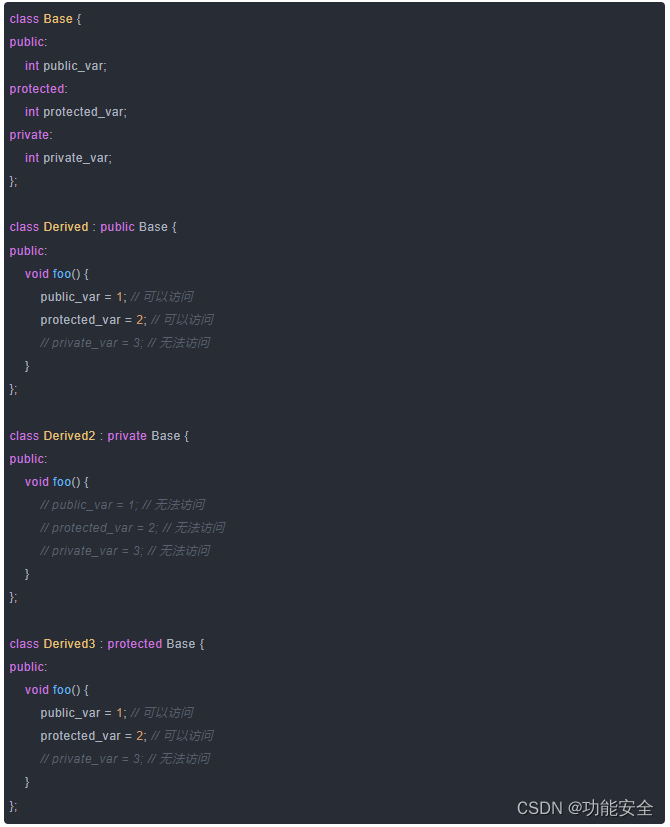
文章目录
- 第五章 Python数据容器
- 5.1. 容器类型介绍
- 5.2. 数据容器运算符
- 5.2.1. 成员运算符
- 5.2.2. 身份运算符
- 5.3. 字符串str
- 5.3.1. 字符串的定义
- 5.3.2. 运算符的相关操作
- 5.3.3. 索引和切片
- 5.3.3.1. 索引
- 5.3.3.2. 切片
- 5.3.4. 字符串遍历
- 5.3.5. 字符串的相关操作
- 5.3.5.1. 获取的操作 【重要】
- 5.3.5.2. 转换的操作 【重要】
- 5.3.5.3. 判断的操作 【重要】
- 5.3.5.4. 格式化的操作
- 5.3.5.5. 切割和拼接
- 5.3.5.6. 替换和移除
- 5.4. list(列表)
- 5.4.1. 列表的定义
- 5.4.2. 列表中的运算符
- 5.4.3. 索引和切片
- 5.4.4. 列表的遍历
- 5.4.5. 列表的操作
- 5.4.5. 列表推导式
- 5.5. tuple(元组)
- 5.5.1. 元组的定义
- 5.5.2. 元组的运算
- 5.5.3. 索引和切片
- 5.5.4. 元组的遍历
- 5.5.5. 元组的操作
- 5.5.6. 打包和解包
- 5.6. set(集合)
- 5.6.1. 集合的定义
- 5.6.2. 集合的运算符
- 5.6.3. 集合的操作【了解】
- 5.6.4. 不可变集合(frozenset)
- 5.7. dict(字典、映射)
- 5.7.1. 字典的定义
- 5.7.2. 字典的运算符
- 5.7.3. 字典的操作
- 5.7.4. 字典的遍历
- 5.7.5. 字典推导式
- 5.8. 容器类型总结
- 5.9. 容器综合案例
- 双色球
第五章 Python数据容器
5.1. 容器类型介绍
为什么学习数据容器?
思考:需要在程序中记录5名学生的信息,如姓名该如何实现?
# 现有的方式 提供五个变量存储5个学生的姓名
name1 = "张三"
name2 = "李四"
name5 = "王五"
name6 = "赵六"
name7 = "田七"
# 如果现有需求改变,需要记录50个学生的信息,如姓名该如何实现? ---》 还是提供50个变量吗? 是否可行?
# 其实以编程而言是可以的,但是无论是内存空间的开辟,还是后续对数据的使用都很不方便且效率低下
那么,面临数据的批量存储或批量使用该如何操作?就是使用到Python中的容器类型了
name_list = ["张三","李四","王五","赵六","田七"]
#一个变量记录五份数据,这就是数据容器,一个容器可以容纳多份数据,提供对数据存储和操作方式
Python中的数据容器:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素,每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同如:是否支持重复元素、是否可以修改、是否有序等
数据容器分为5类分别是:字符串(str)、列表(list)、元组(tuple)、集合(set)、字典(dict)
5.2. 数据容器运算符
5.2.1. 成员运算符
针对于容器型数据的,判断一个数据是否为容器中的内部元素
| 运算符 | 描述 |
|---|---|
| in | 数据 in 容器型数据 把数据当做一个整体 检查是否在容器型数据中 |
| not in | 数据 not in 容器型数据 把数据当做一个整体 检查是否不在容器型数据中 |
5.2.2. 身份运算符
身份运算符用于比较两个对象的内存地址是否一致,是否是对同一对象的引用
| 运算符 | 描述 |
|---|---|
| id | id(数据) 可以获取数据的地址 |
| is | 数据 is 数据 判断两个数据的地址是否一致 |
| not is | not 数据 is 数据 判断两个数据的地址是否不一致 |
需要注意:is用于判断两个变量引用对象是否为同一个,而==用于判断引用变量的值是否相等
5.3. 字符串str
字符串是字符的容器:一个字符串可以存放任意数量的字符(包含零个或者多个字符的有序不可变序列)。
需要注意:
- 不可变:内容一旦确定,就不允许发生变化
- 有序: 添加顺序和显式顺序一致,元素在添加的时候会为元素设置编号,这个编号是从0开始的【这个编号称为索引、下标、脚标】
- 序列是指:内容连续、有序,可使用下标索引的一类数据容器。列表、元组、字符串,均可以可以视为序列。
5.3.1. 字符串的定义
有两种方式来进行定义:
- 使用引号包含格式的字面量定义法
- 使用
str()进行构造
# 空字字符串
str0 = ''
str0_0 = str()
# 创建字符串
str1 = "我是字符串"
str2 = str("我是字符串")
#str() 不仅可以创建字符串,而且可以将赋值参数转换为字符串类型
str3 = str(10) # "10"
str4 = str([1,2,3,4]) #"[1,2,3,4]"
字符串的分类:
转义字符串:因为在编程语言中有
\,是转义符,会将一些特殊的符号转义成其他的含义n ----> \n 换行符 t ----> \t 水平制表符 r ----> \r 回车符 【windows系统的字节模式下 换行符是两个符号组成的 \r\n】 f ----> \f 换页符 v ----> \v 纵向制表符 u ----> \u unicode码的前缀 '\u4e00' x ----> \x 字节模式下 十六进制的前缀原生字符串:保持每个字符原本的含义,就是原生字符串
对比一下:
\n在转义字符串中是 一个换行符, 原生字符串解读,应该是两个符号反斜杠和n将转义字符串转化成原生字符串的方式:
- 使用
\进行再次转义使用
r或者R修饰字符串
s = 'C:\\Users\jkMaster\Documents\\test.txt'
print(s)
s = r'C:\Users\jkMaster\Documents\test.txt'
print(s)
# 这两字符串变量打印结果时一样,但是不同点在于,当遇到python中的转移字符串时,如何将转移字符串转变会原有含义的操作即原生字符串的操作
5.3.2. 运算符的相关操作
# +号运算符 提供的是拼接操作(要求:字符串只能和字符串拼接)
print("hello"+" world")
# *号运算符 乘以一个正整数n 将字符串的内容重复n次
print("qfedu "*3)
# %号运算符 格式化在字符串未知的位置使用占位符占位,再对字符串使用%运算符给占位符赋值
# %s字符串 %d整数 %f小数
print("姓名:%s,年龄%d,薪水%.2f"%("张三",18,1234.56))
# +=号运算符 在变量原来值的基础上拼接上新的内容(要求:字符串只能和字符串拼接)
str1 = "hello"
str1 += " world"
print(str1)
# *=号运算符 在变量值的基础上将内容重复n次 赋值给变量
str2 = "qfedu "
str2 *= 3
print(str2)
# 关系运算符 > >= < <= == !=
# 字符在比较的时候按照什么来比较的??? python是utf-8的编码 所以它是按照utf-8编码规则 对比字符对应的十进制数据
str3_1 = "a"
str3_2 = "A"
print(str3_1 > str3_2)
# 成员运算符
str4_1 = "a"
str4_2 = "abc"
print(f"a是否存在abc中?{str4_1 in str4_2}")
print(f"a是否不存在abc中?{str4_1 not in str4_2}")
#身份运算符
str5_1 = "abc"
str5_2 = "abc"
print(f"str5_1中存储的字符串内存地址是:{id(str5_1)}")
print(f"str5_2中存储的字符串内存地址是:{id(str5_2)}")
print(f"str5_1和str5_2的地址是否相等?:{str5_1 is str5_2}")
print(f"str5_1和str5_2的地址是否不相等?:{not str5_1 is str5_2}")
5.3.3. 索引和切片
5.3.3.1. 索引
索引就是表名字符串中存储字符对应的位置
Python对于序列的索引有两种方式的操作:
正向索引 【从左向右数】范围是[0, 长度N-1]
负向索引 【从右向左数】范围是[-1, -N, -1] — 递减数列
对于有序序列来说,想要定位获取或者修改序列中的元素,就需要索引来进行定位,格式:
序列[索引]
# len(序列) --》可以获取序列的长度
s = '\n'
print(len(s)) # 1
s1 = r'\n'
print(len(s1)) # 2
s = r'Welcome to qfedu study'
print(len(s)) # 22
# 获取第一个字符
ch = s[0] # 定位到之后赋值给变量
print(ch) # W
# 负向索引
ch = s[-len(s)]
print(ch) # W
# 获取最后一个字符
last_ch = s[len(s) - 1]
print(last_ch) # y
last_ch = s[-1]
print(last_ch) # y
# 获取倒数第三个字符
last_ch_3 = s[-3]
print(last_ch_3)
# 字符串是不允许发生变化【不可变】
# s[0] = 'w' # 修改这个位置的元素
# TypeError: 'str' object does not support item assignment
# 类型错误:字符串对象不支持元素被指派内容
5.3.3.2. 切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
通过索引定位范围区域,在这个区域中提取相关的子串信息,切片的操作是
序列[起始索引:结束索引:步长]起始索引和结束索引只是定位范围的,使用正向索引和负向索引均可
根据步长的正负情况切片是分为两种的
正向切片 【从左向右提取子串】
步长是为正数,起始索引定位的字符应该在结束索引定位的左边
从起始索引定位的字符开始 按照步长 获取相应的字符,注意不包含结束索引对应的位置
负向切片 【从右向左提取子串】
步长是负数,起始索引定位的字符应该在结束索引定位的右边
从起始索引定位的字符开始 按照步长 获取相应的字符,注意不包含结束索引对应的位置
切片的操作中有些内容是可以省略的:
:步长可以省略,表示步长为1起始索引可以省略,如果是正向切片 表示从最左边开始, 如果是负向切片 表示从最右边开始结束索引可以省略,如果是正向切片 表示到最右边结束,如果是负向切片 表示到最左边结束
s = r'Welcome to qfedu study'
sub_s = s[0:len(s):1]
print(sub_s) # Welcome to qfedu study
# 等价于
sub_s = s[:]
print(sub_s) # Welcome to qfedu study
sub_s = s[-1:-len(s)-1:-1]
print(sub_s) # 对字符串反转
# yduts udefq ot emocleW
# 等价于
sub_s = s[::-1]
print(sub_s)
# tyduts udefq ot emocleW
sub_s = s[:3] # 提取前3个
print(sub_s) # Wel
sub_s = s[-3:] # 提取的是后3个字符
print(sub_s) # udy
sub_s = s[-3::-1]
print(sub_s) # uts udefq ot emocleW
sub_s = s[1:-1:-1]
print(sub_s) # ''
sub_s = s[::2]
print(sub_s) # Wloet fd td
5.3.4. 字符串遍历
方式1:直接遍历获取元素
for 变量名 in 字符串: 操作方式2:使用range生成下标数列,根据下标获取元素
for 变量名 in range(len(字符串)): 操作方式3:enumerate枚举遍历序列
对序列操作完成时候 会生成一个新的序列,这个序列中的元素是一个二元组
(下标, 元素)
s = 'nice hello'
for ch in s:
print(ch)
'''
n
i
c
e
'''
print('=' * 30)
# 因为字符串是有序序列 可以通过索引获取元素
for i in range(len(s)):
print(i, s[i])
# 获取e这个字符在字符串中的位置
# 直接遍历下标
for i1 in range(len(s)):
if s[i1] == 'e':
print(i1)
# enumerate(s) ---> [(下标, 元素), (下标1, 元素1), (下标2, 元素2)] --》元组的操作在后面会详细说明 这里大家知道如何操作即可
for item in enumerate(s):
print(item)
'''
(0, 'n')
(1, 'i')
(2, 'c')
(3, 'e')
(4, ' ')
(5, 'h')
(6, 'e')
(7, 'l')
(8, 'l')
(9, 'o')
'''
# 解包: 给多个变量赋值的时候
x, y, z = 10, 11, 12
print(x, y, z) # 10 11 12
'''
当用逗号分割定义数据时, 解释器会将其解释为一个元组类型
'''
data = 1, 2, 3, 4, 5, 6 # 打包
print(data, type(data)) # (1, 2, 3, 4, 5, 6) <class 'tuple'>
'''
当把多个数据赋值给多个变量时, 是在给元组数据解包, 将数据赋值给对等位置的变量
'''
for pos, ele in enumerate(s):
if ele == 'e':
print(pos)
5.3.5. 字符串的相关操作
5.3.5.1. 获取的操作 【重要】
s = r'Welcome to qfedu study'
'''
1. 在指定范围中 查询子串第一次出现的位置
字符串对象.index(子串, 起始位置, 结束位置) --- 找不到报错
字符串对象.find(子串, 起始位置, 结束位置) --- 找不到 返回的是-1
子串是多个符号 获取的是第一个符号的下标
'''
# 不规定查找范围 从左到右整体查询
pos = s.index('s')
print(pos)
# 对'也有转义的意思 在字符串要展示的内容中 要呈现 '
# 王籽澎的昵称是 '隔壁老王'
message = '王籽澎的昵称是 \'隔壁老王\''
print(message)
# 从指定位置开始进行查找
pos = s.index('s', 3)
print(pos)
# 指定开始与结束[不包含]
#pos = s.index('s', 3, 8)
# print(pos) # ValueError: substring not found
s1 = 'noodle too'
pos = s1.index('oo')
print(pos) # 1
pos = s.find('s', 3, 8)
print(pos) # -1
'''
2. 在指定范围中 查询子串最后一次出现的位置
字符串对象.rindex(子串, 起始位置, 结束位置) --- 找不到报错
字符串对象.rfind(子串, 起始位置, 结束位置) --- 找不到 返回的是-1
子串是多个符号 获取的是第一个符号的下标
'''
pos = s.rfind('s')
print(pos) # 17
pos = s.rfind('s', 0, 10)
print(pos) # -1
'''
3. 在指定范围中 查询子串出现的次数
字符串对象.count(子串, 起始位置, 结束位置)
'''
pos = s.count('s')
print(pos) # 1
# 指定起始 到末尾开始查找
pos = s.count('s', 8)
print(pos) # 1
pos = s.count('s', 8, len(s))
print(pos) # 1
5.3.5.2. 转换的操作 【重要】
s = 'helLo,Nice to Meet you.My age is 18.aheklfnfsd hjdhsjhgfs '
# 1. 将小写英文字母转化为大写 其他的不变
new_s = s.upper()
print(new_s) # HELLO,NICE TO MEET YOU.MY AGE IS 18.
print(s)
# 2. 将大写英文字母转化为小写 其他的不变
new_s = s.lower()
print(new_s) # hello,nice to meet you.my age is 18.
# 3. 大写转小写 小写转大写 其他字符不变
new_s = s.swapcase()
print(new_s) # HELLO,nICE TO mEET YOU.mY AGE IS 18.
# 4. 首字母大写 其他字母小写 其他符号不变
new_s = s.capitalize()
print(new_s) # Hello,nice to meet you.my age is 18.
# 5. 每个单词首字母大写 其他小写
# 单词: 非连续性的符号组在一起就是单词
new_s = s.title()
print(new_s) # Hello,Nice To Meet You.My Age Is 18.Aheklfnfsd Hjdhsjhgfs
# 6. 根据编码规则 获取字符对应的字节数据
print(hex(255)) # 0xff
'''
GBK编码 一个汉字2个字节 1个字节是8位
UTF-8编码 一个汉字是3个字节
二进制数据位数比较多 可读性差一些 所以展示字节数据的时候 使用的十六进制的格式
单字节数据 【ASCII】 --- 编码之前和编码之后的形态是一样的
'''
s = 'abc1234你好'
# 按照GBK的编码规则 获取字符对应的字节数据
byte_data = s.encode(encoding='gbk')
print(byte_data) # b'abc1234\xc4\xe3\xba\xc3' 字节串
# 字节串的内容就是 字节数据 [呈现的时候转化为十进制数据了]
for b in byte_data:
print(b)
'''
97
98
99
49
50
51
52
196
227
186
195
'''
# 解码: 将字节数据按照编码规则 解析成字符串
s1 = byte_data.decode(encoding='gbk') # 编码规则和解码规则要保持一致 如果不一致 要么报错 要么乱码
print(s1) # abc1234你好
s2 = '你好啊'
byte_data1 = s2.encode(encoding='utf-8')
print(byte_data1) # b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x95\x8a'
# s3 = byte_data1.decode(encoding='gbk')
# print(s3) # UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 8: incomplete multibyte sequence
s4 = '你好'
byte_data2 = s4.encode(encoding='utf-8')
print(byte_data2) # b'\xe4\xbd\xa0\xe5\xa5\xbd'
s5 = byte_data2.decode(encoding='gbk')
print(s5) # 浣犲ソ
5.3.5.3. 判断的操作 【重要】
# 1. 判断字符串的内容是否为纯数字
s = '1230'
res = s.isdigit()
print(res) # True
s = '1230 '
print(s.isdigit()) # False
# 2. 判断字符串的内容是否为纯字母
# 字母:世界各国语言 统称为字母
s = 'abc你Вㅘタ'
res = s.isalpha()
print(res) # True
# 要判断是否为纯英文字母 【英文是单字节数据特点】
'''
单字节和多字节的特点是编码之后 的字节串的内容不一样
单字节保持不变 【不会出现其他的符号】
多字节会按照字节数转成十六进制的数据 【例如\xaf】 就会出现非字母的符号
'''
s1 = 'abc'
s2 = 'abc你'
print(s1.encode(encoding='utf-8')) # b'abc'
print(s2.encode(encoding='utf-8')) # b'abc\xe4\xbd\xa0'
# 要判断是否为纯英文字母
print(s1.encode('utf-8').isalpha()) # True
print(s2.encode('utf-8').isalpha()) # False
# 3. 判断字符串的内容是否为数字或者字母 [纯数字 纯字母 数字和字母]
print('123'.isalnum()) # True
print('123abc'.isalnum()) # True
print('123abc比你好'.isalnum()) # True
print('123abc你好 hello'.isalnum()) # False
# 如何判断字符串的内容为数字或者英文字母 【同上】
print('123abc'.encode(encoding='utf-8').isalnum()) # True
print('123abc比你好'.encode(encoding='utf-8').isalnum()) # False
# 如何判断字符串的内容为数字和英文字母 【既有数字 又有英文字母】
s = '123'
res = s.encode(encoding='utf-8').isalnum() is True and s.isdigit() is False and s.encode(encoding='utf-8').isalpha() is False
print(res)
# 4. 判断字符串中的英文字母是否为大写字母
s = 'her12324'
res = s.isupper()
print(res) # False
s1 = 'HER12324'
res = s1.isupper()
print(res) # True
# 5. 判断字符串中的英文字母是否为小写字母
res = s.islower()
print(res) # True
res = s1.islower()
print(res) # False
# 6. 判断字符串的内容是否满足 单词的首字母大写 其他小写
s = 'Good Nice 13'
res = s.istitle()
print(res) # True
s1 = 'Good nice 13'
res = s1.istitle()
print(res) # False
# 7. 判断字符串的内容是否是ASCII码符号
print(s.isascii()) # True
# 8. 判断字符串的内容是否已指定内容开头
# res = 'good good study'.startswith(指定内容)
'''
指定内容的数据类型:
1. 字符串 验证是否以指定的字符串开头
2. (字符串1,字符串2, 字符串3) 元组类型的数据 判断字符串的内容是否以其中一个开头
'''
res = 'good good study'.startswith('good')
print(res) # True
res = 'Good good study'.startswith('good')
print(res) # False
res = 'Good good study'.startswith(('good', 'Good', 'GOOD'))
print(res) # True
# 9. 判断字符串的内容是否已指定内容结尾
'''
1. 字符串 验证是否以指定的字符串结尾
2. (字符串1,字符串2, 字符串3) 元组类型的数据 判断字符串的内容是否以其中一个结尾
'''
res = 'good good study'.endswith('dy')
print(res)
res = 'good good stuDy'.endswith(('dy', 'Dy', 'DY', 'dY'))
print(res)
5.3.5.4. 格式化的操作
# 1. 按照指定宽度 对展示的字符串内容填充数据 【居左右填充 居右左填充 居中左右填充】
s = 'hello'
print(s)
# 居左右填充
# new_s = s.ljust(宽度, 填充符) # 填充符默认是空格
new_s = s.ljust(10)
print(new_s) # 'hello '
new_s = s.ljust(10, '-')
print(new_s) # hello-----
# 居右左填充
new_s = s.rjust(10)
print(new_s) # ' hello'
new_s = s.rjust(10, '*')
print(new_s) # '*****hello'
# 居中
new_s = s.center(10)
print(new_s) # ' hello '
new_s = s.center(10, '+')
print(new_s) # '++hello+++'
# 2. 按照指定宽度 对字符串进行右对齐 左边填充0
s = '10'
new_s = s.zfill(10)
print(new_s) # 0000000010
# 3. 引号嵌套的问题*** 【展示的内容中有双引号 字符串数据就采用单引号包含 】
# 展示的内容中有单引号 字符串数据就采用双引号包含
s = "王籽澎的昵称是 '隔壁老王'"
print(s)
s = '王籽澎的昵称是 "隔壁老王"'
print(s)
# 有冲突的情况 内外引号情况一样 解决方式就是对内部引号采用转义符转义 取消掉字符串标记的含义
s = '王籽澎的昵称是 \'隔壁老王\''
print(s)
# 4. 字符串内容比较长 *** 可以直接换行写多个字符串 会自动拼接在一起 使用\把多个字符串连接在一起 形成一个
s = '其中五六只虾已熟透发红。方女士称,当天气温41度,' \
'可能是自己把虾往地上和电动车后座放了的缘故,温度太高虾被烫熟了,' \
'觉得十分搞笑。感慨这天气能不出门就不出门,待在空调房里最香。'
print(s)
s = '其中五六只虾已熟透发红。方女士称,当天气温41度,可能是自己把虾往地上和电动车后座放了的缘故,温度太高虾被烫熟了,觉得十分搞笑。感慨这天气能不出门就不出门,待在空调房里最香。'
print(s)
# 5. 字符串格式化
'''
除了%运算符之外 字符串也提供了相应的操作
字符串对象.format(填充的数据)
这种格式化方式,字符串对象里面的未知数据的占位符采用的是{}
'''
name = '王籽澎'
gender = '男'
age = 21
score = 79.9
message = '这个人叫%s, 今年%d岁 性别是%s 成绩是%f' % (name, age, gender, score)
print(message)
message = '这个人叫{}, 今年{}岁 性别是{} 成绩是{:.2f}'.format(name, age, gender, score)
print(message)
''' *******
Python3.6出现了简化操作 使用f或者F修饰字符串 在需要填充数据的地方 直接 {数据}
如何对数据进一步格式化
保留多少位小数 {数据:.nf} n保留小数的位数
按照指定宽度填充数据 {数据:[占位符][对齐模式][宽度]}
占位符默认是空格
对齐模式 >[居右] ^[居中] <[居左]
千位分割法 {数据:,}
'''
message = f'这个人叫{name}, 今年{age}岁 性别是{gender} 成绩是{score:.2f} 学号{10:0>6} 千位分割{12345678987654567:,}' \
f'二进制展示数据{10:0b} 八进制展示数据{10:0o} 十六进制{10:0x} ' \
f'科学计数法{123456789234567:e}'
print(message)
value = input('请输入数据:')
# 打印出来的信息是 value=数据值
info = f'{value=}' # 3.8中新增的
print(info) # value='19'
5.3.5.5. 切割和拼接
# 切割: 以指定子串为切割点 将字符串分成n段
'''
字符串数据.split(切割符, 切割次数) 没有设置切割次数 能切几次切几次
从左开始查找切割点 进行切割的
字符串数据.rsplit(切割符, 切割次数) 没有设置切割次数 能切几次切几次
从右开始查找切割点 进行切割的
'''
s = 'hello nice to meet you'
# 以 'e'为切割点
sub_list = s.split('e')
print(sub_list) # ['h', 'llo nic', ' to m', '', 't you']
'''
'h'
'llo nic'
' to m'
''
't you'
'''
# 如果没有设置切割符 默认以任意的空白符号为切割符 会将结果中的空字符串给移除
'''
空格
换行
制表符等等
'''
sub_list = s.split()
print(sub_list) # ['hello', 'nice', 'to', 'meet', 'you']
# 设置切割次数
sub_list = s.split('e', 1)
print(sub_list) # ['h', 'llo nice to meet you']
sub_list = s.rsplit('e')
print(sub_list) # ['h', 'llo nic', ' to m', '', 't you']
sub_list = s.rsplit('e', 1)
print(sub_list) # ['hello nice to me', 't you']
# 2. 拼接
# 使用拼接符把序列中的内容拼接成一个字符串
'''
'拼接符'.join(序列)
底层实现就是采用的+号拼接 【字符串只能跟字符串拼接】
序列中的元素必须是字符串类型的
'''
words = ['hello', 'nice', 'to', 'meet', 'you']
res = '_'.join(words)
print(res) # hello_nice_to_meet_you
# nums = (11, 23, 45)
# res = '+'.join(nums) # TypeError: sequence item 0: expected str instance, int found
5.3.5.6. 替换和移除
# 替换
'''
字符串数据.replace(旧子串, 新子串, 个数)
旧子串 --- 要替换掉的
新子串 --- 要替换成的
个数 --- 不设置的换 默认全部替换
'''
s = 'good good god'
new_s = s.replace('g', 'G')
print(new_s) # Good Good God
new_s = s.replace('g', 'G', 1)
print(new_s) # Good good god
new_s = s.replace(' ', '_')
print(new_s) # good_good_god
'''
移除的是两端的内容
字符串数据.strip(指定内容) 移除字符串两端的指定内容
字符串数据.lstrip(指定内容) 只移除左端的指定内容
字符串数据.rstrip(指定内容) 只移除右端的指定内容
指定内容没有设置 移除的是任意的空白符号
'''
s = ' \t\r\nabc\tgood \n'
new_s= s.strip()
print(new_s) # abc good
s = '@#$%^abc\tgood^%$#'
new_s = s.strip('@#$%^&*') # 左右逐个获取 验证是否在指定的内容中 在的话移除 不在话停止移除操作
print(new_s) # abc good
s = '@#$%^abc\tgood^%$#'
new_s = s.lstrip('@#$%^&*') # 左右逐个获取 验证是否在指定的内容中 在的话移除 不在话停止移除操作
print(new_s) # abc good^%$#
s = '@#$%^abc\tgood^%$#'
new_s = s.rstrip('@#$%^&*') # 左右逐个获取 验证是否在指定的内容中 在的话移除 不在话停止移除操作
print(new_s) # @#$%^abc good
总结:
作为数据容器,字符串有如下特点:只可以存储字符串、长度任意(取决于内存大小)、支持下标索引、允许重复字符串存在、不可以修改(增加或删除元素等)、支持for循环
5.4. list(列表)
概念:存放零个或者多个数据的有序的可变的序列
列表数据的标识是
[],是在[]存储元素,元素之间使用,隔开列表中是可以存放不同类型的数据作为元素的,但是为了数据的统一性,所以我们一般来存储的时候类型就是统一的
5.4.1. 列表的定义
- 采用
[]字面量定义法- 采用
list()构造
l0 = [] # 空列表
print(l0) # []
l1 = [19, 28, 44, 56, 38]
print(l1)
# list()构造
l2 = list()
print(l2) # []
# 把其他序列类型转化为列表类型 【构造一个列表 把其他序列中的元素添加在列表中】
l3 = list('10')
print(l3) # ['1', '0']
l4 = list(range(1, 100, 10))
print(l4) # [1, 11, 21, 31, 41, 51, 61, 71, 81, 91]
5.4.2. 列表中的运算符
l1 = [19, 27, 83, 56]
l2 = [77, 55, 43]
# + 合并两个列表中的数据 把数据添加到一个新的列表中
new_li = l1 + l2
print(new_li) # [19, 27, 83, 56, 77, 55, 43]
# * 将列表中的元素重复n次 放在一个新的列表中
new_li = l1 * 3
print(new_li, l1) # [19, 27, 83, 56, 19, 27, 83, 56, 19, 27, 83, 56]
# += 将当前列表的基础上追加其他序列中的元素
l1 += range(1, 10)
print(l1) # [19, 27, 83, 56, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# *= 将当前列表的元素重复n次
l1 *= 2
print(l1) # [19, 27, 83, 56, 1, 2, 3, 4, 5, 6, 7, 8, 9, 19, 27, 83, 56, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#比较运算符【> >= < <= == !=】相同位置的元素进行比较 直到产生结果 比较结束
l3 = ['good', 'nice']
l4 = ['god', 'look']
print(l3 > l4) # True --》 good 和 god 比较
# 成员运算符 in 和 not in 判断元素是否在或者不在列表中
print(19 in l1) # True
print(19 not in l1) # False
# 身份运算符 id 、is 和 not is
print(id(l1)) # 获取地址
print(id(l2)) # 获取地址
print(l1 is l2) # 判断地址是否一致
print(not l1 is l2)# 判断地址是否不一致
5.4.3. 索引和切片
索引
python索引分为正向索引和负向索引
正向索引的范围是[0, 长度N - 1] 从左向右
负向索引的范围是[-1, -长度N] 从右向左
通过索引定位到对应位置,修改或者获取该位置的元素
nums = [19, 27, 38, 41, 25]
# 获取第2个元素
ele = nums[1]
print(ele)
# 获取倒数第二个
ele = nums[-2]
print(ele)
# 修改
nums[0] = 87
print(nums) # [87, 27, 38, 41, 25]
nums[-1] = 65
print(nums) # [87, 27, 38, 41, 65]
切片
切片类似于字符串
列表[start:stop:step]
正向切片步长step为正数 表示从左向右取值
负向切片步长step为负数 表示从右向左取值
start和stop只是来定位取数据的范围
start省略 正向切片的时候 表示从最左边开始 负向切片表示从最右边开始
stop省略 正向切片的时候 表示到最右边结束 负向切片表示到最左边结束
# 切片
sun_nums = nums[::2]
print(sun_nums) # [87, 38, 65]
sun_nums = nums[::-1]
print(sun_nums) # [65, 41, 38, 27, 87]
sun_nums = nums[:]
print(sun_nums) # [87, 27, 38, 41, 65] 备份了一份
'''
切片:根据索引以及步长定位到列表的多个位置
因为列表是可变的 也可以通过切片对这些位置的数据进行修改 【赋值得是一个序列型数据】
切片定位的下标范围是连续的 赋值的个数可以随便
但是位置是跳跃的 定位到几个位置 就得赋予几个值
'''
nums[:2] = [19, 33]
print(nums) # [19, 33, 38, 41, 65]
nums[:2] = [19]
print(nums) # [19, 38, 41, 65]
nums[:2] = [19, 99, 78, 36]
print(nums) # [19, 99, 78, 36, 41, 65]
# nums[::2] = [99]
# print(nums) # ValueError: attempt to assign sequence of size 1 to extended slice of size 3
nums[::2] = [99] * 3
print(nums) # [99, 99, 99, 36, 99, 65]
5.4.4. 列表的遍历
方式1:直接遍历获取元素
for 变量名 in 列表: 操作方式2:使用range生成下标数列,根据下标获取元素
for 变量名 in range(len(列表)): 操作方式3:enumerate枚举遍历序列
对序列操作完成时候 会生成一个新的序列,这个序列中的元素是一个二元组
(下标, 元素)
# 直接遍历元素
words = ['hello', 'enumerate', 'length', 'operator', 'expression', 'sort']
for w in words:
print(w)
# 过滤 要获取长度在6以上的单词
'''
肯定要接收结果的,由于结果是有多个的 肯定得定义一个容器来接收
1. 定义一个空列表
2. 遍历列表
3. 按照需求判断 找到符合要求的数据 把数据添加在列表中
+= 在当前列表的基础上 追加其他序列中的元素
'''
greatest_6 = []
# 遍历
for w1 in words:
if len(w1) > 6:
# greatest_6 += [w1] # 加上中括号的原因 是因为得把w1当做整体数据 追加在greatest_6中 w1得放在一个序列中
# append
greatest_6.append(w1) # 列表中提供的追加元素的操作
print(greatest_6)
# 转换 把列表中的每个单词 转换成首字母大写 其他字母小写
new_words = []
for w2 in words:
new_words.append(w2.title())
print(new_words)
# ['Hello', 'Enumerate', 'Length', 'Operator', 'Expression', 'Sort']
nums = [18, 29, 33, 56]
# 将nums中元素 通过+拼接在一起
str_nums = []
for ele in nums:
str_nums.append(str(ele))
print(str_nums) # ['18', '29', '33', '56']
res = '+'.join(str_nums)
print(res) # 18+29+33+56
nums1 = [77, 56, 39, 28, 41, 63, 55]
# 质数【在大于1的自然数中 只有1和本身这两个因数的数据为质数】
'''
在2到本身-1之间不存在因数 这种数是质数
'''
# 找到nums1中质数的下标 【列表是可以通过下标定位到元素的】
for i in range(len(nums1)):
# print(nums1[i]) # 判断nums1[i]是不是质数
# 设置一个标记 假设是
flag = True
# 遍历获取2-本身-1之间的数据
for v in range(2, int(nums1[i] ** 0.5) + 1):
if nums1[i] % v == 0:
# 这里就找到了1和本身之外的因数了
flag = False
break
# 结束验证 看一下flag标记的值
# 假设没有被推到 假设成立 这个数据就是质数
if flag is True:
print(i)
for pos, ele1 in enumerate(nums1):
# 设置一个标记 假设ele1持有的数据是质数
flag = True
# 遍历获取2-本身-1之间的数据
for v in range(2, int(ele1 ** 0.5) + 1):
if ele1 % v == 0:
# 这里就找到了1和本身之外的因数了
flag = False
break
# 结束验证 看一下flag标记的值
# 假设没有被推到 假设成立 这个数据就是质数
if flag is True:
print(pos)
5.4.5. 列表的操作
nums = [23, 71, 29, 77, 83, 23, 14, 51, 79, 23]
# 1. 添加数据的操作
# 在末尾追加数据
res = nums.append(17)
print(res) # None 列表是一个可变的数据 相关操作没有产生新的内容 影响的都是原数据 所以拿到的是None
print(nums) # 看操作有没有影响 看原数据
# [23, 71, 29, 77, 83, 23, 14, 51, 79, 23, 17]
# 在指定下标的位置添加数据 该位置及其之后的数据会向后移动一位
nums.insert(1, 80)
print(nums) # [23, 80, 71, 29, 77, 83, 23, 14, 51, 79, 23, 17]
nums.insert(-2, 77)
print(nums) # [23, 80, 71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17]
# 合并其他序列的元素 等同于+=
nums.extend(range(7, 100, 7))
print(nums)
# [23, 80, 71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91, 98]
# 2. 删除的操作
# 删除末尾的元素 返回的是被删掉的数据
value = nums.pop()
print(value) # 98
print(nums) # [23, 80, 71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91]
# 删除指定索引位置的元素 【删除该位置的元素 后面的元素会补位】
value = nums.pop(1)
print(nums, value)
# [23, 71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91] 80
# 删除指定元素 【如果没有这个元素 会报错 如果这个元素是重复的 删除是查找到第一个】
# nums.remove(99) # ValueError: list.remove(x): x not in list
nums.remove(23)
print(nums)
# [71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91]
# 清空列表
# nums.clear()
# print(nums) # []
# 3. 获取相关的操作
# 3.1 获取元素在指定的范围内第一个出现的位置
'''
列表数据.index(数据, 起始位置, 结束位置)
如果找不到 报错
'''
pos = nums.index(23)
print(pos) # 4
pos = nums.index(23, 5)
print(pos) # 9
# pos = nums.index(23, 5, 9)
# print(pos) # ValueError: 23 is not in list
# 3.2 获取元素在列表中出现的次数
'''
列表数据.count(数据)
'''
count = nums.count(23)
print(count) # 2
# 3.3 获取列表中元素的最大值
'''
max(序列) --- 获取序列中最大的元素
打包这个名词 多个数据用逗号分开 会把数据打包成元组
'''
print(max(nums)) # 91
print(max('good')) # o
# 获取多个数据中的最大值 最小值
print(max(19, 34, 56, 72, 38)) # 72
# 3.4 获取列表中元素的最小值
'''
min(序列) --- 获取序列中最小的元素
'''
print(min(nums)) # 7
print(min(19, 34, 56, 72, 38)) # 19
# 4.其他的操作
# 4.1拷贝列表
copy_nums = nums.copy()
print(copy_nums)
print(id(nums), id(copy_nums))
# 4.2 对列表的元素按照大小进行排序
# nums.sort() # 升序排序
# print(nums)
# # [7, 14, 14, 17, 21, 23, 23, 28, 29, 35, 42, 49, 51, 56, 63, 70, 71, 77, 77, 77, 79, 83, 84, 91]
# nums.sort(reverse=True) # 升序之后是否反转 是的话 就变成降序了 默认是False
# print(nums)
# [91, 84, 83, 79, 77, 77, 77, 71, 70, 63, 56, 51, 49, 42, 35, 29, 28, 23, 23, 21, 17, 14, 14, 7]
# 4.3 对列表的内容进行反转
'''
和切片反转的区别:
切片反转生成是新的列表
而这个操作是影响的原列表
'''
new_nums = nums[::-1]
print(new_nums)
print(id(new_nums), id(nums))
nums.reverse()
print(nums)
5.4.5. 列表推导式
理解成对列表过滤或者转换格式的简化,虽然说是简化,但是它要比
append操作效率要高对数据进行过滤
[变量 for 变量 in 序列 if 判断条件]对数据进行转换
[对变量转换之后数据 for 变量 in 序列]
'''
2. 已知一个数字列表`nums = [1, 2, 3, 4, 5]`, 编写程序将列表中所有元素乘以2
'''
nums = [1, 2, 3, 4, 5]
pow_nums = []
for ele in nums:
pow_nums.append(ele * 2)
print(pow_nums) # [2, 4, 6, 8, 10]
# 列表推导式
new_nums = [ele * 2 for ele in nums]
print(new_nums)
nums = [19, 23, 45, 67]
# 用+号把数据拼在一起 使用的是字符串的join
res = '+'.join([str(ele) for ele in nums])
print(res)
'''
3. 列表中存储学生的成绩`scores = [98, 67, 56, 77, 45, 81, 54]`,去除掉不及格的成绩
'''
scores = [98, 67, 56, 77, 45, 81, 54]
# 保留及格
pass_scores = []
for sc in scores:
if sc >= 60:
pass_scores.append(sc)
print(pass_scores)
# 列表推导式
pass_scores1 = [sc for sc in scores if sc >= 60]
print(pass_scores1)
'''
1. `There is no denying that successful business lies in a healthy body and mind`提取这句话中包含`i`的**单词**
'''
s = 'There is no denying that successful business lies in a healthy body and mind'
# 切割
words = s.split()
print(words)
i_words = [w for w in words if 'i' in w]
print(i_words)
'''
5. `names = ['lucy', 'lulu', 'john', 'rose', 'hanmeimei', 'lili', 'rosum']`
1. 查找列表中包含`o`的名字
2. 查找列表中以`r`开头的名字
3. 查找列表中长度在4个以上的名字
'''
names = ['lucy', 'lulu', 'john', 'rose', 'hanmeimei', 'lili', 'rosum']
o_names = [name for name in names if 'o' in name]
r_names = [name for name in names if name.startswith('r')]
greatest_4_names = [name for name in names if len(name) > 4]
print(o_names, r_names, greatest_4_names)
总结:
列表:可以容纳多个元素(上限为2**63-1、9223372036854775807个)、可以容纳不同类型的元素(混装)、数据是有序存储的(有下标序号)、允许重复数据存在、可以修改(增加或删除元素等)
5.5. tuple(元组)
元组和列表类似,与列表的区别是列表是可变的【元素的值可以更改,长度可以发生变化】,
元组是不可变的
元组的数据标记是
()【提高表达式优先级也是使用()包含的】有些场景下存储的数据是固定的,像这种情况建议使用元组。【从内存角度来说 使用元组会比列表少占内存】
5.5.1. 元组的定义
元组有几个元素就称为几元组
- 使用
()字面量形式来定义- 使用
tuple()来构造
# 1. 元组的定义
t = () # 空元组
print(t, type(t)) # () <class 'tuple'>
# 当元组中只有一个数据时 元素后面必须加上逗号 【不加的话 解释器把它解释成提高表达式优先级的意思了】
t1 = (10)
print(type(t1), t1) # <class 'int'> 10
t2 = (10,) # 定义一元组的注意事项
print(type(t2), t2) # <class 'tuple'> (10,)
t3 = (12, 34, 56, 78)
print(t3)
# 用tuple构造 【把其他序列转换为元组类型】
t0 = tuple() # 空元组
print(t0) # ()
t1 = tuple('hello')
print(t1) # ('h', 'e', 'l', 'l', 'o')('h', 'e', 'l', 'l', 'o')
5.5.2. 元组的运算
"""
+ 合并 放在一个新的元组中
* 重复
+= 在当前元组的数据的基础上 合并新的序列 但是生成一个新的元组
*= 在当前元组的数据的基础上 完成重复 但是生成一个新的元组
比较运算符 > >= < <= == !=相同索引位置的元素进行比较 直到结果的出现
成员运算符 in 和 not in
身份运算符 id 、is 和 not is
"""
t1 = (1, 2, 3)
t2 = (5, 6, 7)
print(id(t1)) # 2245004633920
new_t = t1 + t2
print(new_t, t1, t2)
t1 += (8, 9)
print(t1, id(t1)) # (1, 2, 3, 8, 9) 2245045930640
t2 = (10,20) * 3
print(t2)
5.5.3. 索引和切片
元组的索引和切片操作更类同于字符串,因为是不可变的 只有获取没有修改
索引
Python对于序列的索引有两种方式的操作:
正向索引 【从左向右数】范围是[0, 长度N-1]
负向索引 【从右向左数】范围是[-1, -N, -1] — 递减数列
对于有序序列来说,想要定位获取或者修改序列中的元素,就需要索引来进行定位,格式:
序列[索引]
切片
通过索引定位范围区域,在这个区域中提取相关的子串信息,切片的操作是
序列[起始索引:结束索引:步长]起始索引和结束索引只是定位范围的,使用正向索引和负向索引均可
根据步长的正负情况切片是分为两种的
正向切片 【从左向右提取子串】
步长是为正数,起始索引定位的字符应该在结束索引定位的左边
从起始索引定位的字符开始 按照步长 获取相应的字符,注意不包含结束索引对应的位置
负向切片 【从右向左提取子串】
步长是负数,起始索引定位的字符应该在结束索引定位的右边
从起始索引定位的字符开始 按照步长 获取相应的字符,注意不包含结束索引对应的位置
切片的操作中有些内容是可以省略的:
:步长可以省略,表示步长为1起始索引可以省略,如果是正向切片 表示从最左边开始, 如果是负向切片 表示从最右边开始结束索引可以省略,如果是正向切片 表示到最右边结束,如果是负向切片 表示到最左边结束
t = (13, 45, 67, 8, 29, 33, 56, 71)
# 获取倒数第3个元素
print(t[-3])
# 获取前3个
print(t[:3]) # (13, 45, 67)
# 反转
print(t[::-1])
5.5.4. 元组的遍历
方式1:直接遍历获取元素
for 变量名 in 元组: 操作方式2:使用range生成下标数列,根据下标获取元素
for 变量名 in range(len(元组)): 操作方式3:enumerate枚举遍历序列
对序列操作完成时候 会生成一个新的序列,这个序列中的元素是一个二元组
(下标, 元素)
# 遍历
for ele in t:
print(ele)
for i in range(len(t)):
print(t[i])
for i, ele in enumerate(t):
print(i, ele)
5.5.5. 元组的操作
t = (28, 34, 56, 78, 19, 23, 45, 67, 19)
print(len(t)) # 元组的长度
print(t.index(19)) # 获取元素第一次出现的位置
print(t.index(19, 5)) # 从下标5开始第一次出现的位置
# 在区间[5,8)之间第一次出现的位置
# print(t.index(19, 5, 8)) # ValueError: tuple.index(x): x not in tuple
# 统计某个元素出现的次数
print(t.count(19)) # 2
5.5.6. 打包和解包
打包:当我们使用逗号分割定义多个数据,赋值给一个变量时, 会将数据打包成元组,赋值给该变量
解包:把序列中的元素赋值给多个变量时,把序列解包,将相同位置的数据赋值给对应位置的变量
# 打包
a = 10, 22, 33, 45, 61
print(type(a), a) # <class 'tuple'> (10, 22, 33, 45, 61)
# 解包
a, b, c = 'xyz'
print(a, b, c) # 'x' 'y' 'z'
m, n = [11, 27]
print(m, n) # 11 27
p, q, k = range(3)
print(p, q, k) # 0 1 2
需要注意:
当变量的个数与序列中元素个数不对等时,会出现问题报错的
# h, i, j = [19, 22] # ValueError: not enough values to unpack (expected 3, got 2) # h, i, j, l, e = [19, 22, 33, 56, 71, 89] # ValueError: too many values to unpack (expected 5) # h, i, j, l, e, *t = [19, 22, 33, 56, 71, 89, 78, 65] # print(h, i,j, l, e, t ) # 19 22 33 56 71 [89, 78, 65] # *t, h, i, j, l, e = [19, 22, 33, 56, 71, 89, 78, 65] # print(h, i,j, l, e, t ) # 56 71 89 78 65 [19, 22, 33] h, i, *t, j, l, e = [19, 22, 33, 56, 71, 89, 78, 65] print(h, i,j, l, e, t ) # 19 22 89 78 65 [33, 56, 71]这个错误可以使用星号表达式来解决 , 用
*修饰一个变量名,用它去接受过多的数据,因为*修饰完成之后将其变量容器型数据,可以来接受多个数据总结:
元组:可以容纳多个数据、可以容纳不同类型的数据(混装)、数据是有序存储的(下标索引)、允许重复数据存在、不可以修改(增加或删除元素等)、支持for循环、多数特性和list一致,不同点在于不可修改的特性。
5.6. set(集合)
由一个或多个确定的元素所构成的整体,称为集合,集合中的东西称为元素
集合的特点是 :
- 确定性 【要么在集合中 要么不在】
- 唯一性 【集合中的元素是唯一的 不重复的】
- 无序性
集合是可变的无序序列
5.6.1. 集合的定义
- 使用字面量
{}定义法 【不能定义空集合】- 使用
set()进行构造
# 1. 字面量方式
s = {18, 27, 33, 56, 41}
print(type(s), s) # <class 'set'> {33, 41, 18, 56, 27}
# 2. set构造
# 定义空集合的唯一方式
s0 = set()
print(s0) # set()
# 将其他序列转换成集合 顺便对元素去重
s1 = set('hello')
print(s1) # {'l', 'h', 'e', 'o'}
5.6.2. 集合的运算符
"""
& 交集 把数据存储在一个新的集合中
| 并集 把数据存储在一个新的集合中
^ 对称差 把数据存储在一个新的集合中
- 差集 把数据存储在一个新的集合中
&= 交集 修改前者
|= 并集 修改前者
^= 对称差 修改前者
-= 差集 修改前者
> 判断后者是否为前者的真子集
>= 判断后者是否为前者的子集
< 判断前者是否为后者的真子集
<= 判断前者是否为后者的子集
== 判断两个集合数据是否一样
!= 判断两个集合数据是否不一样
in 判断元素是否包含在集合中
not in 判断元素是否不包含在集合中
id 获取地址
is 判断地址是否一致
not is 判断地址是否不止一致
"""
s1 = {19, 22, 38, 41, 56, 27}
s2 = {22, 41, 56, 33, 29, 45}
# 交集
new_s = s1 & s2
print(new_s, s1, s2)
# {56, 41, 22} {38, 41, 19, 22, 56, 27} {33, 41, 45, 22, 56, 29}
# 并集
new_s = s1 | s2
print(new_s, s1, s2)
# {33, 38, 41, 45, 19, 22, 56, 27, 29} {38, 41, 19, 22, 56, 27} {33, 41, 45, 22, 56, 29}
# 差集
new_s = s1 - s2
print(new_s, s1, s2)
# {27, 19, 38} {38, 41, 19, 22, 56, 27} {33, 41, 45, 22, 56, 29}
# 对称差
new_s = s1 ^ s2 # 并集 - 交集
print(new_s, s1, s2)
# {33, 38, 45, 19, 27, 29} {38, 41, 19, 22, 56, 27} {33, 41, 45, 22, 56, 29}
s1 &= s2
print(s1, s2) # {56, 41, 22} {33, 41, 45, 22, 56, 29}
# 判断的操作
s3 = {19, 22, 45, 67, 82}
print(s3 > {22, 45, 67, 19, 82}) # False
print(s3 >= {22, 45, 67, 19, 82}) # True
print({67, 22} < s3) # True
print(s3 == {22, 45, 67, 19, 82}) # True
print(s3 != {22, 45, 67, 19, 82}) # False
print(19 in s3) # True
5.6.3. 集合的操作【了解】
有一些操作与集合的运算符是对应的
s1 = {13, 27, 38}
# 添加元素
s1.add(38)
print(s1) # 元素存在 不做响应
s1.add(19)
print(s1) # {19, 27, 13, 38}
# 移除
s1.remove(27) # 不是成员 会报错
print(s1)
s1.discard(27) # 不是成员 不做响应
print(s1)
# s1.clear() # 清空
# 拷贝集合
s2 = s1.copy()
print(s2)
# 判断两个集合是否不存在交集
print({12, 34}.isdisjoint({77, 82})) # True
print({12, 34}.isdisjoint({77, 82, 12})) # False
# 因为集合没有索引,所以只能使用追简单的for循环操作
for ele in s1:
print(ele)
5.6.4. 不可变集合(frozenset)
frozenset与set的关系 和tuple与list的关系差不多
# 构造定义不可变集合 【把其他序列转变成不可变集合】
fs = frozenset({12, 34, 56, 7})
print(fs)
fs1 = frozenset([33, 56, 27, 15])
print(fs1)
print(fs & fs1) # frozenset({56})
总结:
集合:可以容纳多个数据、可以容纳不同类型的数据(混装)、数据是无序存储的(不支持下标索引)、不允许重复数据存在、可以修改(增加或删除元素等)、支持for循环
5.7. dict(字典、映射)
类似于新华字典的结构,里面的数据放的是成对的数据,这个数据叫做键值对
这个键类似于新华字典中要查的词,值就类似于这个词对应的解释
在新华字典中需要先定位到字,才能查到相应的解释
Python中字典的结构是一样的,是根据键定位到值的。所以对键是有要求的:
- 不允许重复
- 不允许发生变化 【键对应的类型必须是不可变的 --整数 字符串 元组】
字典的数据结构本质是无序的可变序列 【在Python3.6的时候做了一个优化,字典的从内存角度来说比3.5及其之前的降低25%, 展示的时候跟书写的时候 顺序是一致的】
无序的数据就没有编号【索引】这一说。字典中定位数据就通过键来定位的,字典的键就等同于有序数据的索引
5.7.1. 字典的定义
- 通过
{}字面量法来定义,存在键值对的时候,结构是{key: value, key1: value1}- 通过
dict()来进行构造的
# 1. 定义一个空字典
d0 = {}
print(type(d0)) # <class 'dict'>
d1 = {'语文': 77, '数学': 87, '英语': 85}
print(d1) # {'语文': 77, '数学': 87, '英语': 85}
# 比列表的好处在于可以清晰的看出数据所表达的意义 [77, 87, 85]
# 2. dict构造
# 空字典
d2 = dict()
print(d2) # {}
# 将其他序列转化成字典的时候 对这个序列有要求
'''
字典比较特殊 呈现一个数据的话需要两个值来配合 一个做键 一个做值
因此把其他序列转换成字典的话 这个序列得是二维的, 内层序列得有两个元素
[['语文', 77], ['数学', 78]]
'''
d3 = dict([('语文', 77), ('数学', 78), ('英语', 87)])
print(d3) # {'语文': 77, '数学': 78}
d4 = dict(enumerate('abcdef')) # enumerate('abcdef') 对序列重组 组合二维的 内层是二元组 (索引, 元素)
print(d4) # {0: 'a', 1: 'b', 2: 'c', 3: 'd', 4: 'e', 5: 'f'}
# 另外一种构造方式
# dict(变量名=数据值, 变量名1=数据值1) # 把变量名转化为字符串类型 作为字典的键
d5 = dict(a=97, b=98, c=99, d=100)
print(d5) # {'a': 97, 'b': 98, 'c': 99, 'd': 100}
5.7.2. 字典的运算符
scores = {'语文': 78, '数学': 97, '英语': 82, '政治': 77}
print('语文' in scores) # True
print(77 in scores) # False
print('历史' not in scores) # True
scores1 = {'语文': 78, '数学': 97}
print(id(scores))
print(scores is scores1)
print(not scores is scores1)
# print(scores > scores1)
# TypeError: '>' not supported between instances of 'dict' and 'dict'
5.7.3. 字典的操作
scores = {'语文': 78, '数学': 97, '英语': 82, '政治': 77}
# 1. 添加数据
# 添加新的键值对
'''
字典数据[键] = 值
键不存在 会将其作为新的键值对添加在字典中
键若存在 将字典中该键对应的值进行修改
'''
scores['历史'] = 65
print(scores) # {'语文': 78, '数学': 97, '英语': 82, '政治': 77, '历史': 65}
scores['英语'] = 28
print(scores) # {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65}
'''
字典数据.setdefault(键, 值)
键不存在 添加新的键值对
键若存在 不做任何反应
'''
scores.setdefault('化学', 78)
print(scores)
# {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78}
scores.setdefault('数学', 79)
print(scores) # {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78}
# 合并其他序列的元素
scores.update({'生物': 77, '地理': 56})
print(scores)
# {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78, '生物': 77, '地理': 56}
# 序列得是二维的
scores.update([('物理', 87), ('体育', 98)])
print(scores)
# {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78, '生物': 77, '地理': 56, '物理': 87, '体育': 98}
# 2. 删除数据
# 【根据键 把整个键值对就都删除】
'''
del 字典数据[键]
'''
del scores['历史']
print(scores)
# {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '化学': 78, '生物': 77, '地理': 56, '物理': 87, '体育': 98}
'''
字典数据.pop(键)
和del的区别是 这个删完之后可以获取到键对应的值
'''
value = scores.pop('生物')
print(scores) # {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '化学': 78, '地理': 56, '物理': 87, '体育': 98}
print(value) # 77
'''
清空字典
'''
# scores.clear()
# print(scores) # {}
# 3. 获取相关数据信息
# 根据键获取值
'''
变量名 = 字典数据[键]
键若存在 获取键对应的数据值
键若不存在 就报错
'''
value = scores['语文']
print(value) # 78
# value = scores['生物'] # KeyError: '生物'
'''
变量名 = 字典数据.get(键)
键若存在 获取键对应的数据值
键若不存在 不会报错 返回的是None
'''
value = scores.get('语文')
print(value) # 78
value = scores.get('生物')
print(value) # None
# 当键不存在的时候 可以自定义相应的数据 键存在 还是把键对应的值返回
value = scores.get('语文', 0)
print(value) # 78
value = scores.get('生物', 0)
print(value) # 0
# 获取所有的键
all_keys = scores.keys()
print(all_keys) # dict_keys(['语文', '数学', '英语', '政治', '化学', '地理', '物理', '体育']) 一维数据
# 获取所有的值
all_values = scores.values()
print(all_values) # dict_values([78, 97, 28, 77, 78, 56, 87, 98]) 一维数据
# 获取所有的键值组合
all_items = scores.items()
print(all_items)
# dict_items([('语文', 78), ('数学', 97), ('英语', 28), ('政治', 77), ('化学', 78), ('地理', 56), ('物理', 87), ('体育', 98)])
# 二维数据 内层是二元组 (键, 值)
# 4.其他的操作
# 拷贝字典
new_scores = scores.copy()
print(new_scores)
# 构造键序列构造字典[值默认为None] dict.fromkeys(键)
d0 = dict.fromkeys('abcdefg')
print(d0) # {'a': None, 'b': None, 'c': None, 'd': None, 'e': None, 'f': None, 'g': None}
# dict.fromkeys(键序列, 值) # 给键设置值
d1 = dict.fromkeys('abcdefg', 0)
print(d1)
# {'a': 0, 'b': 0, 'c': 0, 'd': 0, 'e': 0, 'f': 0, 'g': 0}
5.7.4. 字典的遍历
scores = {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78, '生物': 77, '地理': 56}
# 直接遍历
for key in scores:
print(key)
'''
语文
数学
英语
政治
历史
化学
生物
地理
'''
print('=' * 20)
# 等同于遍历 字典.keys()
for k in scores.keys():
print(k, scores[k])
print('=' * 20)
# 直接遍历字典的所有的值
for v in scores.values():
print(v)
'''
78
97
28
77
65
78
77
56
'''
print('=' * 20)
# ******* 对字典进行操作 既要获取键 又要获取值 对字典的所有条目进行操作 字典.items()
for item in scores.items():
print(item, item[0], item[1]) # 元组类型的数据
'''
('语文', 78)
('数学', 97)
('英语', 28)
('政治', 77)
('历史', 65)
('化学', 78)
('生物', 77)
('地理', 56)
'''
print('=' * 20)
# d0 = dict(scores.items())
# print(d0)
for k, v in scores.items():
print(k, v)
# 语文 78
# 数学 97
# 英语 28
# 政治 77
# 历史 65
# 化学 78
# 生物 77
# 地理 56
5.7.5. 字典推导式
类似于列表推导式
格式
{键的变量: 值的变量 for 键的变量, 值的变量 in 字典.items() if 判断条件}
scores = {'语文': 88, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78, '生物': 77, '地理': 56}
# 获取成绩在80及其以上的 科目与成绩信息
'''
思路:
1. 定以一个空字典 用来存储获取的信息
2. 遍历获取所有的键值信息
3. 判断操作 将符合要求的放在存储信息的字典中
'''
scores_80 = {}
# 遍历
for k, v in scores.items():
if v >= 80:
scores_80[k] = v
print(scores_80) # {'语文': 88, '数学': 97}
print({k: v for k, v in scores.items() if v >= 80})
# 成绩在60到80之间的 科目及其成绩信息
scores_6080 = {}
print({k: v for k, v in scores.items() if 60 <= v <= 80})
总结:
字典:可以容纳多个数据、可以容纳不同类型的数据、每一份数据是KeyValue键值对、可以通过Key获取到Value,Key不可重复(重复会覆盖)、不支持下标索引、可以修改(增加或删除更新元素等)、支持for循环,不支持while循环
5.8. 容器类型总结
数据容器分类
数据容器可以从以下视角进行简单的分类:
是否支持下标索引:
支持:列表、元组、字符串 - 序列类型
不支持:集合、字典 - 非序列类型
是否支持重复元素:
支持:列表、元组、字符串 - 序列类型
不支持:集合、字典 - 非序列类型
是否可以修改:
支持:列表、集合、字典
不支持:元组、字符串
数据容器特点对比
| 列表 | 元组 | 字符串 | 集合 | 字典 | |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | Key:Value Key:除字典外任意类型 Value:任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的一批数据记录场景 | 不可修改、可重复的一批数据记录场景 | 一串字符的记录场景 | 不可重复的数据记录场景 | 以Key检索Value的数据记录场景 |
基于各类数据容器的特点,它们的应用场景如下:
- 列表:一批数据,可修改、可重复的存储场景
- 元组:一批数据,不可修改、可重复的存储场景
- 字符串:一串字符串的存储场景
- 集合:一批数据,去重存储场景
- 字典:一批数据,可用Key检索Value的存储场景
5.9. 容器综合案例
双色球
玩法规则:
“双色球”每注投注号码由 6 个红色球号码和 1 个蓝色球号码组成。红色球号码从 1—33 中选择,蓝色球号码从 1—16 中选择。 球的数字匹配数量和颜色决定了是否中奖。
具体中奖规则:
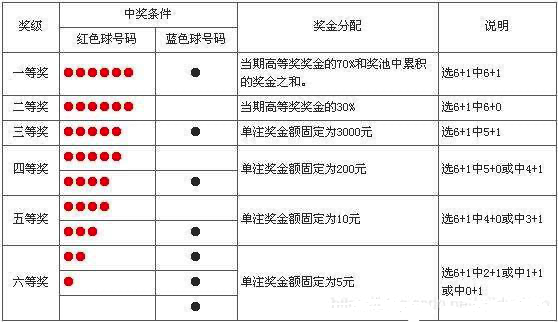
需求:
1.生成本期双色球中奖号码。
(注意:1.生成的红球随机有序且不可重复、2.蓝球和红球的随机范围不同且篮球允许和红球重复)2.两种产生数据方式
2.1通过控制台输入竞猜号码。
2.2自动生成
3.记录红球、蓝球竞猜正确球的数量,并根据获奖条件输出竞猜结果和本期双色球号码
运行效果图:
启动画面

机选效果


自选效果


# @Author : 大数据章鱼哥
# @Company : 北京千锋互联科技有限公司
import random
def get_custom_balls():
# 准备一个彩票
balls = []
# 让用户输入选择
while True:
input_red = input("请输入6个红球(范围1-33): ")
input_red = input_red.split()
if len(input_red) != 6:
print("红球数量错误,请重新输入")
continue
# 将6个红球转成整型
input_red = [int(x) for x in input_red]
# 对红球进行排序
input_red.sort()
# 判断红球是否越界
if input_red[0] < 1 or input_red[5] > 33:
print("红球越界了,请重新输入")
continue
# 判断红球是否重复
if len(set(input_red)) < 6:
print("红球重复了,请重新输入")
continue
balls += input_red
break
# 让用户输入蓝球
while True:
input_blue = int(input("请输入一个蓝球(范围1-16): "))
if input_blue > 16 or input_blue < 0:
print("蓝球越界,请重新输入")
continue
balls.append(input_blue)
break
return balls
def get_random_balls():
# 准备一个红球池
red_balls = list(range(1, 34))
# 创建双色球
balls = []
# 循环6次,取6个红球
for i in range(6):
# 生成一个随机下标
random_index = random.randint(0, len(red_balls) - 1)
# 从红球池中获取一个随机的球,从中移除,并添加到双色球中
balls.append(red_balls.pop(random_index))
# 对红球排序
balls.sort()
# 随机篮球
balls.append(random.randint(1, 16))
return balls
def get_ball_desc(balls):
red = map(lambda x: f"{x:02d}", balls[:6])
blue = f"{balls[6]:02d}"
return f"红球: {', '.join(red)} 蓝球: {blue}"
def get_ticket_money(level):
mapping = {1: 5000000, 2: 500000, 3: 3000, 4: 200, 5: 10, 6: 5, 7: 0}
return mapping.get(level, 0)
def check_balls(user_balls, ticket_balls):
# 将用户选择的双色球、中奖号码双色球的红球部分提取到set中
user_balls_set = set(user_balls[:6])
ticket_balls_set = set(ticket_balls[:6])
# 计算两个集合的交集,长度就是中奖号码的个数
red_number = len(user_balls_set & ticket_balls_set)
# 计算蓝球数量
blue_number = 1 if user_balls[6] == ticket_balls[6] else 0
# 记录中奖等级
if red_number == 6 and blue_number == 1:
ticket_level = 1
elif red_number == 6 and blue_number == 0:
ticket_level = 2
elif red_number == 5 and blue_number == 1:
ticket_level = 3
elif red_number + blue_number == 5:
ticket_level = 4
elif red_number + blue_number == 4:
ticket_level = 5
elif blue_number == 1:
ticket_level = 6
else:
ticket_level = 7
return ticket_level, get_ticket_money(ticket_level)
def get_level_upper(ticket_level):
mapping = {1: '一等奖', 2: '二等奖', 3: '三等奖', 4: '四等奖', 5: '五等奖', 6: '六等奖'}
return mapping.get(ticket_level)
def user_operation():
"""
用户的操作界面
:return: None
"""
print(f"{' 欢迎使用双色球系统 ':*^60}")
while True:
# 让用户输入自己的选择
while True:
user_choice = int(input("请输入您的选择: 1、自选号码 2、机选号码 0、退出系统 "))
if user_choice in (0, 1, 2):
break
# 根据用户的选择,执行不同的操作,生成用户选择的双色球
user_balls = []
match user_choice:
case 1:
user_balls = get_custom_balls()
case 2:
user_balls = get_random_balls()
case 0:
break
# 系统随机生成一注双色球,作为中奖号码
ticket_balls = get_random_balls()
# 匹配两注双色球,获取中奖等级以及奖金
ticket_level, ticket_money = check_balls(user_balls, ticket_balls)
# 打印最后的结果
print(f"您的选择是: {get_ball_desc(user_balls)}")
print(f"中奖号码是: {get_ball_desc(ticket_balls)}")
if 1 <= ticket_level <= 6:
print(f"🎉🎉🎉恭喜!!!您中了{get_level_upper(ticket_level)},奖金 {ticket_money:,}元!")
else:
print("很遗憾,您本次没有中奖,请再接再厉!")
print("再见!欢迎下次再来使用!")
user_operation()