刘昊 | 数据库工程师
最近手头有个系统,有需要搭建灾备库的需求(RTO要求4小时内,根据实际情况计算)。考虑到生产系统是5版本,TiCDC存在一些兼容性问题,且TiDB Binlog已经有实践案例及经验可供参考,故选择使用TiDB Binlog来实现主集群-->灾备集群的增量数据同步。数据全量初始化采用Dumpling + TiDB Lightning工具。
具体实施过程如下:
一、灾备集群部署
灾备集群搭建方案,采用与主集群1:1的方式进行部署,直接用现生产环境集群拓扑文件进行部署,部署完成后建用户并赋权,具体过程不再赘述。
二、主集群扩容pump
编辑生产集群扩容pump所需拓扑文件,内容如下
pump_servers:
- host: 10.3.31.1
ssh_port: 22
port: 8250
deploy_dir: /app/tidb/tidb-deploy/pump-8250
og_dir: /app/tidb/tidb-deploy/pump-8250/log
data_dir: /app/tidb/tidb-data/pump-8250
- host: 10.3.31.2
ssh_port: 22
port: 8250
deploy_dir: /app/tidb/tidb-deploy/pump-8250
log_dir: /app/tidb/tidb-deploy/pump-8250/log
data_dir: /app/tidb/tidb-data/pump-8250
- host: 10.3.31.3
ssh_port: 22
port: 8250
deploy_dir: /app/tidb/tidb-deploy/pump-8250
log_dir: /app/tidb/tidb-deploy/pump-8250/log
data_dir: /app/tidb/tidb-data/pump-8250编辑完成后,执行扩容命令
[tidb@tidb-test1 ~]$ tiup cluster scale-out tidb-test ./scale-out-pump.yaml -u tidb -p扩容完成后,最终会输出如下内容

三、开启主集群Binlog功能
执行edit-config命令,修改集群配置:
[tidb@tidb-test1 ~]$ tiup cluster edit-config tidb-test在server_configs下TiDB部分,添加如下配置
binlog.enable: true
binlog.ignore-error: true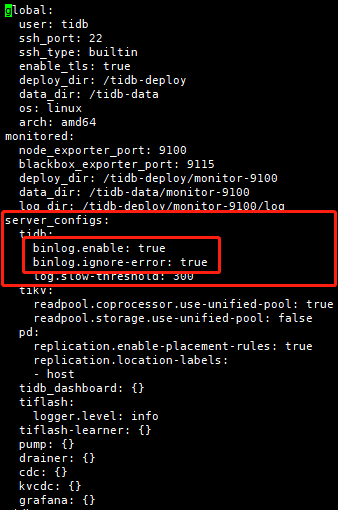
编辑完成后,reload tidb节点使配置生效
[tidb@tidb-test1 ~]$ tiup cluster reload tidb-test -R tidbreload完成后,会输出如下内容
四、主集群调整GC时间
登录数据库,执行如下sql:
set global tidb_gc_life_time = '360m';sql返回执行成功后,再次执行select @@tidb_gc_life_time;,查询结果输出为6h或360m,即为调整成功。
五、使用dumpling工具并将生产数据全量导出
[tidb@tidb-test1 ~]$ sudo mkdir $/dumpdir ($/dumpdir为导出数据存放目录,需确保空间充足)
[tidb@tidb-test1 ~]$ sudo chmod 777 $/dumpdir -R
[tidb@tidb-test1 ~]$ ./dumpling -u root -P 4000 -h 10.3.31.1 --filetype sql -t 8 -o $/dumpdir -r 200000 -F256MiB导出完成后,日志最终会输出["dump data successfully, dumpling will exit now"]字样,如下图所示:

六、将导出数据目录上传至灾备服务器,进行全量导入
第一步,使用lightning工具将数据全量导入
以下为运行lightning所需配置文件,因导入数据量大,建议开启断点
[lightning]
level = "info"
file = "tidb-lightning.log"
index-concurrency = 2
table-concurrency = 6
io-concurrency =20
[tikv-importer]
backend = "local"
sorted-kv-dir = "/home/tidb/sorted"
[mydumper]
data-source-dir = "$/dumpdir"
no-schema = false
filter = ['*.*']
[tidb]
host = "10.3.31.101"
port = 4000
user = "root"
password = ""
status-port = 10080
pd-addr = "10.3.31.101:2379"
[checkpoint]
enable = true
schema = "lightning-task-sql-checkpoint"
driver = "file"
[post-restore]
checksum = true
analyze = false第二步,开始导入
[tidb@tidb-test1 ~]$ nohup ./tidb-lightning --config lightning-full.toml &导入完成后,日志会输出["tidb lightning exit"],如图:

七、灾备集群扩容pump
编辑扩容pump所需配置文件
pump_servers:
- host: 10.3.31.101
ssh_port: 22
port: 8250
deploy_dir: /app/tidb/tidb-deploy/pump-8250
og_dir: /app/tidb/tidb-deploy/pump-8250/log
data_dir: /app/tidb/tidb-data/pump-8250
- host: 10.3.31.102
ssh_port: 22
port: 8250
deploy_dir: /app/tidb/tidb-deploy/pump-8250
log_dir: /app/tidb/tidb-deploy/pump-8250/log
data_dir: /app/tidb/tidb-data/pump-8250
- host: 10.3.31.103
ssh_port: 22
port: 8250
deploy_dir: /app/tidb/tidb-deploy/pump-8250
log_dir: /app/tidb/tidb-deploy/pump-8250/log
data_dir: /app/tidb/tidb-data/pump-8250上传完成后,执行如下命令扩容
[tidb@tidb-test1 ~]$ tiup cluster scale-out tidb-test ./scale-out-pump.yaml -u tidb扩容完成后,最终会输出如下内容
八、灾备集群开启Binlog功能
执行edit-config命令,修改集群配置文件
[tidb@tidb-test1 ~]$ tiup cluster edit-config tidb-test在server_config下tidb部分,添加如下配置
binlog.enable: true
binlog.ignore-error: true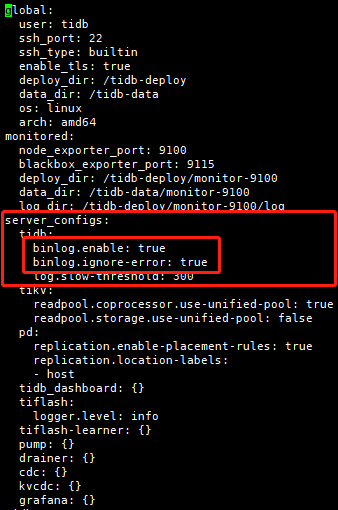
修改完成后,reload tidb节点使配置生效
[tidb@tidb-test1 ~]$ tiup cluster reload tidb-test -R tidbreload完成后,会输出如下内容
九、生产集群与灾备集群新建Drainer用户并授权
分别登录生产和灾备数据库,执行如下SQL,创建Drainer用户并授权
create user 'drainer'@'%' IDENTIFIED by 'Passwd@123';
grant select on . to 'drainer'@'%' with grant OPTION;
grant insert on . to 'drainer'@'%' with grant OPTION;
grant update on . to 'drainer'@'%' with grant OPTION;
grant delete on . to 'drainer'@'%' with grant OPTION;
grant create on . to 'drainer'@'%' with grant OPTION;
grant drop on . to 'drainer'@'%' with grant OPTION;
grant alter on . to 'drainer'@'%' with grant OPTION;
grant execute on . to 'drainer'@'%' with grant OPTION;
grant index on . to 'drainer'@'%' with grant OPTION;
grant create view on . to 'drainer'@'%' with grant OPTION;
Flush privileges;以上sql均返回成功后,执行show grants for 'drainer'@'%';确认drainer用户权限包含Insert、Update、Delete、Create、Drop、Alter、Execute、Index、Select、Create View权限。
十、灾备集群扩容Drainer(本地记录Binlog,实现增量备份)
编辑扩容Binlog所需配置文件
drainer_servers:
- host: 10.3.31.104
port: 18249
deploy_dir: /tidb-deploy/drainer-18249
data_dir: /tidb-data/drainer-18249
config:
syncer.db-type: "file"
syncer.to.host: "10.3.31.104"
syncer.to.dir: &binlog_dir(需手动创建,新建目录需将属主与属组改为tidb用)编辑完成后,执行如下命令扩容
[tidb@tidb-test1 ~]$ tiup cluster scale-out tidb-test ./scale-out-drainer.yaml --user tidb -p扩容完成后,最终会输出如下内容
十一、主集群扩容Drainer
编辑扩容Drainer所需配置文件
drainer_servers:
- host: 10.3.31.104
port: 8249
deploy_dir: /tidb-deploy/drainer-8249
data_dir: /tidb-data/drainer-8249
config:
initial-commit-ts: (dumpling导出metadata中的Pso)
syncer.db-type: "tidb"
syncer.to.host: "10.3.31.101"
syncer.to.user: "drainer"
syncer.to.password: "XXX"(密码为第9步新建的drainer用户密码)
syncer.to.port: 24000dumpling导出metadata中Pso查看方式:
导出数据目录中$/dumpdir ,会有一个metadata的文件,执行cat命令即可查看该文件中Pso,如图所示:

编辑完成后,执行如下命令扩容
[tidb@tidb-test1 ~]$ tiup cluster scale-out tidb-test ./scale-out-drainer.yaml --user tidb -p扩容完成后,最终会输出如下内容:
十二、检验同步链路是否搭建成功
分别访问集群监控(10.3.31.1:3000、10.3.31.101:3000),查询grafana监控面板中tidb-test-binlog-->drainer界面,如图:
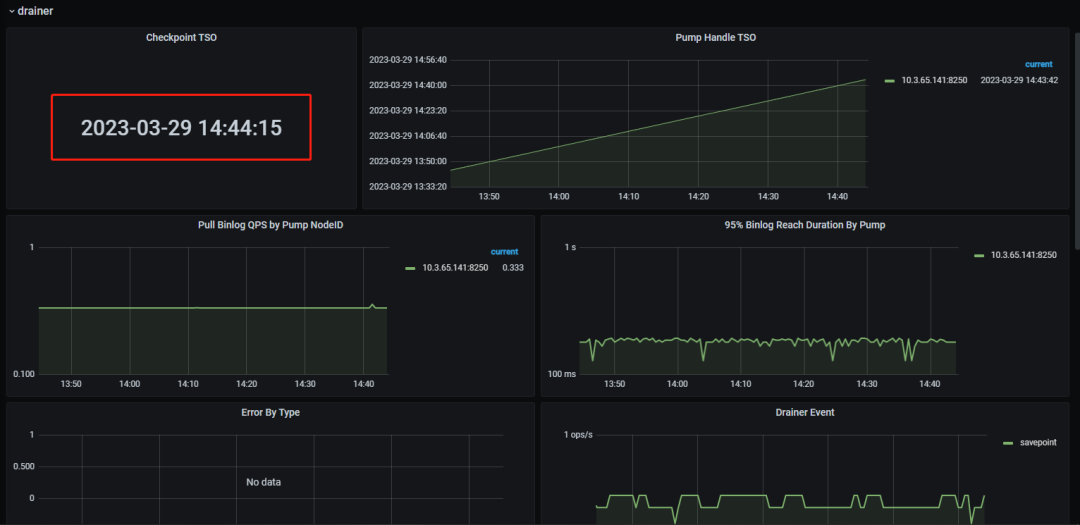
checkpoint正常推进,代表drainer同步链路正常工作。
在生产库新建test表或在原有test表中插入数据,在灾备库进行查询,如生产库执行的DDL或DML在灾备库能够查询到,证明生产库增量数据可通过同步链路同步至灾备库,生产-->灾备数据同步链路搭建成功。
十三、GC时间调整回原配置
登录数据库,执行如下SQL:
set global tidb_gc_life_time = '10m';sql返回执行成功后,再次执行select @@tidb_gc_life_time;,查询结果输出为1h或10m,即为调整成功。
至此TiDB Binlog搭建的集群数据同步链路搭建完成,数据同步成功。
部署过程中,需要注意的是drainer的initial-commit-ts参数,只能在部署的时候配置,无法在已有drainer节点上进行配置。后续运维过程中,需额外关注Skip Binlog Count监控指标,防止出现TiDB 写入 Binlog 失败的情况,如出现TiDB 写入 Binlog 失败,需及时进行处理。
各位路过大佬如果有相关方案及操作步骤改进建议,欢迎进群讨论。