知道此结点的上一个结点位置,该如何入手呢?
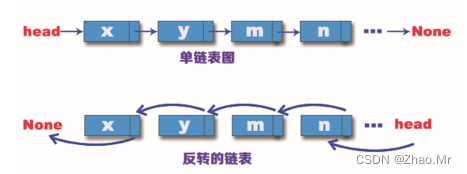
在Python算法中,实现单向链表反转的具体代码如下:
"""
功能:链表反转
参数:head是链表的头结点
"""
def reverse(head):
p= head # 定义变量p指向head
q=None # q是p的前一个结点
while p!=None:
a=q # 将a接到q之后
q=p # 将q接到p之后
p=p.next # p移到下一个结点
q.next=a # q连接到之前的结点
return q
从代码中可以看到,实现单向链表反转需要用到三个变量:p、q、a,接下来我们来看这一段程序的反转过程。
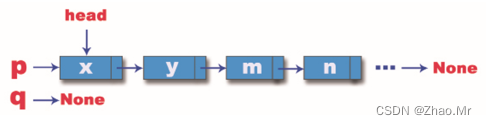
步骤1:执行while语句前,变量p指向了头结点,变量q为空,此时链表的情况如图所示。
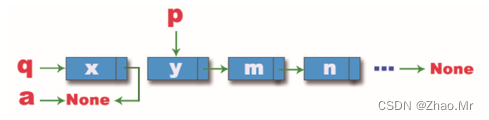
步骤2:执行第一次while循环,借助变量a,将变量a接到变量q之后,将变量q接到变量p之后,变量p结点向下一个结点移动,再将变量q连接到之前的结点,此时链表的情况如图所示。
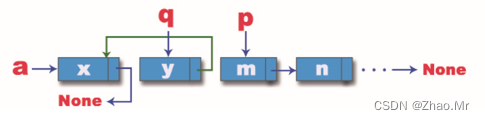
步骤3:执行第二次while循环,这次将变量q的位置交接给变量a,变量p的位置交接给变量q,变量p再向下一个节点移动,最后将变量q的结点连接到之前的结点变量a上,此时链表的情况如图所示。
步骤4:执行第三次循环,再次将变量q交接给变量a,变量p交接给变量q,变量p再向下一个结点移动,然后变量q连接到之前的结点变量a上,此时链表的情况如图所示。
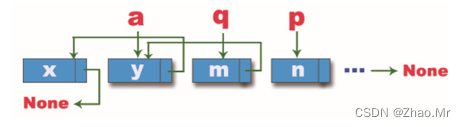
直到p=None时,整个单向链表就反转过来了,最终链表反转如图25所示。
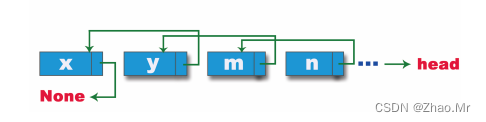
反转学生链表,具体代码如下:
import sys
"""
功能:创建链表结点
"""
class student:
def __init__(self):
self.number=0 # 学生的学号
self.name='' # 学生的姓名
self.sex = '' # 学生的性别
self.next=''
findword=0
name_data=['Luck','Talon','Mark','Bill'] # 链表学生名字
data=[[1,"Woman"],[2,"Man"],[3,"Man"],[4,"Man"]] # 链表学生学号和性别
head=student() # 建立链表头部
if not head:
print('Error!! 内存分配失败!!')
sys.exit(0)
head.number=data[0][0] # 链表头部学生学号
head.name=name_data[0] # 链表头部学生姓名
head.sex=data[0][1] # 链表头部学生性别
head.next=None
ptr=head
for i in range(1,4): # 建立链表
new_node=student()
new_node.number=data[i][0] # 初始化链表学生学号
new_node.name=name_data[i] # 初始化链表学生姓名
new_node.sex=data[i][1] # 初始化链表学生性别
new_node.next=None
ptr.next=new_node # 指向学生链表下一个结点
ptr=ptr.next
ptr=head
i=0
print('反转前的学生链表结点数据:')
while ptr !=None: # 打印链表数据
print('☆ %2d\t %-1s\t%-3s ☆' %(ptr.number,ptr.name,ptr.sex), end='')
i=i+1
if i>=1: # 一个数据为一行
print()
i=0
ptr=ptr.next # 指向下一个结点
ptr=head
before=None
print('\n反转后的学生链表结点数据:')
while ptr!=None: # 链表反转,利用三个指针,反转指针核心
last=before
before=ptr
ptr=ptr.next
before.next=last
ptr=before
while ptr!=None: # 打印链表数据
print('★ %2d\t %-1s\t%-3s ★' %(ptr.number,ptr.name,ptr.sex), end='')
i=i+1
if i>=1: # 一个数据为一行
print()
i=0
ptr=ptr.next
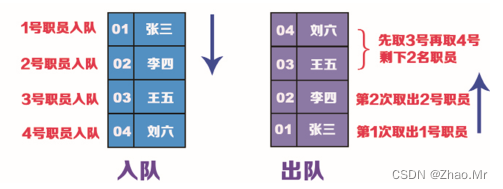
7. 堆栈、队列与链表
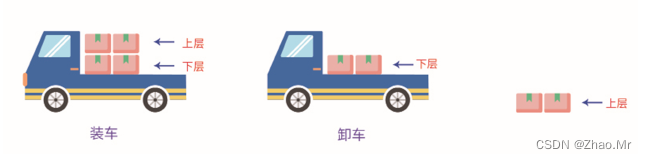
堆栈与队列都是比较抽象的数据结构,它们在计算机领域的应用都很广。堆栈多用于递归调用。堆栈简单来说就是将数据一层一层堆积起来,要想获取数据,需要先将后堆的数据取出,堆栈的数据结构是典型的“后进先出”结构。生活中也有很多类似堆栈的例子,例如装卸货车,把商品一层一层堆在货车上,卸货车时,需要从最后堆的上面一层开始卸。
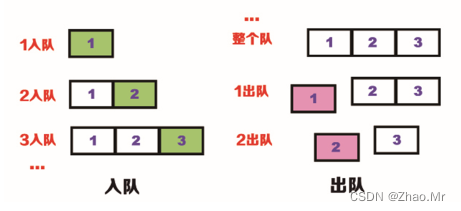
而队列不同,队列就像排队一样,刚来的人入队时要排在队尾,每次出队的都是队首的人,它的数据结构是典型的“先进先出”。
7.1 用链表实现堆栈
使用链表实现堆栈的优点是可以随时动态改变链表的长度,能有效地利用内存空间,保证不浪费内存,实现用多大就申请多大的内存空间的功能。但这种功能有利也有弊,它的缺点就是设计的算法有点复杂。但是理解了堆栈的本质,该算法也不难理解,接下来我们来看用Python链表算法如何实现堆栈。
(1)声明堆栈的链表结点
"""
功能:定义堆栈链表结点类
"""
class Node:
def __init__(self):
self.data=0 # 声明堆栈数据
self.next=None # 堆栈用来指向下一个结点
top=None # 声明顶端并初始化
(2)判断堆栈链表是否为空
"""
功能:判断堆栈链表是否为空
"""
def is_empty():
global top # 将top声明为全局变量
if(top==None): # 顶端为None
return 1 # 返回1
else: # 否则
return 0 # 返回0
(3)将数据压入堆栈
"""
功能:将数据压入堆栈中
"""
def push(data):
global top
new_node=Node() # 新结点
new_node.data=data # 将数据指定为结点的内容
new_node.next=top # 将新结点指向堆栈的顶端
top=new_node # 新结点成为堆栈的顶端
(4)将数据弹出堆栈(从堆栈中取数据)
"""
功能:将数据弹出
"""
def pop():
global top
if is_empty(): # 判断堆栈链表是否为空
print("当前堆栈链表为空")
return -1 # 退出程序
else:
p=top # 指向堆栈的顶端
top=top.next # 将堆栈顶端指向下一个结点
temp=p.data # 弹出数据
return temp # 将从堆栈中弹出的数据返回给主程序
使用链表实现堆栈
"""
功能:定义堆栈链表结点类
"""
class Node:
def __init__(self):
self.data=0 # 声明堆栈数据
self.next=None # 堆栈来指向下一个结点
top=None # 声明顶端并初始化
"""
功能:判断堆栈链表是否为空
"""
def is_empty():
global top # 将top声明为全局变量
if(top==None): # 顶端为None
return 1 # 返回1
else: # 否则
return 0 # 返回0
"""
功能:将数据压入堆栈中
"""
def push(data):
global top
new_node=Node() # 新结点
new_node.data=data # 将数据指定为结点的内容
new_node.next=top # 将新结点指向堆栈的顶端
top=new_node # 新结点成为堆栈的顶端
"""
功能:将数据弹出
"""
def pop():
global top
if is_empty(): # 判断堆栈链表为空
print("当前堆栈链表为空")
return -1 # 退出程序
else:
p=top # 指向堆栈的顶端
top=top.next # 将堆栈顶端指向下一个结点
temp=p.data # 弹出数据
return temp # 将从堆栈中弹出的数据返回给主程序
while True:
i=int(input("1:向堆栈中压入数据,2;堆栈中弹出,3:退出堆栈操作:请输入您的选择: "))
if i==1:
data = int(input("请输入要压入的数据:"))
push(data) # 调用堆栈压入数据函数
elif i==2:
print("弹出的数据为", pop()) # 调用堆栈弹出数据函数
elif i==3:
break # 退出堆栈操作,即退出循环
print("---------------------------------------")
while(not is_empty()): # 将数据陆续从顶端弹出
print('堆栈弹出的顺序为:%d' %pop())
print("---------------------------------------")
print("可以看出:先压入的数据后弹出,后压入的数据先弹出")
可以看出压入数据和弹出数据的情况。

7.2 用链表实现队列
队列也可以用链表实现,在定义队列方法时,要包含指向队列前端和队列末端的指针。接下来我们来看用Python链表算法如何实现队列。
我们用职员的姓名和工号来建立队列。
(1)建立职员队列链表结点
"""
功能:定义职员队列链表
"""
class worker:
def __init__(self):
self.name=''*20 # 职员名字
self.number=0 # 职员工位号
self.next=None # 队列中指向下一个结点
fore=worker()
end=worker()
fore=None # 队列前端指针
end=None # 队列末尾指针
(2)将数据加入队列中
"""
功能:将数据加入到队列中
参数:name:表示职员名字
number:表示职员工位号
"""
def add_queue(name,number):
global fore
global end
new_data=worker() # 分配内存给新数据
new_data.name=name # 为新数据赋值
new_data.number=number # 为新数据赋值
if end==None: # 如果end为None,表示这是第一个元素
fore=new_data
else:
end.next=new_data # 将新数据连接到队列末尾
end=new_data # 将end指向新数据,这是新数据的末尾
new_data.next=None # 新数据之后再无其他数据
(3)取出队列中的数据
"""
功能:取出队列中的数据
"""
def out_queue():
global fore
global end
if fore==None: # 如果队列前端为None,表示这个队列为空
print("队列已经没有数据了")
else:#否则
print("姓名:",fore.name," 工号:",fore.number) # 输出信息
fore=fore.next # 将队列前端移到下一个元素
使用链表实现职员队列
"""
功能:定义职员队列链表
"""
class worker:
def __init__(self):
self.name=''*20 # 职员名字
self.number=0 # 职员工位号
self.next=None # 队列中指向下一个结点
fore=worker()
end=worker()
fore=None # 队列前端指针
end=None # 队列末尾指针
"""
功能:将数据加入到队列中
参数:name:表示职员名字
number:表示职员工位号
"""
def add_queue(name,number):
global fore
global end
new_data=worker() # 分配内存给新数据
new_data.name=name # 为新数据赋值
new_data.number=number # 为新数据赋值
if end==None: # 如果end为None,表示这是第一个元素
fore=new_data
else:
end.next=new_data # 将新数据连接到队列末尾
end=new_data # 将end指向新数据,这是新数据的末尾
new_data.next=None # 新数据之后再无其他数据
"""
功能:取出队列中的数据
"""
def out_queue():
global fore
global end
if fore==None: # 如果队列前端为None,表示这个队列为空
print("队列已经没有数据了")
else: # 否则
print("姓名:",fore.name," 工号:",fore.number) # 输出信息
# 将队列前端移到下一个元素
fore=fore.next
"""
功能:显示队列中的数据
"""
def show():
global fore
global end
p = fore # 从队列前端开始
if p== None: # 判断p为空,则队列为空
print('队列已空!') # 提示
else:
while p != None: # 从队列前端(fore)到队列末尾(end)遍历队列
print("姓名:",p.name,"\t工号:", p.number) # 输出队列信息
p = p.next # 指向下一个结点
i = 0 # 用于选择变量
while True:
i = int(input("1:向队列加入数据 2:从队列中取出数据 3:显示队列中数据 4:退出程序,请选择:"))
if i == 1: # 选择1
name = input("姓名: ") # 输出职员姓名
score = int(input("工位号: ")) # 输入职员工位号
add_queue(name, score) # 向队列中加入数据
elif i == 2: # 选择2
out_queue() # 在队列中取出数据
elif i==3: # 选择3
show() # 显示在队列中未取出的数据
elif i == 4: # 选择4
break # 退出程序
else: # 否则
print("输入有误") # 提示输入有误
可以看出在队列中加入数据和取出数据的情况。