📌前言:本篇博客介绍如何速通MySQL的第二篇,主要介绍Mysql中主要的基础的入门,学习MySQL之前要先安装好MySQL,如果还没有安装的小伙伴可以看看博主前面的博客,里面有详细的安装教程。或者看一下下面这个链接,以及第一篇还没看的也建议先看第一篇噢~
🚀如何安装Mysql
🚀【MySQL】如何速通MySQL(1)
🚀【MySQL】如何速通MySQL(2)
在第二篇如何速通MySQL中我们学习了Mysql的增删改查(基础),有基础部分就有进阶部分嘛,所以本篇博客就对MySQL中的增删改查进阶进行学习~话不多说,走起!
MySQL如何速通MySQL
- 一、MySQL增删改查(进阶)
- 1.数据库约束
- ① 增加举例数据
- ② NULL约束
- ③ UNIQUE:唯一约束
- ④ DEFAULT:默认值约束
- ⑤ PRIMARY KEY:主键约束
- ⑥ FOREIGN KEY:外键约束
- ⑦ 自增主键
- 2.新增查询
- 3.聚合查询
- 4.Having和Group by子句
- 二.表的设计
- 1.一对一
- 2.一对多
- 3.多对多
一、MySQL增删改查(进阶)
📢对于MySQL的进阶内容,主要从约束,表的设计,以及更多的查询说起,在前面的增删改查中,我们的很多数据处理是不够严谨的,也只是在一张表上做文章,所有我们还得对MySQL有更多的认识。
1.数据库约束
对于数据库来说,约束,就是数据库针对里面的数据能写啥,给出的一组"检验规则",这样的约束,可以是程序员人工保证,但是人和计算机比,总是没那么靠谱,所以让程序自动保证,可以提高效率,提高准确性,让数据库这个软件集成的一个针对数据校验的功能。下面的这些约束,都是在我们创建表的时候,在后面加上的。
我们先了解一下有哪些约束:
| 约束类型 | 说明 |
|---|---|
| NOT NULL | 指示某列不能存储 NULL 值 |
| UNIQUE | 保证某列的每行必须有唯一的值 |
| DEFAULT | 规定没有给列赋值时的默认值 |
| PRIMARY KEY | NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录 |
| FOREIGN KEY | 保证一个表中的数据匹配另一个表中的值的参照完整性 |
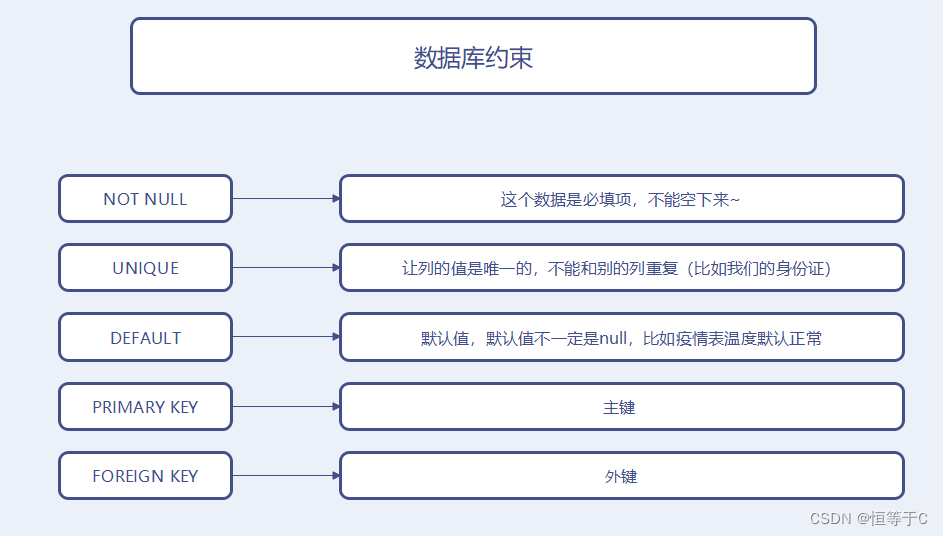
然后对于每个约束都举个栗子~
① 增加举例数据
create table student(id int, name varchar(20), class_id int);//学生表
create table score(stu_id int,math decimal(3,1),chinese decimal(3,1),english decimal(3,1));//成绩表
create table class(id int,name varchar(20));//班级表
//新增学生数据
insert into student values
(1001,'jame',1),
(1002,'lisa',2),
(1003,'curry',2),
(1004,'marry',1),
(1005,'rose',2);
//新增成绩数据
insert into score values
(1001,99,85,71),
(1002,85,77,91),
(1003,99,52,67),
(1004,76,82,68),
(1005,81,45,54);
//新增班级数据
insert into class values
(1,'Java01'),
(2,'python01');
新增完成后分别查询,结果为:
mysql> select * from student;
+------+-------+----------+
| id | name | class_id |
+------+-------+----------+
| 1001 | jame | 1 |
| 1002 | lisa | 2 |
| 1003 | curry | 2 |
| 1004 | marry | 1 |
| 1005 | rose | 2 |
+------+-------+----------+
5 rows in set (0.00 sec)
mysql> select * from class;
+------+----------+
| id | name |
+------+----------+
| 1 | Java01 |
| 2 | python01 |
+------+----------+
2 rows in set (0.00 sec)
mysql> select * from score;
+--------+------+---------+---------+
| stu_id | math | chinese | english |
+--------+------+---------+---------+
| 1001 | 99.0 | 85.0 | 71.0 |
| 1002 | 85.0 | 77.0 | 91.0 |
| 1003 | 99.0 | 52.0 | 67.0 |
| 1004 | 76.0 | 82.0 | 68.0 |
| 1005 | 81.0 | 45.0 | 54.0 |
+--------+------+---------+---------+
5 rows in set (0.00 sec)
② NULL约束
✅在我们填很多东西的时候,有一些空为必填项,也就是不能为空,那么这种设置就是类似于我们这里的NULL约束,创建表时,可以指定某列不为空。我们就以创建teacher表来举例:
create table teacher (
id int not null,//在这里id后面加入not null
name varchar(20),
class_id int
);
在创建表后,我们在加入数据的时候,id这一项就不可以再设置为null了,比如我们可以试一下:
mysql> insert into teacher values(null,'fat',1);
ERROR 1048 (23000): Column 'id' cannot be null//直接错误提示为不能是null
③ UNIQUE:唯一约束
✅前面的是不能为空,而这里我们的是唯一约束,很多时候的数据都是唯一的,我们的电话号码,身份证号,考生号等等,所以这里我们用unique来指定列为唯一的、不重复的:
create table teacher (
id int unique,//指定id列为唯一不能重复的列
name varchar(20),
class_id int
);
在创建后,我们同样可以作死去增加同样的数据,看看数据库报错:
mysql> insert into teacher values(1001,'aaa',1);
Query OK, 1 row affected (0.00 sec)//先加入一条id为1001的数据
mysql> insert into teacher values(1001,'bbb',2);
ERROR 1062 (23000): Duplicate entry '1001' for key 'id'//报错重复数据id
④ DEFAULT:默认值约束
✅在我们填写一些资料的时候,有一些是会给你设置自动的默认值,也就是当你不填的时候,系统就自己填充默认值,这里也是一样的,当我们不设置某个列的默认值的时候,默认值默认为null,但是我们可以自己设置:
create table teacher (
id int unique,
name varchar(20),
class_name varchar(20) default 'java01'//默认班级名为java01
);
创建好后,我们同样可以去新增创建试一试:
mysql> insert into teacher(id,name) values(1001,'aaa');//就填id和name,让数据库自动填充class_name
Query OK, 1 row affected (0.00 sec)
mysql> insert into teacher values(1002,'bbb','python01');//当然也可以自己填充数据
Query OK, 1 row affected (0.00 sec)
最后结果显示为:
mysql> select * from teacher;
+------+------+------------+
| id | name | class_name |
+------+------+------------+
| 1001 | aaa | java01 |
| 1002 | bbb | python01 |
+------+------+------------+
2 rows in set (0.00 sec)
⑤ PRIMARY KEY:主键约束
✅正如上面表格写的,主键约束PRIMARY KEY是NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
create table teacher (
id int primary key,//设置id为主键
name varchar(20),
class_name varchar(20) default 'java01'
);
创建成功,尝试一下空值和重复值:
mysql> insert into teacher values(1001,'aaa','java01');//先增加一条数据
Query OK, 1 row affected (0.00 sec)
mysql> insert into teacher values(null,'bbb','java01');
ERROR 1048 (23000): Column 'id' cannot be null//id列不能为空
mysql> insert into teacher values(1001,'bbb','java01');
ERROR 1062 (23000): Duplicate entry '1001' for key 'PRIMARY'//主键数据不能重复
⑥ FOREIGN KEY:外键约束
✅外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列)
MySQL 外键是指在一个表中定义的一个或多个字段,它们与其他表的字段建立关联,以确保数据的完整性以及约束性。外键可以用来限制插入或更新数据的操作,以确保关联表中的数据一致性。
也就是说,当我们的查询需要更大的舞台的时候,在联合其他表的时候,为了确保数据的完整性以及约束性,就需要用到外键约束。
比如说:
create table student(
id int PRIMARY KEY auto_increment,
name varchar(20),
class_id int
FOREIGN KEY (class_id) REFERENCES class(id)
//意思是这个表的class_id作为class表id的外键
);
create table class(
id int,
name varchar(20)
);
⑦ 自增主键
✅MySQL数据库中,自增主键是一个非常常用的关系型数据库特性。一个自增主键是指一个整数类型(通常是INT)的字段,其值随着每一行的插入自动递增。自增主键通常被用作表中的唯一标识符,以方便数据检索和处理。
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,//默认自己增加
name VARCHAR(50) NOT NULL,
email VARCHAR(50) NOT NULL
);
关于数据库约束:
主键约束外键,在主键没有的情况下,外键是无法创建成功的,而外键也约束着主键,在外键与主键绑定的时候,主键无法直接被删除。子表中的记录,需要在父表中存在,所以为了操作更快,需要给父表指定列设置索引,设置成主键/unique(自带索引)
2.新增查询
📣我们在之前的文章中,对于表数据的查询,新增都见过,那新增查询是什么呢,为了提高插入数据的效率,我们可以使用 INSERT INTO SELECT 语句将一个表的数据插入到另一个表中,也就是将查询结果的数据作为另一个表的新增数据。
比如说:
1.创建两个数据表
mysql> create table student(id int, name varchar(20), class_id int);//全级的学生数据
mysql> create table student01 (id int , name varchar(20));//1班的学生数据
2.新建查询
mysql> insert into student01 (id, name) select id, name from student where class_id = 1;//将班级id为1班的查询数据插入student01
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
3.查询结果
mysql> select * from student01;
+------+-------+
| id | name |
+------+-------+
| 1001 | jame |
| 1004 | marry |
+------+-------+
2 rows in set (0.00 sec)
3.聚合查询
📣有时候我们需要用到一些统计数据,那么对于数据库来说也会需要,所以就有聚合查询,类似于excel表的函数,但没有那么的精细。常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
下面统一举个例子大家就了解啦:
① count
count是计算该列数据的总和,也就是这一行有多少数据。
mysql> select count(id) from student;//查询student表有多少学生
+-----------+
| count(id) |
+-----------+
| 5 |
+-----------+
1 row in set (0.00 sec
② sum
sum就是相当于算总和,是数字然后可以加起来的才有意义。
mysql> select sum(math) from score;//查询学生数学成绩总和
+-----------+
| sum(math) |
+-----------+
| 440.0 |
+-----------+
1 row in set (0.00 sec)
③ avg
avg就是查平均值,将总和平均的数据
mysql> select avg(math) from score;
+-----------+
| avg(math) |
+-----------+
| 88.00000 |
+-----------+
1 row in set (0.00 sec)
④ max & min
max & min是最大值和最小值,同样是不是数字没有意义。
mysql> select max(math),min(english) from score;//查看学生成绩数学最高分和英语最低分
+-----------+--------------+
| max(math) | min(english) |
+-----------+--------------+
| 99.0 | 54.0 |
+-----------+--------------+
1 row in set (0.00 sec)
4.Having和Group by子句
📣HAVING 子句和 GROUP BY 子句都是与 SQL 查询中的聚合函数(如 COUNT、SUM、AVG 等)相关的一些子句。
① GROUP BY 子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
简单来说,就是我们的表中会有很多数据,为了更明显的查询到我们需要的数据,如果一个公司的工资表,我们用聚合函数去查询最大值的时候,很明显查到的都是大佬的工资,我们普遍的草根老百姓哪有这上限,所以我们可以根据岗位来分组查询:
create table company(//创建公司表
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary decimal(11,2)
);
insert into company(name, role, salary) values//增加数据
('虾兵','小弟', 1599.20),
('蟹将','小弟', 2000.99),
('东海龙王','总经理', 9999.11),
('南海龙王','副经理', 7333.5),
('隔壁老王','董事长', 99900.33),
('白龙马','副经理', 7000.66),
('西海龙王','副经理', 8000.66);
比如我们要查询各个职位的平均工资:
mysql> select role,avg(salary) from company;//错误演示
+------+--------------+
| role | avg(salary) |
+------+--------------+
| 小弟 | 19404.921429 |
+------+--------------+
1 row in set (0.00 sec)
你见过哪个小弟平均工资有这么多的,黑社会啊,所以我们就要加上group by子句来进行职业分组:
mysql> select role,avg(salary) from company group by role;//根据role进行分组查询
+--------+--------------+
| role | avg(salary) |
+--------+--------------+
| 副经理 | 7444.940000 |
| 小弟 | 1800.095000 |
| 总经理 | 9999.110000 |
| 董事长 | 99900.330000 |
+--------+--------------+
4 rows in set (0.00 sec)
② Having子句
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
也就是对分组后查询数据进行一个条件筛选,比如说上面的数据,那董事长是我们能一起对比的吗,财务不想干了吗,所以我们得屏蔽一下对董事长的数据:
mysql> select role,avg(salary) from company group by role having role != '董事长'; //用having子句来对分组结果再进行筛选
+--------+-------------+
| role | avg(salary) |
+--------+-------------+
| 副经理 | 7444.940000 |
| 小弟 | 1800.095000 |
| 总经理 | 9999.110000 |
+--------+-------------+
3 rows in set (0.00 sec)
二.表的设计
对于数据库来说,表是很重要的,所以我们在学习数据库操作的同时,也要了解关于表的设计,比如是需要记录全级同学的成绩,那我们怎么做比较好,要分成多少个表,每个表需要记录的数据有哪些等等。
表的设计关键:找到实体,确认实体间关系。
找到实体,就像我们上面说的:需要记录全级同学的成绩,那我们的实体就应该有,同学,班级,成绩等,然后以这些来做表,并且要关联他们。而在这些之前,我们要明确,对于表的设计,大体可以分为一对一,一对多和多对一。
1.一对一
首先是这种一对一的关系,以学校的教务系统为例,我们会有以下这两个表:
student表(学生id,学生姓名,学生班级....)其中有user_id
user表(用户账户,密码...)其中有student_id
两者的对应关系其实就是小学生造句一样:一个账户对应一个学生,一个学生也只有一个账号。
当我们要在数据库中表示这种一对一的关联关系,有两种方法:
📌 方法1.可以把这两个实体用一张表来表示。
📌方法2.可以用两张表来表示,其中一张表包含另一个表的id。
根据这个对应关系,就可以随时找到某个账户对应的学生是谁,也能找到某个学生对应的账户是啥了。
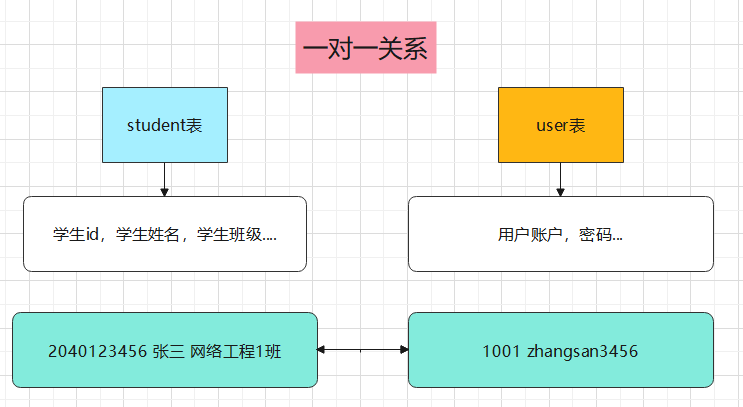
-- 一对一的意思就比如说
-- 一个学生只有一个账号
-- 一个账号只给一个学生
//设计表可以是下面几种情况
1.设计一个大表,包含学生信息 + 账号信息//太复制了,不清晰
account-student(accountid,username,password, studentName);
2.搞俩个表,相互关联//有点头重脚轻的意思
account(accountid, username, password, studentid);
student(studentid, name, ......);
3.同样是搞两个表
account(accountid, username, password);
student(studentid, studentName, accountid);
//一般使用这一种
2.一对多
那么一对多,其实也蛮好理解,还是以教务系统为例,这次我们的两个表分别是:
student表(学号,姓名....)
class表(班级编号,班级名称....)
来来来,这次我们的表是student表和class表,我们来造句:一个学生应该处于一个班级中,一个班级可以包含多个学生(一对多)。
然后在数据库中表示一对多的关系,就有两种典型的方案:
📌 方法1:在班级表中,新增一列,表示这个班级里的学生id都有啥。下图中,就是在class表中新增一列,然后张三等人就在这个班的学生列表。

📌 方法2:班级表不变,在学生表中,新增一列classid,也就是所在班级。如下图,就是在student表中增加一个学生班级,这里更容易体现一对多的关系。

那么对于一对多,是不是两种方法都可以呢?
实际上,在MySQL中,表示这种一对多的关系的时候,只能采用方案二,不能用方案一。因为MySQL中没有提供类似于"数组"这样的类型,所以我们存不了如方案一中新增的一列学生。但并不是所有数据库没有,像Redis的数据库就有数组类型,就可以考虑方案一这种方式表示。
-- 一对多对应举例可以是
-- 一个学生对应一个班级
-- 一个班级有多个学生
class(classid, className);
1 java101
2 java102
student(studentid, name, classid);
1 张三 1
2 李四 2
//张三李四对应上class表的classid
3.多对多
然后就是多对多,经过上面两个,相信大家也知道多对多是什么样子的了,这里我们还是用两个表表示这种关系:
student表(学号,姓名...)
grade表(课程编号,课程名称...)
然后我们来继续造句:一个学生可以选择多门课程,一个课程可以包含多名学生。
然后在数据库中,这种多对多的关系,只需要一招:使用关联表来表示两个实体的关系。
比如:
📑student表:
| student表 | 学号 | 姓名 |
|---|---|---|
| – | 2040123456 | 张三 |
| – | 2040124567 | 李四 |
| – | 2040125678 | 王五 |
📑grade表:
| grade表 | 课程编号 | 课程名称 |
|---|---|---|
| – | 1001 | 高等数学 |
| – | 1002 | 大学物理 |
| – | 1003 | 计算机网络 |
然后创建一个关联表,就是有学生学号,又有课程编号的表:
| 学生-课程关联表 | 学号 | 课程编号 |
|---|---|---|
| – | 2040123456 | 1001 |
| – | 2040123456 | 1002 |
| – | 2040124567 | 1001 |
这样子我们就可以清楚的了解他们的对应情况了,学号为2040123456的同学选择了课程编号为1001,1002的课程;课程编号为1001的课程,包含了学号为2040123456和2040124567的同学,就体现了这种多对多的关系了。
更简单的说法就是,张三李四选择了高等数学课,高等数学课上有张三李四。通过上面关联表的学号列,就可以看见每个同学选了哪些课。
有的时候,为了更方便的表示/找到实体之间的关系,尤其是针对复杂的场景,,先套入关系,选择对应方案进行设计。如果实体关系比较复杂,实体比较多,可以画图了解分析,实体关系图,也就是E-R图。在学校的数据库考试中,就经常会出现,必考,而且至少是一个大题。
这就是本篇如何速通MySQL第三部分的全部内容啦,接下来剩下一个部分,带你速通MySQL。欢迎关注。一起学习,共同努力!
还有一件事: