Triton教程 —Triton架构

文章目录
- Triton教程 ---Triton架构
- 并发模型执行
- 模型和调度器
- 无状态模型
- 状态模型
- 控制输入
- 隐式状态管理
- 状态初始化
- 调度策略
- 直接的
- Oldest
- 合奏模型
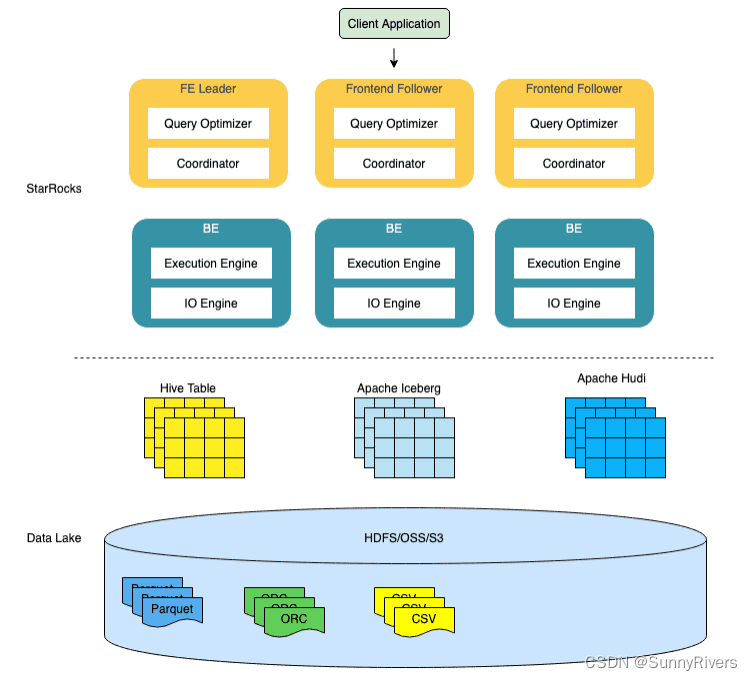
下图显示了 Triton 推理服务器的高级架构。 模型存储库是一个基于文件系统的模型存储库,Triton 将使其可用于推理。 推理请求通过 HTTP/REST 或 GRPC 或 C API 到达服务器,然后路由到适当的每个模型调度程序。 Triton 实现了多种调度和批处理算法,可以在逐个模型的基础上进行配置。 每个模型的调度器可选择执行推理请求的批处理,然后将请求传递给与模型类型对应的后端。 后端使用批处理请求中提供的输入执行推理以生成请求的输出。 然后返回输出。
Triton 支持后端 C API,允许 Triton 扩展新功能,例如自定义预处理和后处理操作,甚至是新的深度学习框架。
Triton 提供的模型可以通过专用模型管理 API 查询和控制,该 API 可通过 HTTP/REST 或 GRPC 协议或 C API 获得。
就绪性和活性健康端点和利用率、吞吐量和延迟指标简化了 Triton 与部署框架(如 Kubernetes)的集成。

并发模型执行
Triton 架构允许多个模型或同一模型的多个实例在同一系统上并行执行。 系统可能有零个、一个或多个 GPU。 下图显示了具有两个模型的示例; 模型 0 和模型 1。 假设 Triton 当前没有处理任何请求,当两个请求同时到达时,每个模型一个,Triton 立即将它们都调度到 GPU 上,GPU 的硬件调度程序开始并行处理这两个计算。 在系统 CPU 上执行的模型由 Triton 类似地处理,除了 CPU 线程执行每个模型的调度由系统的操作系统处理。

默认情况下,如果同一模型的多个请求同时到达,Triton 将通过在 GPU 上一次只调度一个来序列化它们的执行,如下图所示。

Triton 提供了一个名为 instance-group 的模型配置选项,它允许每个模型指定应该允许该模型并行执行的次数。 每个这样启用的并行执行都称为一个实例。 默认情况下,Triton 为系统中每个可用的 GPU 为每个模型提供一个实例。 通过使用模型配置中的 instance_group 字段,可以更改模型的执行实例数。 下图显示了当 model1 配置为允许三个实例时的模型执行。 如图所示,前三个 model1 推理请求立即并行执行。 第四个 model1 推理请求必须等到前三个执行中的一个执行完成才能开始。

模型和调度器
Triton 支持多种调度和批处理算法,可以为每个模型独立选择。 本节介绍无状态、有状态和集成模型,以及 Triton 如何提供调度程序来支持这些模型类型。 对于给定的模型,调度程序的选择和配置是通过模型的配置文件完成的。
无状态模型
关于 Triton 的调度程序,无状态模型不会在推理请求之间维护状态。 在无状态模型上执行的每个推理都独立于使用该模型的所有其他推理。
无状态模型的示例是 CNN,例如图像分类和对象检测。 默认调度程序或动态批处理程序可用作这些无状态模型的调度程序。
RNN 和具有内部存储器的类似模型可以是无状态的,只要它们维护的状态不跨越推理请求。 例如,如果推理请求的批次之间未携带内部状态,则 Triton 认为迭代批次中所有元素的 RNN 是无状态的。 默认调度程序可用于这些无状态模型。 不能使用动态批处理程序,因为模型通常不希望批处理代表多个推理请求。
状态模型
关于 Triton 的调度程序,有状态模型确实会在推理请求之间维护状态。 该模型需要多个推理请求,这些请求一起形成一系列推理,这些推理必须路由到同一模型实例,以便模型维护的状态得到正确更新。 此外,该模型可能要求 Triton 提供控制信号,例如指示序列的开始和结束。
序列批处理程序必须用于这些有状态模型。 如下所述,序列批处理程序可确保将序列中的所有推理请求路由到同一模型实例,以便模型可以正确维护状态。 序列批处理程序还与模型通信以指示序列何时开始、序列何时结束、序列何时具有准备好执行的推理请求以及序列的相关 ID。
在对有状态模型发出推理请求时,客户端应用程序必须为序列中的所有请求提供相同的关联 ID,并且还必须标记序列的开始和结束。 关联 ID 允许 Triton 识别请求属于同一序列。
控制输入
为了使有状态模型与序列批处理程序一起正确运行,模型通常必须接受一个或多个 Triton 用来与模型通信的控制输入张量。 模型配置的 ModelSequenceBatching::Control 部分指示模型如何公开序列批处理程序应该用于这些控件的张量。 所有控件都是可选的。 下面是模型配置的一部分,显示了所有可用控制信号的示例配置。
sequence_batching {
control_input [
{
name: "START"
control [
{
kind: CONTROL_SEQUENCE_START
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "END"
control [
{
kind: CONTROL_SEQUENCE_END
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "READY"
control [
{
kind: CONTROL_SEQUENCE_READY
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "CORRID"
control [
{
kind: CONTROL_SEQUENCE_CORRID
data_type: TYPE_UINT64
}
]
}
]
}
-
Start:开始输入张量在配置中使用 CONTROL_SEQUENCE_START 指定。 示例配置表明模型有一个名为 START 的输入张量,其数据类型为 32 位浮点数。 序列批处理程序将在对模型执行推理时定义此张量。 START 张量必须是一维的,大小等于批量大小。 张量中的每个元素指示相应批槽中的序列是否开始。 在示例配置中,fp32_false_true 表示序列开始由张量元素等于 1 表示,非开始由张量元素等于 0 表示。
-
End:结束输入张量在配置中使用 CONTROL_SEQUENCE_END 指定。 示例配置表明模型有一个名为 END 的输入张量,具有 32 位浮点数据类型。 序列批处理程序将在对模型执行推理时定义此张量。 END 张量必须是一维的,大小等于批量大小。 张量中的每个元素指示相应批槽中的序列是否结束。 在示例配置中,fp32_false_true表示一个序列结束由张量元素等于1表示,非结束由张量元素等于0表示。
-
Ready:就绪输入张量在配置中使用 CONTROL_SEQUENCE_READY 指定。 示例配置表明模型有一个名为 READY 的输入张量,其数据类型为 32 位浮点数。 序列批处理程序将在对模型执行推理时定义此张量。 READY 张量必须是一维的,其大小等于批量大小。 张量中的每个元素指示相应批槽中的序列是否具有准备好进行推理的推理请求。 在示例配置中,fp32_false_true 表示序列就绪由张量元素等于 1 表示,非就绪由张量元素等于 0 表示。
-
Correlation ID:关联 ID 输入张量在配置中使用 CONTROL_SEQUENCE_CORRID 指定。 示例配置表明模型有一个名为 CORRID 的输入张量,其数据类型为无符号 64 位整数。 序列批处理程序将在对模型执行推理时定义此张量。 CORRID 张量必须是一维的,大小等于批量大小。 张量中的每个元素表示相应批槽中序列的相关 ID。
隐式状态管理
隐式状态管理允许有状态模型将其状态存储在 Triton 中。 当使用隐式状态时,有状态模型不需要在模型内部存储推理所需的状态。
下面是模型配置的一部分,表明模型正在使用隐式状态。
sequence_batching {
state [
{
input_name: "INPUT_STATE"
output_name: "OUTPUT_STATE"
data_type: TYPE_INT32
dims: [ -1 ]
}
]
}
sequence_batching 设置中的状态部分用于指示模型正在使用隐式状态。 input_name 字段指定将包含输入状态的输入张量的名称。 output_name 字段描述了包含输出状态的模型产生的输出张量的名称。 模型在序列中第 i 个请求中提供的输出状态将用作第 i+1 个请求中的输入状态。 dims 字段指定状态张量的维度。 当 dims 字段包含可变大小的维度时,输入状态和输出状态的形状不必匹配。
出于调试目的,客户端可以请求输出状态。 为了允许客户端请求输出状态,模型配置的输出部分必须将输出状态列为模型输出之一。 请注意,由于必须传输额外的张量,从客户端请求输出状态可能会增加请求延迟。
隐式状态管理需要后端支持。 目前只有 onnxruntime_backend 和 tensorrt_backend 支持隐式状态。
状态初始化
默认情况下,序列中的起始请求包含输入状态的未初始化数据。 模型可以使用请求中的开始标志来检测新序列的开始,并通过在模型输出中提供初始状态来初始化模型状态。 如果模型状态描述中的 dims 部分包含可变大小的维度,Triton 将为每个可变大小的维度使用 1 来启动请求。 对于序列中的其他非启动请求,输入状态是序列中前一个请求的输出状态。 对于使用隐式状态的示例 ONNX 模型,您可以参考此生成脚本中的 create_onnx_modelfile_wo_initial_state() 生成的 onnx 模型。 这是一个简单的累加器模型,它使用隐式状态将请求的部分总和存储在 Triton 的序列中。 对于状态初始化,如果请求正在启动,模型会将“OUTPUT_STATE”设置为等于“INPUT”张量。 对于非启动请求,它将“OUTPUT_STATE”张量设置为“INPUT”和“INPUT_STATE”张量之和。
除了上面讨论的默认状态初始化之外,Triton 还提供了另外两种初始化状态的机制。
从零初始化状态。
下面是一个从零开始初始化状态的例子。
sequence_batching {
state [
{
input_name: "INPUT_STATE"
output_name: "OUTPUT_STATE"
data_type: TYPE_INT32
dims: [ -1 ]
initial_state: {
data_type: TYPE_INT32
dims: [ 1 ]
zero_data: true
name: "initial state"
}
}
]
}
请注意,在上面的示例中,状态描述中的可变维度被转换为固定大小的维度。
从文件初始化状态
为了从文件初始化状态,您需要在模型目录下创建一个名为“initial_state”的目录。 需要在 data_file 字段中提供该目录下包含初始状态的文件。 存储在该文件中的数据将以行优先顺序用作初始状态。 下面是一个从文件初始化状态的示例状态描述。
sequence_batching {
state [
{
input_name: "INPUT_STATE"
output_name: "OUTPUT_STATE"
data_type: TYPE_INT32
dims: [ -1 ]
initial_state: {
data_type: TYPE_INT32
dims: [ 1 ]
data_file: "initial_state_data"
name: "initial state"
}
}
]
}
调度策略
在决定如何对路由到同一模型实例的序列进行批处理时,序列批处理程序可以采用两种调度策略之一。 这些策略是直接且最古老的。
直接的
使用直接调度策略,序列批处理程序不仅确保序列中的所有推理请求都被路由到同一模型实例,而且每个序列都被路由到模型实例中的专用批处理槽。 当模型维护每个批处理槽的状态并期望将给定序列的所有推理请求路由到同一槽以便正确更新状态时,需要此策略。
作为使用直接调度策略的序列批处理程序的示例,假设一个 TensorRT 有状态模型具有以下模型配置。
name: "direct_stateful_model"
platform: "tensorrt_plan"
max_batch_size: 2
sequence_batching {
max_sequence_idle_microseconds: 5000000
direct { }
control_input [
{
name: "START"
control [
{
kind: CONTROL_SEQUENCE_START
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "READY"
control [
{
kind: CONTROL_SEQUENCE_READY
fp32_false_true: [ 0, 1 ]
}
]
}
]
}
input [
{
name: "INPUT"
data_type: TYPE_FP32
dims: [ 100, 100 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 10 ]
}
]
instance_group [
{
count: 2
}
]
sequence_batching 部分指示模型应使用序列批处理程序和直接调度策略。 在此示例中,模型仅需要来自序列批处理程序的启动和就绪控制输入,因此仅列出这些控制。 instance_group 表示应该实例化模型的两个实例,max_batch_size 表示每个实例都应该执行批量大小为 2 的推理。 下图显示了序列批处理程序和此配置指定的推理资源的表示。

每个模型实例都维护每个批处理槽的状态,并期望将给定序列的所有推理请求路由到同一个槽,以便正确更新状态。 对于这个例子,这意味着 Triton 最多可以同时对四个序列进行推理。
使用直接调度策略,序列批处理程序:
-
识别推理请求何时开始新序列并为该序列分配批处理槽。 如果没有可用于新序列的批处理槽,Triton 会将推理请求放入待办事项列表中。
-
识别推理请求何时是具有分配的批处理槽的序列的一部分,并将请求路由到该槽。
-
识别推理请求何时是积压中序列的一部分,并将请求放入积压中。
-
识别序列中的最后一个推理请求何时完成。 该序列占用的批处理槽会立即重新分配给积压中的序列,或者如果没有积压,则为未来的序列释放。
下图显示了如何使用直接调度策略将多个序列调度到模型实例上。 左图显示了到达 Triton 的几个请求序列。 每个序列可以由任意数量的推理请求组成,并且这些单独的推理请求可以相对于其他序列中的推理请求以任何顺序到达,除了右侧显示的执行顺序假定序列 0 的第一个推理请求到达之前 序列 1-5 中的任何推理请求,序列 1 的第一个推理请求在序列 2-5 中的任何推理请求之前到达,依此类推。
该图的右侧显示了推理请求序列如何随着时间的推移被调度到模型实例上。

下图显示了序列批处理程序使用控制输入张量与模型进行通信。 该图显示了分配给模型实例中两个批槽的两个序列。 每个序列的推理请求随时间到达。 START 和 READY 行显示用于模型每次执行的输入张量值。 随着时间的推移,会发生以下情况:
-
第一个请求到达 slot0 中的序列。 假设模型实例尚未执行推理,序列调度程序会立即调度模型实例执行,因为推理请求可用。
-
这是序列中的第一个请求,因此 START 张量中的相应元素设置为 1。slot1 中没有可用请求,因此 READY 张量仅显示 slot0 就绪。
-
推理完成后,序列调度程序发现任何批处理槽中都没有可用请求,因此模型实例处于空闲状态。
-
接下来,两个推理请求及时到达,以便序列调度程序看到它们在各自的批处理槽中都可用。 调度程序立即安排模型实例执行批量大小为 2 的推理,并使用 START 和 READY 来表明两个槽都有可用的推理请求,但只有槽 1 是新序列的开始。
-
对于其他推理请求,处理以类似的方式继续。

Oldest
使用 Oldest 调度策略,序列批处理程序确保序列中的所有推理请求都被路由到相同的模型实例,然后使用动态批处理程序将来自不同序列的多个推理一起批处理成一起推理的批处理。 使用此策略,模型通常必须使用 CONTROL_SEQUENCE_CORRID 控件,以便它知道批处理中的每个推理请求属于哪个序列。 通常不需要 CONTROL_SEQUENCE_READY 控件,因为批处理中的所有推理将始终准备好进行推理。
作为使用Oldest调度策略的序列批处理程序的示例,假设有一个具有以下模型配置的有状态模型:
name: "oldest_stateful_model"
platform: "tensorflow_savedmodel"
max_batch_size: 2
sequence_batching {
max_sequence_idle_microseconds: 5000000
oldest
{
max_candidate_sequences: 4
}
control_input [
{
name: "START"
control [
{
kind: CONTROL_SEQUENCE_START
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "END"
control [
{
kind: CONTROL_SEQUENCE_END
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "CORRID"
control [
{
kind: CONTROL_SEQUENCE_CORRID
data_type: TYPE_UINT64
}
]
}
]
}
input [
{
name: "INPUT"
data_type: TYPE_FP32
dims: [ 100, 100 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 10 ]
}
]
sequence_batching 部分指示模型应使用序列批处理程序和最旧的调度策略。 配置 Oldest 策略,以便序列批处理程序最多保留 4 个活动候选序列,它更愿意从中形成大小为 2 的动态批处理。在此示例中,模型需要来自序列批处理程序的开始、结束和相关 ID 控制输入。 下图显示了序列批处理程序和此配置指定的推理资源的表示。

使用 Oldest 调度策略,序列批处理程序:
-
识别推理请求何时启动新序列并尝试查找具有候选序列空间的模型实例。 如果没有模型实例有空间容纳新的候选序列,Triton 会将推理请求放入待办事项列表中。
-
识别推理请求何时是某个模型实例中已经是候选序列的序列的一部分,并将请求路由到该模型实例。
-
识别推理请求何时是积压中序列的一部分,并将请求放入积压中。
-
识别序列中的最后一个推理请求何时完成。 模型实例立即从backlog中移除一个序列,使其成为模型实例中的候选序列,或者如果没有backlog,则记录该模型实例可以处理未来的序列。
下图显示了如何将多个序列调度到上述示例配置指定的模型实例上。 左图显示了到达 Triton 的四个请求序列。 如图所示,每个序列由多个推理请求组成。 图的中心显示了推理请求序列如何随时间批处理到模型实例上,假设每个序列的推理请求以相同的速率到达,序列 A 刚好在 B 之前到达,而序列 A 刚好在 C 之前到达,等等。 最旧策略根据最旧的请求形成一个动态批次,但从不在批次中包含来自给定序列的多个请求(例如,序列 D 中的最后两个推理不会一起批处理)。

合奏模型
集成模型表示一个或多个模型的管道以及这些模型之间输入和输出张量的连接。 集成模型旨在用于封装涉及多个模型的过程,例如“数据预处理 -> 推理 -> 数据后处理”。 为此目的使用集成模型可以避免传输中间张量的开销,并最大限度地减少必须发送给 Triton 的请求数量。
集成调度程序必须用于集成模型,无论集成中的模型使用的调度程序如何。 关于集成调度器,集成模型不是实际模型。 相反,它将集合中模型之间的数据流指定为模型配置中的 ModelEnsembling::Step 条目。 调度器收集每个步骤的输出张量,根据规范将它们作为输入张量提供给其他步骤。 尽管如此,从外部来看,集成模型仍然被视为单个模型。
请注意,集成模型将继承所涉及模型的特征,因此请求标头中的元数据必须符合集成内的模型。 例如,如果其中一个模型是有状态模型,那么集成模型的推理请求应该包含有状态模型中提到的信息,这些信息将由调度程序提供给有状态模型。
例如,考虑一个用于图像分类和分割的集成模型,它具有以下模型配置:
name: "ensemble_model"
platform: "ensemble"
max_batch_size: 1
input [
{
name: "IMAGE"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "CLASSIFICATION"
data_type: TYPE_FP32
dims: [ 1000 ]
},
{
name: "SEGMENTATION"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
ensemble_scheduling {
step [
{
model_name: "image_preprocess_model"
model_version: -1
input_map {
key: "RAW_IMAGE"
value: "IMAGE"
}
output_map {
key: "PREPROCESSED_OUTPUT"
value: "preprocessed_image"
}
},
{
model_name: "classification_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "CLASSIFICATION_OUTPUT"
value: "CLASSIFICATION"
}
},
{
model_name: "segmentation_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "SEGMENTATION_OUTPUT"
value: "SEGMENTATION"
}
}
]
}
ensemble_scheduling 部分表明将使用集成调度器,集成模型由三个不同的模型组成。 步骤部分中的每个元素指定要使用的模型以及模型的输入和输出如何映射到调度程序识别的张量名称。 例如,step中的第一个元素指定应使用最新版本的image_preprocess_model,其输入“RAW_IMAGE”的内容由“IMAGE”张量提供,其输出“PREPROCESSED_OUTPUT”的内容将映射到“preprocessed_image” ”张量供以后使用。 调度程序识别的张量名称是合奏输入、合奏输出以及 input_map 和 output_map 中的所有值。
构成集成的模型也可能启用了动态批处理。 由于集成模型只是在组合模型之间路由数据,Triton 可以在不修改集成配置的情况下将请求带入集成模型,以利用组合模型的动态批处理。
假设只提供集成模型、预处理模型、分类模型和分割模型,客户端应用程序会将它们视为可以独立处理请求的四个不同模型。 但是,集成调度程序将如下所示查看集成模型。

当收到集成模型的推理请求时,集成调度程序将:
-
认识到请求中的“IMAGE”张量映射到预处理模型中的输入“RAW_IMAGE”。
-
检查集成中的模型并向预处理模型发送内部请求,因为所需的所有输入张量都已准备就绪。
-
识别内部请求的完成,收集输出张量并将内容映射到“preprocessed_image”,这是集成中已知的唯一名称。
-
将新收集的张量映射到集合中模型的输入。 在这种情况下,“classification_model”和“segmentation_model”的输入将被映射并标记为就绪。
-
检查需要新收集的张量的模型,并将内部请求发送到输入准备就绪的模型,在这种情况下是分类模型和分割模型。 请注意,响应将按任意顺序排列,具体取决于各个模型的负载和计算时间。
-
重复步骤 3-5 直到不再发送内部请求,然后使用映射到集成输出名称的张量响应推理请求。