require(graphics)# 加载库
par(lwd =2)# 打开绘图板
color = hsv(seq(0,1,1/7))# 设置颜色
Be =function(x, a, b){
dbeta(x, a, b)}
curve(Be(x,1/2,1/2), xlim = c(0,10), ylim = c(0,2),# 画线+设置坐标刻度
ylab = expression(paste("Ga(",alpha,",",lambda,")")),# 设置y轴名称
col = color[1],# 设置颜色
main ="Beta-Density", lty =1)# 设置图名称
curve(Be(x,3/2,3/2), col = color[2], add = T)# add 图坐标以创建,添加线
legend("topright", c("Be(1 / 2, 1 / 2)","Be (3 / 2,3 / 2)"),
col = color, bty ="n", cex =1.2, pch =15)# 设置左上角图例
(3)用plot函数画N(0, 1), t(20), t(10), t(5), t(2)
3、简单抽样(一)
replicate # 重复
(1)从R中装载数据集"cars"
data("cars")
Y = cars[,2]# 将数据集cars中的第二列数据构成Y数组
(2)iteration = 100, N = 50, n = 10 时的误差
N = length(Y)
n =10
iteration=100
y = replicate(Iteration, sample(Y, n))
ybar = apply(y,2, mean)# 选择列来进行平局n
Eybar = mean(ybar)#计算期望
Dx = Eybar - mean(Y)
Dx
(3)iteration = 500, N = 50, n = 10 时的误差
data("cars")
Y = cars[,2]
N = length(Y)
n =10
iteration =500
y = replicate(iteration, sample(Y, n))
ybar = apply(y,2, mean)
Eybar = mean(ybar)
Dx = Eybar - mean(Y)
Dx
[1]-0.1918
Eybar
[1]42.7882
ybar
(4)iteration = 1000, N = 50, n = 10 时的误差
data("cars")
Y = cars[,2]
N = length(Y)
n =10
iteration =1000
y = replicate(iteration, sample(Y, n))
ybar = apply(y,2, mean)
Eybar = mean(ybar)
Dx = Eybar - mean(Y)
Dx
0.0226
(5)编写循环语句,计算iteration从100到2000,步长为100的误差
data("cars")
Y = cars[,2]
N = length(Y)
n =10for(iteration in seq(100,2000,100)){
y = replicate(iteration, sample(Y, n))
ybar = apply(y,2, mean)
Eybar = mean(ybar)
Dx = Eybar - mean(Y)
print(Dx)}
(6)编写程序,画出(5)中误差变化的情况
require(graphics)
data("cars")
Y = cars[,2]
N = length(Y)
n =10for(iteration in seq(100,2000,100)){
y = replicate(iteration, sample(Y, n))
ybar = apply(y,2, mean)
Eybar = mean(ybar)
Dx[iteration /100]= Eybar - mean(Y)}
plot(x = seq(100,2000,100), y = Dx, type ='o', xlab ='iteration', ylab ='Dx', col ='red')
(7) 将(5)中的结果记录到"record"文件
write.table(Dx, file ='record.txt', col.names=F)
4、简单抽样(二)
1、产生200个均值15, 标准差1的正态随机数
mu =15# 均值
sigma =1# 标准差
N =200
r = rnorm(N, mu , sigma)
r
2、用简单随机抽样方法(无放回),抽取样本容量为20的样本
mu =15# 均值
sigma =1# 标准差
N =200
n =20
Y = rnorm(N, mu, sigma)
r = sample(Y, n)
r
3、抽培养如2所示样本100个,分别用for循环、replicate()实现
# for 循环
mu =15
sigma =1
N =200
n =20
Y = rnorm(N, mu, sigma)
number =100
r = replicate(number, sample(Y, n))
r
# replicate()
mu =15
sigma =1
N =200
n =20
Y = rnorm(N, mu, sigma)
number =100for(i in1: number) r[, i]= sample(Y, n)
r
4、计算100个样本中每个样本的样本均值、样本标准差
mu =15
sigma =1
N =200
n =20
Y = rnorm(N, mu, sigma)
number =100
y = replicate(number, sample(Y, n))
ybar = apply(y,2, mean)# 计算每一个样本均值
s = apply(y,2, sd)# 计算每一个样本标准差
ybar
5、根据每个样本,计算总体均值的置信水平95%的置信区间
mu =15
sigma =1
N =200
n =20
Y = rnorm(N, mu, sigma)
number =100
y = replicate(number, sample(Y, n))
ybar = apply(y,2, mean)
s = apply(y,2, sd)
f = n / N
ybar = apply(y,2, mean)
s = apply(r,2, sd)
yl = ybar - sqrt((1- f)/ n)* s
yu = ybar + sqrt((1- f)/ n)* s
yl # 置信下区间
yu # 置信上区间
6、在平面直角坐标系中画出100个置信区间
mu =15
sigma =1
N =200
n =20
Y = rnorm(N, mu, sigma)
number =100
y = replicate(number, sample(Y, n))
s = apply(y,2, sd)
f = n / N
ymean = apply(y,2, mean)
s = apply(r,2, sd)
yl = ymean - sqrt((1- f)/ n)* s
yu = ymean + sqrt((1- f)/ n)* s
f = n / N
u =1.96# 制作图表
plot (1, xlim=c(0.5, number +0.5), ylim = c(min(yl)-0.5, max(yu)+0.5),
type ="n", xlab ="Trials", ylab ="Confidence Intervals",
main = expression(paste("Confidence Interval of 1-", alpha, sep=" ")))# 绘制线条for(i in1: number){
arrows(i, yl[i], i, yu[i], length =0.1, angle =90, code =3,
col = ifelse(ymean > yl[i]& ymean < yu[i],"blue","red"))
points(i, ymean[i])}#Sys.sleep(0.5)
7、 计算100个置信区间的置信概率
mu =15
sigma =1
N =200
n =20
Y = rnorm(N, mu, sigma)
number =100
y = replicate(number, sample(Y, n))
s = apply(y,2, sd)
f = n / N
ymean = apply(y,2, mean)
s = apply(r,2, sd)
yl = ymean - sqrt((1- f)/ n)* s
yu = ymean + sqrt((1- f)/ n)* s
f = n / N
u =1.96
plot (1, xlim=c(0.5, number +0.5), ylim = c(min(yl)-0.5, max(yu)+0.5),
type ="n", xlab ="Trials", main = expression(paste("Confidence Interval of 1-", alpha, sep=" ")),
ylab ="Confidence Intervals")
cn =0# 1for(i in1: number){
arrows(i, yl[i], i, yu[i], length =0.1, angle =90, code =3,
col = ifelse(ymean > yl[i]& ymean < yu[i],"blue","red"))
points(i, ymean[i])
cn = cn + as.numeric(ymean > yl[i]& ymean < yu[i])# 1}
abline(h = ymean, lty =2,)# 1
cp = cn / number # 1
cat ("Confidence Probability = ", cp)# 1
# 1.1
pre = c(550,720,1500,1020,620,980,928,1200,1350,1750,670,729,1530)
now = c(610,780,1600,1030,600,1050,977,1440,1570,2210,980,865,1710)
y_tilde = sum(now)/ sum(pre)*128200
y_tilde
t.test(now / pre *128200)
data: now/pre *128200
t =32.17, df =12, p-value =5.142e-13
alternative hypothesis: true mean is not equal to 095 percent confidence interval:# 95%置信区间135639155347
sample estimates:# 样本估计
mean of x
145493
# 1.2
pre = c(550,720,1500,1020,620,980,928,1200,1350,1750,670,729,1530)
now = c(610,780,1600,1030,600,1050,977,1440,1570,2210,980,865,1710)
y_tilde = sum(now)/ sum(pre)*128200
y_tilde
t.test(now / pre *128200)
xbar = mean(pre)
ybar = mean(now)
N =123
n =13
X =128200
sxy = cov(pre, now)
varx = var(pre)
vary = var(now)
R = ybar / xbar
Yrbar = R * X
a = sxy / varx
Xbar = X / N
ylr = N ^2*(1- n / N)
se = sqrt((n -1)*(vary - a * sxy)/(n -2))
vYlr = N ^2*(1- n / N)* se **2/ n
sd = sqrt(vYlr)
alpha =0.05(C = Q(Yrbar, sd, alpha))
输入信号与冲激响应的离散卷积 系统冲激响应: h ( t ) ∑ τ 0 ∞ x ( t ) δ ( t − τ ) h(t)\sum_{\tau0}^{\infty}x(t)\delta(t-\tau ) h(t)τ0∑∞x(t)δ(t−τ)
上式中 h ( t ) h(t) h(t)是冲激信号输入到系统后系统的输出,也是系统对外在激…
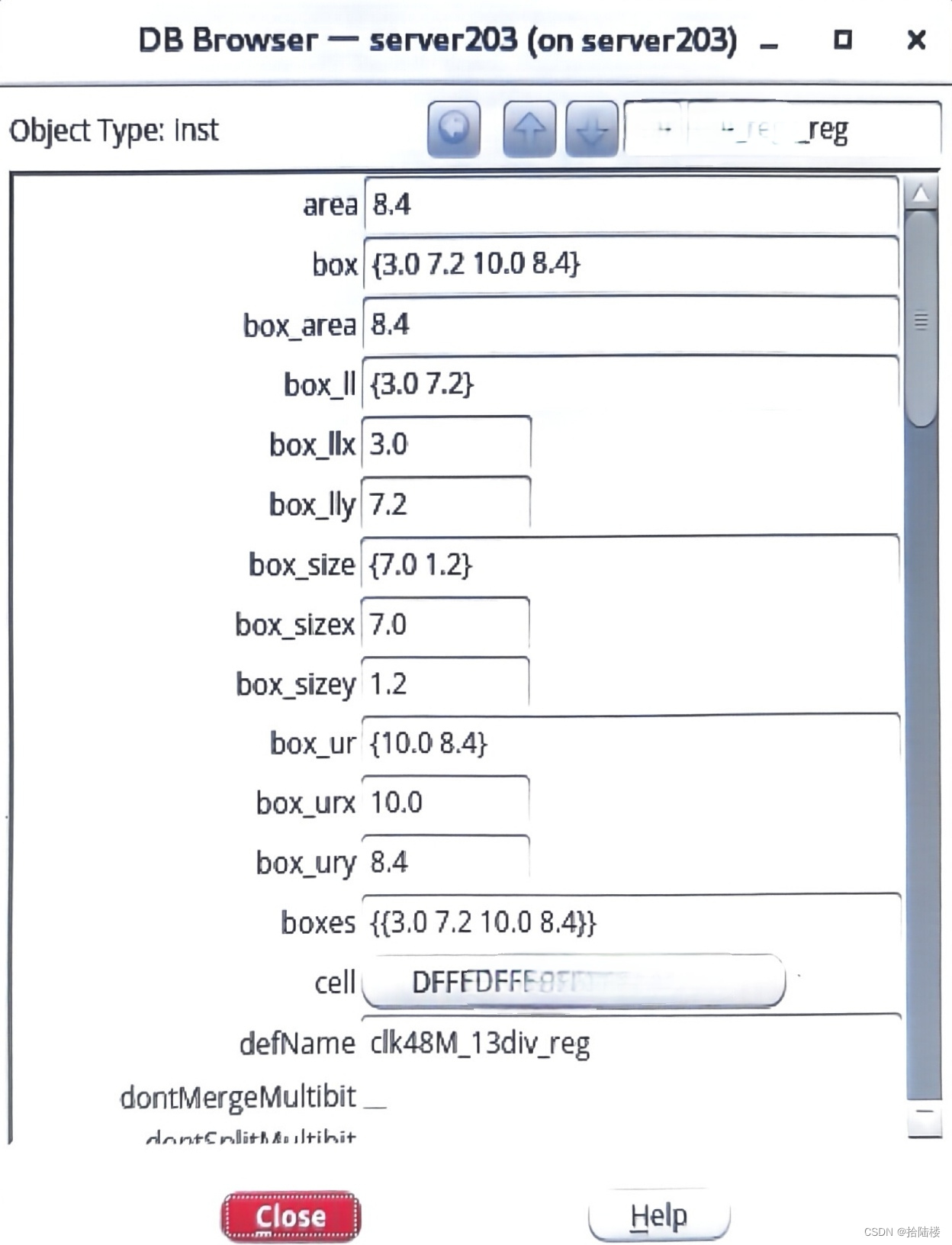
dbGet是innovus/encounter工具自带的"database access command"命令中的一部分,它几乎可以用来获取设计相关的一切信息。
输入dbGet 按[Tab]键,能看到三个选项,分别是head / top /selected。这三个选项所代表的意义如下:
head --…
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iqYJOXau-1686833845961)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230613162257583.png)]](https://img-blog.csdnimg.cn/2588a56a7c494220a3e6d1c62aed9e41.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QInDbmMt-1686833746631)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230613163926996.png)]](https://img-blog.csdnimg.cn/ef18b11eac094429848c67280039e40d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CHjoIt1c-1686833915840)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230614215217276.png)]](https://img-blog.csdnimg.cn/08699d36b2044b65b80b9cf02fb56478.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v2CRXamF-1686834005316)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230614223136724.png)]](https://img-blog.csdnimg.cn/3931b7bcc2634d58afab018aa261381d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jb5Rn37z-1686834005319)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230614224003299.png)]](https://img-blog.csdnimg.cn/34ef06ef3ef64983b4057d21da6664b1.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QI92sZ9g-1686834005320)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230614224022561.png)]](https://img-blog.csdnimg.cn/ec18e7ce2ebb42bf8f21a0eeab0ac458.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-47q17ok8-1686834065957)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230614224750954.png)]](https://img-blog.csdnimg.cn/5dedcce7280b4ed997fa81706eb428e3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GTAWA4M4-1686834065957)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230614224759788.png)]](https://img-blog.csdnimg.cn/808af02745ae4efda90ffb29a88fbd6c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AfpLaI78-1686834065958)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230614224812351.png)]](https://img-blog.csdnimg.cn/7637d0eb22674dd4960fe5161e13e215.png)