FasterTransformer
- Faster Transformer是一个Transformer单层前向计算的高效实现。一个函数由多个OP组合实现。每一个基本OP都会对应一次GPU kernel的调用,和多次显存读写。OP融合可以降低GPU调度和显存读写,进而提升性能。在Faster Transformer,作者将除矩阵乘法以外的所有kernel都进行了尽可能的融合。
NVIDIA 博客在2019-07-15的介绍:
- 目前优化集中在编码器(encoder)的前向计算(解码器decoder开发在后续特性规划中)。底层由CUDA和cuBLAS实现,支持FP16和FP32两种计算模式,其中FP16可以充分利用Volta和Turing架构GPU上的Tensor Core计算单元。
Faster Transformer共接收4个输入参数。首先是attention head的数量以及每个head的维度。这两个参数是决定Transformer网络结构的关键参数。
这两个参数的动态传入,可以保证Faster Transformer既支持标准的BERT-BASE(12 head x 64维),也支持裁剪过的模型(例如,4 head x 32维),或者其他各式专门定制化的模型。其余两个参数是Batch Size 和句子最大长度。
出于性能考虑,目前句子最大长度固定为最常用的32,64 和128三种,未来会支持任意长度。Faster Transformer对外提供C++ API,TensorFlow OP 接口,以及TensorRT插件,并提供了相应的示例,用以支持用户将其集成到不同的线上应用代码中。
NVIDIA BERT推理解决方案Faster Transformer开源啦,这篇文章还有单层计算attention的图解,可结合代码查看
Jul 29, 2021 v1.0版本的介绍
- Faster Transformer 建立在 CUDA 和 cuBLAS 之上。它支持大于 3 且小于或等于 1024 的序列长度。变压器层的两个关键参数,即磁头的数量和每个磁头的大小,在运行时传递。因此,不仅BERT Base(12头* 64头),而且定制型号,如4头* 32/头和8头* 96每头,都得到了很好的支持。我们的实现在小批量和大批量情况下都显示出良好的加速。
v1.0_tag
-
https://github.com/NVIDIA/FasterTransformer/tree/release/v1.0_tag
-
环境准备
-
下边的操作有点麻烦,这个链接给出了dockerfile https://github.com/NVIDIA/TensorRT/tree/release/5.1/docker
-
sudo docker run -it --shm-size 8gb --rm --gpus=all -v ${PWD}:/test nvcr.io/nvidia/cuda:10.0-cudnn7-devel-ubuntu16.04 bash
-
cd /test/FastT
-
git clone https://github.com/NVIDIA/FasterTransformer.git -
apt-get update
-
apt-get install git
-
下载 FasterTransformer-release-v1.0_tag.zip
git clone -b release/v1.0_tag --depth=1 https://github.com/NVIDIA/FasterTransformer.git -
apt-get install zip
-
unzip FasterTransformer-release-v1.0_tag.zip -
git submodule init && git submodule update
bulid
- mkdir -p build && cd build
- wget https://github.com/Kitware/CMake/releases/download/v3.26.3/cmake-3.26.3-linux-x86_64.sh
- bash ./cmake-3.26.4-linux-x86_64.sh --skip-licence --prefix=/usr
- export PATH=“/usr/cmake-3.26.4-linux-x86_64/bin:$PATH”
cmake -DSM=86 -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON -DBUILD_MULTI_GPU=ON ..orcmake -DSM=xx -DCMAKE_BUILD_TYPE=Release .. # C++ only
CMake Error at CMakeLists.txt:109 (add_subdirectory):
The source directory
/test/FastT/code/FasterTransformer/tools
does not contain a CMakeLists.txt file.
- 原因:在https://github.com/NVIDIA/FasterTransformer/blob/release/v1.0_tag/CMakeLists.txt有 add_subdirectory(tools)
- 所以将其修改成 add_subdirectory(tools/gemm_test)了
make
- make
- maybe error : nvcc fatal : redefinition of argument ‘std’
- https://github.com/facebookresearch/DetectAndTrack/issues/57 : Try to find out all --std=c++11 and removed
这个错误通常是由于您在使用`-ccbin`选项时指定了一个使用了不同的C++标准库的编译器而引起的。
加入`-Xcompiler -stdlib=libstdc++`选项可以明确告诉`nvcc`使用`libstdc++`标准库。例如:
nvcc -ccbin g++-7 -Xcompiler -stdlib=libstdc++ your_file.cu -o your_executable
可以在`-ccbin`选项中指定您需要使用的C++编译器,然后在`-Xcompiler`选项中指定需要使用的标准库,以解决此问题。如果您不知道应该使用哪个编译器和标准库,请参考您的CUDA安装说明文档或咨询CUDA社区。
TEST
-
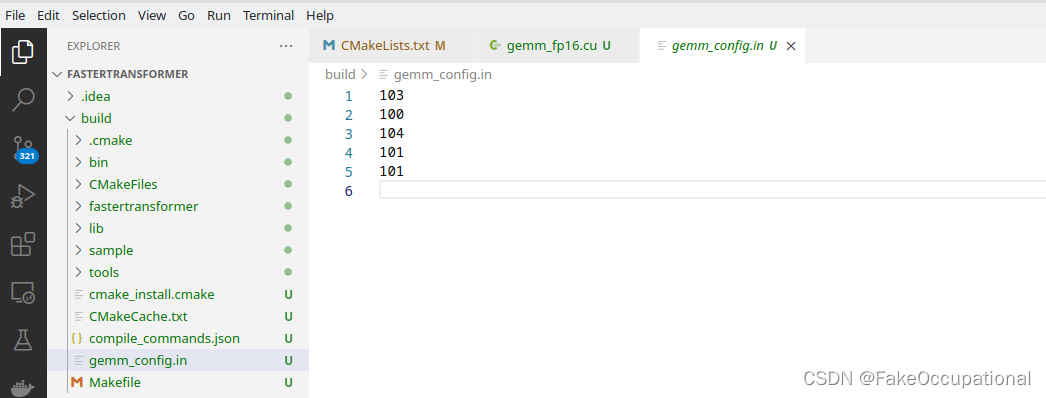
./bin/gemm_fp16 100 12 32 64# 在路径构建下生成gemm_config.in文件,以选择gemm算法以获得最佳性能。
-
c++ demos:
./build/bin/transformer_fp16 100 12 32 64<batch_size> <num_layerse> <seq_len> <head_num> <size_per_head>
Useful sample code
$ 1. sample/tensorflow/transformer_fp32.py: transformer_layer Tensorflow FP32 OP call, time measurement, timeline generation
$ 2. sample/tensorflow/transformer_fp16.py: transformer_layer Tensorflow FP16 OP call, time measurement, timeline generation
$ 3. sample/tensorflow/error_check.py: how to catch custom OP runtime errors
$ 4. sample/cpp/transformer_fp32.cc: transformer layer C++ FP32 sample
$ 5. sample/cpp/transformer_fp16.cc: transformer layer C++ FP16 sample
$ 6. sample/tensorRT/transformer_trt.cc: transformer layer tensorRT FP32/FP16 sample
$ 7. tools/gemm_test/gemm_fp16.cu: loop over all cublas FP16 GEMM algorithms and pick the best one
$ 8. tools/gemm_test/gemm_fp32.cu: loop over all cublas FP32 GEMM algorithms and pick the best one
CG
-
https://developer.nvidia.com/cuda-example
-
https://github.com/NVIDIA/FasterTransformer
-
构建FasterTransformer : 推荐使用Nvidia官方提供的镜像,如: nvcr.io/nvidia/tensorflow:22.09-tf1-py3 、 nvcr.io/nvidia/pytorch:22.09-py3等,当然也可以使用Pytorch官方提供的镜像。
-
使用 FasterTransformer 和 Triton 推理服务器部署 GPT-J 和 T5
-
FasterTransformer 中的优化
-
https://on-demand.gputechconf.com/gtc-cn/2019/pdf/CN9468/presentation.pdf
-
FasterTransformer 2.0优化——公开课听课笔记
-
跑ChatGPT体量模型,从此只需一块GPU:加速百倍的方法来了
-
https://github.com/prabhuomkar/pytorch-cpp/blob/master/tutorials/basics/pytorch_basics/CMakeLists.txt