🤵♂️ 个人主页:@Lingxw_w的个人主页
✍🏻作者简介:计算机科学与技术研究生在读
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、赛题背景
二、赛事任务
三、赛题数据
四、评价指标
五、Baseline解题思路
1、读取数据
2、数据预处理
3、LGBMRegressor
4、可视化
一、赛题背景
跨境电商广告 ROI(收入/广告消耗)预测一直以来都是效果类广告领域的重要挑战。在当前全球化背景下,海外媒体流量成本不断攀升,加之广告主对广告投入产出的关注日益加强,使得对广告投放效果的预测成为当下迫切需要解决的问题。
在解决这个问题过程中,人工智能和大数据技术发挥着至关重要的作用。通过对广告投放数据的深入分析,我们可以挖掘出潜在的规律和趋势,从而为广告主提供更精准的效果预测。这样的预测结果可以帮助广告主更好地制定广告策略,优化广告素材和投放时机,以提高整体营销效能。
二、赛事任务
本次大赛提供了讯飞AI营销旗下独立站电商业务的广告投放数据作为训练样本。参赛选手需基于所提供的数据样本构建预测模型,并在每天的前 13 小时内,每小时生成当日 ROI 的预测值。这将有助于检验选手模型在不同时间点的预测准确性,进而优化广告投放策略。
三、赛题数据
出于数据安全保证的考虑,所有数据均为脱敏处理后的数据。训练集提供了若干天中13点以前每小时的样本,每条记录以广告ID和日期作为标识,其特征数据包含该小时内各类广告指标信息,标签是该广告在当天的ROI。测试集的区别仅为每条记录不包含当天的ROI字段。具体的数据字段定义将随数据集一起提供。

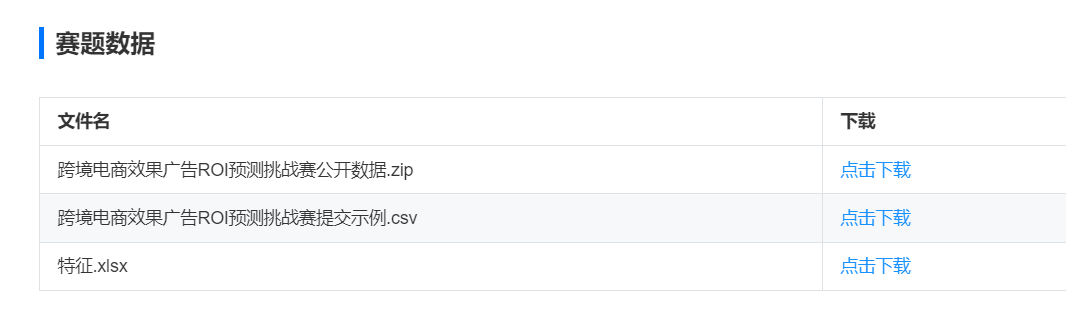 下载地址:Datamining_project: 数据挖掘实战项目代码
下载地址:Datamining_project: 数据挖掘实战项目代码
赛题数据集由三部分组成:
-
基础信息(用户、广告)
-
当前投放信息(广告)
-
累计投放信息(广告)
四、评价指标
依据提交的结果文件,采用加权平均绝对误差(Weighted Mean Absolute Error, WMAE)进行评价。
WMAE 的定义如下:
WMAE = (1/N) * Σ [w(t) * |y_true(t) - y_pred(t)|]
其中,N 是预测样本数量;w(t) 是时间加权因子,范围为 [0, 1],随着 t(当前小时)接近 12(一天中午以前)而递增。我们选用线性递增函数表示 w(t):w(t) = (t+1)/ 13,其中 t 为当前小时(0-12);y_true(t) 是真实的当天 ROI;y_pred(t) 是预测的当天 ROI。
通过使用 WMAE 作为评估指标,我们鼓励参赛者开发出在一整天各个时间点都表现良好的预测模型。排名将根据参赛者提交的预测结果的 WMAE 从低到高进行,WMAE 越低表示预测性能越好。请注意不要使用规则将每天其他小时的预测值用最后一小时预测值替代,任何利用数据泄露提交的结果,最终成绩都将被作废。
五、Baseline解题思路
赛题是一个比较典型的计算广告类型的题目,需要对ROI进行回归。但在题中包含了较多的ID类型,如用户ID和广告ID等。
此外赛赛题中还报告了时间因素,可从用户+广告的角度考虑进一步的特征工程。
导入需要的一些库;
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns1、读取数据
读取数据
train_data = pd.read_csv('跨境电商效果广告ROI预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('跨境电商效果广告ROI预测挑战赛公开数据/testA.csv')
train_data['datetime'] = pd.to_datetime(train_data['datetime'])
test_data['datetime'] = pd.to_datetime(test_data['datetime'])
train_data['datetime_hour'] = train_data['datetime'].dt.hour
test_data['datetime_hour'] = test_data['datetime'].dt.hour
train_data.drop('datetime', axis=1, inplace=True)
test_data.drop('datetime', axis=1, inplace=True)2、数据预处理
在训练模型之前,我们通常都要对训练数据进行一定的处理。将类别编号就是一种常用的处理方法,比如把类别“男”,“女”编号为0和1。可以使用sklearn.preprocessing中的LabelEncoder处理这个问题。
将n个类别编码为0~n-1之间的整数(包含0和n-1)。LabelEncoder
from sklearn.preprocessing import LabelEncoder
for col in ['ad_id', 'ad_set_id', 'campaign_id', 'product_id', 'account_id', 'post_id_emb', 'post_type', 'countries']:
lbl = LabelEncoder()
lbl.fit(list(train_data[col]) + list(test_data[col]))
train_data[col] = lbl.transform(list(train_data[col]))
test_data[col] = lbl.transform(list(test_data[col]))
3、LGBMRegressor
from lightgbm import LGBMRegressor
model = LGBMRegressor()
train_data['product_id_roi_mean'] = train_data['product_id'].map(train_data.groupby(['product_id'])['roi'].mean())
test_data['product_id_roi_mean'] = test_data['product_id'].map(train_data.groupby(['product_id'])['roi'].mean())
train_data['account_id_roi_mean'] = train_data['account_id'].map(train_data.groupby(['account_id'])['roi'].mean())
test_data['account_id_roi_mean'] = test_data['account_id'].map(train_data.groupby(['account_id'])['roi'].mean())
train_data['countries_roi_mean'] = train_data['countries'].map(train_data.groupby(['countries'])['roi'].mean())
test_data['countries_roi_mean'] = test_data['countries'].map(train_data.groupby(['countries'])['roi'].mean())
train_data['datetime_hour_roi_mean'] = train_data['datetime_hour'].map(train_data.groupby(['datetime_hour'])['roi'].mean())
test_data['datetime_hour_roi_mean'] = test_data['datetime_hour'].map(train_data.groupby(['datetime_hour'])['roi'].mean())
model.fit(
train_data.iloc[:].drop('roi', axis=1),
train_data.iloc[:]['roi'], categorical_feature=['ad_id', 'ad_set_id', 'campaign_id', 'product_id', 'account_id', 'post_id_emb', 'post_type', 'countries']
)
df = pd.read_csv('提交示例.csv')
df['roi'] = model.predict(test_data.iloc[:].drop('uuid', axis=1))
df.to_csv('submit.csv', index=None)4、可视化
# coding: utf-8
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
# 加载数据
print('加载数据...')
df_train = pd.read_csv('../data/regression.train.txt', header=None, sep='\t')
df_test = pd.read_csv('../data/regression.test.txt', header=None, sep='\t')
# 取出特征和标签
y_train = df_train[0].values
y_test = df_test[0].values
X_train = df_train.drop(0, axis=1).values
X_test = df_test.drop(0, axis=1).values
print('开始训练...')
# 直接初始化LGBMRegressor
# 这个LightGBM的Regressor和sklearn中其他Regressor基本是一致的
gbm = lgb.LGBMRegressor(objective='regression',
num_leaves=31,
learning_rate=0.05,
n_estimators=20)
# 使用fit函数拟合
gbm.fit(X_train, y_train,
eval_set=[(X_test, y_test)],
eval_metric='l1',
early_stopping_rounds=5)
# 预测
print('开始预测...')
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
# 评估预测结果
print('预测结果的rmse是:')
print(mean_squared_error(y_test, y_pred) ** 0.5)参考链接:
机器学习应用之LGBM详解 - 知乎
2023 iFLYTEK A.I.开发者大赛-讯飞开放平台
其他数据挖掘实战案例: [订阅链接]
【数据挖掘实战】——航空公司客户价值分析(K-Means聚类案例)
【数据挖掘实战】——中医证型的关联规则挖掘(Apriori算法)
【数据挖掘实战】——家用电器用户行为分析及事件识别(BP神经网络)
【数据挖掘实战】——应用系统负载分析与容量预测(ARIMA模型)
【数据挖掘实战】——电力窃漏电用户自动识别(LM神经网络和决策树)
【数据挖掘实战】——基于水色图像的水质评价(LM神经网络和决策树)