文章目录
- 大数据:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型以及价值密度四大特征。
- Hadoop:是一个能够对大量数据进行分布式处理的软件框架,用户可以利用Hadoop生态体系开发和处理海量数据。由于Hadoop有可靠及高效的处理性能,使得它逐渐成为分析大数据的领先平台。Hadoop的核心是HDFS和MapReduce。
- HDFS:Hadoop的分布式文件系统,它是Hadoop生态系统中的核心项目之一,是分布式计算中数据存储管理基础,是解决海量大数据文件存储的问题,是目前应用最广泛的分布式文件系统。
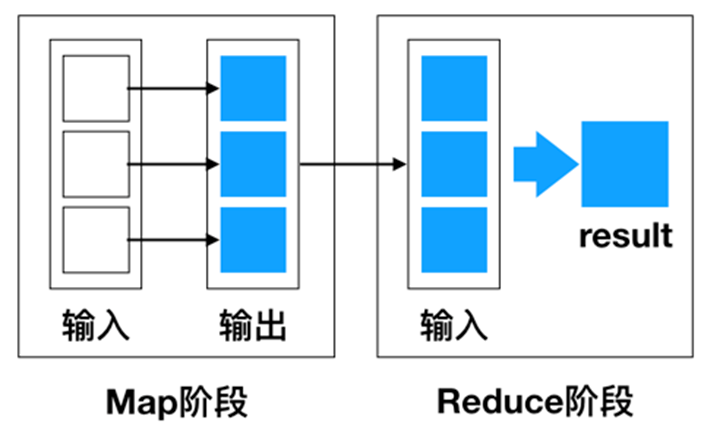
- MapReduce:Hadoop的分布式计算框架,是一种计算模型,用于大规模数据集(大于1TB)的并行运算。它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。
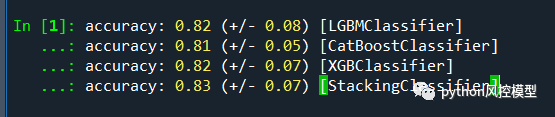
使用MapReduce执行计算任务的时候,每个任务的执行过程都会被分为两个阶段,分别是Map和Reduce,其中Map阶段用于对原始数据进行处理,Reduce阶段用于对Map阶段的结果进行汇总,得到最终结果。
- Yarn:(Yet Another Resource Negotiator)是Hadoop 2.0中的资源管理器,它可为上层应用提供统一的资源管理和调度。
- Sqoop:Hadoop的数据迁移工具,是一款开源的数据导入导出工具,主要用于在Hadoop与传统的数据库间进行数据的转换。
- Mahout:Hadoop的数据挖掘算法库,是Apache旗下的一个开源项目,它提供了一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员方便快捷地创建智能应用程序。
- HBase:Hadoop的分布式存储系统,是Google Bigtable克隆版,它是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
- Zookeeper:Hadoop的分布式协作服务,是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和HBase的重要组件。
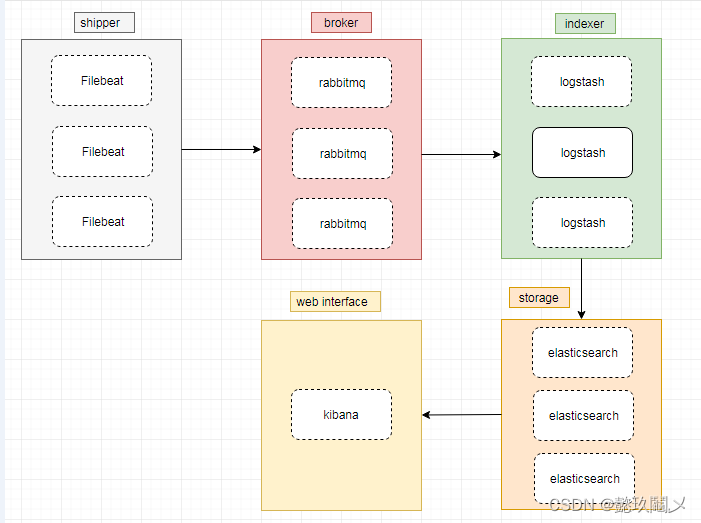
- Flume:Hadoop的日志收集工具,是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
- Shell:在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。