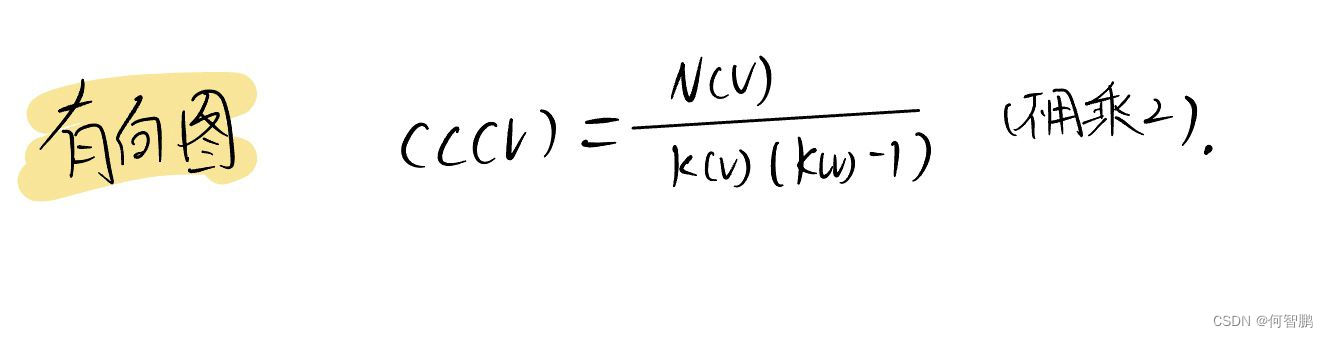序言
这里整理下聚合的优化选项 以及 数据类型
Stream Aggregation
SQL 是数据分析中使用最广泛的语言。Flink Table API 和 SQL 使用户能够以更少的时间和精力定义高效的流分析应用程序。此外,Flink Table API 和 SQL 是高效优化过的,它集成了许多查询优化和算子优化。但并不是所有的优化都是默认开启的,因此对于某些工作负载,可以通过打开某些选项来提高性能。
虽然在介绍TableApi 但是在StreamApi的算子上也可以借鉴他们优化的处理方式cuiyaonan2000@163.com
MiniBatch 聚合 #
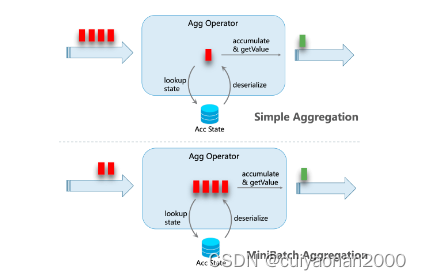
默认情况下,无界聚合算子是逐条处理输入的记录,即:(1)从状态中读取累加器,(2)累加/撤回记录至累加器,(3)将累加器写回状态,(4)下一条记录将再次从(1)开始处理。这种处理模式可能会增加 StateBackend 开销(尤其是对于 RocksDB StateBackend )。此外,生产中非常常见的数据倾斜会使这个问题恶化,并且容易导致 job 发生反压。
MiniBatch 聚合的核心思想是将一组输入的数据缓存在聚合算子内部的缓冲区中。当输入的数据被触发处理时,每个 key 只需一个操作即可访问状态。这样可以大大减少状态开销并获得更好的吞吐量。但是,这可能会增加一些延迟,因为它会缓冲一些记录而不是立即处理它们。这是吞吐量和延迟之间的权衡。---这中跟windows很像,就是根据一段时间来处理,那跟window是否有冲突呢cuiyaonan2000@163.com????
下图说明了 mini-batch 聚合如何减少状态操作。
代码中开启优化
// instantiate table environment
TableEnvironment tEnv = ...;
// access flink configuration
TableConfig configuration = tEnv.getConfig();
// set low-level key-value options
configuration.set("table.exec.mini-batch.enabled", "true"); // enable mini-batch optimization
configuration.set("table.exec.mini-batch.allow-latency", "5 s"); // use 5 seconds to buffer input records
configuration.set("table.exec.mini-batch.size", "5000"); // the maximum number of records can be buffered by each aggregate operator taskLocal-Global 聚合 #
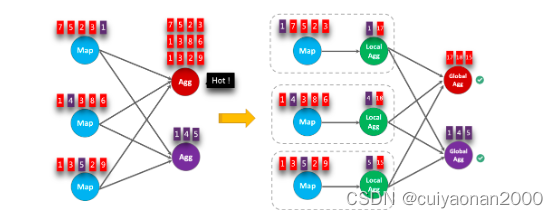
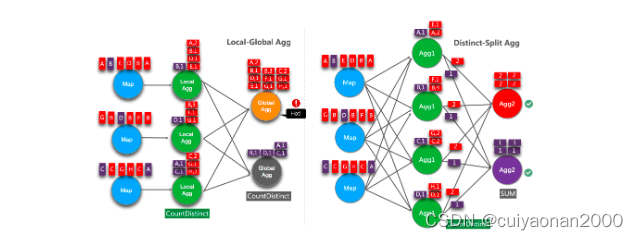
Local-Global 聚合是为解决数据倾斜问题提出的,通过将一组聚合分为两个阶段,首先在上游进行本地聚合,然后在下游进行全局聚合,类似于 MapReduce 中的 Combine + Reduce 模式。例如,就以下 SQL 而言:
SELECT color, sum(id)
FROM T
GROUP BY color数据流中的记录可能会倾斜,因此某些聚合算子的实例必须比其他实例处理更多的记录,这会产生热点问题。本地聚合可以将一定数量具有相同 key 的输入数据累加到单个累加器中。全局聚合将仅接收 reduce 后的累加器,而不是大量的原始输入数据。这可以大大减少网络 shuffle 和状态访问的成本。每次本地聚合累积的输入数据量基于 mini-batch 间隔。这意味着 local-global 聚合依赖于启用了 mini-batch 优化。
下图显示了 local-global 聚合如何提高性能。
代码开启,这个我们在streamApi中可以借鉴
// instantiate table environment
TableEnvironment tEnv = ...;
// access flink configuration
Configuration configuration = tEnv.getConfig().getConfiguration();
// set low-level key-value options
configuration.setString("table.exec.mini-batch.enabled", "true"); // local-global aggregation depends on mini-batch is enabled
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
configuration.setString("table.exec.mini-batch.size", "5000");
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE"); // enable two-phase, i.e. local-global aggregation拆分 distinct 聚合 #
Local-Global 优化可有效消除常规聚合的数据倾斜,例如 SUM、COUNT、MAX、MIN、AVG。但是在处理 distinct 聚合时,其性能并不令人满意。---是丢Local-Global的补充优化
例如,如果我们要分析今天有多少唯一用户登录。我们可能有以下查询:
SELECT day, COUNT(DISTINCT user_id)
FROM T
GROUP BY day
如果 distinct key (即 user_id)的值分布稀疏,则 COUNT DISTINCT 不适合减少数据。即使启用了 local-global 优化也没有太大帮助。因为累加器仍然包含几乎所有原始记录,并且全局聚合将成为瓶颈(大多数繁重的累加器由一个任务处理,即同一天)。
这个优化的想法是将不同的聚合(例如 COUNT(DISTINCT col))分为两个级别。第一次聚合由 group key 和额外的 bucket key 进行 shuffle。bucket key 是使用 HASH_CODE(distinct_key) % BUCKET_NUM 计算的。BUCKET_NUM 默认为1024,可以通过 table.optimizer.distinct-agg.split.bucket-num 选项进行配置。第二次聚合是由原始 group key 进行 shuffle,并使用 SUM 聚合来自不同 buckets 的 COUNT DISTINCT 值。由于相同的 distinct key 将仅在同一 bucket 中计算,因此转换是等效的。bucket key 充当附加 group key 的角色,以分担 group key 中热点的负担。bucket key 使 job 具有可伸缩性来解决不同聚合中的数据倾斜/热点。
拆分 distinct 聚合后,以上查询将被自动改写为以下查询:
SELECT day, SUM(cnt)
FROM (
SELECT day, COUNT(DISTINCT user_id) as cnt
FROM T
GROUP BY day, MOD(HASH_CODE(user_id), 1024)
)
GROUP BY day
下图显示了拆分 distinct 聚合如何提高性能(假设颜色表示 days,字母表示 user_id)。
开启代码
// instantiate table environment
TableEnvironment tEnv = ...;
tEnv.getConfig()
.set("table.optimizer.distinct-agg.split.enabled", "true"); // enable distinct agg split在 distinct 聚合上使用 FILTER 修饰符 #
在某些情况下,用户可能需要从不同维度计算 UV(独立访客)的数量,例如来自 Android 的 UV、iPhone 的 UV、Web 的 UV 和总 UV。很多人会选择 CASE WHEN,例如:
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT CASE WHEN flag IN ('android', 'iphone') THEN user_id ELSE NULL END) AS app_uv,
COUNT(DISTINCT CASE WHEN flag IN ('wap', 'other') THEN user_id ELSE NULL END) AS web_uv
FROM T
GROUP BY day
但是,在这种情况下,建议使用 FILTER 语法而不是 CASE WHEN。因为 FILTER 更符合 SQL 标准,并且能获得更多的性能提升。FILTER 是用于聚合函数的修饰符,用于限制聚合中使用的值。将上面的示例替换为 FILTER 修饰符,如下所示:
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('android', 'iphone')) AS app_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('wap', 'other')) AS web_uv
FROM T
GROUP BY day
Flink SQL 优化器可以识别相同的 distinct key 上的不同过滤器参数。例如,在上面的示例中,三个 COUNT DISTINCT 都在 user_id 一列上。Flink 可以只使用一个共享状态实例,而不是三个状态实例,以减少状态访问和状态大小。在某些工作负载下,可以获得显著的性能提升。