1. diffusion
(0) 总结
可以参考此处:https://blog.csdn.net/weixin_40920183/article/details/130652651
https://zhuanlan.zhihu.com/p/599887666
总的来说,diffusion就是分为训练和采样两个阶段。
(A)训练阶段:其中,训练阶段的目标是将加噪后的隐向量输入到UNetModel 来输出预估噪声,和真实噪声信息标签(初始化使用随机高斯噪声Gaussian Noise)作比较来计算 KL 散度 loss,并通过反向传播算法更新 UNetModel 模型参数;引入文本向量 context 后,UNetModel 在训练时把其作为 condition,利用注意力机制(具体来说就是把文本特征作为V,时序信息作为K,UNet中间层的输出作为Q,然后计算这样的跨模态注意力图,从而将文本信息融入到图像中)来更好地引导图像往文本向量方向生成。注意,这个阶段的目标是学习将加噪后的图片,与真实噪声尽可能地相近,目标就是要让图片最后变成一个高斯分布的噪声。注意,这个过程会记录下每一步图片->加噪图片的参数信息,在之后的采样阶段,这些可学习参数将会被直接用来进行反向推理。注意,加噪100步,那么100个时间步的噪声是一次性都加入进去的!只不过一次迭代是不足以完成加噪学习过程,需要进行很多次迭代。此外,训练过程的Steptime,时使用随机步长的!避免陷入局部最优!
小细节:(1)用 AutoEncoderKL 自编码器把输入图片从像素空间映射到隐向量空间,把 RGB 图片转换到隐式向量表达。其中,在训练 Unet 时自编码器参数已经训练好和固定的,自编码器把输入图片张量进行降维得到隐向量。(2)用 FrozenCLIPEmbedder 文本编码器来编码输入提示词 Prompt,生成向量表示 context,这里需要规定文本最大编码长度和向量嵌入大小。(CLIP是一个图像-文本预训练模型:根据从网络上抓取的图像及其文字说明进行训练的。CLIP 是图像编码器和文本编码器的组合,它的训练过程可以简化为给图片加上文字说明)
(B)采样阶段:采样阶段就是将随机种子产生的随机噪声+ FrozenCLIPEmbedder 文本编码器把输入提示词 Prompt 得到的编码,然后送入训练好的UNetModel 模型,结合不同采样器(如 DDPM/DDIM/PLMS)迭代 T 次不断去除噪声,得到具有文本信息的隐向量表征。用 AutoEncoderKL 自编码器把上面得到的图像隐向量进行解码,得到被映射到像素空间的生成图像。注意,这里有个很核心的理论就是,逆向过程也服从高斯分布。
一般默认20步即可得到预期效果。采样过程就是将训练阶段得到的可学习参数 ε ε ε 直接应用在这个噪声数据上,通过贝叶斯法则,重参数技巧,大概简化即为 x 0 x_0 x0 * ε 1 ε_1 ε1 即可得到 x 1 x_1 x1 如此迭代下去,最后得到 x n x_n xn 即满意的效果图。
小细节:稳定扩散算法最适用于处理高斯噪声和一些常见的图像生成和处理任务。当你使用其他类型的噪声时(伯努利分布,二项分布,泊松分布,Gamma分布,均匀分布,指数分布),算法的效果可能会有所下降,因此可能需要进行适当的调整和改进。具体来说,如果高斯噪声改变,比如在你做的分子生成任务中,那么是要达到某种目的的,比如旋转平移不变性,那么噪声的均值和方差会改变,得到的生成结果也会具有和噪声一样的性质的结果。自然图像中就是高斯分布,所以没必要更改均值和方差,改了的话对于损失函数就要更改,比如KL散度的平方。
(0-1) 文本到图像生成(Stable Diffusion)
High-Resolution Image Synthesis with Latent Diffusion Models(Latent Diffusion Models) CVPR2022
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。具体来说,得益于Stability AI的计算资源支持和LAION的数据资源支持,Stable Diffusion在LAION-5B的一个子集上训练了一个Latent Diffusion Models,该模型专门用于文图生成。
核心创新点:通过构建latent-diffusion-model(LDM) ,解决了之前直接在高维度特征建立扩散模型带来的资源消耗和精度限制 ,在多类下游任务中都实现了State-of-the-art。
(1)贡献:
- Diffusion model相比GAN可以取得更好的图片生成效果,然而该模型是一种自回归模型,需要反复迭代计算,因此训练和推理代价都很高。论文提出一种在潜在表示空间(latent space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。
- 相比于其它空间压缩方法(如),论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。
- 论文将该模型在无条件图片生成(unconditional image synthesis), 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。
- 论文还提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。这也为日后Stable Diffusion的开发奠定了基础。
(2)模型细节:
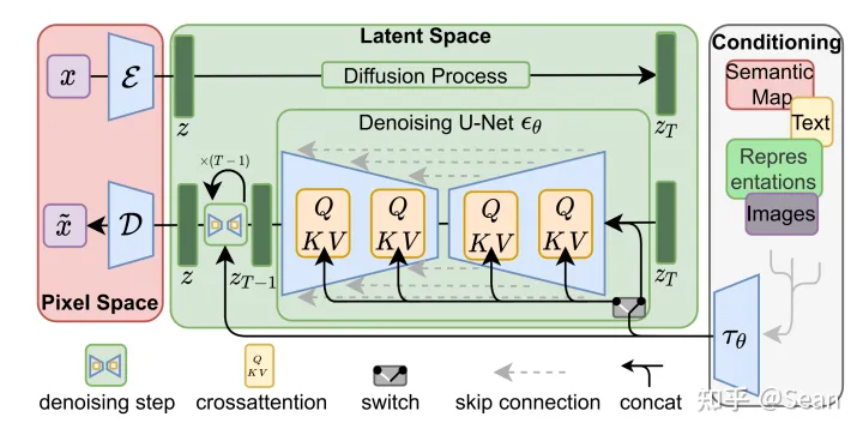
Latent Diffusion Models整体框架如图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E \mathcal{E} E 和一个解码器 D \mathcal{D} D)。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。个人认为这种将高维特征压缩到低维,然后在低维空间上进行操作的方法具有普适性,可以很容易推广到文本、音频、视频等领域。
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。但是有一个重要的地方是论文为diffusion操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
(0-2) 图片感知压缩(Perceptual Image Compression)
感知压缩本质上是一个tradeoff,之前的很多扩散模型没有使用这个技巧也可以进行,但原有的非感知压缩的扩散模型有一个很大的问题在于,由于在像素空间上训练模型,如果我们希望生成一张分辨率很高的图片,这就意味着我们训练的空间也是一个很高维的空间。
引入感知压缩就是说通过VAE这类自编码模型对原图片进行处理,忽略掉图片中的高频信息,只保留重要、基础的一些特征。这种方法带来的的好处就像引文部分说的一样,能够大幅降低训练和采样阶段的计算复杂度,让文图生成等任务能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛。
感知压缩主要利用一个预训练的自编码模型,该模型能够学习到一个在感知上等同于图像空间的潜在表示空间。这种方法的一个优势是只需要训练一个通用的自编码模型,就可以用于不同的扩散模型的训练,在不同的任务上使用。这样一来,感知压缩的方法除了应用在标准的无条件图片生成外,也可以十分方便的拓展到各种图像到图像(inpainting,super-resolution)和文本到图像(text-to-image)任务上。
由此可知,基于感知压缩的扩散模型的训练本质上是一个两阶段训练的过程,第一阶段需要训练一个自编码器,第二阶段才需要训练扩散模型本身。在第一阶段训练自编码器时,为了避免潜在表示空间出现高度的异化,作者使用了两种正则化方法,一种是KL-reg,另一种是VQ-reg,因此在官方发布的一阶段预训练模型中,会看到KL和VQ两种实现。在Stable Diffusion中主要采用 AutoEncoderKL这种实现。
具体来说,给定图像 x ∈ R H × W × 3 x \in \mathbb{R}^{H \times W \times 3} x∈RH×W×3 ,我们可以先利用一个编码器 E \mathcal{E} E 来将图像编码到潜在表示空间 z = E ( x ) z=\mathcal{E}(x) z=E(x) ,其中 z ∈ R h × w × c z \in \mathbb{R}^{h \times w \times c} z∈Rh×w×c ,然后再用解码器从潜在表示空间重建图片 x ~ = D ( z ) = D ( E ( x ) ) \tilde{x}=\mathcal{D}(z)=\mathcal{D}(\mathcal{E}(x)) x~=D(z)=D(E(x)) 。在感知压缩压缩的过程中,下采样因子的大小为 f = H / h = W / w f=H / h=W / w f=H/h=W/w ,它是2的次方,即 f = 2 m f=2^{m} f=2m。
(0-3) 潜在扩散模型(Latent Diffusion Models)
首先简要介绍一下普通的扩散模型(DM),扩散模型可以解释为一个时序去噪自编码器(equally weighted sequence of denoising autoencoders)
ϵ
θ
(
x
t
,
t
)
;
t
=
1
…
T
\epsilon_{\theta}\left(x_{t}, t\right) ; t=1 \ldots T
ϵθ(xt,t);t=1…T ,其目标是根据输入
x
t
x_{t}
xt 去预测一个对应去噪后的变体,或者说预测噪音,其中
x
t
x_{t}
xt 是输入
x
x
x 的噪音版本。相应的目标函数可以写成如下形式:
L
D
M
=
E
x
,
ϵ
∼
N
(
0
,
1
)
,
t
[
∥
ϵ
−
ϵ
θ
(
x
t
,
t
)
∥
2
2
]
L_{D M}=\mathbb{E}_{x, \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_{\theta}\left(x_{t}, t\right)\right\|_{2}^{2}\right]
LDM=Ex,ϵ∼N(0,1),t[∥ϵ−ϵθ(xt,t)∥22]
其中
t
t
t 从
{
1
,
…
,
T
}
\{1, \ldots, T\}
{1,…,T} 中均匀采样获得。
而在潜在扩散模型(LDM)中,引入了预训练的感知压缩模型,它包括一个编码器
E
\mathcal{E}
E 和一个解码器
D
\mathcal{D}
D 。这样就可以利用在训练时就可以利用编码器得到
z
t
z_{t}
zt,从而让模型在潜在表示空间中学习,相应的目标函数可以写成如下形式:
L
L
D
M
=
E
E
(
x
)
,
ϵ
∼
N
(
0
,
1
)
,
t
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
)
∥
2
2
]
L_{L D M}=\mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_{\theta}\left(z_{t}, t\right)\right\|_{2}^{2}\right]
LLDM=EE(x),ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t)∥22]
(0-4) 条件机制(Conditioning Mechanisms)
除了无条件图片生成外,我们也可以进行条件图片生成,这主要是通过拓展得到一个条件时序去噪自编码器(conditional denoising autoencoder)
ϵ
θ
(
z
t
,
t
,
y
)
\epsilon_{\theta}\left(z_{t}, t, y\right)
ϵθ(zt,t,y) 来实现的,这样一来我们就可通过
y
y
y 来控制图片合成的过程。具体来说,论文通过在UNet主干网络上增加cross-attention机制来实现
ϵ
θ
(
z
t
,
t
,
y
)
\epsilon_{\theta}\left(z_{t}, t, y\right)
ϵθ(zt,t,y) 。为了能够从多个不同的模态预处理
y
y
y ,论文引入了一个领域专用编码器(domain specific encoder)
τ
θ
\tau_{\theta}
τθ ,它用来将
y
y
y 映射为一个中间表示
τ
θ
(
y
)
∈
R
M
×
d
τ
\tau_{\theta}(y) \in \mathbb{R}^{M \times d_{\tau}}
τθ(y)∈RM×dτ ,这样我们就可以很方便的引入各种形态的条件(文本、类别、layout等等)。最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
)
⋅
V
,
with
Q
=
W
Q
(
i
)
⋅
φ
i
(
z
t
)
,
K
=
W
K
(
i
)
⋅
τ
θ
(
y
)
,
V
=
W
V
(
i
)
⋅
τ
θ
(
y
)
\begin{array}{l} \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d}}\right) \cdot V, \text { with } \\ Q=W_{Q}^{(i)} \cdot \varphi_{i}\left(z_{t}\right), K=W_{K}^{(i)} \cdot \tau_{\theta}(y), V=W_{V}^{(i)} \cdot \tau_{\theta}(y) \end{array}
Attention(Q,K,V)=softmax(dQKT)⋅V, with Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y)
(1) 摘要
通过将图像形成过程分解为去噪自编码器的顺序应用,扩散模型(DMs)在图像数据和其他数据上实现了最先进的合成结果。此外,它们的配方允许一个指导机制来控制图像生成过程,而无需再训练。然而,由于这些模型通常直接在像素空间中操作,因此优化功能强大的dm通常会消耗数百个GPU天,并且由于顺序评估而导致推理成本高昂。为了使DM训练在有限的计算资源上同时保持其质量和灵活性,我们将它们应用于强大的预训练自编码器的潜在空间。与之前的工作相比,在这种表示上训练扩散模型可以首次在复杂性降低和细节保存之间达到近乎最佳的点,极大地提高了视觉保真度。通过在模型架构中引入交叉注意层,我们将扩散模型转变为强大而灵活的生成器,用于一般条件输入(如文本或边界框),并以卷积方式实现高分辨率合成。我们的潜在扩散模型(ldm)在图像绘制和类别条件图像合成方面取得了最新的技术水平,并在各种任务上表现出极具竞争力的性能,包括无条件图像生成、文本到图像合成和超分辨率,同时与基于像素的DMs相比,显著降低了计算需求。