梳理一下之前理解不太清楚的知识点,重点内容可能会再拆出来单独研究。
原书链接:Index of /
一、 数据组织
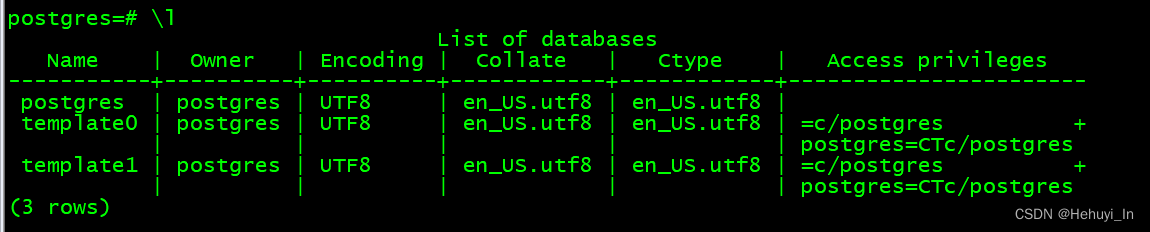
1. pg系统库
- template0:用于从逻辑备份还原,或创建不同字符集的数据库,不可以修改
- template1:真正的模板库,修改之后创建其他业务库时会以其为模板
- postgres:常规db,可以自行决定是否用作业务库(一般不用)
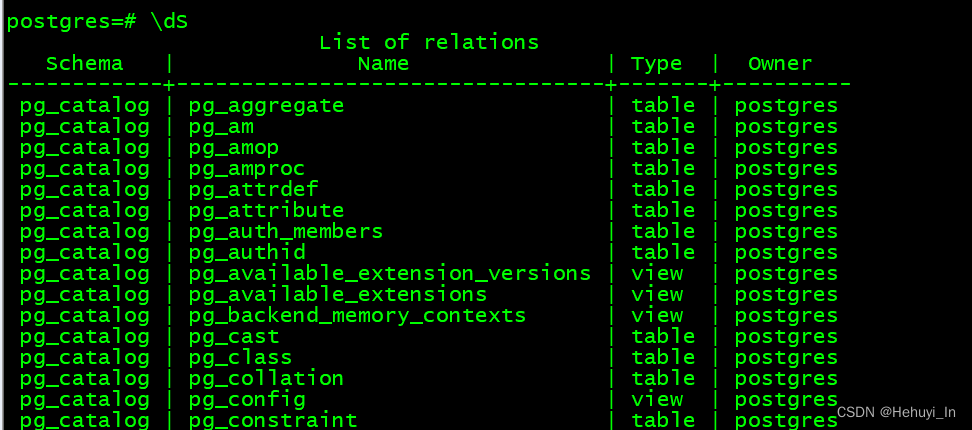
2. 系统表(system catalog)
- 均以pg_开头
- 部分系统表不属于任何数据库,但所有数据库均可访问它们
3. Schema
命名空间,在逻辑上相当于DB中的一个目录。
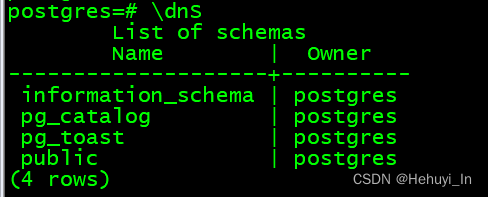
pg自带以下schema:
- public:若无特殊设置,则为用户对象默认schema
- pg_catalog:系统表的schema
- information_schema:系统表的替代视图
- pg_toast:用于toast对象
- pg_temp:用于临时表
search_path变量用于设置搜索路径,pg_catalog和pg_temp 这两个schema总是包含在其中(因此所有库中都能查到系统表和临时表),但默认不显示。
4. 表空间
如果说schema是逻辑上的目录,表空间则是物理上一个真正的目录,它与DB可以是多对多的关系。主要用于冷热数据分层,可以将旧数据放在单独表空间并移到低性能磁盘。
- pg_default:默认表空间,位于$PGDATA/base目录
- pg_global:存储共享系统表(system catalog)的表空间,位于$PGDATA/global目录
- 当用户创建表空间时,pg会自动在$PGDATA下创建同名目录,可以移到其他位置。

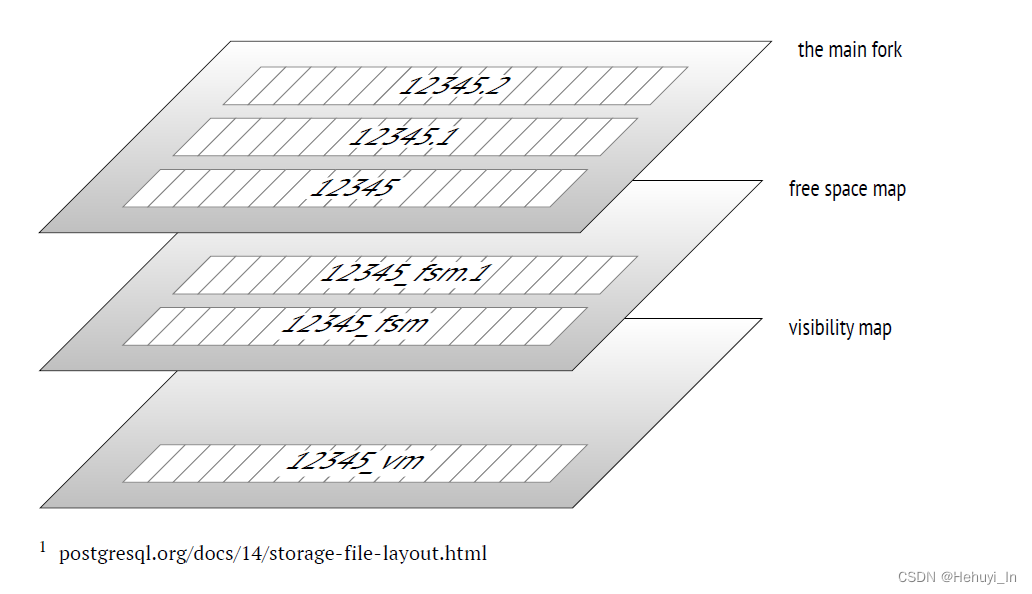
5. 数据文件与分支
- 主文件:存储实际数据,以一串数字为文件名(对应pg_class. relfilenode字段,注意不一定是oid),默认如果超过1G,则为扩展出xxx.1,xxx.2这种文件
- 空闲空间映射文件:fsm文件,保存页中可用空间的映射,在新数据插入时快速定位可用位置。既用于表也用于索引。
- 可见性映射文件:vm文件,如果一个页中的所有元组都是可见的(或者均已冻结),vm文件中会将两个对应标志位设为1。后续可以跳过对这些页的vacuum,freeze操作,提升性能,另外在执行计划中也可以使用 index-only scans,更加高效。只用于表不用于索引。
- 初始文件:init文件,仅对unlogged table可用
测试创建unlogged table
CREATE UNLOGGED TABLE t(a int);
INSERT INTO t VALUES (1);
SELECT pg_relation_filepath('t');
未完待续...


![[读论文] Monocular 3D Object Reconstruction with GAN inversion (ECCV2022)](https://img-blog.csdnimg.cn/30f8815ed56443b2b72dbb25dd7d32e2.png)