协同过滤:利用集体智慧,借鉴相关人群的观点进行推荐。
过去兴趣相似的用户在未来的兴趣也会相似;相似的用户会产生相似的历史行为数据。
根据历史行为,产生相似用户,分析出推荐结果。
用一句大白话说,其实也就是小明喜欢A、B,小红喜欢A、B、C,那么就可以推测出来小明也喜欢C,我们就可以给小明推荐C。
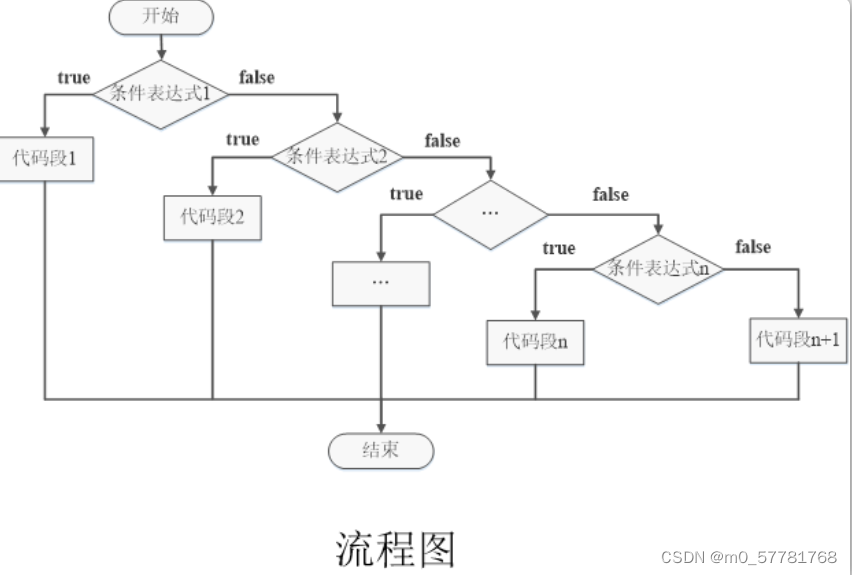
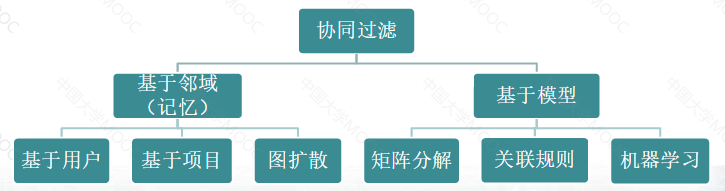
协同过滤算法的基本分类
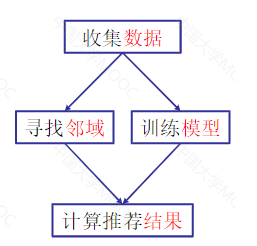
协同过滤算法的一般步骤
收集数据—>寻找邻域—>计算推荐结果
收集用户行为数据:
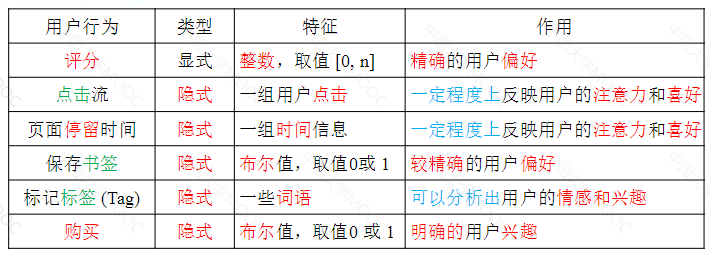
显示反馈:用户主动地向系统表达其偏好,一般需要用户在消费完项目后进行额外反馈。
隐式反馈:隐含用户对项目偏好的行为数据,是用户在探索或消费项目过程中正常操作。
User-CF基于用户的协同过滤
基本思想:基于用户对项目的历史偏好找到相邻(相似)的用户,将邻居(相似)用户喜欢的项目推荐给当前用户。
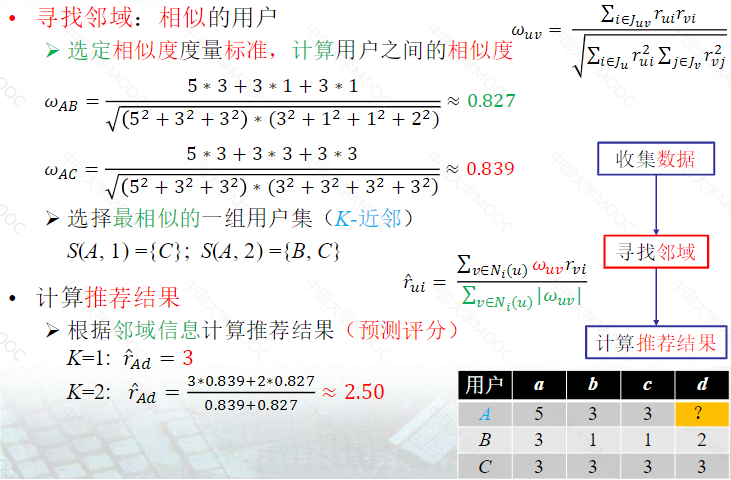
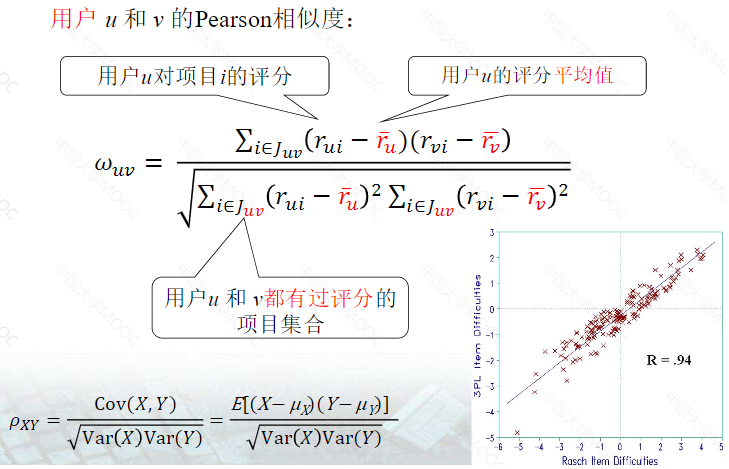
用户兴趣相似度的计算
Jaccard公式和余弦相似度公式,这两个公式仅仅是计算用户的兴趣相似度。

实例计算:(用户相似度)

兴趣度预测
(1)先求出与用户u最相似的K个用户
(2)

计算推荐结果:

基于User-CF的推荐系统
离线预处理:
(1)计算用户之间的相似度
(2)并据此确定每个用户的邻域(K近邻)
在线推荐:

用户相似度改进IUF
问题:用户A和B都买过《新华字典》;用户C和D都买过《操作系统》,那么哪组用户更相似呢?
显然是买操作系统的那组用户是更相似的,因为新华字典有很多人买,而操作系统是这个专业的。但如果用以上方法计算相似度,两组相似度是一样的,基于这样的弊端,做出了改建。
逆用户频率
基本思想就是:惩罚热门项目;两个用户对冷门项目有过同样行为更能说明他们的兴趣相似。
相似度计算公式得到改进:

基于用户的缺点
很多用户两两之间,只有很少的共同反馈,而仅有的共同反馈的项目,往往是热门项目,缺乏区分度。
随着用户行为数据的增加,用户间相似度可能变化很快,离线算法难以瞬间更新推荐结果。
基于物品的协同过滤Item-CF
基本思想:基于用户对项目的反馈(偏好),寻找相似(相关)的项目;根据用户的历史反馈(偏好)行为,为他推荐相似的项目。
就是说,我过去喜欢某类商品,将来还是喜欢这类商品。
项目的相似度计算

兴趣度预测

基于Item-CF的推荐系统
离线预处理:计算项目之间的相似度,并据此确定每个项目的邻域。
在线推荐:

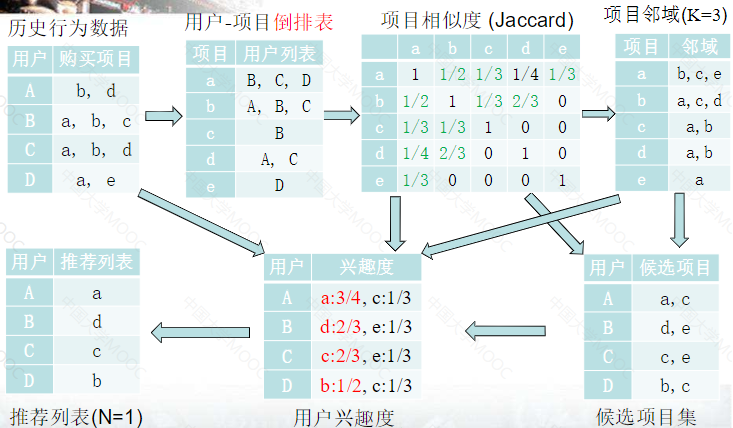
计算实例:
项目相似度改进
惩罚活跃用户
基本思想:越活跃的用户对项目相似度的贡献越小。

惩罚热门项目
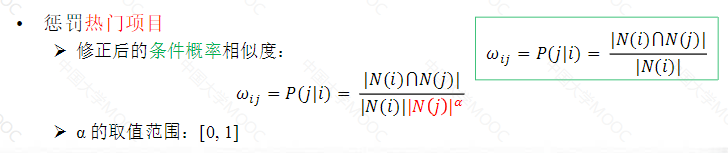
基于邻域的评分预测
这个就是计算对物品的评分。
余弦相似度(用户)

基于User-CF的评分预测
Pearson相似度(用户)

基于用户的或基于项目的评分预测修正
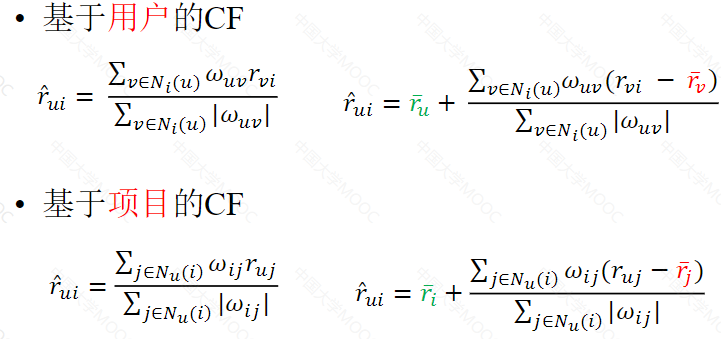

基于二部图的CF
传统邻域方法的缺点
范围限制问题:只考虑和用户有过共同评价(或购买)项目的相邻用户
计算空间复杂度较大:需在内存中保存整个用户-项目反馈(评分)集合(矩阵)
数据稀疏/冷启动问题:用户一般只会评价(或购买)少量项目
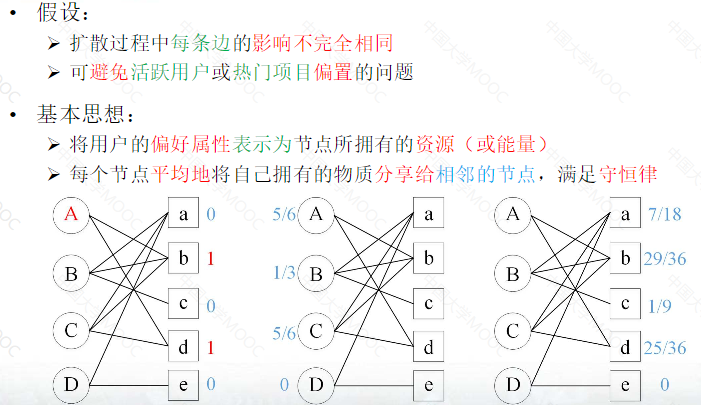
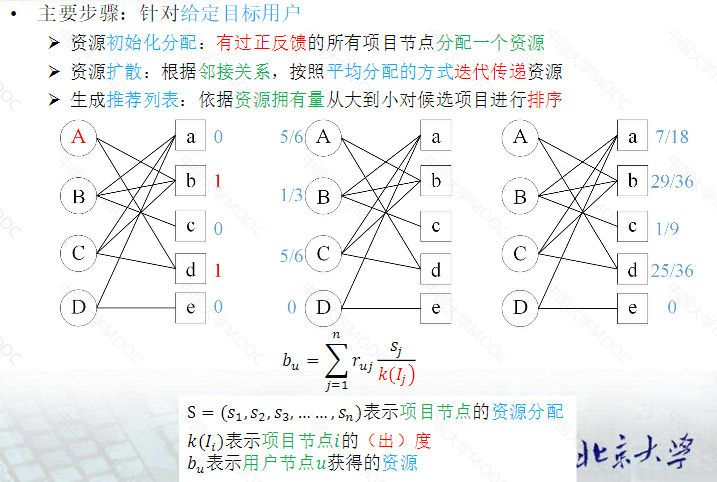
基于二部图的协同过滤

激活扩散



物质扩散

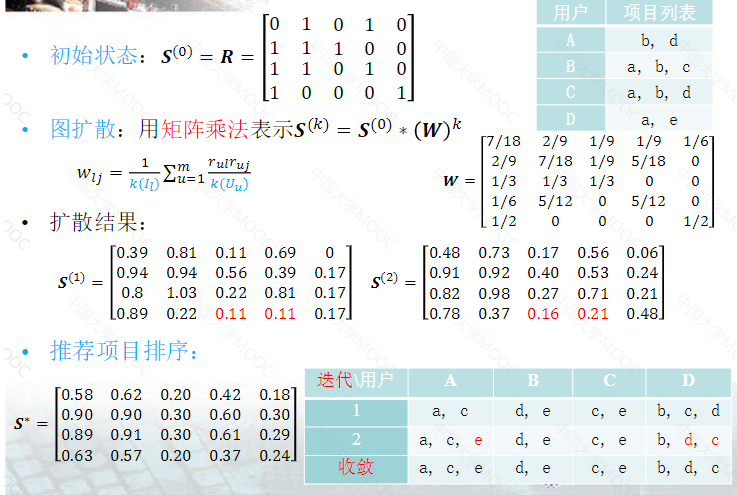
图扩散



![[附源码]Python计算机毕业设计Django酒店物联网平台系统](https://img-blog.csdnimg.cn/4ae069ba4c634d789d13f94019738230.png)