写在前面
随着滴滴内部技术栈的不断统一,实时相关技术组件资源的不断整合,各业务线实时数据相关开发经验的不断沉淀,基本形成了一套面向公司不同业务场景需求的最佳技术选型和具体落地方案。但同时我们也发现,大部分实时开发同学在做实时数据建设过程中会笼统的把实时数据建设等同于 flink 数据开发,常常把实时数据处理过程中的其他相关组件放在边缘位置,无法高效的整合数据处理组件来完成不同业务场景的实时需求。为此,我们从当前公司内的典型实时数据开发方案出发,整理了不同场景下的实时数据建设技术选型,帮助大家更好的进行实时数据建设,为业务持续输出高质量且稳定的实时数据价值。
本篇文章分为:
1. 实时数据开发在公司内的主要业务场景
2. 实时数据开发在公司内的通用方案
数据源
数据通道
同步中心
实时开发平台
数据集
实时数据应用
3. 特定场景下的实时数据开发组件选型
实时指标监控场景
实时 BI 分析场景
实时数据在线服务场景
实时特征和标签系
4. 各组件资源使用原则
5. 总结和展望
1. 实时数据开发在公司内的主要业务场景
目前公司内各业务线使用实时数据的主要场景分为四块:
实时指标监控:例如产研侧指标稳定性监控,业务侧实时指标异常波动监控,运营大盘业务健康度监控等。这类场景的主要特点是对数据及时性要求很高,且高度依赖时间序列,主要依赖时间轴作为分析度量,数据分析复杂度一般。
实时BI分析:主要面向数据分析师和运营同学配置实时看板或者实时报表,包括公司运营大盘、实时核心看板,展厅实时大屏等。这类场景的主要特点是对数据准确性要求极高,对数据及时性容许有一定延迟,需要支持较复杂的数据分析能力。
实时数据在线服务:主要以 API 接口的方式提供实时指标,多用于为数据产品提供实时数据。这类场景对数据及时性和准确性要求较高,指标计算复杂度一般,对接口查询QPS 要求非常高,在提供实时数据的同时需要保证整个服务的高可用。
实时特征:主要用于机器学习模型更新、推荐预测、推荐策略、标签系统等方面。这类场景对数据及时性、准确性、查询 QPS 要求一般,但其本身实现逻辑对实时计算引擎的使用要求较高,要求实时计算引擎有较强的实时数据处理能力,较强的状态存储能力,较丰富的外部组件对接能力。
2. 实时数据开发在公司内的通用方案
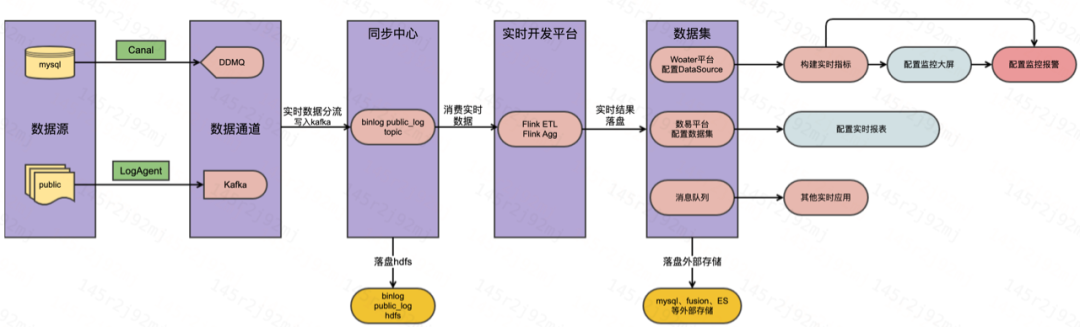
公司内实时数据开发通用方案组件主要包括:实时数据采集、数据通道、数据同步、实时数据计算、实时数据集存储、实时数据应用共六个部分,目前这六个部分使用的组件基本稳定,各组件都可以在相应的平台上灵活使用。
数据源
当前公司主要的实时数据来源是 MySQL 产生的 binlog 日志和业务服务器上产生的 puliclog日志,MySQL 的 binlog 日志是通过阿里开源的采集工具 Canal 完成,Canal 的工作原理是把自己伪装成 MySQL slave,模拟 MySQL slave 的交互协议向 MySQL Master 发送 dump 协议,MySQL master 收到Canal发送的 dump 请求,开始推送 binary log 给 Canal,Canal 解析 binary log 最终把结果发送给 DDMQ 中;Public log 是公司内规范定义的业务日志,通过在业务服务器上部署 LogAgent,由 Agent Manager 进行处理并生成采集配置,在 Agent 访问 Agent Manager 拉取采集配置之后,采集任务开始执行,最终把日志发送到 kafka 中。
数据通道
公司主流的消息通道是 DDMQ 和 kafka,所有的binlog日志源头都来自 DDMQ,DDMQ 是滴滴2018年底开源的产品,他使用 RocketMQ 和 kafka 作为消息的低层存储引擎,主要特点是支持延迟和事务消息,同时也支持复杂的消息转发过滤功能;public log 主要使用 kafka 作为消息通道,实时任务中间链路的开发也主要使用 kafka 作为存储媒介,其主要特点是高可扩展性和生态完善,与 Flink 配合开发效率极高,组件运维很方便。
同步中心
主要功能是把从源头采集的数据,根据业务需要进行离线和实时数据分离。平台对离线场景所需的数据以 DataX 为基础开发的数据链路同步功能,完成数据端到端的数据同步并把结果落盘到 hdfs 中。对实时场景所需的数据,使用内嵌实时计算引擎的 Dsink 任务完成数据采集配置并把结果推送到 kafka 消息队列中,同时也会把数据落盘到 hdfs 中构建离线增量或全量 ods 表。
实时开发平台
目前公司内实时任务开发已经全部整合到数梦(一站式数据开发平台)的实时开发平台上,支持 flink jar 和 flink sql 两种模式,截止2022年6月平台上运行的实时任务中 jar 任务占8%,sql 任务占92%。在日常的实时任务开发中推荐使用 Flink 1.12的 SQL 语法完成实时任务的开发,一方面保证指标口径的一致性,另一方面也能提高实时任务的可维护性。用户在任务开发过程中,建议引入并使用本地调试功能,尽可能规避实时任务开发过程中的错误,提高实时任务上线成功率。通常我们在实时开发平台上主要完成的工作是ETL操作或轻度汇总指标的计算,然后把处理结果写入下游 sink 中。
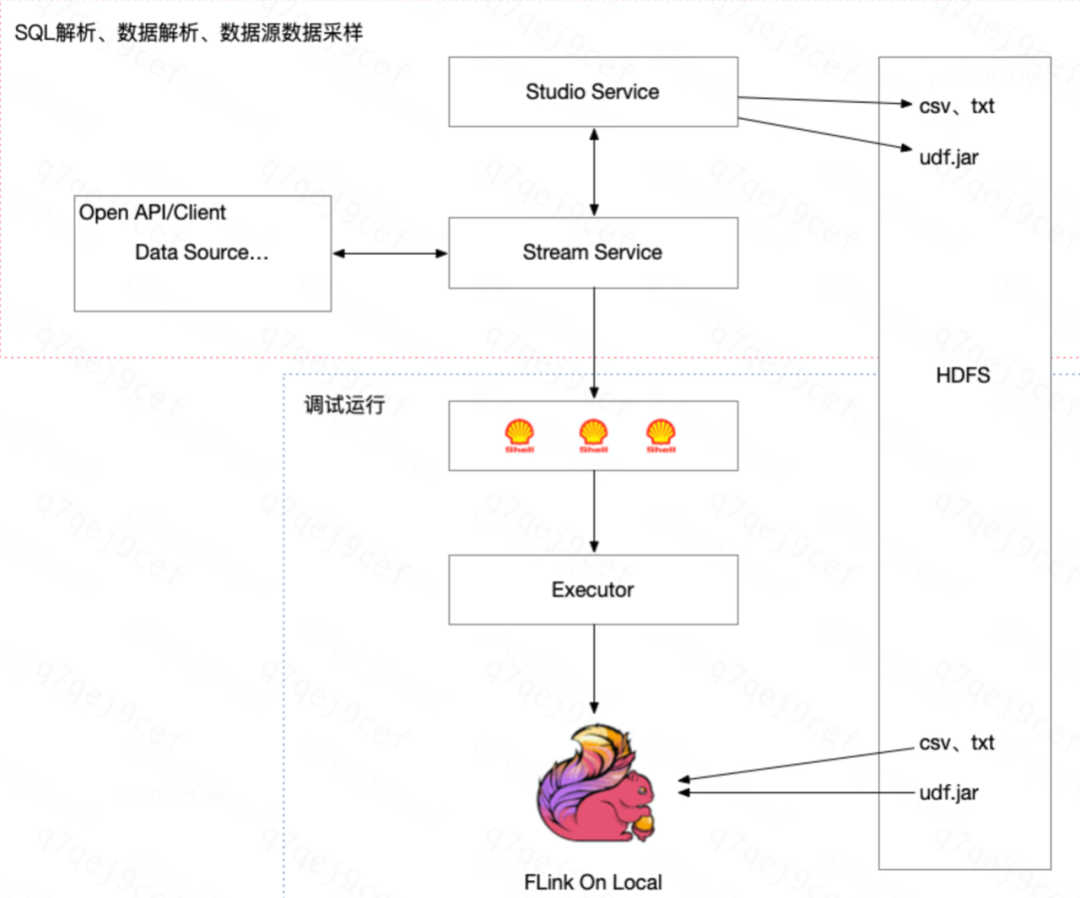
图为本地调试功能流程图
数据集
计算结果的下游 sink 一般包括 Kakfa、druid、Clickhouse、MySQL、Hbase、ES、fusion 等。对于实时任务的中间结果或者实时数仓的 dwd 层数据我们会写入 kafka 中;对于用于指标监控报警的数据我们会写入 Druid 中,利用 druid 时序数据库的特性提高实时指标的监控性能;对于业务bi分析的场景可以把数据写入 Clickhouse 中来配置多样化BI看板;使用flink完成指标计算的结果数据也可以直接写入 mysql,Hbase,ES 或者 fusion 中,这里的具体选型我们将在下一章具体业务场景下做具体说明。目前各下游 sink 已经整合进平台,对于使用 druid 的情况一般需要在 Woater(统一指标监控平台)上配置 Datasource,对于使用 Clickhouse 的情况一般需要在数易(BI分析平台)上配置数据集。

监控报警

实时BI分析
实时数据应用
对于实时结果数据,常用的使用方式包括在 Woater (统一指标监控平台)平台上创建实时指标,同时配置对应的实时看板或者实时监控报警,满足业务分钟级的结果指标监控和实时曲线分析。也可以在数易(BI分析平台)上使用数梦流表( Druid 的 Meta 化表)或者 ClickHouse 数据集来配置实时报表,满足业务侧不同的BI分析需求。
3. 特定场景下的实时数据开发组件选型
以上链路是当前实时任务开发的主要开发链路,在实时开发过程中,结合业务具体需要和各平台的能力优劣,我们需要具体问题具体分析,根据不同业务场景,选择最合适的开发选型。
实时指标监控场景
场景特点:对时间序列依赖明显,对指标及时性要求较高,对指标精确度一般,对查询 QPS 要求较高,对实时数据产出稳定性要求较高。
具体链路:

该类场景建议在 Woater (统一指标监控平台)上配置 DataSource,基于监控要求设置对应的指标列和维度列,为提升查询效率需要配置聚合粒度,常用聚合粒度为30s或1min,同时对于需要计算UV类指标的场景,需要把对应的指标列字段设置为 hyperUnique 类型来提高计算性能,通过设置 druid 的消费分区来提高 druid 消费 topic 数据的能力,一般建议 topic 分区数是 druid 分区数的偶数倍。通过 DataSource 配置的实时指标用于配置实时监控看板和实时监控报警。
核心重保链路:对于核心的监控场景,为了保障实时链路的稳定性和及时性,需要进行双链路开发。

从原始数据源开始做实时数据处理过程的双链路,包括 FLink 任务双活,结果 topic 双活,Druid 表双活三个部分,同时需要支持实时指标级别的双活切换,实现稳定的指标查询,也避免下游监控报警出现误报的情况。
实时 BI 分析场景
场景特点:不完全依赖时间序列,对实时指标准确性要求高,能容许一定的时间延迟,对查询 QPS 要求一般,需要支持灵活的维度+指标组合查询。
具体链路:
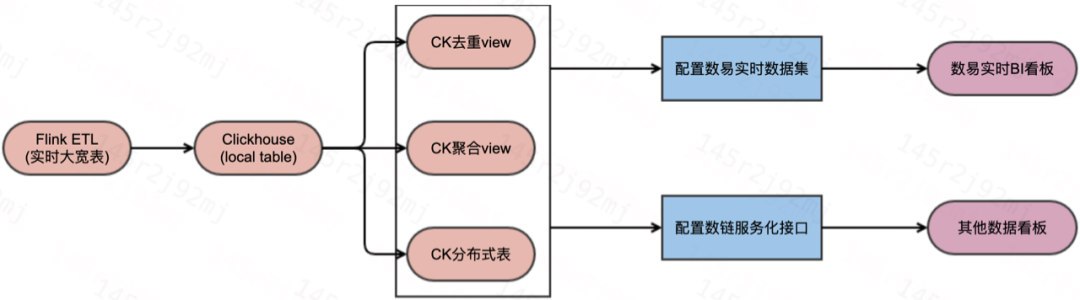
这类场景的主要方案是在 flink 任务中把需要的维度信息都尽可能打平,然后把打平的实时数据微批写入到 Clickhouse 的本地表中。我们以 ClickHouse 的 local 表作为底表,下游根据各类业务需要配置不同的物化视图表,对于需要基于主键做实时去重的场景可以使用CK的 ReplacingMergeTree 引擎实现,之后使用实时去重物化视图表作为数易(BI分析平台)的数据集或者数链(数据服务化平台)接口查询底表供下游配置BI看板;对于确定维度和指标的看板场景为了提高查询性能也可以在 ClickHouse 的 local 表基础上,基于业务需要的维度字段使用 AggregatingMergeTree 引擎创建聚合视图表。这样可以满足下游数易配置看板或者提供数链接口的需求;最后一种是不需要实时去重和预聚合的普通场景,可以把 fink 大屏的数据或者初步预聚合的数据写入CK的普通分布式表中,直接配置数易数据集让用户自行配置业务所需的指标看板。
三类表选择的主要原则:
对业务指标准确性要求极高且有明确去重主键的业务场景,建议使用CK的实时去重视图表。
对业务指标准确性较高,有明确的维度和指标定义,且查询逻辑较复杂或者查询 QPS 较高的场景,建议做预聚合操作,使用CK的聚合视图表。
对业务量不大,业务变更逻辑频繁的场景,建议前期直接使用CK的分布式普通表提供下游看板配置,满足业务的快速迭代和取数需求。
实时数据在线服务场景
场景特点:对实时指标准确性要求高,对查询 QPS 要求较高,对数据及时性要求一般
具体链路:
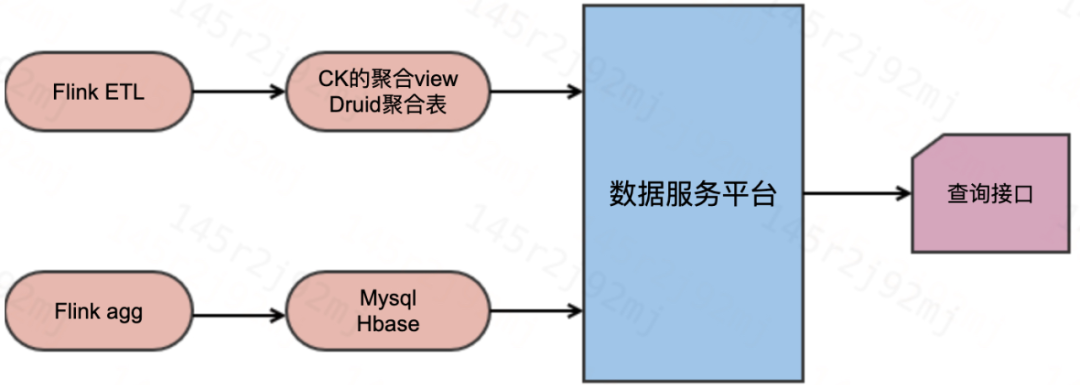
这类场景主要特点是需要把所需的实时指标做各类前置处理,一种方式是把所需要的实时指标在 flink 任务中完成计算,把最终的结果实时写入到 Mysql 或者 Hbase 等支持实时更新的存储中,供下游数据服务平台进行接口封装。这类方案适用于业务逻辑变更不频繁且需要提供数据服务的场景;另一种方式是把聚合逻辑下移,flink任务主要做数据内容打宽和简单的预聚合,主要的指标统计工作交由下游的 OLAP 引擎计算,数据服务平台通过封装 OLAP 引擎来提供接口查询服务。这样做的好处是在业务指标逻辑频繁变更的情况下也能使用 OLAP 的预聚合能力提供高效的实时指标服务,缺点是对 OLAP的查询压力较大,需要提供更多的资源供 OLAP 消耗才能保证服务的高 QPS。
实时特征和标签系统
场景特点:对实时指标准确性要求一般,对查询 QPS 要求较高且涉及到较大的实时状态运算,需要支持实时和离线指标融合的情况。
具体链路:
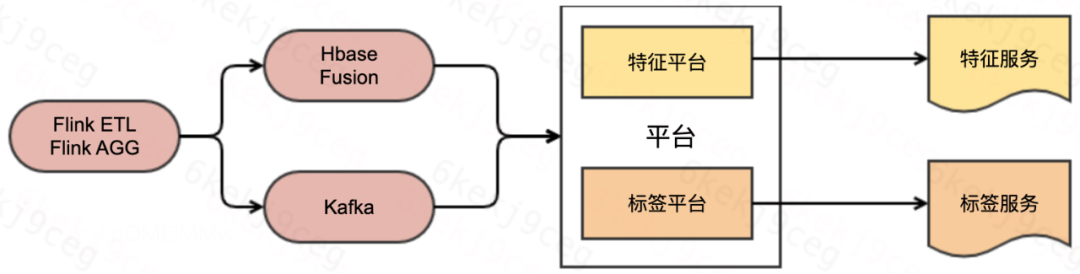
该类场景一般会有明确的指标列和维度列,需要把大量的实时特征或者指标标签接入平台,方案一是直接通过 topic 让平台消费数据,平台封装后提供特征或者标签服务,方案二是利用 Hbase 和 Fusion 基于强大的主键更新能力,把实时和离线标签都灌入其中后接入平台的方式提供特征服务或者标签服务,供下游算法同学使用。
4. 各组件资源使用原则
实时数据开发涉及到的组件较多,各组件在使用过程中建议遵循基本原则,做到资源充分利用,在满足实时任务开发的前提下,节约大量不必要的成本开销。
数据采集:单一采集原则,对于业务需要的实时指标开发,上游数据源尽可能做到复用,保证实时和离线 ods 层统一。
ddmq:一个 flink 任务对应一个 ddmq 消费组,支持多个 topic 使用一个消费组,不建议同一个消费组在不同实时任务中使用。
kafka:单分区流量建议不超过3MB/s,重要的实时任务kafka存储时间需要控制在48~72小时左右,至少保证能回溯2天的历史数据。
Flink:kafka 和 ddmq 的 source 并发数需要严格与 kafka 和 ddmq 设置的分区数一致,这样的消费性能最佳。公司内 flink 任务的单TM资源是固定的 slot = 2、taskmanagermemory = 4096、containers.vcores = 2 根据业务场景不同可以做适当调整,对于纯ETL场景可以适当调大单TM的slot数量,对于含有较大内存占用的任务可以适当调大 taskmanagermemory 数值。在正常实时任务开发过程中消费 kafka 任务的全局并发建议和 source 并发一致,消费 ddmq 的全局并发需要根据 ddmq 的流量确定,流量在(1000±500)区间的场景全局并发设置为3,超过的场景更加该比例折算,具体需要根据业务计算逻辑中算子耗时最大值预估。
druid:创建druid表时一定要设置聚合粒度,建议粒度为30s或者1min,数据存储周期默认为3个月,在确定的业务场景中创建的 druid 表需要明确维度和指标字段,维度字段尽可能使用 String 类型,Druid 对 String 类型做了 bitmap 和倒排索引优化;指标字段在满足业务使用的前提下,尽可能使用预估类型来提高实时指标的计算性能。
Clickhouse:Flink 实时写入任务默认间隔不小于30s,写入并行度尽量控制在10以内,CK表数据存储周期控制在1个月左右,必须按照时间作为分区字段,其他类型的字段无法作为分区。实时数据写入场景推荐使用 Flink2Ck native connector 模式写入,提高实时写入的稳定性,同时减少CK的CPU消耗;Flink2CK写入吞吐量建议控制在20M/s(单并发)以内,间接保障CK集群的稳定性。
5. 总结和展望
本文主要从当前滴滴具体的业务场景出发总结了主流的实时任务开发方案以及技术栈,为用户从离线开发转向实时数据开发提供一定的入门基础,同时为产品和运营同学提供了较好的实时链路开发科普,一定程度上降低了实时数据建设的开发门槛。之后通过滴滴典型的四个业务场景实时指标监控、实时BI分析、实时数据在线服务、实时特征来具体说明各业务场景下实时组件的选型差异和遵循原则。可以帮助业务开发同学根据具体数据需求指定合理的实时开发方案并快速落地。最后本文对实时任务开发过程中的主要组件提供了配置建议,保证在完成用户实时任务开发的前提下尽可能降低开发成本,提高资源总体使用效率,降本提效。