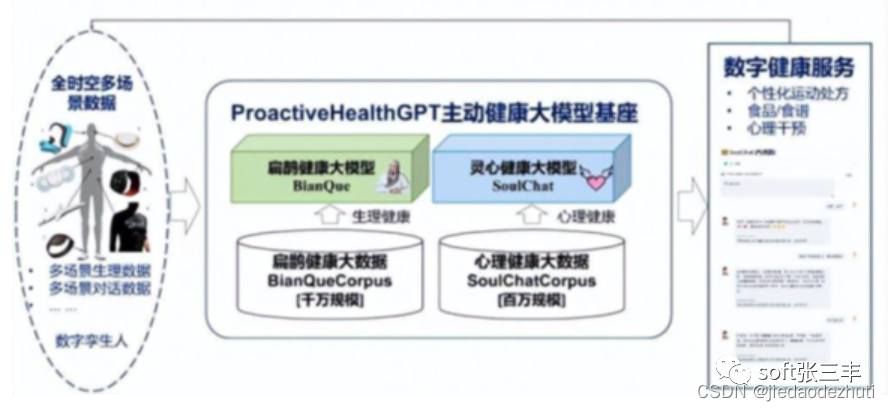
中文医疗大模型
中文医疗大模型是指通过利用自然语言处理技术和机器学习算法,在大量的医疗文本数据中预训练出来的模型。它可以实现对医疗信息的分类、摘要、问答系统、机器翻译等功能,是医疗行业中的重要工具。在医疗领域中,大规模语言模型(Large Language Model)具有广泛的应用潜力。
开源医疗大模型
目前,开源中文医疗大模型还没有特别成熟的项目,但是有一些相关的开源项目和数据集可以使用。
- MedBERT:由清华大学自然语言处理与社会人文计算实验室(THUNLP)开发的基于BERT模型的医疗领域预训练模型,可以用于中文医疗文本的处理和分析。项目地址:
https://github.com/ymcui/Medical-Transformer - CMeIE:由中国科学院计算技术研究所开发的中文医疗实体识别和关系抽取工具包,基于深度学习模型,可以用于从中文医疗文本中提取实体和关系。项目地址:
https://github.com/csking1/CMeIE - 中文医疗问答数据集:由哈工大社会计算与信息检索研究中心发布的中文医疗问答数据集,包含了大量的医疗领域问题和对应的答案。可以用于训练医疗问答系统等任务。
数据集地址:
https://github.com/zhangsheng93/Chinese-Health-Question-Answering-Dataset
这些开源项目和数据集可以为中文医疗大模型的开发提供一些基础资源,但是需要根据具体的应用场景和需求进行进一步的开发和调优。
华佗 GPT
HuatuoGPT(华佗 GPT)是开源中文医疗大模型,基于医生回复和 ChatGPT 回复,让语言模型成为医生,提供丰富且准确的问诊。

HuatuoGPT 致力于通过融合 ChatGPT 生成的 “蒸馏数据” 和真实世界医生回复的数据,以使语言模型具备像医生一样的诊断能力和提供有用信息的能力,同时保持对用户流畅的交互和内容的丰富性,对话更加丝滑。