文章目录
- 索引
- 概念
- page
- 索引类型
- B树vsB+树
- 主键索引
- 非聚簇索引
- 覆盖索引
- 复合索引/联合索引
- 优化
- 基于B+树的索引
- hash索引
- 事务
- 事务的特性ACID
- 问题
- 隔离级别
索引
概念
使用一定的数据结构,来保存索引字段(一列或多列)对应的数据。以后根据索引字段来检索,就可提高检索效率。
sql性能优化关键:是否能够命中索引。
因为其使用一定数据结构来保存,所以需要一定的空间(本地硬盘的文件)来保存。
创建索引,更新/删除索引字段,插入数据:都会导致索引更新的耗时操作。
page
数据库保存数据的基本单位:page
目的:硬盘读取文件到内存的io操作也是耗时的,读取数据最好也就能最少次读取到需要的结果集
索引类型
B树vsB+树
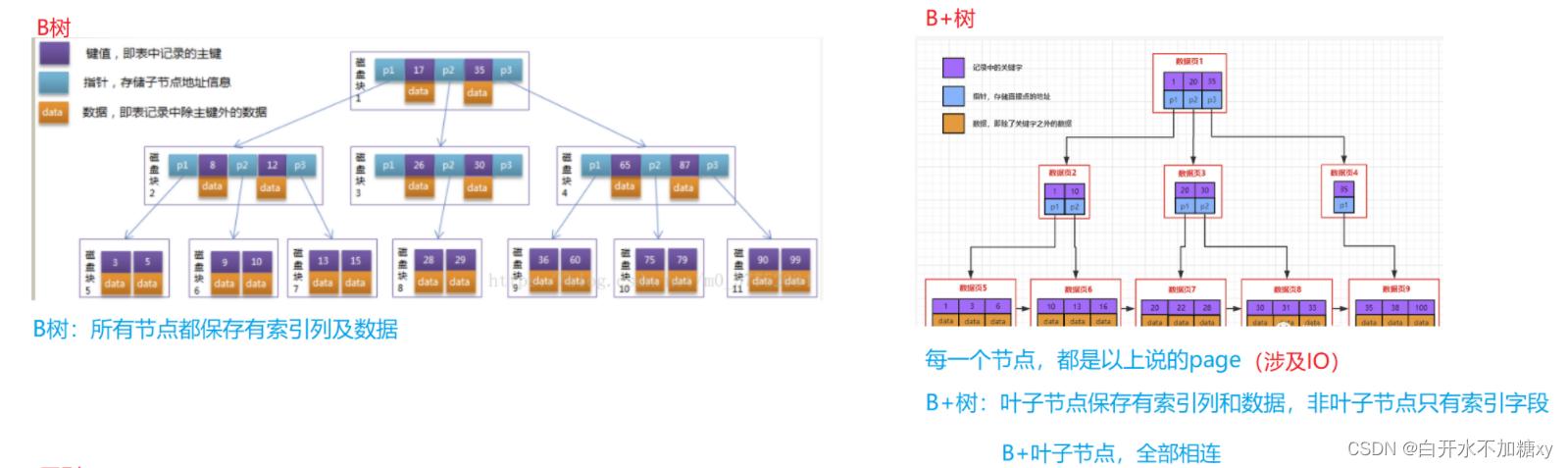
区别:
1. 数据的保存位置不同
B+树保存在叶子结点,B树保存在所有结点中。
体现了B+树优势:结点不存储数据,这样一个结点可以存储更多key,可使得树更紧凑,所以IO操作次数更少。
查询性能稳定:每次查询都是从根节点遍历到叶子节点,查询路径长度相同,即每次查询效率相当
2. 叶子节点的指向:
B+树相邻的叶子节点通过指针相连,B树没有
体现出B+树优势:所有叶子节点形成有序链表,便于范围查找
主键索引
默认是B+树,聚簇索引(一张表只能有一个主键索引)
B+树的叶子节点上,存放主键字段(索引字段)及数据

主键索引(聚簇索引)

优缺点:
优点: 速度快
缺点: 主键需要是整型,且字段不要太长。更新代价大(效率低)
非聚簇索引
非主键索引都是。可以使用很多种类型的索引,如B+树,Hash索引等。
假如用B+树,存储结构︰叶子节点:存放索引字段值+主键的值

age字段建立的B+树索引

搜索数据的方式:
(1)先通过索引字段,找到叶子节点上的主键值存在回表,意味着效率比主键索引慢
优缺点:
优点: 更新代价相对比聚簇索引小(叶子节点是索引值和主键值,没有真实数据)
缺点:
(1)也依赖有序数据
(2)可能产生回表操作导致效率会更低
覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为"覆盖索引"


检索的时候,是根据name索引字段来检索(name是在叶子节点,排序的),查询字段又没有其他字段,所以就不需要回表
复合索引/联合索引
涉及最左匹配原则︰联合索引的多个索引字段,遵循从左往右的优先级,最左优先,当出现范围查询(><between like等等)

优化
基于B+树的索引
1.主键索引(聚簇索引)2.非聚簇索引

hash索引
Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash 函数定位到数据所在的位置,这是B+树所不能比的。
hashmap存储数据的特性:键值对,无序,键唯一(不重复)
hashmap底层数据结构:数组+链表+红黑树!!

缺点:不支持顺序和范围查询
事务
事务的特性ACID


问题
(1)丢失更新 事务1修改数据的操作,在事务2修改以后,就覆盖掉(相当于丢失)

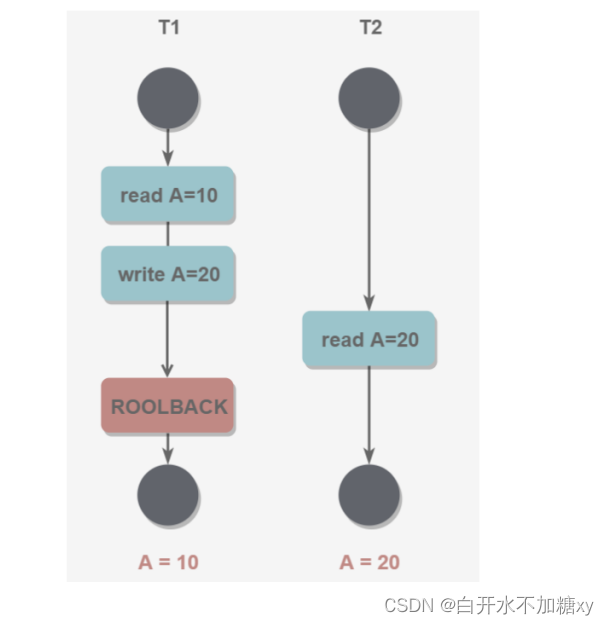
(2)脏读(第一个事务修改数据但没有提交,第二个事务就读取,在第一个事务回滚后,第二个事务读取的就是脏数据)
(3)不可重复读―一个事务两次读取数据,中间有另一个事务修改,第一个事务两次读取的数据就不同(不一致)

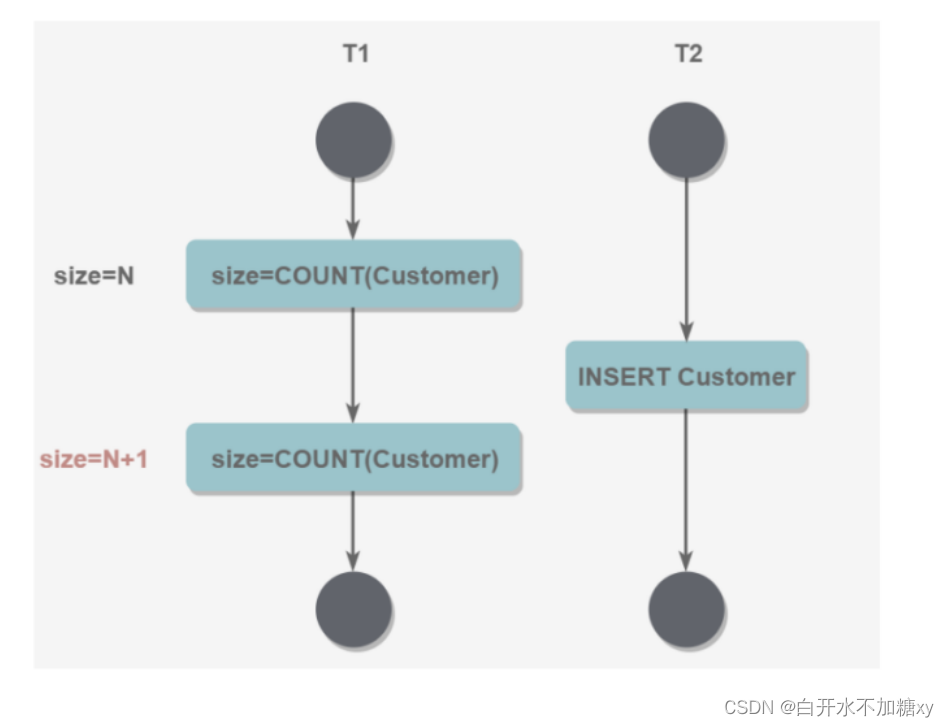
(4) 幻读 一个事务两次读取,中间有另一个事务执行了插入操作,造成第一个事务看到不同的结果
隔离级别
隔离级别!!!


![[附源码]Python计算机毕业设计Django农村人居环境治理监管系统](https://img-blog.csdnimg.cn/e326e60577f246e5bee10b16a1a0eb8d.png)






![[附源码]Python计算机毕业设计Django失物招领微信小程序论文](https://img-blog.csdnimg.cn/1e5cc57c26204824a12f9cca3f170aab.png)


![[附源码]计算机毕业设计失物招领微信小程序论文Springboot程序](https://img-blog.csdnimg.cn/ec010e2bc3ee48f19218aaaeff4c6925.png)
