问题
不管是在书本或者是博客上,都会推荐我们在重写 equals 方法时重写 hashCode 方法。明明对象之间就是通过 equals 方法进行判断的,那么为什么非要写 hashCode 方法呢?
equals 实验
创建一个 Teacher 类。方便起见,就一个 name 属性。
public class Teacher {
public Teacher() {
}
public Teacher(String name) {
this.name = name;
}
private String name;
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "Teacher{" +
"name='" + name + '\'' +
'}';
}
}
我们都知道,如果不重写 equals 方法,默认是通过 == 来比较两个对象,那么不是同一个对象肯定不相等。但是实际业务中,都是通过属性是否相等来判断两个对象是否为同一个。
重写 equals 前
@Slf4j
public class EqualsTest {
public static void main(String[] args) {
Teacher teacher1 = new Teacher("李四");
Teacher teacher2 = new Teacher("李四");
log.info("两个对象是否相同 ? {}", teacher1.equals(teacher2));
}
}

重写 equals 方法后
@Override
public boolean equals(Object o) {
if (this == o) { return true; }
if (!(o instanceof Teacher)) { return false; }
Teacher teacher = (Teacher) o;
return getName() != null ? getName().equals(teacher.getName()) : teacher.getName() == null;
}

可以看到,我们并没有重写 hashCode 方法,只是重写了 equals 方法,就能实现对象相等比较了呀,为啥还要用 hashCode? 关键就在于将对象存储在哈希(散列)集合中会出问题。
问题复现
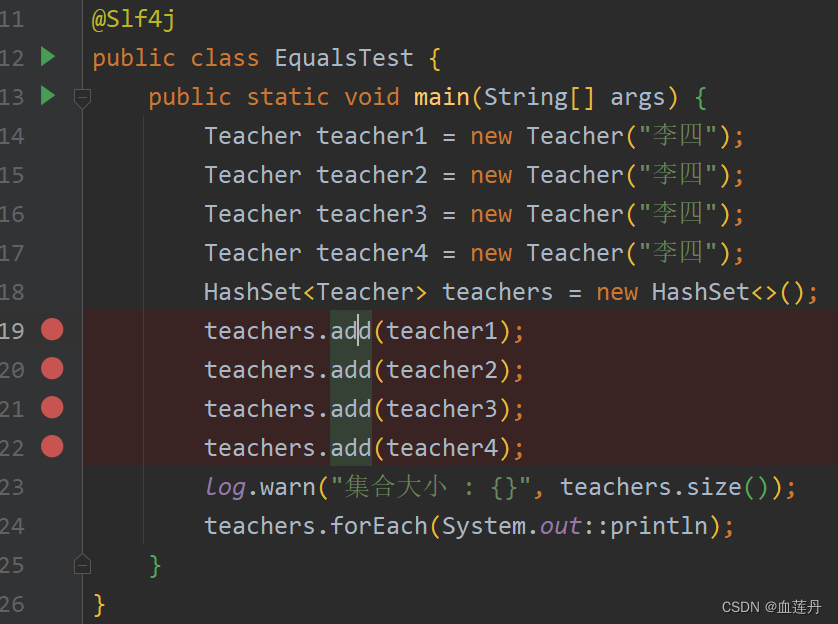
先看如下代码,想一下 Set 集合中最终有几个元素。
@Slf4j
public class EqualsTest {
public static void main(String[] args) {
Teacher teacher1 = new Teacher("李四");
Teacher teacher2 = new Teacher("李四");
Teacher teacher3 = new Teacher("李四");
Teacher teacher4 = new Teacher("李四");
Set<Teacher> teachers = new HashSet<>();
teachers.add(teacher1);
teachers.add(teacher2);
teachers.add(teacher3);
teachers.add(teacher4);
log.warn("集合大小: {}", teachers.size());
teachers.forEach(System.out::println);
}
}
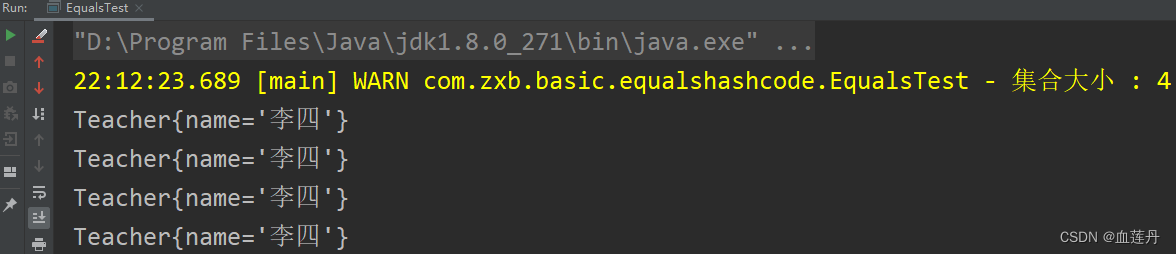 可以看到,HashSet 并没有去重,四个相同的对象,都保存进了 HashSet。这就是没有重写 hashCode 方法导致的结果。
可以看到,HashSet 并没有去重,四个相同的对象,都保存进了 HashSet。这就是没有重写 hashCode 方法导致的结果。
这里我先说结论:在 Java 中,当往哈希(散列)集合中添加元素时,先去判断 hashCode 值是否相同,如果不同,则直接插入。如果相同,才去判断 equals。
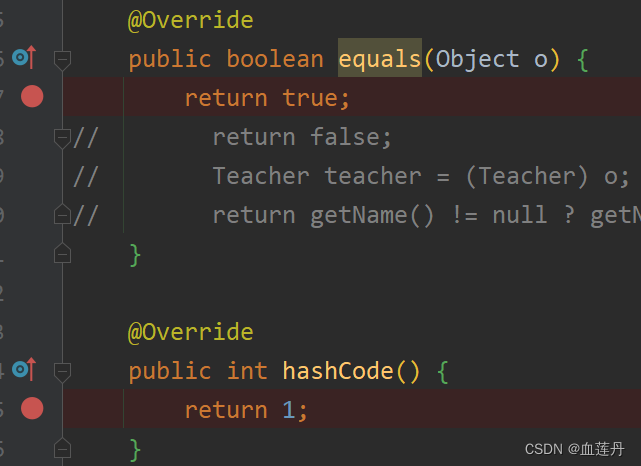
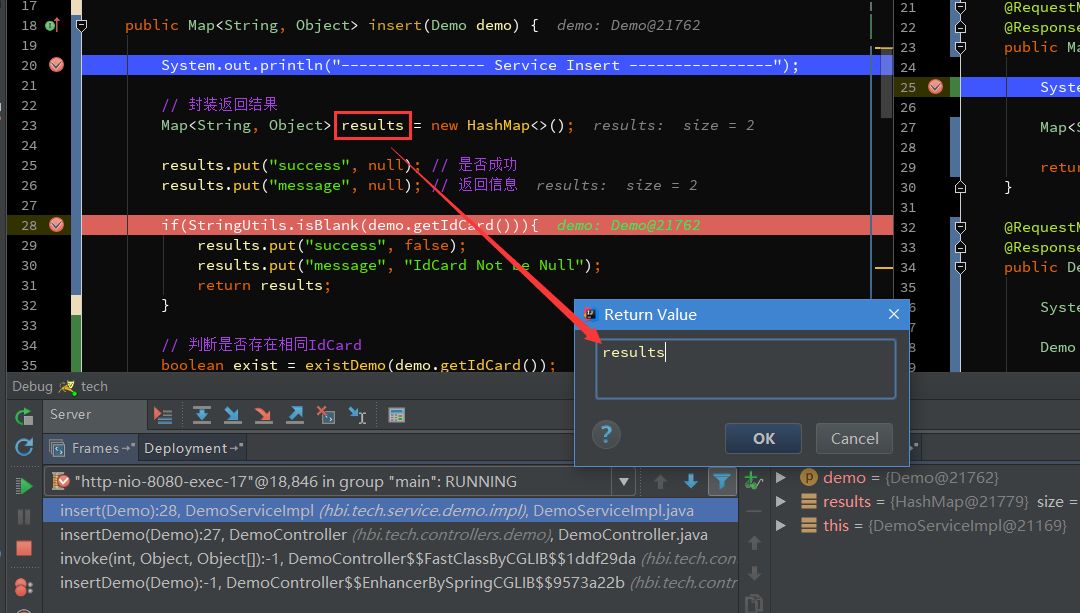
可以自己重写一个 hashCode 方法,比如写死返回 1。然后 equals 写死返回 false。然后在 add 方法,hashCode 方法,equals 方法上分别打上断点。那么此时集合中有四个 Teacher 对象。如果 equals 写死返回 true,则集合中只有一个对象。


![[附源码]计算机毕业设计失物招领微信小程序论文Springboot程序](https://img-blog.csdnimg.cn/ec010e2bc3ee48f19218aaaeff4c6925.png)


![[附源码]Python计算机毕业设计SSM健身俱乐部管理系统(程序+LW)](https://img-blog.csdnimg.cn/c898cf46a1d5486196d98442bcb7ca81.png)





![[附源码]Python计算机毕业设计SSM教师业绩考核和职称评审系统(程序+LW)](https://img-blog.csdnimg.cn/0d4d556e13204f9f9b7f751cc0ad0412.png)