Hive
概述
Hive是一个基于Hadoop的数据仓库系统,它提供了类似与SQL的查询语言HiveQL,可以将结构化数据存储在Hadoop分布式文件系统中,并通过MapReduce进行过处理。
Hive的目标是使数据分析师和其他人员能够使用SQL语言来查询大规模的数据集,而无需编写MapReduce程序。将结构化数据映射到Hadoop的分布式文件系统(HDFS)上,并提供了一个高层次的抽象层,使得用户可以使用类似于SQL的查询语言来查询和分析数据。
Hive还提供了一些内置函数和UDF(用户定义函数),可以扩展其功能,Hive是开源的,由Apache软件基金会进行维护。
好处
- 易于使用
- Hive使用类似于SQL的查询语言,这使得用户可以快速上手并开始查询和分析数据
- 处理大规模数据
- Hive可以处理大规模的数据,因为它是基于Hadoop的分布式文件系统(HDFS)构建的
- 可扩展性
- Hive可以轻松地扩展到处理更大规模地数据,因为它可以在Hadoop集群上运行
- 数据仓库
- Hive可以将结构化数据映射到Hadoop的分布式文件系统(HDFS)上,从而创建一个数据仓库,使得用户可以轻松地查询和分析数据。
- 开源
- Hive是一个开源项目,因此用户可以自由地使用和修改它,以满足他们的需求。
架构原理
- 元数据存储
- Hive的元数据存储在关系型数据库中,例如MySQL。元数据包括表的结构、分区、列和分布式文件系统中数据的位置等信息。
- 查询编译器
- Hive的查询编译器将HiveQL语句转换为MapReduce任务,这些任务将在Hadoop集群上执行。查询编译器还可以优化查询以提高性能。
- 执行引擎
- Hive的执行引擎负责执行MapReduce任务,并将结果返回给用户。执行引擎还可以处理数据的分区和排序等操作。
- 存储处理
- Hive支持多种数据存储格式,包括文本、序列化、ORC和Parquet等。存储处理模块负责将数据存储在HDFS中,并提供对数据的读写操作。
- 用户接口
- Hive提供了多种用户接口,包括命令行界面、Web界面和ODBC/JDBC接口等。用户可以使用这些接口来执行HiveQL查询和管理Hive元数据。
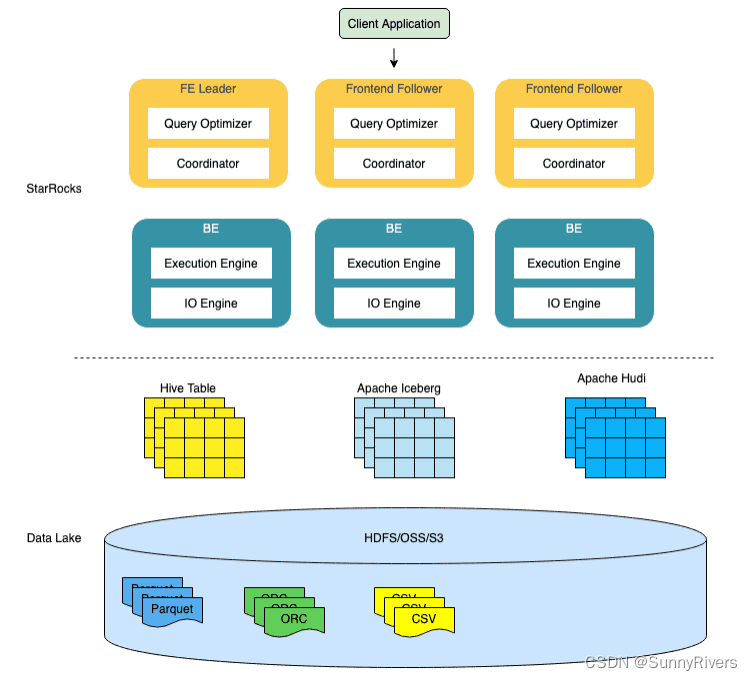
了解Hive系统架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ARtWX2NG-1686788415354)(E:\Java笔记\大数据\Hadoop\Hive\Hive\Hive.assets\image-20230613090335227.png)]](https://img-blog.csdnimg.cn/9e1d729eba34424c8bc2ac9f482e8373.png)
Hive是一个基于Hadoop的数据仓库工具,它提供了一个种类SQL的查询语言,使得用户可以方便地使用Hadoop进行数据分析和处理,
Hive的系统架构如下:
- 用户接口层
- Hive提供了CLI(命令行界面)和JDBC/ODBC接口,使得用户可以通过命令或者其他工具来执行Hive查询
- 元数据层
- Hive的元数据存储在关系型数据库中,包括表的结构、分区信息、表的位置等。
- 驱动层
- Hive的驱动程序负责解析用户的查询语句,生成执行计划,并将计划提交给执行引擎。
- 执行引擎层
- Hive的执行引擎负责执行查询计划,包括MapReduce,Tez,Spark等。
- 存储层
- Hive支持多种存储格式,包括文本、序列化、ORC等。
- Hadoop层
- Hive运行在Hadoop上,利用Hadoop的分布式计算能力来处理大规模数据。
了解Hive数据模型
Hive是一个基于Hadoop的数据仓库工具,它提供了一种类似SQL的查询语言,称之为HiveQL,用于查询和分析大规模的数据集。Hive的数据模型是基于表的,类似于关系行数据库的数据模型,但是它是基于Hadoop分布式文件系统(HDFS)存储的
Hive中的数据模型包括一下几个方面:
- 数据库
- Hive中的数据库类似于关系型数据库中的数据库,用于组织和管理表。一个Hive实例可以包含多个数据库,每个数据库可以包含多个表。
- 表
- Hive中的表类似于关系型数据库中的表,用于存储数据。每个表都有一个名称和一组列,每个列都有一个名称和一个数据类型。表可以分区和分桶,以提高查询性能。
- 分区
- Hive中的分区是指将表按照某个列的值进行划分,以便更快地查询数据。例如,可以将一张表按照日期列进行分区,每个分区对应一个日期值。
- 分桶
- Hive中的分桶是指将表按照某个列的哈希值进行划分,以便更快地查询数据。分桶可以在分区的基础上使用,以进一步提高查询性能。
- 视图
- Hive中的视图类似于关系型数据库中的视图,用于简化复杂的查询。视图是基于一个或多个表的查询结果,可以像表一样使用。
总的来说,Hive的数据模型是基于表的,但是它也支持分区、分桶和视图等高级特性,以提高查询性能和简化查询语句。
应用场景
- 大数据分析:
- Hive可以处理PB级别的数据,适用于大数据分析场景,可以通过Hive SQL语句进行数据查询、过滤、聚合等操作。
- 数据仓库
- Hive可以将结构化的数据映射为一张数据库表,可以将多个数据源的数据整合到一个数据仓库中,方便数据分析和管理。
- 数据ETL
- Hive可以通过HiveQL语句进行数据抽取、转换和加载,支持多种数据格式,如CSV、JSON、Parquet等。
- 数据可视化
- Hive可以将查询结果导出为CSV、JSON等格式,方便数据可视化工具进行数据展示和分析。
总之,Hive适用于大数据分析、数据仓库、数据ETL等场景,可以帮助企业快速处理大规模的数据,并提供类SQL的查询和分析能力。
Hive与传统数据库的对比
Hive是一个基于Hadoop的数据仓库工具,它使用类SQL语言(HiveQL)来查询和分析大规模数据集。相比传统数据库,Hive有以下几个不同点:
- 数据库存储方式:
- 传统数据库使用关系型模型,将数据存储在表格中,而Hive使用分布式文件系统(如HDFS)来存储数据,数据以文件的形式存储在分布式文件系统中。
- 数据处理方式:
- 传统数据库使用事务来保证数据的一致性和完整性,而Hive使用MapReduce来处理数据,这种方式可以处理大规模数据集,但是对于实时性要求高的场景不太适用。
- 查询语言:
- 传统数据库使用SQL语言来查询数据,而Hive使用HiveQL语言,它是类SQL语言,但是与传统SQL语言有一些不同。
- 数据规模:
- 传统数据库适用于小规模数据集,而Hive适用于大规模数据集,可以处理PB级别的数据。
总的来说,Hive适用于大规模数据集的处理和分析,而传统数据库适用于小规模数据集的存储和查询。