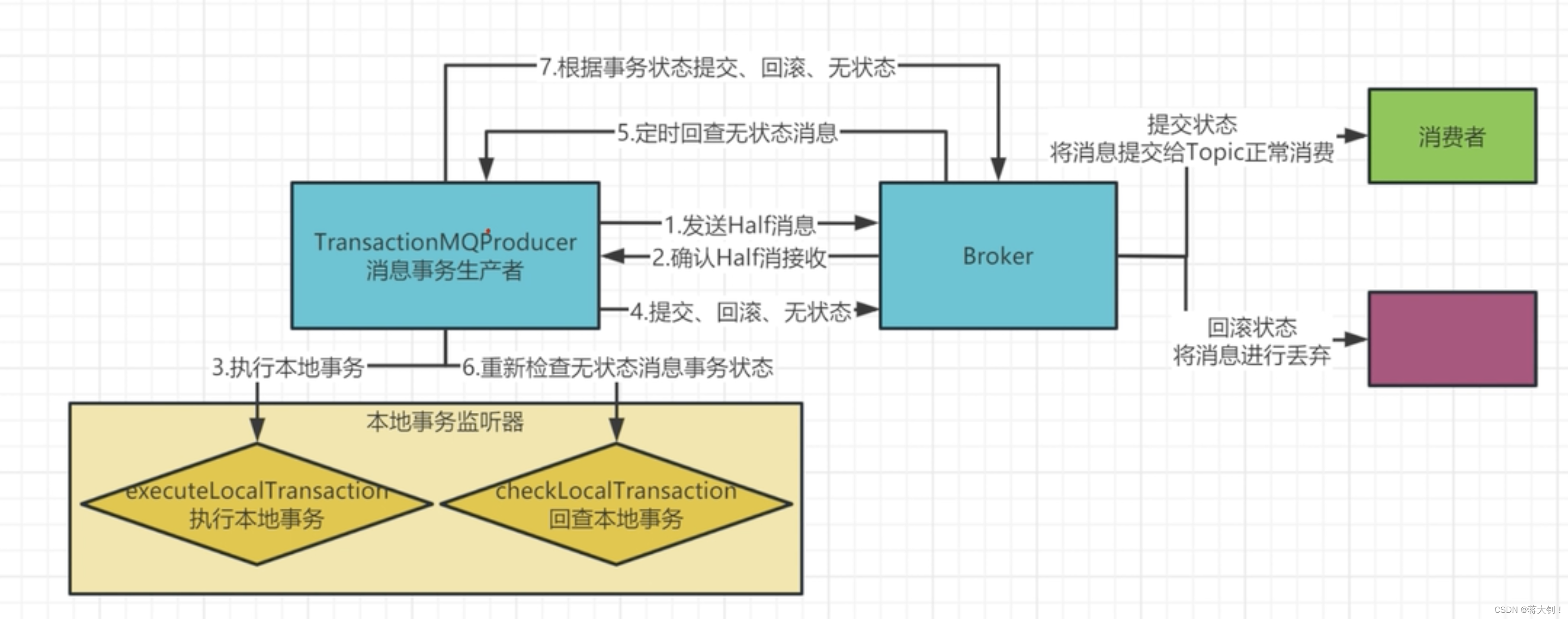
文章目录
- 什么是Starrocks
- 适用场景
- 系统架构
- 产品特性
什么是Starrocks
StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过复杂的预处理,就可以用 StarRocks 来支持多种数据分析场景的极速分析。
StarRocks 架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO (Cost Based Optimizer) 优化器,查询速度(尤其是多表关联查询)远超同类产品。
StarRocks 能很好地支持实时数据分析,并能实现对实时更新数据的高效查询。StarRocks 还支持现代化物化视图,进一步加速查询。
使用 StarRocks,用户可以灵活构建包括大宽表、星型模型、雪花模型在内的各类模型。
StarRocks 兼容 MySQL 协议,支持标准 SQL 语法,易于对接使用,全系统无外部依赖,高可用,易于运维管理。StarRocks 还兼容多种主流 BI 产品,包括 Tableau、Power BI、FineBI 和 Smartbi。
适用场景
StarRocks 可以满足企业级用户的多种分析需求,包括 OLAP (Online Analytical Processing) 多维分析、定制报表、实时数据分析和 Ad-hoc 数据分析等。
- OLAP 多维分析
利用 StarRocks 的 MPP 框架和向量化执行引擎,用户可以灵活的选择雪花模型,星型模型,宽表模型或者预聚合模型。适用于灵活配置的多维分析报表,业务场景包括:-
用户行为分析
-
用户画像、标签分析、圈人
-
高维业务指标报表
-
自助式报表平台
-
业务问题探查分析
-
跨主题业务分析
-
财务报表
-
系统监控分析
-
- 实时数据仓库
StarRocks 设计和实现了 Primary-Key 模型,能够实时更新数据并极速查询,可以秒级同步 TP (Transaction Processing) 数据库的变化,构建实时数仓,业务场景包括:-
电商大促数据分析
-
物流行业的运单分析
-
金融行业绩效分析、指标计算
-
直播质量分析
-
广告投放分析
-
管理驾驶舱
-
探针分析APM(Application Performance Management)
-
- 高并发查询
StarRocks 通过良好的数据分布特性,灵活的索引以及物化视图等特性,可以解决面向用户侧的分析场景,业务场景包括:-
广告主报表分析
-
零售行业渠道人员分析
-
SaaS 行业面向用户分析报表
-
Dashboard 多页面分析
-
- 统一分析
-
通过使用一套系统解决多维分析、高并发查询、预计算、实时分析查询等场景,降低系统复杂度和多技术栈开发与维护成本。
-
使用 StarRocks 统一管理数据湖和数据仓库,将高并发和实时性要求很高的业务放在 StarRocks 中分析,也可以使用 External Catalog 和外部表进行数据湖上的分析。
-
系统架构
StarRocks 架构简洁,整个系统的核心只有 FE(Frontend)、BE(Backend)两类进程,不依赖任何外部组件,方便部署与维护。FE 和 BE 模块都可以在线水平扩展,元数据和业务数据都有副本机制,确保整个系统无单点。StarRocks 提供 MySQL 协议接口,支持标准 SQL 语法。用户可通过 MySQL 客户端方便地查询和分析 StarRocks 中的数据。
- 系统架构图
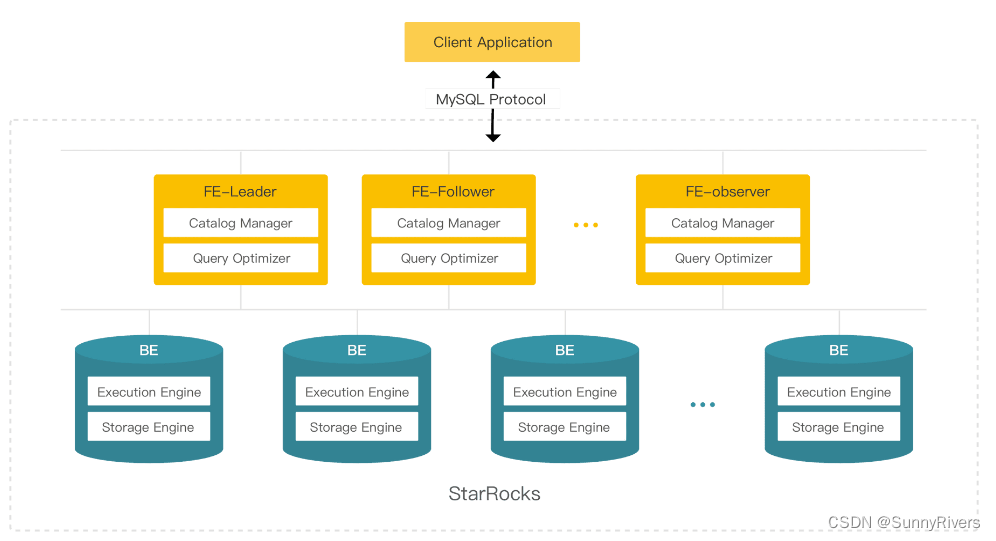
(1)FE
FE 是 StarRocks 的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。每个 FE 节点都会在内存保留一份完整的元数据,这样每个 FE 节点都能够提供无差别的服务。
FE 有三种角色:Leader FE,Follower FE 和 Observer FE。Follower 会通过类 Paxos 的 Berkeley DB Java Edition(BDBJE)协议自动选举出一个 Leader。三者区别如下:
- Leader
(a)Leader 从 Follower 中自动选出,进行选主需要集群中有半数以上的 Follower 节点存活。如果 Leader 节点失败,Follower 会发起新一轮选举。
(b)Leader FE 提供元数据读写服务。只有 Leader 节点会对元数据进行写操作,Follower 和 Observer 只有读取权限。Follower 和 Observer 将元数据写入请求路由到 Leader 节点,Leader 更新完数据后,会通过 BDB JE 同步给 Follower 和 Observer。必须有半数以上的 Follower 节点同步成功才算作元数据写入成功。 - Follower
(a)只有元数据读取权限,无写入权限。通过回放 Leader 的元数据日志来异步同步数据。
(b)参与 Leader 选举,必须有半数以上的 Follower 节点存活才能进行选主。 - Observer
(a)主要用于扩展集群的查询并发能力,可选部署。
(b)不参与选主,不会增加集群的选主压力。
(c)通过回放 Leader 的元数据日志来异步同步数据。
(2)BE
BE 是 StarRocks 的后端节点,负责数据存储、SQL执行等工作。
-
数据存储方面,StarRocks 的 BE 节点都是完全对等的,FE 按照一定策略将数据分配到对应的 BE 节点。BE 负责将导入数据写成对应的格式存储下来,并生成相关索引。
-
在执行 SQL 计算时,一条 SQL 语句首先会按照具体的语义规划成逻辑执行单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在对应的数据存储节点上执行,这样可以实现本地计算,避免数据的传输与拷贝,从而能够得到极致的查询性能。
在进行 Stream load 导入时,FE 会选定一个 BE 节点作为 Coordinator BE,负责将数据分发到其他 BE 节点。导入的最终结果由 Coordinator BE 返回给用户。
- 数据管理
StarRocks 使用列式存储,采用分区分桶机制进行数据管理。一张表可以被划分成多个分区,如将一张表按照时间来进行分区,粒度可以是一天,或者一周等。一个分区内的数据可以根据一列或者多列进行分桶,将数据切分成多个 Tablet。Tablet 是 StarRocks 中最小的数据管理单元。每个 Tablet 都会以多副本 (replica) 的形式存储在不同的 BE 节点中。您可以自行指定 Tablet 的个数和大小。 StarRocks 会管理好每个 Tablet 副本的分布信息。
下图展示了 StarRocks 的数据划分以及 Tablet 多副本机制。图中,表按照日期划分为 4 个分区,第一个分区进一步切分成 4 个 Tablet。每个 Tablet 使用 3 副本进行备份,分布在 3 个不同的 BE 节点上。
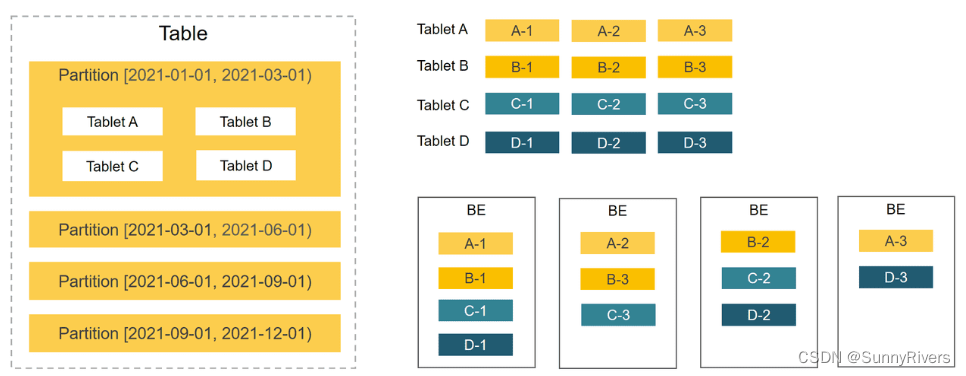
由于一张表被切分成了多个 Tablet,StarRocks 在执行 SQL 语句时,可以对所有 Tablet 实现并发处理,从而充分的利用多机、多核提供的计算能力。用户也可以利用 StarRocks 数据的切分方式,将高并发请求压力分摊到多个物理节点,从而可以通过增加物理节点的方式来扩展系统支持高并发的能力。
Tablet 的分布方式与具体的物理节点没有相关性。在 BE 节点规模发生变化时,比如在扩容、缩容时,StarRocks 可以做到无需停止服务,直接完成节点的增减。节点的变化会触发 Tablet 的自动迁移。当节点增加时,一部分 Tablet 会在后台自动被均衡到新增的节点,从而使得数据能够在集群内分布的更加均衡。在节点减少时,下线机器上的 Tablet 会被自动均衡到其他节点,从而自动保证数据的副本数不变。管理员能够非常容易地实现 StarRocks 的弹性伸缩,无需手工进行任何数据的重分布。
StarRocks 支持 Tablet 多副本存储,默认副本数为三个。多副本能够保证数据存储的高可靠以及服务的高可用。在使用三副本的情况下,一个节点的异常不会影响服务的可用性,集群的读、写服务仍然能够正常进行。另外,增加副本数还有助于提高系统的高并发查询能力。
产品特性
-
MPP 分布式执行框架
StarRocks 采用 MPP (Massively Parallel Processing) 分布式执行框架。在 MPP 执行框架中,一条查询请求会被拆分成多个物理计算单元,在多机并行执行。每个执行节点拥有独享的资源(CPU、内存)。MPP 执行框架能够使得单个查询请求可以充分利用所有执行节点的资源,所以单个查询的性能可以随着集群的水平扩展而不断提升。
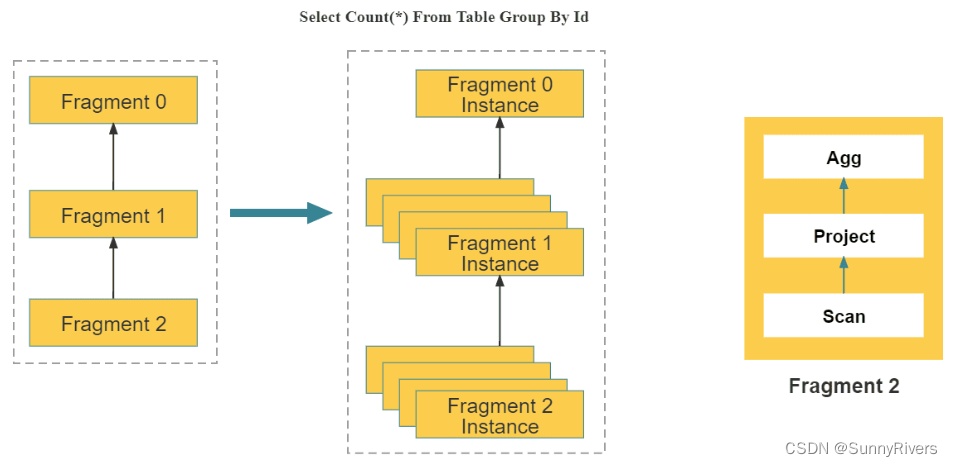
如上图所示,StarRocks 会将一个查询在逻辑上切分为多个逻辑执行单元(Query Fragment)。按照每个逻辑执行单元需要处理的计算量,每个逻辑执行单元会由一个或者多个物理执行单元来具体实现。物理执行单元是最小的调度单位。一个物理执行单元会被调度到集群某个 BE 上执行。一个逻辑执行单元可以包括一个或者多个执行算子,如图中的 Fragment 包括了 Scan,Project,Aggregate。每个物理执行单元只处理部分数据。由于每个逻辑执行单元处理的复杂度不一样,所以每个逻辑执行单元的并行度是不一样的,即,不同逻辑执行单元可以由不同数目的物理执行单元来具体执行,以提高资源使用率,提升查询速度。
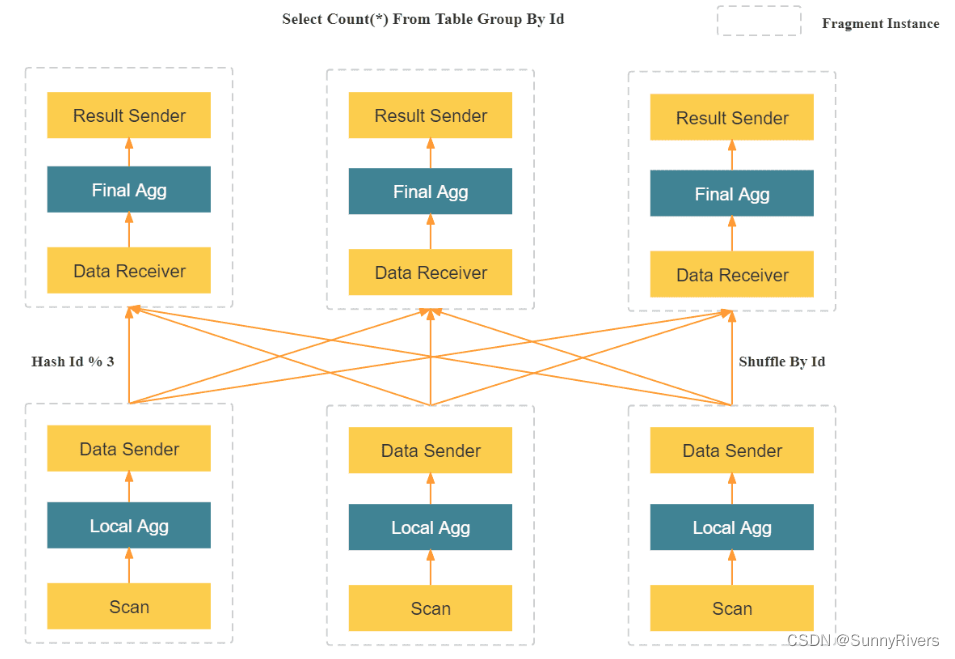
与很多数据分析系统采用的 Scatter-Gather 分布式执行框架不同,MPP分布式执行框架可以利用更多的资源处理查询请求。在 Scatter-Gather 框架中,只有 Gather 节点能处理最后一级的汇总计算。而在 MPP 框架中,数据会被 Shuffle 到多个节点,并且由多个节点来完成最后的汇总计算。在复杂计算时(比如高基数 Group By,大表 Join 等操作),StarRocks 的 MPP 框架相对于 Scatter-Gather 模式的产品有明显的性能优势。 -
全面向量化执行引擎
StarRocks 通过实现全面向量化引擎,充分发挥了 CPU 的处理能力。全面向量化引擎按照列式的方式组织和处理数据。StarRocks 的数据存储、内存中数据的组织方式,以及 SQL 算子的计算方式,都是列式实现的。按列的数据组织也会更加充分的利用 CPU 的 Cache,按列计算会有更少的虚函数调用以及更少的分支判断从而获得更加充分的 CPU 指令流水。
另一方面,StarRocks 的全面向量化引擎通过向量化算法充分的利用 CPU 提供的 SIMD(Single Instruction Multiple Data)指令。这样 StarRocks 可以用更少的指令数目,完成更多的数据操作。经过标准测试集的验证,StarRocks的全面向量化引擎可以将执行算子的性能,整体提升 3~10 倍。
除了使用向量化技术实现所有算子外,StarRocks 还在执行引擎中实现了其他的优化。比如 StarRocks 实现了 Operation on Encoded Data 的技术。对于字符串字段的操作,StarRocks 在无需解码情况下就可以直接基于编码字段完成算子执行,比如实现关联算子、聚合算子、表达式算子计算等。这可以极大的降低 SQL 在执行过程中的计算复杂度。通过这个优化手段,相关查询速度可以提升 2 倍以上。 -
CBO 优化器
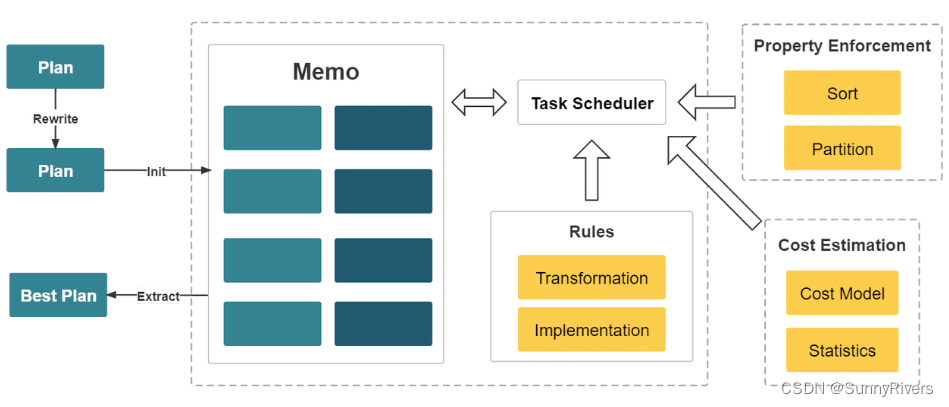
在多表关联查询场景下,仅靠优秀的执行引擎没有办法获得最极致的执行性能。因为这类场景下,不同执行计划的复杂度可能会相差几个数量级。查询中关联表的数目越大,可能的执行计划就越多,在众多的可能中选择一个最优的计划,这是一个 NP-Hard 的问题。只有优秀的查询优化器,才能选择出相对最优的查询计划,从而实现极致的多表分析性能。
StarRocks 从零设计并实现了一款全新的,基于代价的优化器 CBO(Cost Based Optimizer)。该优化器是 Cascades Like 的,在设计时,针对 StarRocks 的全面向量化执行引擎进行了深度定制,并进行了多项优化和创新。该优化器内部实现了公共表达式复用,相关子查询重写,Lateral Join,Join Reorder,Join 分布式执行策略选择,低基数字典优化等重要功能和优化。目前,该优化器已可以完整支持 TPC-DS 99 条 SQL 语句。
由于全新 CBO 的支持,StarRocks 能比同类产品更好地支持多表关联查询,特别是复杂的多表关联查询,让全面向量化引擎能够发挥极致的性能。 -
可实时更新的列式存储引擎
StarRocks 实现了列式存储引擎,数据以按列的方式进行存储。通过这样的方式,相同类型的数据连续存放。一方面,数据可以使用更加高效的编码方式,获得更高的压缩比,降低存储成本。另一方面,也降低了系统读取数据的 I/O 总量,提升了查询性能。此外,在大部分 OLAP 场景中,查询只会涉及部分列。相对于行存,列存只需要读取部分列的数据,能够极大地降低磁盘 I/O 吞吐。
StarRocks 能够支持秒级的导入延迟,提供准实时的服务能力。StarRocks 的存储引擎在数据导入时能够保证每一次操作的 ACID。一个批次的导入数据生效是原子性的,要么全部导入成功,要么全部失败。并发进行的各个事务相互之间互不影响,对外提供 Snapshot Isolation 的事务隔离级别。
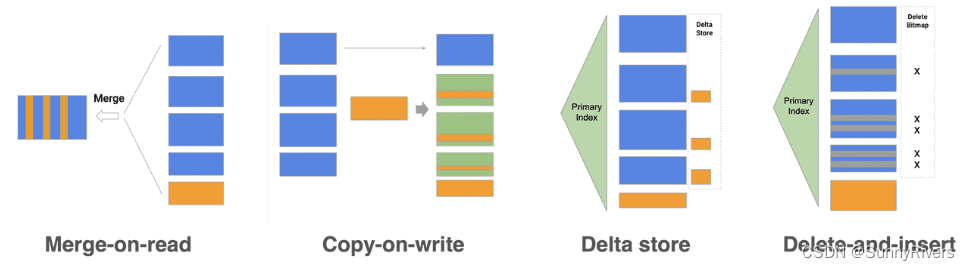
StarRocks 存储引擎不仅能够提供高效的 Partial Update 操作,也能高效处理 Upsert 类操作。使用 Delete-and-insert 的实现方式,通过主键索引快速过滤数据,避免读取时的 Sort 和 Merge 操作,同时还可以充分利用其他二级索引,在大量更新的场景下,仍然可以保证查询的极速性能。 -
智能的物化视图
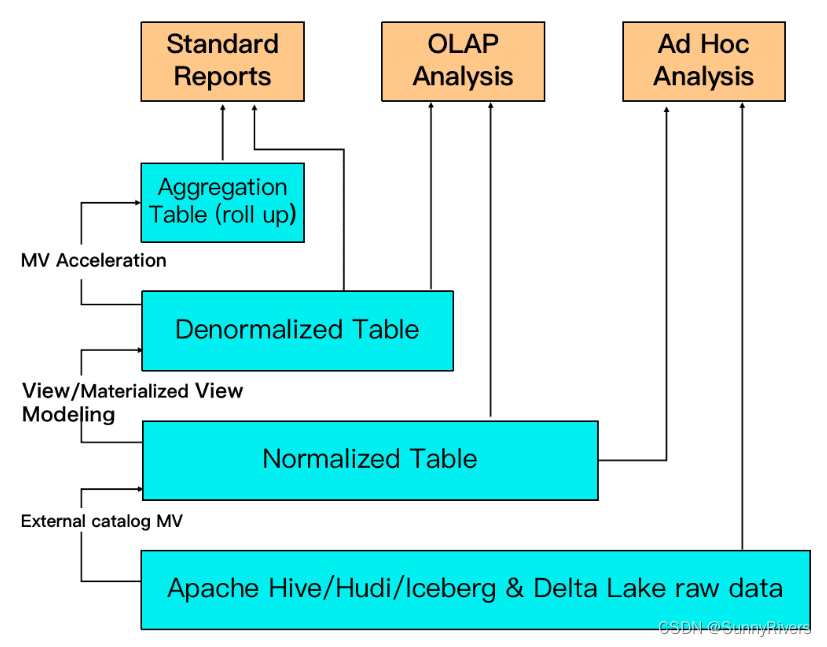
StarRocks 支持用户使用物化视图(materialized view)进行查询加速和数仓分层。不同于一些同类产品的物化视图需要手动和原表做数据同步,StarRocks 的物化视图可以自动根据原始表更新数据。只要原始表数据发生变更,物化视图的更新也同步完成,不需要额外的维护操作就可以保证物化视图能够维持与原表一致。不仅如此,物化视图的选择也是自动进行的。StarRocks 在进行查询规划时,如果有合适的物化视图能够加速查询,StarRocks 自动进行查询改写(query rewrite),将查询自动定位到最适合的物化视图上进行查询加速。
StarRocks 的物化视图可以按需灵活创建和删除。用户可以在使用过程中视实际使用情况来判断是否需要创建或删除物化视图。StarRocks 会在后台自动完成物化视图的相关调整。
StarRocks 的物化视图可以替代传统的 ETL 建模流程,用户无需在上游应用处做数据转换,可以在使用物化视图时完成数据转换,简化了数据处理流程。
例如图中,最底层 ODS 的湖上数据可以通过 External Catalog MV 来构建 DWD 层的 normalized table;并且可以通过多表关联的物化视图来构建 DWS 层的宽表 (denormalized table);最上层可以进一步构建实时的物化视图来支撑高并发的查询,提供更加优异的查询性能。 -
数据湖分析
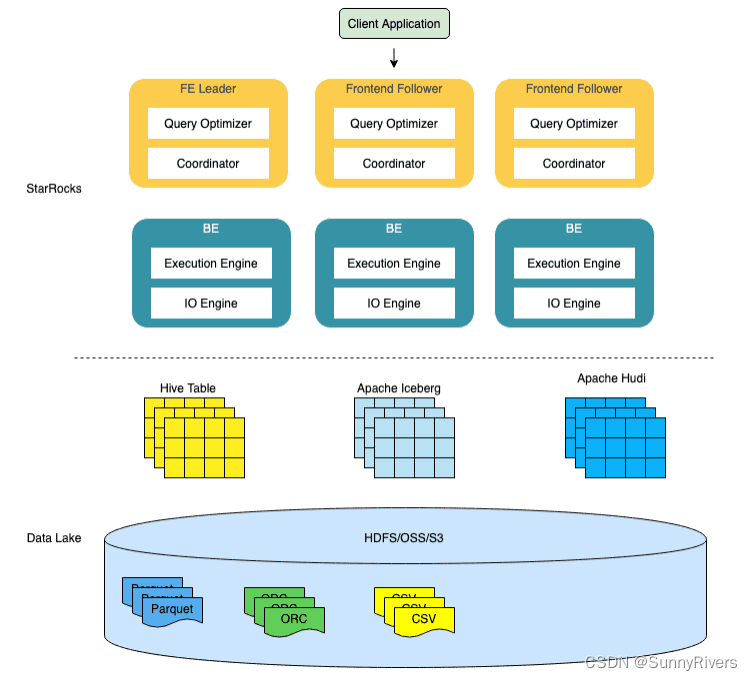
StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Apache Hive、Apache Iceberg、Apache Hudi、Delta Lake 等数据湖上的数据,无需进行数据迁移。支持的存储系统包括 HDFS、S3、OSS,支持的文件格式包括 Parquet、ORC、CSV。
如上图所示,在数据湖分析场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。使用数据湖的优势在于可以使用开放的存储格式和灵活多变的 schema 定义方式,可以让 BI/AI/Adhoc/报表等业务有统一的 single source of truth。而 StarRocks 作为数据湖的计算引擎,可以充分发挥向量化引擎和 CBO 的优势,大大提升了数据湖分析的性能。