前面的文章介绍了URL编码,UTF8编码,base64,gzip等多种编解码的方式,这里,本节对字符和编码一些杂项进行梳理,相信你会感兴趣。
Python 中的字符和编码
为什么要强调字符编号和字符编码分离这样⼀个概念呢。因为在编程语言中,很重要的一个方面就是处理字符,一门优秀的编程语言应该也要明确这两个概念,而Python 恰巧就是这样的一门语言。尽管在 Python2 中区分的还不是特别的明显,但是在 Python3 中是明确的用str 类表示字符串;bytes 表示字节串,即可以用来存储字符串编码后的值,说明如下:
1,Python3 中使用 str 类来表示和存储字符串,在一个具体的字符串对象中存储的内容是每个字符的编号,该编号就是字符集中赋予的。至于该编号在 Python 中使用个字节来进行存储往往是不确定的,例如常用汉字的编号通常使用两个字节就可以表示编号。对于一些特殊的字符(比如音乐中的那些字符),往往需要更多的字节。这是 Python内部的实现机制,不在过多的阐述,感兴趣的同学在学习完本文方法之后,自行研究尝试。
2,Python 3 中使用 bytes 类来表示和存储字符串编码的值。由于字符对应的编码方式不止一个,包括 UTF-8、UTF-16、UTF-32 以及 GB2312、GBK 等,因此其存储的值通常是编码方式决定的,不同的编码方式下,得到字符串的编码值互不相同;其次编码之后bytes 对象中存储的值和 str 对象中存储的值也是不一样的。
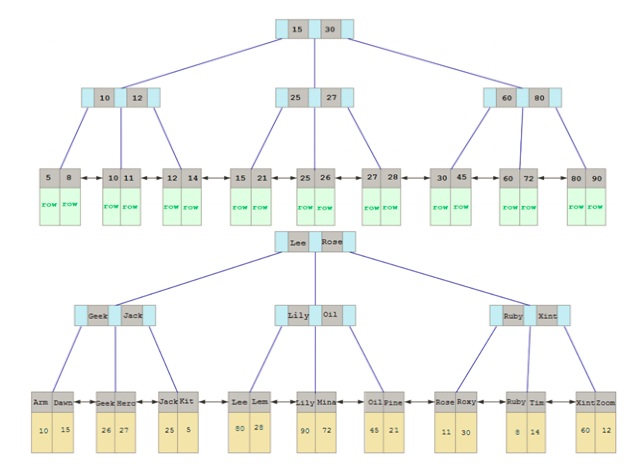
还是以我的 CSDN 博客名称⸺村中少年这几个字符串为例,有前面可知:
1,首先这几个字符的 Unicode 编号分别为 6751、4E2D、5C11、5E74
2,UTF-8 编码后的值为 E6 9D 91 E4 B8 AD E5 B0 91 E5 B9 B4
编写如下程序,并查看对象对应的内存内容:
def printMem(data):
from ctypes import string_at
from sys import getsizeof
from binascii import hexlify
print(hexlify(string_at(id(data), getsizeof(data))))
if name == " main ":
nameStr = '村中少年'
nameBytes = nameStr.encode()
print(type(nameStr))
print(type(nameBytes))
printMem(nameStr)
printMem(nameBytes)
运行结果如下:
<class 'str'>
<class 'bytes'>
b'0500000000000000c0f562b5417f000004000000000000001a53594d- c9e6e066a80a64b5417f00000000000000000000000000000000000000000000000000 000000000000000000`51672d4e115c745e`0000'
b'0300000000000000e0fe60b5417f00000c00000000000000ffffffffffffffff`e69d91e4b8ade5b091e5b9b4`00'
标记的部分分别表示的是字符串中的 Unicode 编号以及 UTF-8 编码后的值,可以看到 nameStr 字符串中的确存储了 Unicode 编号的值,nameBytes 存储的是编码后的值,验证了一开始所说的。这就是 Python 在语言层面上对于字符串和编号的支持,当然非标记的部分是该对象其他部分的值,本次内容不涉及。
下图1是一个外部文件从形成到被 Python 3 读取的一系列操作:
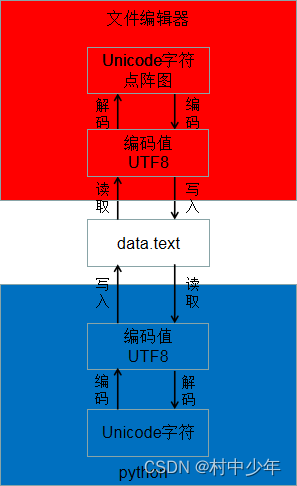
图1
可以看出文件的形成,包括 Python 源码文件的形成,是符合前面描述的显示和存储相分离; 同时 Python 3 在读取文件的时候都是默认按照字符串形式处理的,即转换成为 Unicode 编号,除非显示的指定为二进制的读取方式。
Python 为什么要使用编号表示字符串本身呢?其实这和前面显示和存储分离的道理一样,字符串无论在何处,无论是写在纸上还是显示在计算机上,其本身的含义不变,因此需要编号这个确定的值来表示。但是在存储的时候,出于效率等方面的考虑,有不同的编码方式,不同的编码方式意味着不同的值, 因此编码值( 不唯一) 来表示字符串是不合适的。 早期使用ASCII、GB2312 这种不区分编码和编号的编码模型问题不大,但是在 Unicode 字符集中不行。通过我的这篇⽂章,相信你对于字符串和其编码⽅式应该能够加以区分。
文件系统编码
由于文件系统的编码和操作系统编码基本保持一致,所以往往我们会忽略。实际上如果在两个不同的文件系统之间移动文件的话,一个非常容易发生的事情就是文件名称的乱码,这个相 信很多同学都有遇到过。由于文件的文件名是是文件系统负责解码显示的,因此如果两个文件系统编码不同,乱码则显而易见。背后的原因其实和文件内容乱码是一样的,即编码写入和解码显示使用的规则不一致。往往是一个采用 GBK 写入,一个采用 UTF-8 读取。
网络协议编码
在 HTTP 协议的协议头部中,有这样一个字段,Content-Type:可以用来告诉协议接收方使用指定的方式解码收到的数据,如下为某个 HTTP 的报文头:
GET / HTTP/1.1
Host: www.guoguo-app.com Connection: close
HTTP/1.1 200 OK
Content-Type: text/html;charset=utf-8
Transfer-Encoding: chunked
Connection: close
Vary: Accept-Encoding
Vary: Accept-Encoding
Content-Language: zh-CN
Server: Tengine/Aserver
可以看到服务器告诉客户端采用UTF-8 解码收到的数据内容,浏览器或者爬虫在解析 HTTP 头部之后,按照 HTTP 指定方式解码即可正确显示数据内容,比如在线显示一个文本文件。当然这里使用 charset 我觉得不太准确,因为 charset 往往指的是字符集,应该使用charsetEn- coding 比较合适,虽然我们都能够理解其含义。
网页编码
在 HTML网页中通常使用如下标签表示该 HTML 采用的编码方式:
<meta charset="UTF-8">
浏览器在读取该文件的标签后,会按照 utf8 编码方式式显示该文件。 如果该 HTML文件采用GBK方式存储,则浏览器会显示乱码,因为解码方式错误。因此 HTML 文件实际编码要和网页中的 保持一,不然也可能出现错误。这个时候你可能会问,如果协议中的 Content-Type 与网页中的 meta charset 不一致怎么办。这个时候浏览器肯定会做一个取舍,通常的做法是协议响应头优先级比网页中的高。但是事实上浏览器的编写者如何实现,那 就仁者见仁智者见智了。
上述总结计算机系统中编码和字符的一些点,希望对你有所帮助。
本文为CSDN村中少年原创文章,未经允许不得转载,博主链接这里。