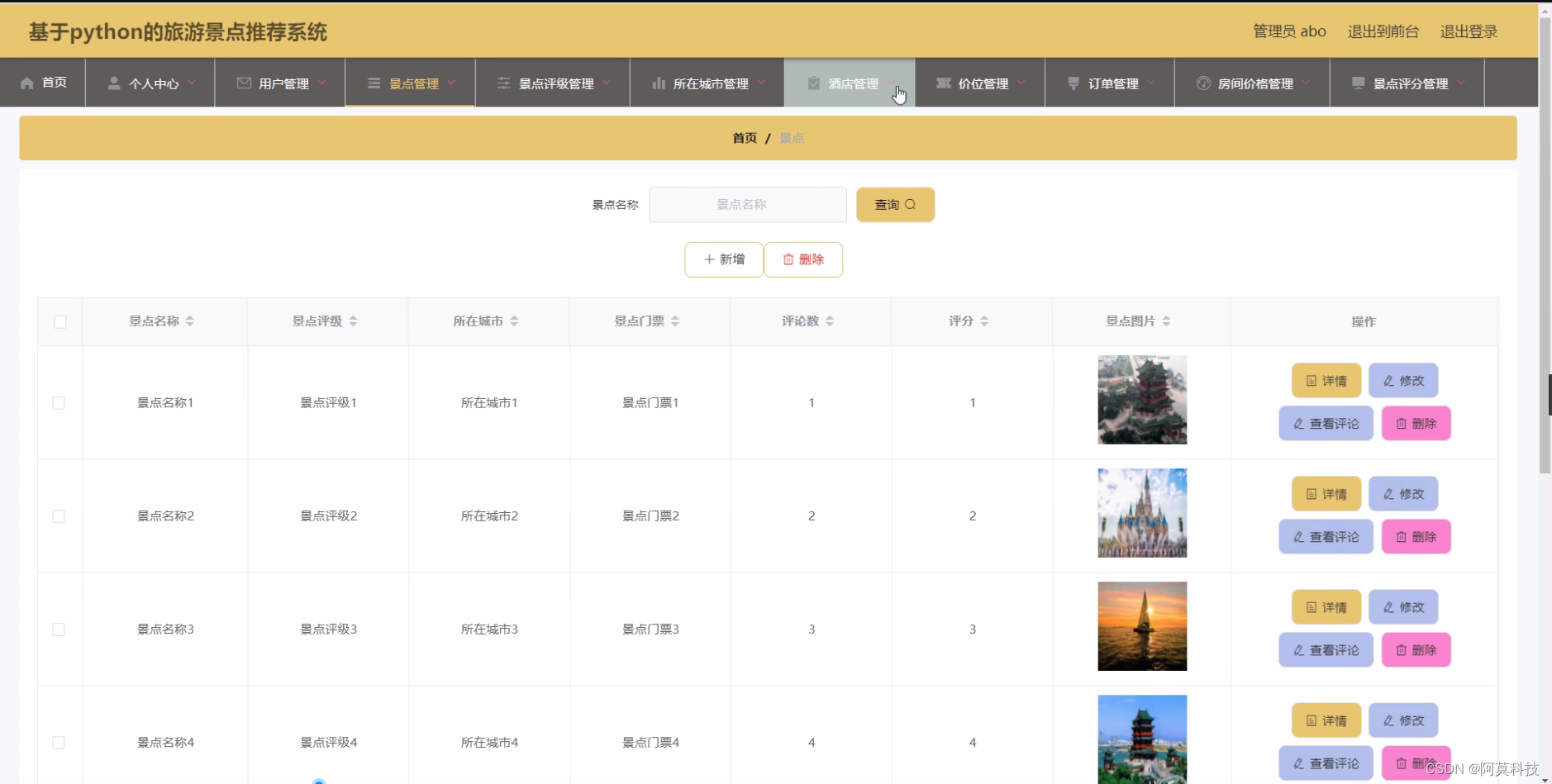
count
count 是MySQL的一个查询数量统计的函数,我们在平常的工作中经常会用到,count(*),count(id),count(1),count(字段)这4种写法有什么区别呢?
//星号
select count(*) from user;
//常数
select count(1) from user;
//id(主键)
select count(id) from user;
//字段
select count(name) from user;
这几种方式都可以查询出user表的个数,但是结果可能会不一样,为什么呢?
思考
为什么《阿里巴巴Java开发手册》中强制要求不让使用 COUNT(列名)或 COUNT(常量)来替代COUNT(*)呢?

因为count(*)是SQL92定义的标准统计行数的语法,
所以MySQL对他进行了很多优化,MyISAM中会直接把表的总行数单独记录下来供count(*)查询,而InnoDB则会在扫表的时候选择最小的索引来降低成本。当然,这些优化的前提都是没有进行where和group的条件查询。
count执行过程
根据mysql执行引擎的不同,count的执行过程也会不同,我们以count(*)为例来分别介绍二者的执行原理。
-
MyISAM引擎:这个引擎最大的特点是不支持事务,锁的话是表级锁,正是由于是表级锁,针对表的操 作都需要串联操作,不会出现两个或多个执行程序对一张表的同时操作,也就是说表的行数是稳定的,可维护的。针对count() 的操作,mysql自己了一个优化,类似于维护一份元数据信息,专门用来记录表的行数,这样每当有count()查询的时候就直接返回这个维护好的值,不需要再扫描全表了。所以它是一个O(1)复杂度的操作。
-
InnoDB引擎:支持事务支持行级锁,行级锁的特点是多个事务可以同时对一张表进行读写,只要是不 同的行就行。但是这样一来表的行数就会变化很快而不可维护,mysql本身也就无法专门维护一个值去记录表的行数了。所以针对count(*)的操作不得不扫描全表以返回一个准确的结果。这是一个O(n)复杂度的操作。
优化:虽然在InnoDB引擎下没有一个直接返回的结果,但是随着mysql版本的不断升级,官方还是做了许多优化的,主要是索引上的优化。从上面我们知道在这个引擎下不可避免的要扫描全表,所以我们也只能再扫描全面上下功夫。由于count(*)不关心具体的列,所以在扫描的过程中我们如果可以选择一个较低成本的索引的话就可以节省扫描的时间。在InnoDB中索引分为聚簇索引(主键索引)和非聚簇索引(非主键索引),聚簇索引的叶子节点中保存的是整行记录,而非聚簇索引的叶子节点中保存的是该行记录的主键的值。这种情况下是非聚簇索引要比聚簇索引小得多,所以在具体执行的过程如果有非聚簇索引的活mysql会自动选择在非聚簇索引的列上做统计,这样就能提高查询的速度。
备注:以上都是在SQL语句中没有where和group by等限定条件下的查询分析。
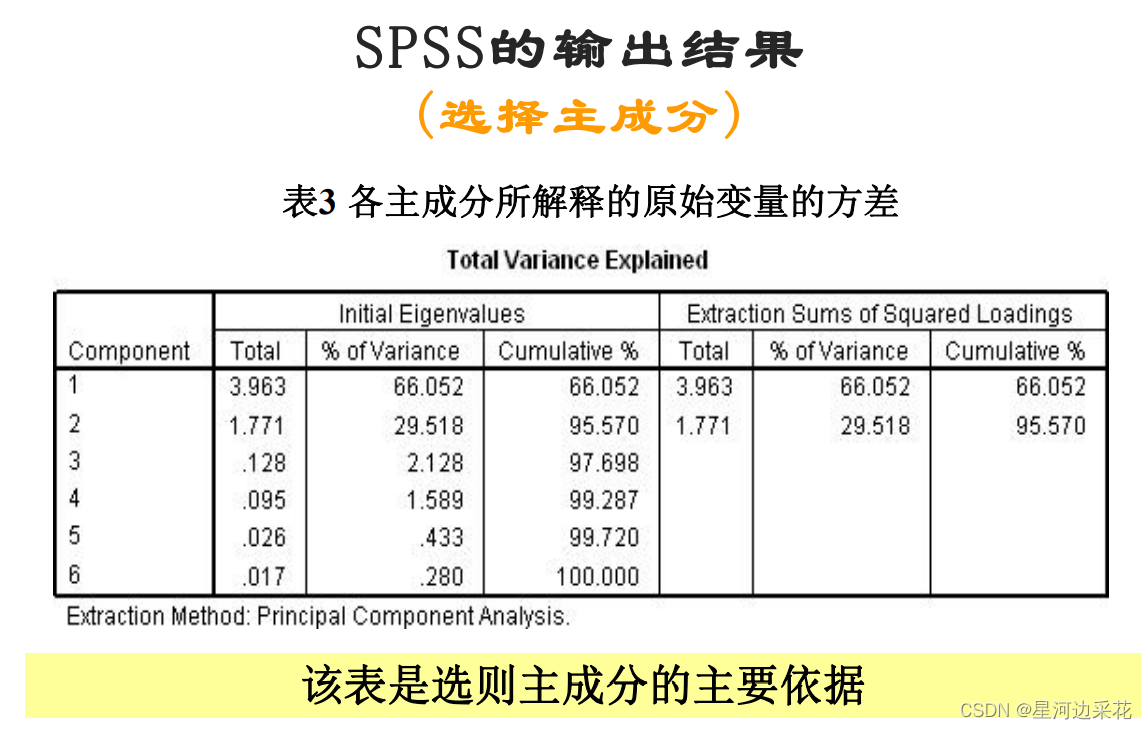
count(*)和count(1)的对比
首先这两者的执行结果是完全一致的,也可以把count(1)换成其他的数字如count(8)甚至是字符串如count(‘x’),都不会影响执行的结果。但是针对二者的执行过程,网上是众说纷纭,一种主流的观点是count()比count(1)快,原因是mysql针对 count( )这种操作做了特殊的优化;另外一种声音是count(1)比count()快,因为count()在执行过程中会先转为为count(1)然后在执行,直接count(1)的话少了一步转换操作,自然会快一些。那么哪种说更有道理呢?我们还是来看官方的说明:
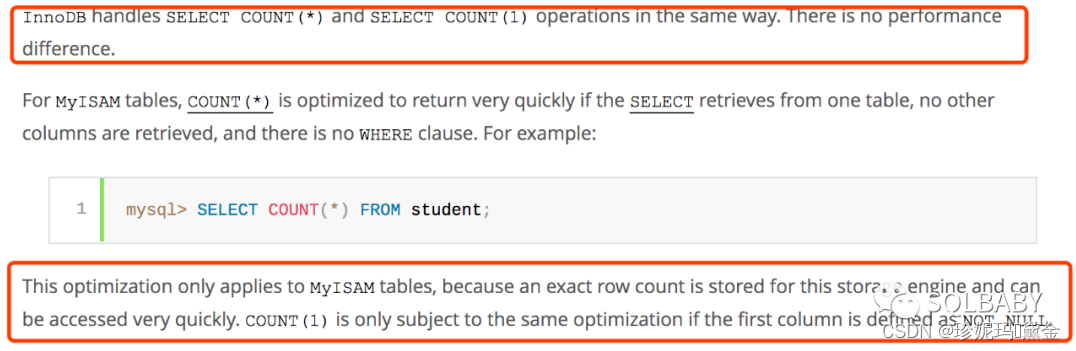
意思就是说对于InnoDB引擎来说count(*)和count(1)的底层操作是一致,在优化上是一致的,没有差异。所以结论就是二者的执行速度是一眼的,不存在孰优孰劣的差异。
不过对于MyISAM引擎来说,只有第一列的值全部不为null的时候,count(1)才和count(*)拥有相同的执行优化。
count(id)和count(字段)的对比
查id 和查字段实际上是一样的,都会查询出非空数据,并累加1,但是由于id是主键非空的,所以count(id) 的效率比count(字段)更快,count(字段)需要把判断是否为null
count执行结果
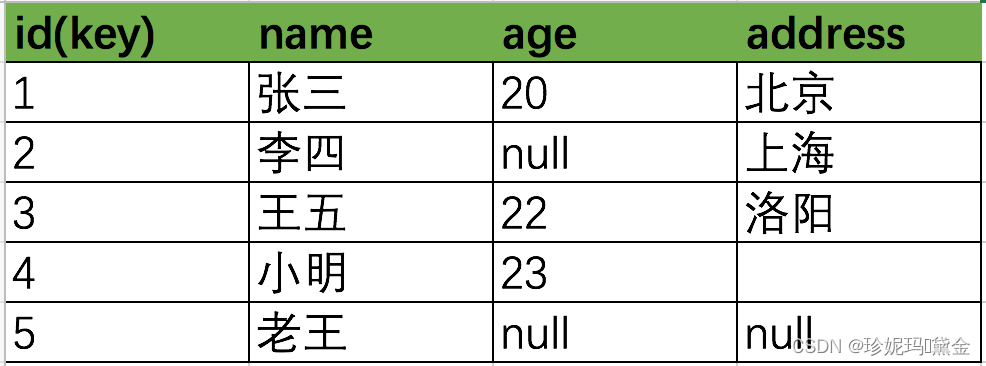
我们分别用这下列几种情况测试下
-
count(*)=5–统计全部的记录行数,包括为null的行
-
count(id)=5–按照主键统计所以行数,扫描全表统计
-
count(1)=5–统计全部的记录行数,包括为bull的行
-
count(name)=5–按照name列统计name不为null的记录行数
-
count(age)=3–按照age列统计age值不为null的记录行数
-
count(address)=3–按照address统计address不为null的记录行数
总结
-
执行速度上:针对一般情况(SQL语句中没有where条件)执行速度上
count(*)=count(1)>count(主键)>count(其他列),
在没有其他特殊要求的情况下推荐大家使用count(*)来代替其他的count。
-
执行结果上,count(*)与count(1)以及count(主键)的结果完全相同,即返回表中的所有行数,包含null 值;count(其他列)会排除掉该列值为null的记录,返回的值小于或者等于总行数。