4.8 Socket介绍
所谓 socket(套接字),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。从所处的地位来讲,套接字上联应用进程,下联网络协议栈,是应用程序通过网络协议进行通信的接口,是应用程序与网络协议根进行交互的接口。
socket 可以看成是两个网络应用程序进行通信时,各自通信连接中的端点,这是一个逻辑上的概念。它是网络环境中进程间通信的 API,也是可以被命名和寻址的通信端点,使用中的每一个套接字都有其类型和一个与之相连进程。通信时其中一个网络应用程序将要传输的一段信息写入它所在主机的 socket 中,该 socket 通过与网络接口卡(NIC)相连的传输介质将这段信息送到另外一台主机的 socket 中,使对方能够接收到这段信息。socket 是由 IP 地址和端口结合的,提供向应用层进程传送数据包的机制。
socket 本身有“插座”的意思,在 Linux 环境下,用于表示进程间网络通信的特殊文件类型。本质为内核借助缓冲区形成的伪文件。既然是文件,那么理所当然的,我们可以使用文件描述符引用套接字。与管道类似的,Linux 系统将其封装成文件的目的是为了统一接口,使得读写套接字和读写文件的操作一致。区别是管道主要应用于本地进程间通信,而套接字多应用于网络进程间数据的传递。
Linux系统,一切皆文件。
套接字通信分两部分:
- 服务器端:被动接受连接,一般不会主动发起连接
- 客户端:主动向服务器发起连接
socket是一套通信的接口,Linux 和 Windows 都有,但是有一些细微的差别。

4.9字节序
简介
大部分计算机采用小端字节序。
现代 CPU 的累加器一次都能装载(至少)4 字节(这里考虑 32 位机),即一个整数。那么这 4字节在内存中排列的顺序将影响它被累加器装载成的整数的值,这就是字节序问题。在各种计算机体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机通信领域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双字等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正确的编码/译码从而导致通信失败
字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。
字节序分为大端字节序(Big-Endian) 和小端字节序(Little-Endian)。大端字节序是指一个整数的最高位字节(23 ~ 31 bit)存储在内存的低地址处,低位字节(0 ~ 7 bit)存储在内存的高地址处;小端字节序则是指整数的高位字节存储在内存的高地址处,而低位字节则存储在内存的低地址处。
字节序举例


判别代码
/*
字节序:字节在内存中存储的顺序。
小端字节序:数据的高位字节存储在内存的高位地址,低位字节存储在内存的低位地址
大端字节序:数据的低位字节存储在内存的高位地址,高位字节存储在内存的低位地址
*/
// 通过代码检测当前主机的字节序
#include <stdio.h>
int main() {
//联合体,直接创建它的变量test
union {
short value; // 2字节
char bytes[sizeof(short)]; // char[2]
} test;
test.value = 0x0102;
if((test.bytes[0] == 1) && (test.bytes[1] == 2)) {
printf("大端字节序\n");
} else if((test.bytes[0] == 2) && (test.bytes[1] == 1)) {
printf("小端字节序\n");
} else {
printf("未知\n");
}
return 0;
}

4.10字节序转换函数
当格式化的数据在两台使用不同字节序的主机之间直接传递时,接收端必然错误的解释之。解决问题的方法是:发送端总是把要发送的数据转换成大端字节序数据后再发送,而接收端知道对方传送过来的数据总是采用大端字节序,所以接收端可以根据自身采用的字节序决定是否对接收到的数据进行转换(小端机转换,大端机不转换)。
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释,网络字节顺序采用大端排序方式。
BSD Socket提供了封装好的转换接口,方便程序员使用。包括从主机字节序到网络字节序的转换函数:htons、htonl;从网络字节序到主机字节序的转换函数:ntohs、ntohl。
h - host 主机,主机字节序
to - 转换成什么
n - network 网络字节序
s - short unsigned short
l - long unsigned int
实现代码:
/*
网络通信时,需要将主机字节序转换成网络字节序(大端),
另外一段获取到数据以后根据情况将网络字节序转换成主机字节序。
// 转换端口
uint16_t htons(uint16_t hostshort); // 主机字节序 - 网络字节序
uint16_t ntohs(uint16_t netshort); // 网络字节序 - 主机字节序
// 转IP
uint32_t htonl(uint32_t hostlong); // 主机字节序 - 网络字节序
uint32_t ntohl(uint32_t netlong); // 网络字节序 - 主机字节序
*/
#include <stdio.h>
#include <arpa/inet.h>
int main() {
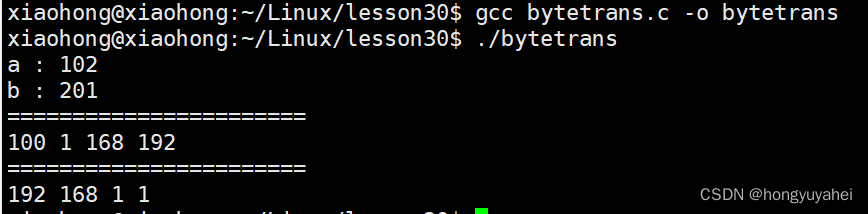
// htons 转换端口
unsigned short a = 0x0102;
printf("a : %x\n", a);
unsigned short b = htons(a);
printf("b : %x\n", b);
printf("=======================\n");
// htonl 转换IP
char buf[4] = {192, 168, 1, 100};
int num = *(int *)buf;
int sum = htonl(num);
unsigned char *p = (char *)∑
printf("%d %d %d %d\n", *p, *(p+1), *(p+2), *(p+3));
printf("=======================\n");
// ntohl
unsigned char buf1[4] = {1, 1, 168, 192};
int num1 = *(int *)buf1;
int sum1 = ntohl(num1);
unsigned char *p1 = (unsigned char *)&sum1;
printf("%d %d %d %d\n", *p1, *(p1+1), *(p1+2), *(p1+3));
// ntohs
return 0;
}


![[读论文]Referring Camouflaged Object Detection](https://img-blog.csdnimg.cn/77ad43e5bcf54278aac20875f214a926.png)