-
用redis有遇到过大key问题吗,怎么解决
-
我介绍项目中用异步解耦的思路来从mysql同步数据到redis,具体就是binlog+kafaka。面试官问读的主mysql的binlog,还是从的binlog。A:主mysql。Q:可以用什么中间件读binlog。A:可以用Canal。Q:除了Canal呢。参考答案1:kafka-connect、Maxwell。Q:读主mysql的binlog会有什么问题? 我没觉得有什么问题,找了一些相关文章:MySQL事务还没提交,Canal就能读到消息了?、canal基于binlog同步方案的局限性和思考,其中后面那一篇1.2.canal 高可用问题的部分完全没看懂。
-
当kafka某topic有8个partition, 消费者组的消费者小于8个,会如何分配partition? 参考答案2,3:kafka的3种消费者分区分配策略:
-
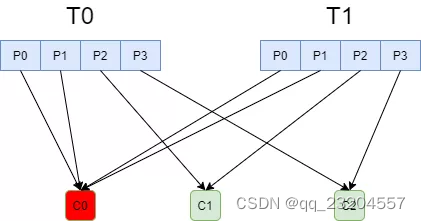
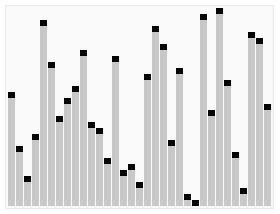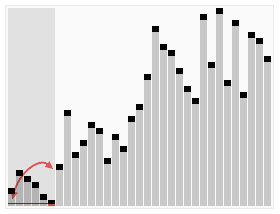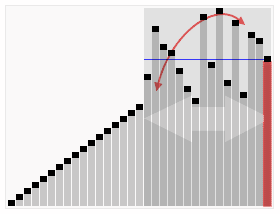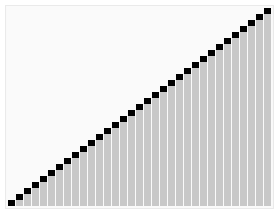
range : RangeAssignor对每个Topic进行独立的分区分配:
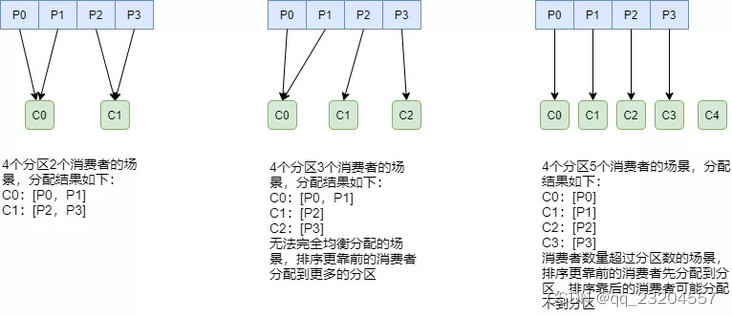
这种分配方式明显的一个问题是随着消费者订阅的Topic的数量的增加,不均衡的问题会越来越严重:
-
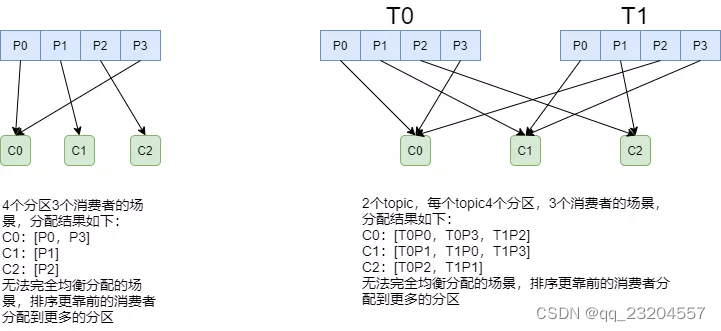
round-robin : 将消费组内订阅的所有Topic的分区排序,所有消费者排序后,尽量均衡分配(RangeAssignor是针对单个Topic的分区进行排序分配的):
-
sticky:sticky分配策略是从0.11.x版本开始引入的分配策略,它主要有两个目的:
(1)分区的分配要尽可能均匀。
(2)分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优于第二个目标。
假设消费者组内有3个消费者(C0、C1、C2),他们都订阅了4个主题(t0、t1、t2、t3),并且每个主题有两个分区。也就是说,整个消费者组订阅了t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1 8个分区。最终的分配结果为
消费者C0:t0p0、t1p1、t3p0
消费者C1:t0p1、t2p0、t3p1
消费者C2:t1p0、t2p1
这看上去似乎与round robin分配策略相同,事实上并不是这样。假设此时C1脱离了消费者组,那么消费者组就会执行rebalance,进而消费分区会重新分配。如果采用round robin策略,那么此时的分配结果如下
消费者C0:t0p0、t1p0、t2p0、t3p0
消费者C2:t0p1、t1p1、t2p1、t3p1
如果采用sticky分配策略,那么分配结果为
消费者C0:t0p0、t1p1、t3p0、t2p0
消费者C2:t1p0、t2p1、t0p1、t3p1
可以看到分配结果中保留了上一次分配中对消费者C0和C2的所有的分配结果,并将原来的消费者C1的负担分配给了剩余的两个消费者C0和C1,最终C0和C2的分配还保持了平衡。
- 生产环境下kafka的broker出现硬盘不足的告警,应该怎么办?参考答案:
- 磁盘扩容4
- 清理老数据4
- Kafka 对于数据迁移的官方说法是分区重分配。即重新分配分区在集群的分布情况。官方提供了kafka-reassign-partitions.sh脚本来执行分区重分配操作5
-
生产环境下kafka发生rebalance,会有什么问题?参考答案6:
1、可能重复消费: Consumer被踢出消费组,可能还没有提交offset,Rebalance时会Partition重新分配其它Consumer,会造成重复消费,虽有幂等操作但耗费消费资源,亦增加集群压力
2、影响消费速度:频繁的Rebalance反而降低了消息的消费速度,大部分时间都在重复消费和Rebalance -
ElasticJob为什么需要zookeeper? 参考答案7,8:
Elastic-Job依赖Zookeeper实现选举机制,在任务执行实例数量变化时(如启动新的实例或停止实例),会触发选举机制,选举出Leader实例,Leader主要进行分片的划分。即将任务划分成多个分片,然后由多个执行的机器分别领取这些分片来执行。比如一个数据库中有 1 亿条数据,需要将这些数据读取出来并计算,然后再写入到数据库中。就可以将这 1 亿条数据划分成 10 个分片,每一个分片读取其中的 1 千万条数据,然后计算后写入数据库。这 10 个分片编号为 0,1,2…9,如果有三台机器执行,A 机器分到分片(0,1,2,9),B 机器分到分片(3,4,5),C 机器分到分片(6,7,8) 。Leader将划分后的结果存放到 zookeeper 中,然后每个节点再从 zookeeper 中获取划分好的分片项。
利用 zookeeper 的 watch 机制来监听系统中各种元数据的变化,从而执行相应的操作。
持久化各种元数据到 zookeeper,如作业的配置信息,每个服务实例的信息等。 -
为什么选型elasticJob
kafka-connect实时流的应用 ↩︎
Kafka 原理以及分区分配策略剖析----2.3.2 分区分配策略 ↩︎
Kafka Rebalance详解 ↩︎
阿里云------EMR Kafka磁盘写满运维 ↩︎ ↩︎
腾讯云中间件团队------避坑指南:Kafka集群快速扩容的方案总结 ↩︎
Kafka的Rebalance机制可能造成的影响及解决方案 ↩︎
Elastic-Job 的执行原理及优化实践 ↩︎
本博------如何执行定时任务,以及分布式任务调度 ↩︎


![React学习[一]](https://img-blog.csdnimg.cn/fcc4c6119248446292444821628c1d96.png#pic_center)