何为柔性数组
所谓柔性数组,是C语言中的一个概念,也叫零长数组。顾名思义,这个数组的长度是不固定的,当没有值时,它的sizeof长度为0。
我们一般这样定义一个柔性数组:
struct buffer_t {
int len;
char buf[]; //柔性数组
};
上面的结构体struct buffer_t中的char buf[]就是一个柔性数组。
那么,怎样才算满足一个柔性数组的定义呢?它至少要满足以下这几个条件:
- 柔性数组必须要定义在结构体中
- 柔性数组必须位于结构体的最后一个位置
- 结构体中除了柔性数组以外,还必须有其他的成员
柔性数组如何使用
上面的struct buffer_t,如果我们对它求sizeof,其实是等于int len的长度的,也就是说 ,char buf[]在结构体里并没有占长度,这也就是零长数组说法的由来。
因此,如果我们想要定义一个1024字节的数组 ,可以这样做:
struct buffer_t *buffer = malloc(sizeof(struct buffer_t) + 1024 * sizeof(char));
我们之所以能够这样定义,是因为柔性数组正好处于结构体的最后一个元素 。
而柔性数组的赋值和访问,这就和普通数组一样的使用就行了。
strcpy(buffer->buf, "hello world");
printf("buf: %s\n", buffer->buf);
柔性数组的好处
那么,为啥会有柔性数组这么奇怪的定义?它和传统的数组定义相比,有啥好处呢?
假设我们不用柔性数组,想要定义一个可以随时使用的字符串,可能的定义方法如下:
struct normal_buffer_t {
char *buf;
int len;
};
而我们需要给该数组申请空间的时候,可能需要做下面几件事:
struct normal_buffer_t *nbuffer = malloc(sizeof(struct normal_buffer_t));
nbuffer->buf = malloc(1024);
当释放的时候,则需要释放两次:
free(nbuffer->buf);
free(nbuffer);
这也就意味着,我们需要给buf单独的申请和释放内存,而对于柔性数组,就没有这个麻烦,对于C语言这样一门需要手动管理内存的编程语言来说,很可能一不留神就遗漏了一次释放,造成内存泄露。
当然这还不是最主要的,而是每多一次malloc,就会多一次系统开销,也会增加内存碎片产生,如果这样的操作很多,那么进程将会产生非常多的内存碎片,严重的情况将导致没有一块比较完整的内存以供后来的程序片段使用,从而造成coredump。
对于传统的数组,它在内存里分布可能是如下的样子:
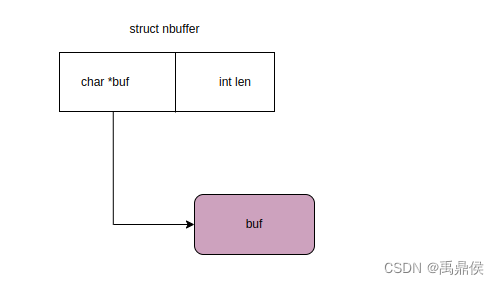
而柔性数组,它在内存里则是连续的:

场景应用
假设我们现在要定义一个字符串,该字符串可以自动扩缩容,可以非常方便地追加数据,按常规做法,我们可能有如下代码:
typedef struct buf_t {
char *data; //存储数据的字符串
int cap; //buf的容量
int size; //字符串实际长度
}buf_t;
#define BUF_CAP_DEFAULT 1046576
//根据长度申请buf
buf_t *buf_new_size(int cap){
buf_t *buf = calloc(1, sizeof(buf_t));
buf->size = 0;
buf->cap = cap;
buf->data = (char *)calloc(1, cap);
return buf;
}
//默认创建出1M大小的buf
buf_t *buf_create(){
return buf_new_size(BUF_CAP_DEFAULT);
}
//内存扩容
void buf_scale_up(buf_t *buf, int cap){
int new_cap = cap << 1;
buf->data = realloc(buf->data, new_cap);
buf->cap = new_cap;
}
//内存缩容
void buf_scale_down(buf_t *buf, int cap){
int new_cap = cap >> 1;
buf->data = realloc(buf->data, new_cap);
buf->cap = new_cap;
}
//往buf中追加数据,如果超出最大容量,自动扩容
void buf_append(buf_t *buf, char *data, int size){
if (buf->size + size > buf->cap) {
buf_scale_up(buf, buf->size + size);
}
memcpy(buf->data + buf->size, data, size);
buf->size += size;
}
//重置buf
void buf_reset(buf_t *buf){
static int reset_times = 0;
if ((buf->size << 1) < buf->cap) {
reset_times++;
}
if (reset_times > 3) {
buf_scale_down(buf, buf->cap);
reset_times = 0;
}
memset(buf->data, 0, buf->size);
buf->size = 0;
}
//销毁buf, 释放内存
void buf_destory(buf_t *buf){
if (buf->data){
free(buf->data);
buf->data = NULL;
}
if (buf){
free(buf);
buf = NULL;
}
}
我们在使用的时候,只需要像下面这样做就行了:
int main(void){
buf_t *buf = buf_create();
buf_append(buf, "hello", 5);
buf_append(buf, ", world", 7);
printf("buf: %s\n", buf->data);
buf_destory(buf);
return 0;
}
这种做法比之我们即用即申请本身已经优化了很多,即不需要频繁的malloc和free,而是尽量复用同一块内存,这样可以有效减少内存碎片。但是对于结构体本身和data,我们仍然是分开申请了两次,这一块还可以用柔性数组进行优化:
typedef struct buf_t {
int cap; //buf的容量
int size; //字符串实际长度
char data[]; //柔性数组
}buf_t;
#define BUF_CAP_DEFAULT 1046576
//根据长度申请buf
buf_t *buf_new_size(int cap){
buf_t *buf = calloc(1, sizeof(buf_t) + cap * sizeof(char));
buf->size = 0;
buf->cap = cap;
return buf;
}
//默认创建出1M大小的buf
buf_t *buf_create(){
return buf_new_size(BUF_CAP_DEFAULT);
}
//内存扩容
void buf_scale_up(buf_t *buf, int cap){
int new_cap = cap << 1;
buf = realloc(buf, sizeof(buf_t) + new_cap * sizeof(char) );
buf->cap = new_cap;
}
//内存缩容
void buf_scale_down(buf_t *buf, int cap){
int new_cap = cap >> 1;
buf = realloc(buf, sizeof(buf_t) + new_cap * sizeof(char) );
buf->cap = new_cap;
}
//往buf中追加数据,如果超出最大容量,自动扩容
void buf_append(buf_t *buf, char *data, int size){
if (buf->size + size > buf->cap) {
buf_scale_up(buf, buf->size + size);
}
memcpy(buf->data + buf->size, data, size);
buf->size += size;
}
//重置buf
void buf_reset(buf_t *buf){
static int reset_times = 0;
if ((buf->size << 1) < buf->cap) {
reset_times++;
}
if (reset_times > 3) {
buf_scale_down(buf, buf->cap);
reset_times = 0;
}
memset(buf->data, 0, buf->size);
buf->size = 0;
}
//销毁buf, 释放内存
void buf_destory(buf_t *buf){
if (buf){
free(buf);
buf = NULL;
}
}
可以看到,除了涉及到内存申请的初始化、扩缩容不太一样之外,其他的实现都是一模一样的。它的调用方式没有发生任何改变:
int main(void){
buf_t *buf = buf_create();
buf_append(buf, "hello", 5);
buf_append(buf, ", world", 7);
printf("buf: %s\n", buf->data);
buf_destory(buf);
return 0;
}
该程序的运行结果:
[root@ck94 0size]# ./buf
buf: hello, world
[root@ck94 0size]# ./buf0
buf: hello, world
本专栏知识点是通过<零声教育>的系统学习,进行梳理总结写下文章,对C/C++课程感兴趣的读者,可以点击链接,查看详细的服务:C/C++Linux服务器开发/高级架构师