文章目录
- 2021
- OBJECT COUNTING: YOU ONLY NEED TO LOOK AT ONE
- 2022
- Scale-Prior Deformable Convolution for Exemplar-Guided Class-Agnostic Counting
- CounTR: Transformer-based Generalised Visual Counting
- Few-shot Object Counting with Similarity-Aware Feature Enhancement
- 2023
- CAN SAM COUNT ANYTHING? AN EMPIRICAL STUDY ON SAM COUNTING
- Zero-Shot Object Counting
2021
OBJECT COUNTING: YOU ONLY NEED TO LOOK AT ONE
摘要: 本文旨在解决一个热门对象计数的挑战性任务。给定一个包含新颖的、以前未见过的类别对象的图像,该任务的目标是只使用一个支持的边界框示例来计算所需类别中的所有实例。为此,我们提出了一个计数模型,通过该模型,您只需要查看一个实例(LaoNet)。首先,一个特征相关模块结合了自我注意和相关注意模块来学习内部关系和相互关系。它使网络对不同实例之间的旋转和大小的不一致性具有鲁棒性。其次,设计了一种尺度聚合机制来帮助提取具有不同尺度信息的特征。与现有的少镜头计数方法相比,LaoNet在学习收敛速度较快的同时,取得了最先进的结果。

2022
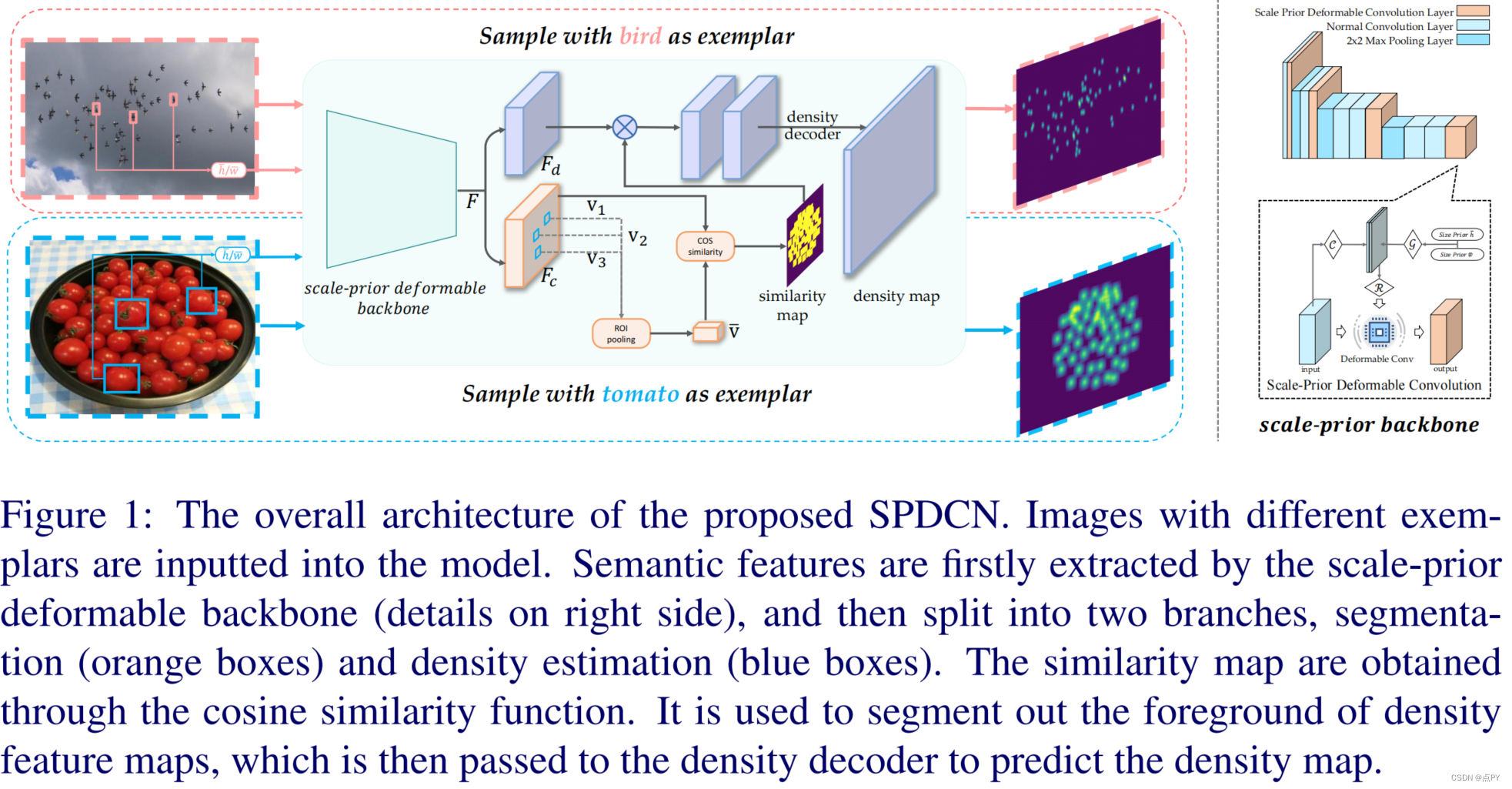
Scale-Prior Deformable Convolution for Exemplar-Guided Class-Agnostic Counting
摘要:类不可知论计数最近成为一项更实用的计数任务,它旨在预测任何范例对象的数量和分布,而不是计算行人或汽车等特定类别。然而,最近的方法是在设计样本和查询图像之间的相似匹配规则,而忽略了提取特征的鲁棒性。为了解决这个问题,我们提出了一种尺度先验可变形卷积,通过将样本的信息,例如,尺度,集成到计数网络的主干中。结果表明,所提出的计数网络可以提取与给定样本相似的对象的语义特征,并有效地过滤不相关的背景。此外,我们发现,由于不同样本中的对象尺度的不同,传统的l2和广义损失不适用于类不可知计数。在此,我们提出了一个尺度敏感的广义损失来解决这个问题。它可以根据给定的范例调整成本函数公式,使预测和地面真实值之间的差异更加突出。大量的实验表明,我们的模型获得了显著的改进,并在一个公共的类无关的计数基准上取得了最先进的性能。

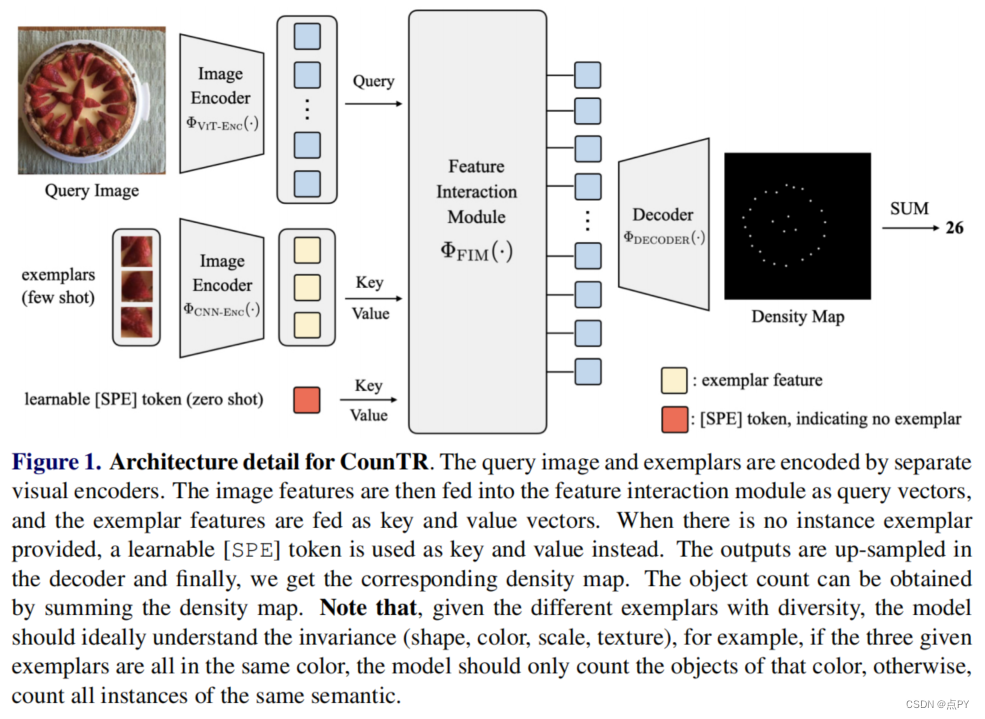
CounTR: Transformer-based Generalised Visual Counting
摘要:在本文中,我们考虑了广义视觉对象计数问题,目的是开发一个计算模型来计算任意语义类别的对象数量,使用任意数量的“范例”,即零射击或低射计数。为此,我们做出了以下四个贡献: (1)我们引入了一种新的基于transformer的架构,用于一般化视觉对象计数,称为计数transformer(CounTR),它明确地捕捉图像补丁之间的相似性或给定的“样本”;(2)采用两阶段训练机制,首先用自监督学习对模型进行预训练,然后进行监督微调;(3)我们提出了一个简单的、可扩展的管道,用于合成具有大量实例或来自不同语义类别的训练图像,明确地迫使模型使用给定的“范例”;(4)我们对大规模计数基准进行了彻底的消融研究,如FSC- 147,并在零镜头和少镜头设置上展示了最先进的性能。
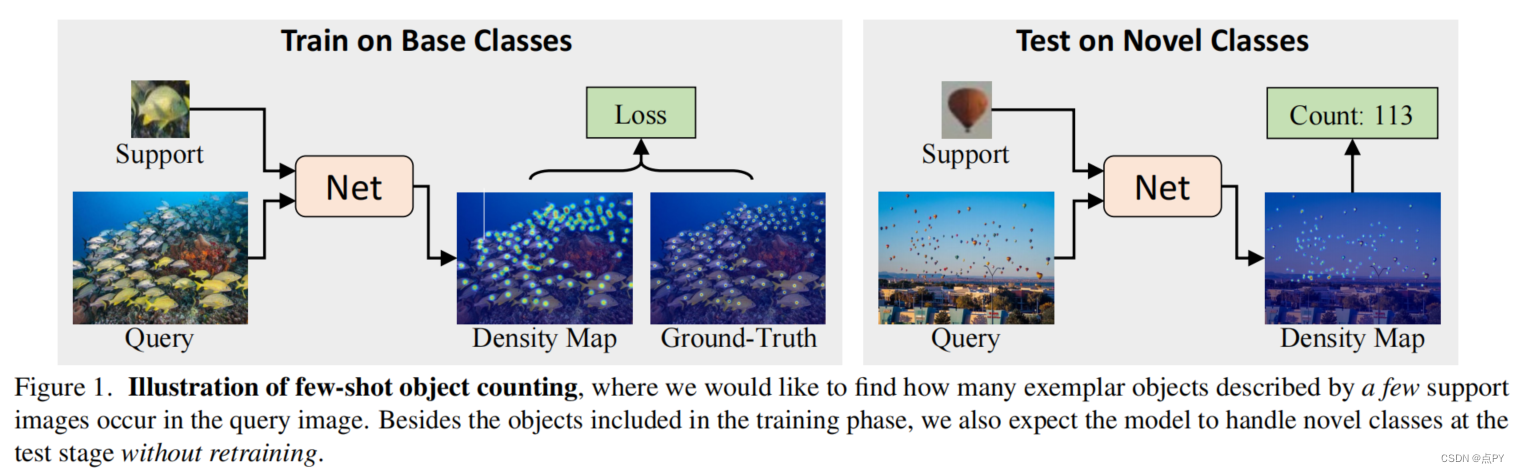
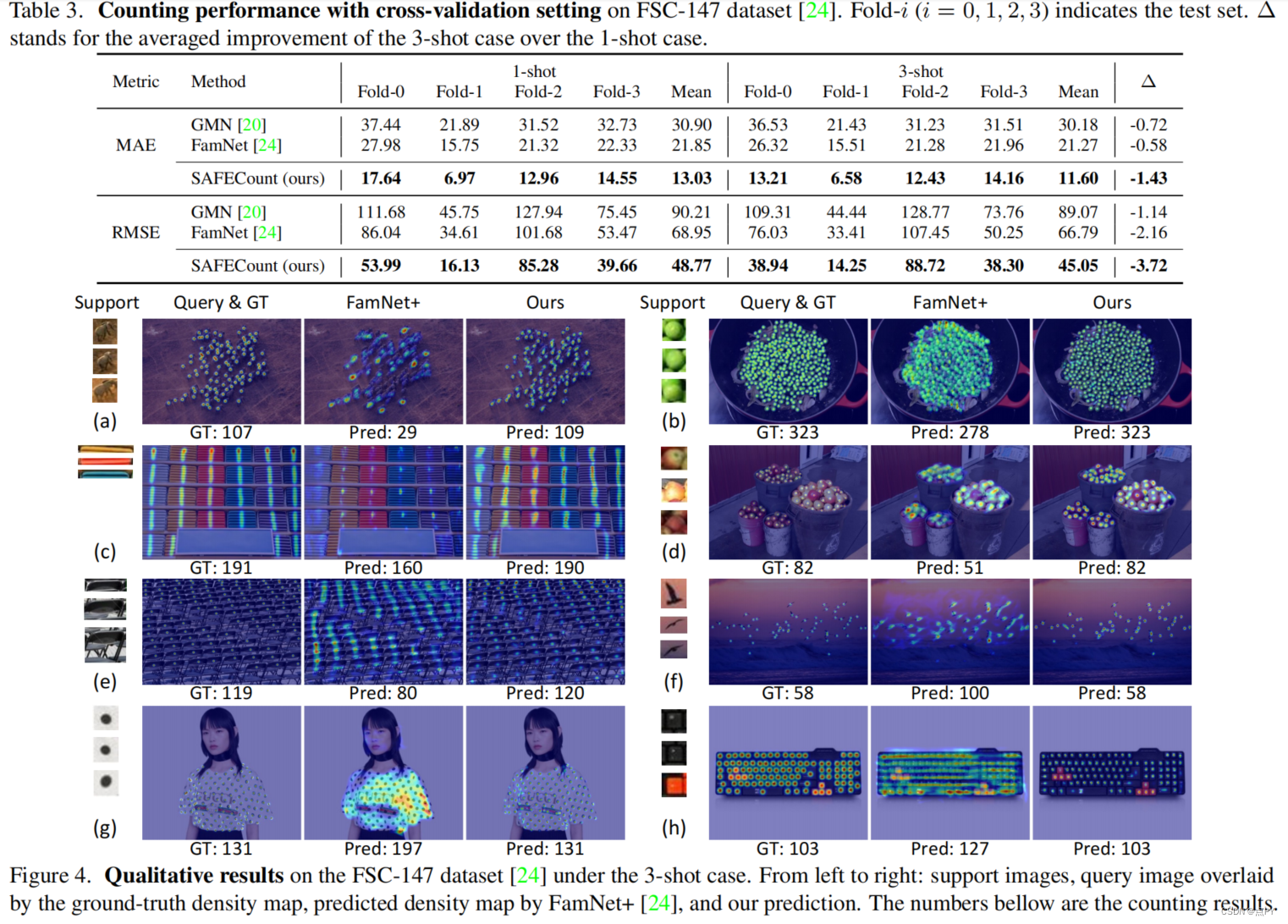
Few-shot Object Counting with Similarity-Aware Feature Enhancement
code: https://github.com/zhiyuanyou/SAFECount
摘要:这项工作研究了少镜头对象计数的问题,它计数在查询图像中发生的范例对象(即,由一个或几个支持图像描述)的数量。主要的挑战在于,目标对象可以密集地打包在查询图像中,这使得很难识别每一个对象。为了解决这一障碍,我们提出了一种新的学习模块,包括相似度比较模块和特征增强模块。具体地说,给定一个支持图像和一个查询图像,我们首先通过比较它们在每个空间位置上的投影特征来得到一个得分图。关于所有支持图像的得分图被一起收集,并跨范例维度和空间维度进行归一化,生成一个可靠的相似性图。然后,我们利用所开发的点向相似性作为加权系数,利用支持特征来增强查询特征。这种设计鼓励模型通过更多地关注类似于支持图像的区域来检查查询图像,从而使不同对象之间的边界更加清晰。在各种基准和训练设置上的广泛实验表明,我们以足够大的优势超过了最先进的方法。例如,在最近的一个大规模的FSC-147数据集上,我们通过将平均绝对误差从22.08提高到14.32(35%↑),超过了最先进的方法。
2023
CAN SAM COUNT ANYTHING? AN EMPIRICAL STUDY ON SAM COUNTING
code: https://github.com/Vision-Intelligence-and-Robots-Group/count-anything
摘要:Meta AI最近发布了“分段任何东西模型”(SAM),该模型因其在类不可知分割方面令人印象深刻的表现而获得了关注。在本研究中,我们探讨了使用SAM进行具有挑战性的少镜头对象计数任务,即通过提供几个边界框来计数一个看不见类别的对象。我们将SAM的性能与其他少量的镜头计数方法进行了比较,发现目前没有进一步的微调,它并不令人满意,特别是对于小的和拥挤的对象。

Zero-Shot Object Counting
code: https://github.com/cvlab-stonybrook/zero-shot-counting
摘要: 类不可知的对象计数的目的是在测试时计算任意类的对象实例。目前解决这一具有挑战性问题的方法需要人工注释的范例作为输入,而这对于新的类别通常是不可用的,特别是对于自治系统。因此,我们提出了零射击对象计数(ZSC),这是一个新的设置,在测试期间只有类名可用。这样的计数系统不需要循环中的人工注释器,并且可以自动操作。从一个类名开始,我们提出了一种方法,可以准确地识别最优补丁,然后可以用作计数样本。具体来说,我们首先构建一个类原型来选择可能包含感兴趣的对象的补丁,即与类相关的补丁。此外,我们引入了一个模型,可以定量地衡量任意补丁作为计数范例的适应性。通过将该模型应用于所有的候选补丁,我们可以选择最合适的补丁作为范例进行计数。在最近的类不可知计数数据集FSC-147上的实验结果验证了我们的方法的有效性。