在使用 Redis 时,可能会出现请求响应慢、网络卡顿、数据丢失的情况。排查问题的时候,发现是 big keys 的问题。
什么是 big keys
在 Redis 中,一个字符串类型最大可以达到 512MB,其他非字符串类型的集合类型(list、set、hash、zset等)可以存储 40 亿个(2^32-1),但在实际业务场景中,并不需要这么大的内存。而且对于一个请求量大的互联网软件,对数据的大小要求更加的严格。如果达到如下标准,就可以认定是 big keys 了:
- String 类型的 key 对应的值超过 5 MB。
- list、set、hash、zset等集合类型,集合元素个数超过 2000。
以上对 big keys 的判断标准并不是唯一,只是一个大题的标准。在实际业务开发中,对 big keys 的判断是需要根据具体的使用场景做不同的判断。比如操作某个 key 导致请求响应时间变慢,那么这个 key 就可以判定成 big keys。
big keys 是如何产生的
一般来说,big keys 的产生都是由于程序的设计不当,或者对数据的规模没有一个大体的估算。比如:
- 统计类:例如统计某个网站的访问用户信息,网站的访问量越来越多,这个 key 的元素也会越来越大。变成了 big keys。
- 社交类:例如某个大V微博粉丝量很大,如果不做合理的设计,也是 big keys。
- 缓存类:一般缓存类的信息访问都比较频繁,是将从数据库查询出来的数据序列化到Redis缓存中,这里的缓存如果设计不当,或者为了方便,把所有的数据都存在一个 key 下,或者随着业务的扩大,对应的缓存也增多,也是形成 big keys。
以上几种类型都是在实际运维中遇到的。在开发中需要根据预估的数据大小来合理的设计缓存数据。
big keys 的危害
在系统中如果存在 big keys,会导致请求数据响应变慢、请求超时或者系统不稳定。
1、响应变慢、超时阻塞
Redis 是单线程工作的,同一时间只能处理一个请求,操作 big keys 时比较耗时,请求响应也变慢。其他请求也处于阻塞状态,导致请求超时。除了查询 big keys 比较耗时,删除 big keys 也会导致一样的问题。
2、网络拥塞
请求单个 big keys 产生的网络流量比较大,假设一个 big keys 为 1MB,客户端每秒访问量是 1000,那么每秒产生 1000MB 的流量,普通的千兆网卡承受不了这么大的流量。而且一般会在单机部署多个Redis实例,一个 big keys 可能也会影响其他实例。
3、内存分布不均
Redis 集群模式中,key根据不同的hash嘈分配到不同的节点上,当大部分的 big keys 分布在同一个节点,导致内存倾斜在同一个节点上,内存分布不均。在水平扩容时,需要以最大容量的节为准,浪费内存。
如何发现 big keys
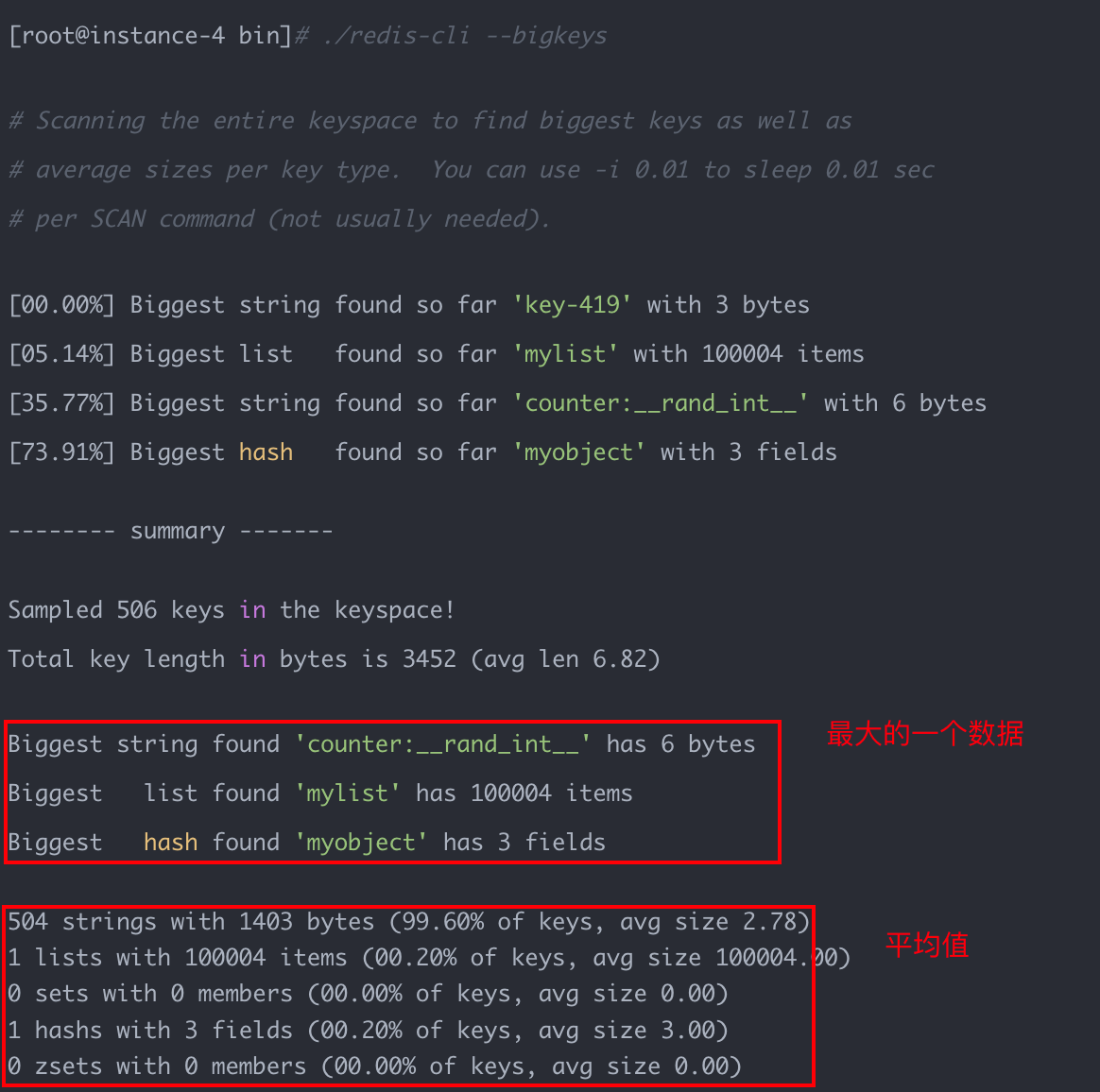
Redis4.0 后提供了 --bigkeys命令,比如:
./redis-cli --bigkeys
获取每个数据类型最大的 big keys,同时给出每个类型键的个数和平均大小。因为 Redis 是单线程工作的,为了减少对线上请求的影响,执行--bigkeys命令需要注意一下几点:
- 最好在 slave 节点执行,因为
--bigkeys也是扫描数据,会造成其他线程阻塞。 - 使用
--i参数,降低扫描的执行速度,比如--i 0.1表示 100 毫秒执行一次。 - 只能统计每个数据类型最大的数据。
big keys 处理
异步删除 big keys
找到 big keys 之后,首先需要删除对应的big keys,但是使用 del 命令删除 big keys 是比较耗时的。Redis4.0 后可以使用 unlink 删除,和 del 命令相比,unlink 是非阻塞的异步删除。
非字符串的 big keys,使用 hscan、sscan、zscan 方式渐进式删除,同时要注意防止big keys 过期时间自动删除问题(例如一个 200 万的 zset 设置1小时过期,会触发del操作,造成阻塞)。
big key 拆分
字符串类型的数据是减少字符串的长度,将一个字符串拆成几个小的字符串。非字符串的是减少元素数量。这些都是讲一个 key 拆成多个 key,比如:
- 字符串类型的数据,根据数据的属性拆分。比如商品信息,根据的类别拆分 key。
- 非字符串类型的数据,根据数据的属性拆分,可以按照日期拆分,比如每天登录人的集合,按照日期拆分,key20220101、key20220102.
如果 big keys 无法避免,那获取数据尽量不要把所有的数据都取出来,就使用分段的方式取出数据。删除的方式也类似,分段删除数据。
总结
- big keys 会造成请求变慢、网络阻塞、数据丢失的问题。
- big keys 是字符串字节达到很大的数量(比如 5MB),非字符串类型元素类型达到 1000 个都可以判定成 big keys,具体还需要看具体的场景。
- big keys 的产生可能由于设计不合理或者对数据大小估算错误,导致数据偏大。
- 解决 big keys 先紧急使用异步删除 unlink 命令删除缓存。然后将单个 key 拆分成多个小 key。
- 如果无法避免 big keys,就使用分段查询的方式查询数据。
- 要从几个方面分析,
- big keys 会带来哪些问题。
- big keys 一般怎么产生的,线上如果产生了big key,线上先怎么紧急处理。
- 有哪些优化方案,各自有什么应用场景。
参考
-
Scanning for big keys
-
Bigkey问题的解决思路与方式探索





![[附源码]Python计算机毕业设计Django酒店物联网平台系统](https://img-blog.csdnimg.cn/4ae069ba4c634d789d13f94019738230.png)