关联文章:【Elacticsearch】 原理/数据结构/面试经典问题整理_东方鲤鱼的博客-CSDN博客
-
建立索引的原理
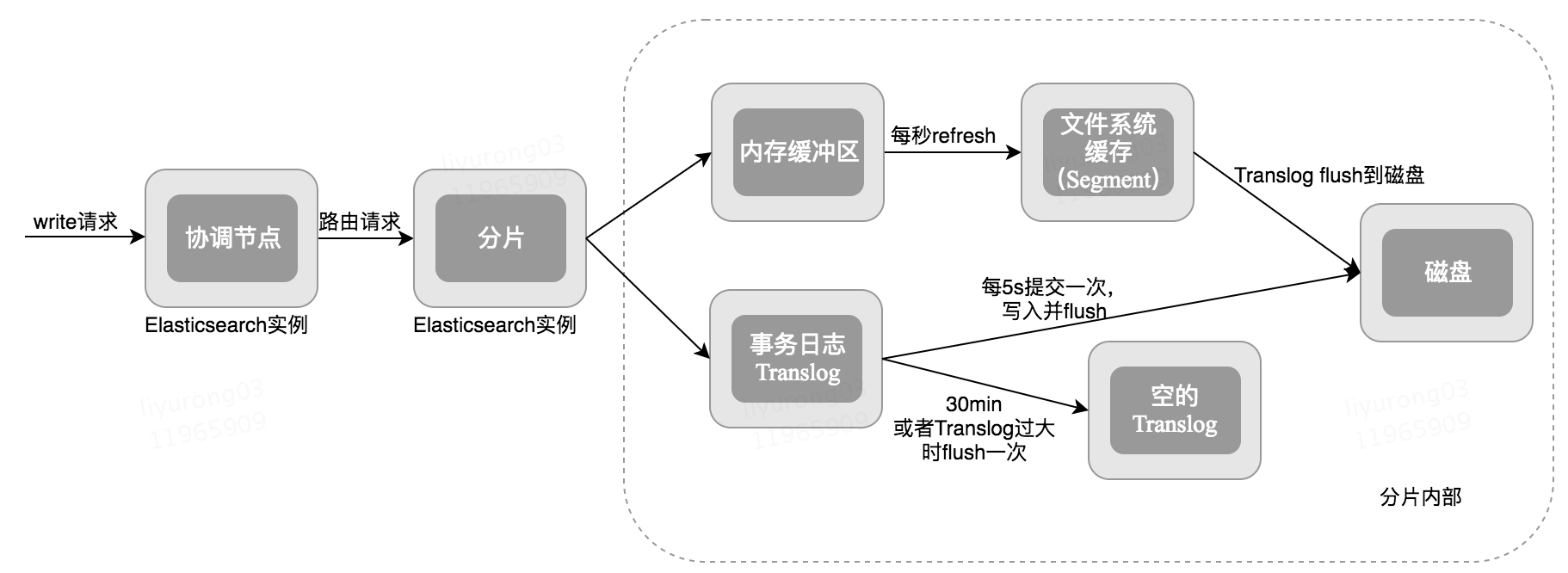
当向协调节点发送请求以索引新文档时,将执行以下操作:
- 所有在Elasticsearch集群中的节点都包含:有关哪个分片存在于哪个节点上的元数据(全状态同步)。协调节点(coordinating node)使用document_id(默认)将文档路由到对应的分片。 shard = hash(document_id) % (num_of_primary_shards)
- 当节点接收到来自协调节点的请求时,请求被写入到translog,并将该文档添加到内存缓冲区。如果请求在主分片上成功,则请求将并行发送到副本分片。只有在所有主分片和副本分片上的translog被fsynced后,客户端才会收到该请求成功的确认。
- 内存缓冲区以固定的时间间隔刷新(默认为1秒),并将内容写入文件系统缓存中的新段(segment)。此分段的内容尚未被fsynced(未被写入文件系统),分段是打开的,内容可用于搜索。
- translog被清空,并且文件系统缓存每隔30分钟进行一次fsync,或者当translog变得太大时进行一次fsync。这个过程在Elasticsearch中称为flush。在刷新过程中,内存缓冲区被清除,内容被写入新的文件分段(segment)。当文件segment被fsynced并刷新到磁盘,会创建一个新的提交点(其实就是会更新文件偏移量,文件系统会自动做这个操作)。旧的translog被删除,一个新的开始。
查询索引原理
读操作由两个阶段组成:查询阶段(query)和取回(fetch)阶段。
查询阶段

查询阶段包含以下三个步骤:
- 客户端发送一个
search请求到Node 3,Node 3会创建一个大小为from + size的空优先队列。 Node 3将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为from + size的本地有序优先队列中。- 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是
Node 3,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。 这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
第一步是广播请求到索引中每一个节点的分片拷贝。 查询请求可以被某个主分片或某个副本分片处理, 这就是为什么更多的副本(当结合更多的硬件)能够增加搜索吞吐率。 协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
每个分片在本地执行查询请求并且创建一个长度为 from + size 的优先队列—也就是说,每个分片创建的结果集足够大,均可以满足全局的搜索请求。 分片返回一个轻量级的结果列表到协调节点,它仅包含文档 ID 集合以及任何排序需要用到的值,例如 _score(相关性分数) 。
但默认情况下,每个分片将前10个结果发送到协调节点,协调创建优先级队列,从所有分片中分选结果并返回前10个匹配。
协调节点将这些分片级的结果合并到自己的有序优先队列里,它代表了全局排序结果集合。至此查询过程结束。
取回阶段
查询阶段标识哪些文档满足搜索请求,但是我们仍然需要取回这些文档。这是取回阶段的任务;
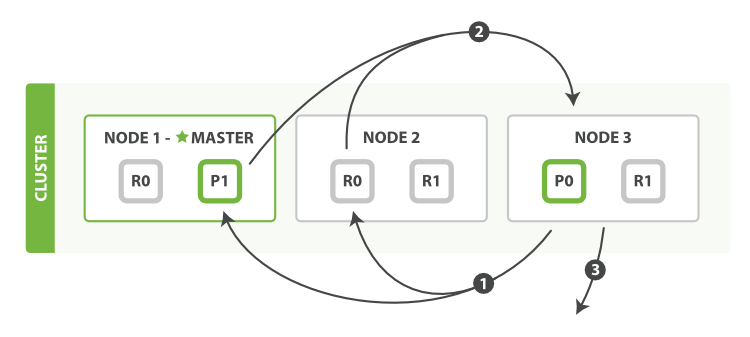
分布式阶段由以下步骤构成:
- 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个
GET请求。 - 每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。
- 一旦所有的文档都被取回了,协调节点返回结果给客户端。
协调节点首先决定哪些文档 确实 需要被取回。例如,如果我们的查询指定了 { "from": 90, "size": 10 } ,最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回。这些文档可能来自和最初搜索请求有关的一个、多个甚至全部分片。
协调节点给持有相关文档的每个分片创建一个 multi-get request
,并发送请求给同样处理查询阶段的分片副本。
分片加载文档体-- _source 字段—如果有需要,用元数据和 search snippet highlighting 丰富结果文档。 一旦协调节点接收到所有的结果文档,它就组装这些结果为单个响应返回给客户端。
更新索引的流程
在 Elasticsearch 中文档是 不可改变 的,不能修改它们。相反,如果想要更新现有的文档,需要 重建索引 或者进行替换,索引的持久化流程和倒排索引被设定为不可修改以及这样设定的好处。因为它是不可变的,你不能修改它。有以下几个方面优势:
- 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
- 一旦索引被读入内核的文件系统缓存,便会留在哪里。由于其不变性,只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
- 其它缓存(像
filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。 - 写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量。
但是如果你需要让一个新的文档可被搜索,这就涉及到索引的更新了,索引不可被修改但又需要更新,这种看似矛盾的要求,我们需要怎么做呢?
ES 的解决方法就是:用更多的索引。就是原来的索引不变,我们对新的文档再创建一个索引。这样说完不知道大家有没有疑惑或者没理解,我们通过图表的方式说明下。
对于修改的场景来说,同一个文档这时磁盘中同时会有两个索引数据一个是原来的索引,另一个是修改之后的索引。
当一个文档被 “删除” 时,它实际上只是在.del 文件中被 标记 删除。一个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除。
删除索引的流程
正如已经在更新流程中提到的,删除文档不会立即将文档从磁盘中删除,只是将文档标记为已删除状态。随着你不断的索引更多的数据,Elasticsearch 将会在后台清理标记为已删除的文档。
在内部,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。 尽管你不能再对旧版本的文档进行访问,但它并不会立即消失。当继续索引更多的数据,Elasticsearch 会在后台清理这些已删除文档。,但实际上 Elasticsearch 按前述完全相同方式执行以下过程:
- 从旧文档构建 JSON
- 更改该 JSON
- 删除旧文档(标记)
- 索引一个新文档