NumPy使用介绍
1.NumPy科学计算库介绍和环境准备
NumPy(Numerical Python)是Python的⼀种开源的数值计算扩展。提供多维数组对象,各种派⽣对象(如掩码数组和矩阵),这种⼯具可⽤来存储和处理⼤型矩阵,⽐Python⾃身的嵌套列表(nested list structure)结构要⾼效的多( 该结构也可以⽤来表示矩阵matrix ),⽀持⼤量的维度数组与矩阵运算,此外也针对数组运算提供⼤量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输⼊输出、离散傅⽴叶变换、基本线性代数,基本统计运算和随机模拟等等
-
⼏乎所有从事Python⼯作的数据分析师都利⽤NumPy的强⼤功能
- 强⼤的N维数组
- 成熟的⼴播功能
- ⽤于整合C/C++和Fortran代码的⼯具包
- NumPy提供了全⾯的数学功能、随机数⽣成器和线性代数功能
-
安装Python库
-
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple -
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple -
Jupyter Notebook是一款开发工具,基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果,经常可以大大增加调试代码效率
-
-
启动命令行终端
- Windows----> 快捷键:win + R ----->输⼊:cmd回⻋------>命令⾏出来
- Mac ---->启动终端
-
命令行终端中启动jupyter
-
进⼊终端输⼊指令:jupyter notebook
-
[注意]:在哪⾥启动jupyter启动,浏览器上的⽬录,对应哪⾥
-

启动后有几处需要注意:
-
会生成一个html连接文件,直接打开即可进入到jupyter操作界面( C:\Users\Administrator\AppData\Roaming\jupyter\runtime\nbserver-14956-open.html )
-
或者复制提供的连接进行访问,例如:http://localhost:8888/?token=3566fc51fefd4fb9528c5a131d7f0beb7cc8c171639fff14
-
token是用户验证的密钥信息
-
如果只打开了IP加8888端口,则在Password or token:中输入token验证,点击login即可登录
-
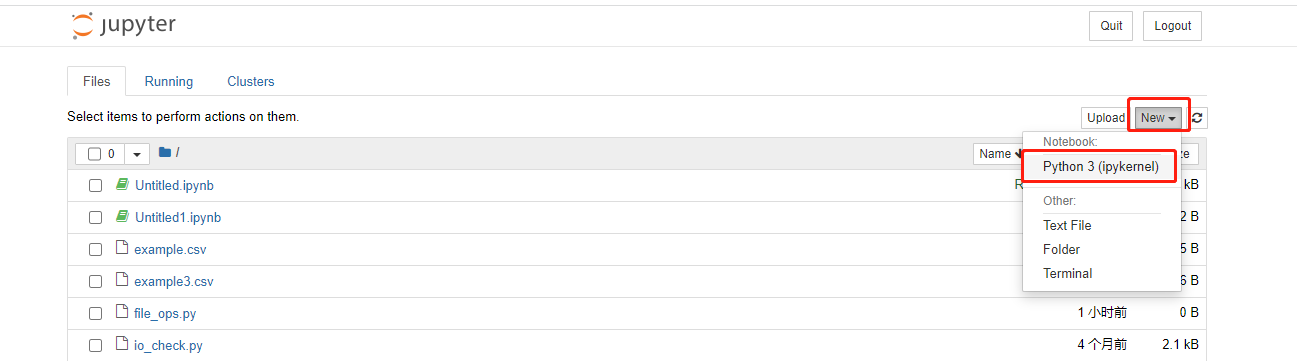
登录后可以在New选项中,创建一个目录、创建一个开发代码文件、开发代码交互界面
初次感受jupyter:
jupyter最常用快捷键
shift + tab 函数用法介绍
tab键,代码补全
alt + enter,运行当前单元,并在下方插入一单元
ctrl + enter,运行当前单元,光标依然在当前单元格
esc 后 b键,在下方插入 ,a键,在上方插入单元
esc 后 2次d键,删除当前单元格帮助中有全部快捷键大全
对比pycharm:
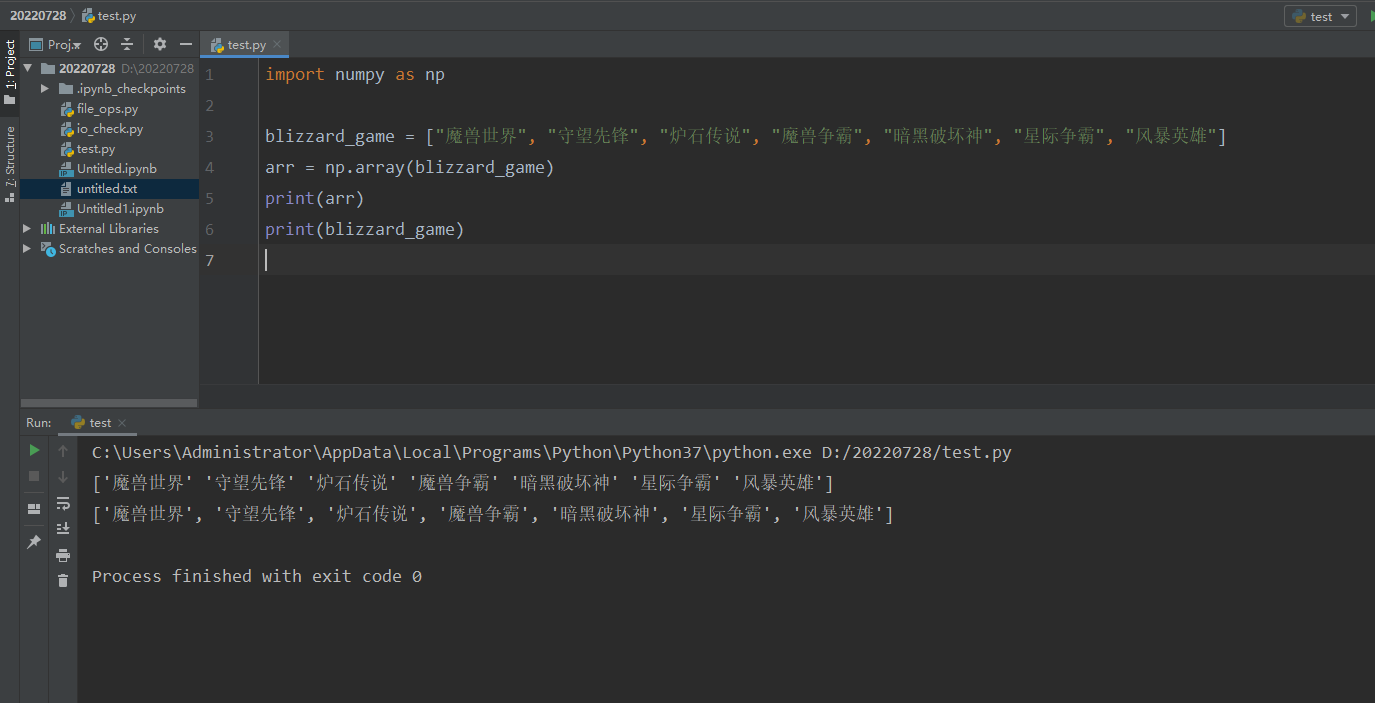
功能代码最终都可以实现功能,jupyter相对可以快速部署使用,引用变量即可OutPut输出;有些地方为了代码展示会使用pycharm更方便,所以后续都会使用到。
2.NumPy基本操作
2-1.创建数组
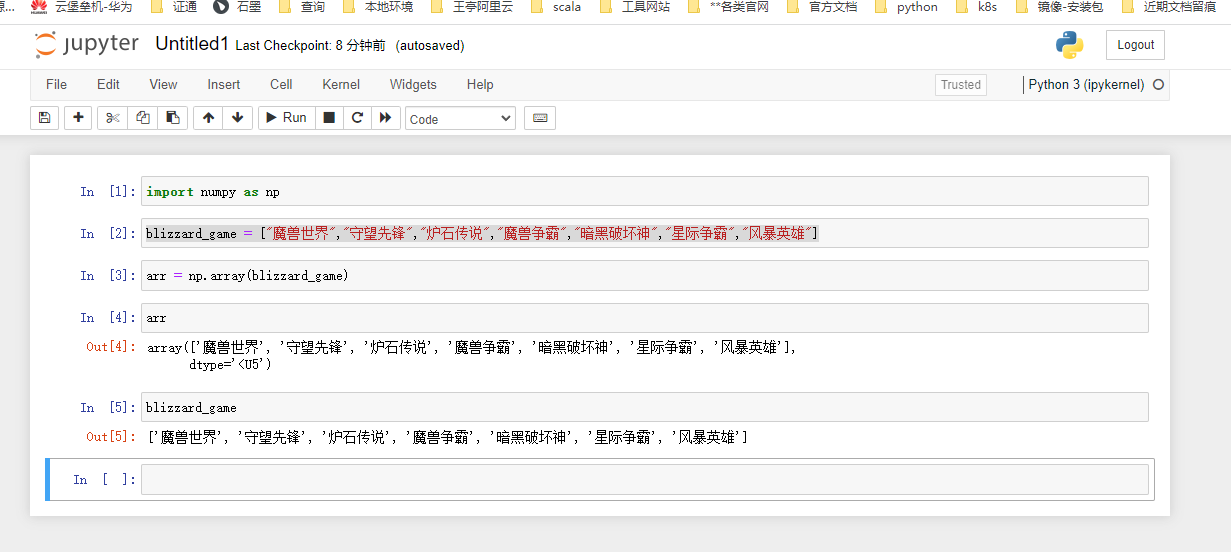
创建数组的最简单的⽅法就是使⽤array函数,将Python下的list转换为ndarray
例如上方的代码
import numpy as np
blizzard_game = ["魔兽世界", "守望先锋", "炉石传说", "魔兽争霸", "暗黑破坏神", "星际争霸", "风暴英雄"]
arr = np.array(blizzard_game)
arr
blizzard_game
numpy.array() 将列表转换为NumPy数组
从输出的内容看,数据是⼀样的
但是随着后续的使用会慢慢了解到同样的内容,NumPy数组的⽅法,功能更加强⼤,要比list能实现更多强大的功能
[注意]:np 和 numpy 后续都指numpy库模块,只是别名并无区别
我们可以利⽤np中的⼀些内置函数来创建数组,⽐如我们创建全0的数组,也可以创建全1数组,全是其他数字的数组,或者等差数列数组,正态分布数组,随机数。
- 创建n个0或者n个1的数组
import numpy as np
arr1 = np.zeros(5)
arr2 = np.ones(5)
print(arr1)
print(arr2)
""" 输出
[0. 0. 0. 0. 0.]
[1. 1. 1. 1. 1.]
"""
- 创建以某个值 x行y列的数组
import numpy as np
arr = np.full(shape=[2, 4], fill_value="暴雪凉凉了")
print(arr)
""" 输出
[['暴雪凉凉了' '暴雪凉凉了' '暴雪凉凉了' '暴雪凉凉了']
['暴雪凉凉了' '暴雪凉凉了' '暴雪凉凉了' '暴雪凉凉了']]
"""
shape=[2, 4] 行、列
fill_value 创建的内容
- 创建等差数列型数组
import numpy as np
arr = np.arange(start=0, stop=30, step=5)
print(arr)
""" 输出
[ 0 5 10 15 20 25]
"""
- 创建int随机整数数组
import numpy as np
arr = np.random.randint(1, 7, size=6)
print(arr)
""" 输出
[5 5 5 1 3 3]
"""
传入3个参数分别对应为
low 最小区间,包含low值
high 最大区间,不包含high值
size 取几个值
- 创建正态分布和随机数数组
import numpy as np
arr1 = np.random.randn(6)
arr2 = np.random.random(size=6)
print(arr1)
print(arr2)
""" 输出
[-1.31009666 1.26289427 -0.90216964 -0.52891451 -0.02613398 2.99314766]
[0.5897261 0.53644782 0.54970934 0.60330606 0.02733836 0.80834182]
"""
使用random.random函数会返回一个[0.0,1.0)之间的随机数值,zise定义输出个数;
而random.randn函数是返回一个标准正太分布数值,即理论上是(负无穷,正无穷)。实际上是在数值0附近徘徊
2-2.查看操作
NumPy的数组类称为ndarray,也被称为别名 array。请注意,numpy.array这与标准Python库类不同array.array,后者仅处理⼀维数组且功能较少
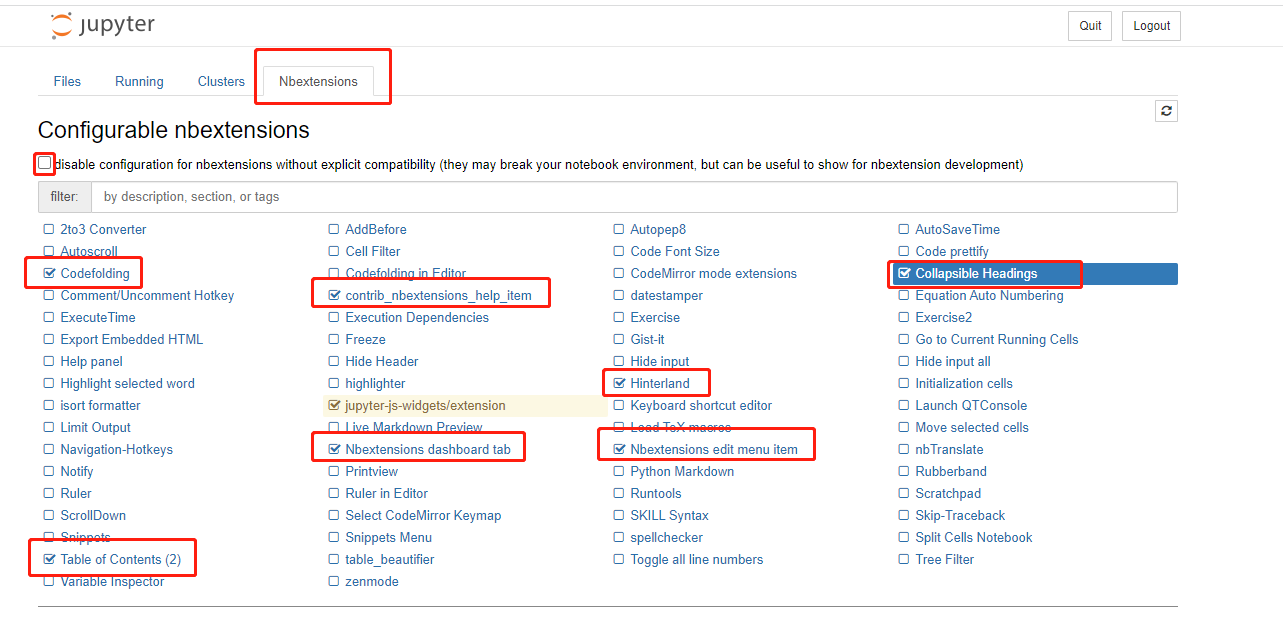
- jupyter扩展插件
pip install jupyter_contrib_nbextensions -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install jupyter_nbextensions_configurator -i https://pypi.tuna.tsinghua.edu.cn/simple
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user
- jupyter_contrib_nbextensions
- 这个包能够对jupyter notebook进行扩展,丰富它的功能,比如函数代码的收叠,对于较长的notebook也可以通过它添加左边目录栏,便于定位
- JupyterNbExtensions Configurator
- 是Jupyter Notebook的一个扩展工具,只需勾选相应插件就能自动载入。可以让你在Jupyter Notebook上的工作效率进一步的提高
这样新启动的jupyter book会多一个新的菜单分页Nbextensions
可以理解成有一些其它工具例如pycharm等比较好的功能通过扩展插件来实现,扩展工具可以不安装,
- 查看数组的轴数、维度
import numpy as np
arr = np.random.randint(0, 100, size=(3, 4, 5))
print(arr.ndim)
""" 输出
3
"""
- 查看数组尺寸形状
import numpy as np
arr = np.random.randint(0, 100, size=(3, 4, 5))
print(arr.shape)
""" 输出
(3, 4, 5)
"""
3组 4行 5列
- 查看数组元素的总数
import numpy as np
arr1 = np.random.randint(0, 100, size=(3, 4, 5))
arr2 = np.random.randint(0, 100, size=(1, 2, 6))
print(arr1.size)
print(arr2.size)
""" 输出
60
12
"""
数组元素的总数相当于各维度的乘积
60 = 3 * 4 * 5
12 = 1 *2 * 6
- 查看数组的数据类型
import numpy as np
arr = np.random.randint(0, 100, size=(3, 4, 5))
print(arr.dtype)
""" 输出
int32
"""
- 查看数组中每个元素的大小
import numpy as np
arr = np.random.randint(0, 100, size=(3, 4, 5))
print(arr.itemsize)
""" 输出
4
"""
数据类型为int32,⼀个字节是8位,相除得出4
2-3文件IO操作
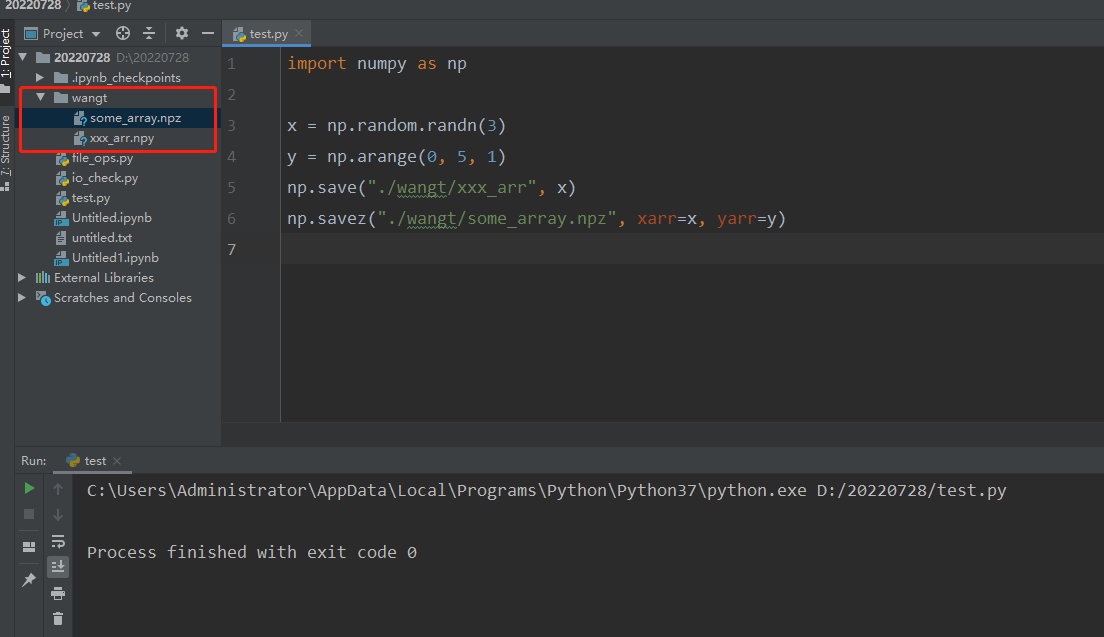
- 保存数组
save⽅法保存ndarray到⼀个npy⽂件,也可以使⽤savez将多个array保存到⼀个.npz⽂件中
import numpy as np
x = np.random.randn(3)
y = np.arange(0, 5, 1)
np.save("./wangt/xxx_arr", x)
np.savez("./wangt/some_array.npz", xarr=x, yarr=y)
通过jupyter创建:


- 读取数组
使用load⽅法来读取存储的数组,如果是.npz⽂件的话,读取之后相当于形成了⼀个key-value类型的变量,通过保存时定义的key来获取相应的array
import numpy as np
np.load('./wangting/xxx_arr.npy')
print(np.load('./wangting/some_array.npz')['yarr'])
""" 输出
[0 1 2 3 4]
"""
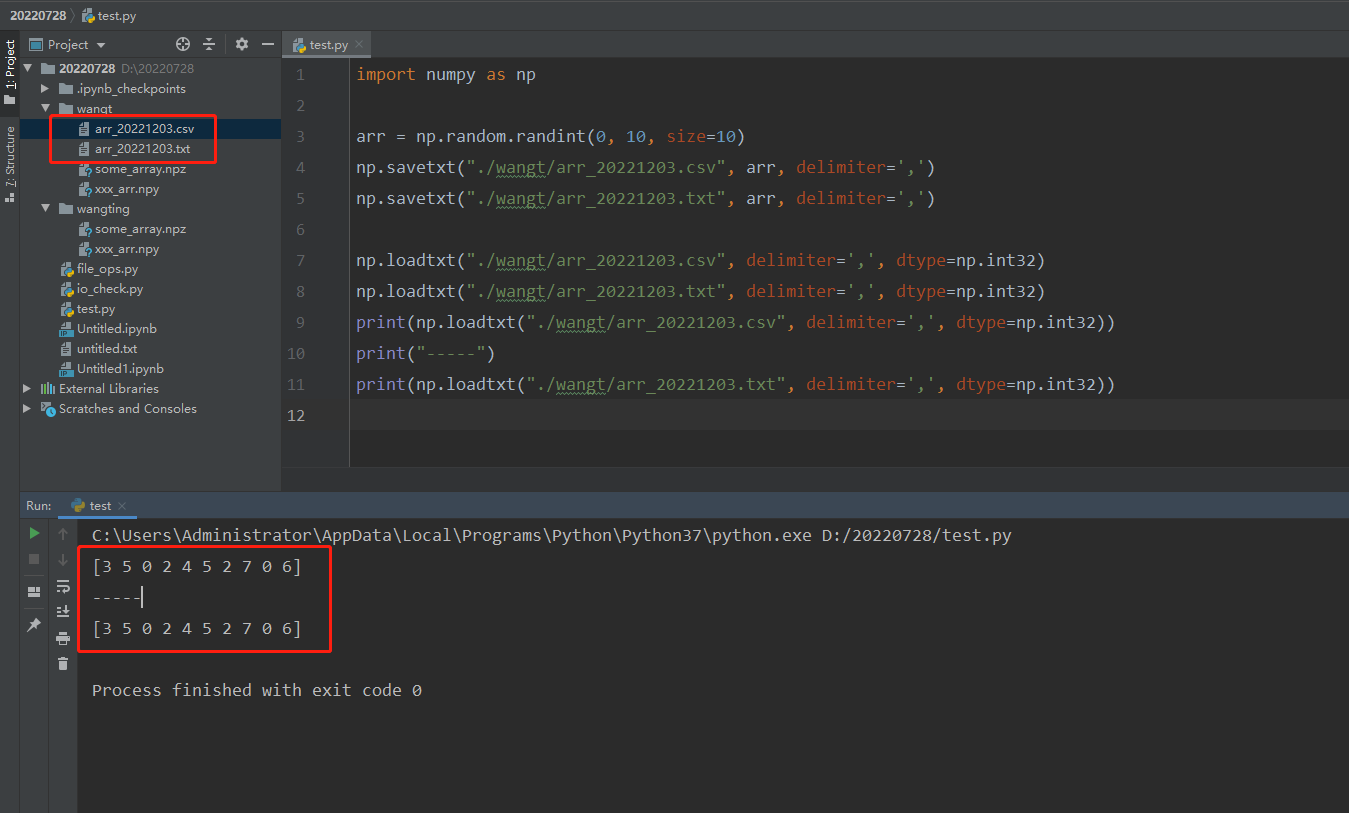
- 读写csv、txt文件
import numpy as np
arr = np.random.randint(0, 10, size=10)
np.savetxt("./wangt/arr_20221203.csv", arr, delimiter=',')
np.savetxt("./wangt/arr_20221203.txt", arr, delimiter=',')
np.loadtxt("./wangt/arr_20221203.csv", delimiter=',', dtype=np.int32)
np.loadtxt("./wangt/arr_20221203.txt", delimiter=',', dtype=np.int32)
print(np.loadtxt("./wangt/arr_20221203.csv", delimiter=',', dtype=np.int32))
print("-----")
print(np.loadtxt("./wangt/arr_20221203.txt", delimiter=',', dtype=np.int32))
""" 输出
[3 5 0 2 4 5 2 7 0 6]
-----
[3 5 0 2 4 5 2 7 0 6]
"""
3.NumPy数据类型介绍
ndarray的数据类型:
-
int
- int8
- uint8
- int16
- int32
- int64
-
float
- float16
- float32
- float64
-
str
可以在创建时指定:
import numpy as np
np.array([1,2,3],dtype = 'float32')
可以在asarray转换时指定:
import numpy as np
arr = [1,2,3,4]
np.asarray(arr,dtype = 'float32')
可以在数据类型转换astype时转换:
import numpy as np
arr = np.random.randint(0,10,size = 5,dtype = 'int16')
arr.astype('float32')
4.NumPy数组运算
- 逻辑运算
import numpy as np
arr1 = np.array([1, 2, 3, 4, 5])
arr2 = np.array([1, 0, 2, 3, 5])
print(arr1 < 5)
print(arr1 >= 5)
print(arr1 == 5)
print(arr1 == arr2)
print(arr1 > arr2)
""" 输出
[ True True True True False]
[False False False False True]
[False False False False True]
[ True False False False True]
[False True True True False]
"""
数组arr中元素逐个逻辑比较
- 数组与标量计算
import numpy as np
arr = np.arange(1, 4)
print(1 / arr)
print(arr + 5)
print(arr * 5)
""" 输出
[1. 0.5 0.33333333]
[6 7 8]
[ 5 10 15]
"""
- *=、+=、-=操作
import numpy as np
arr = np.arange(5)
print(arr)
arr += 2
print(arr)
arr -= 2
print(arr)
arr *= 2
print(arr)
""" 输出
[0 1 2 3 4]
[2 3 4 5 6]
[0 1 2 3 4]
[0 2 4 6 8]
"""
5.NumPy复制和视图
在操作数组时,有时会将其数据复制到新数组中,有时不复制
- 无复制
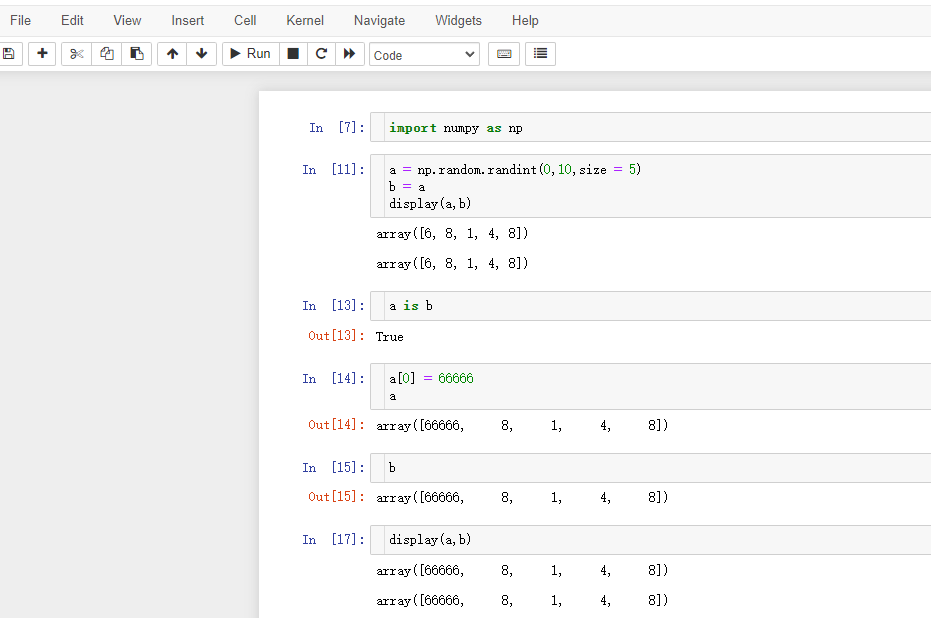
在jupyter中,同时输出多个内容用display()
- 视图、浅拷贝
不同的数组对象可以共享相同的数据。该view⽅法创建⼀个查看相同数据的新数组对象
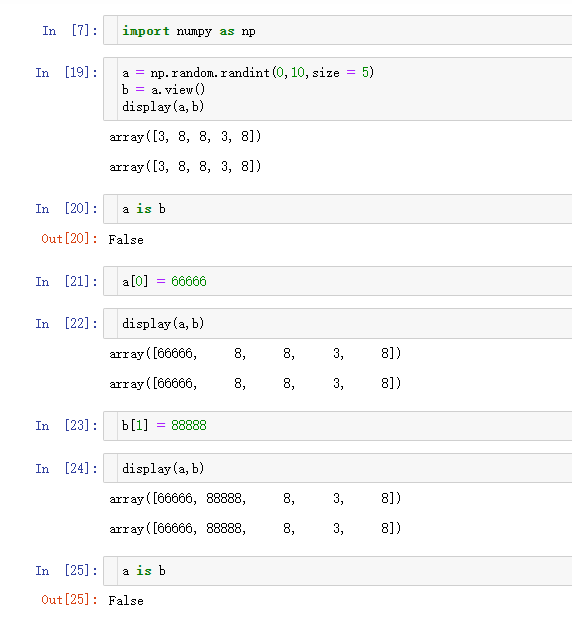
- 深拷贝
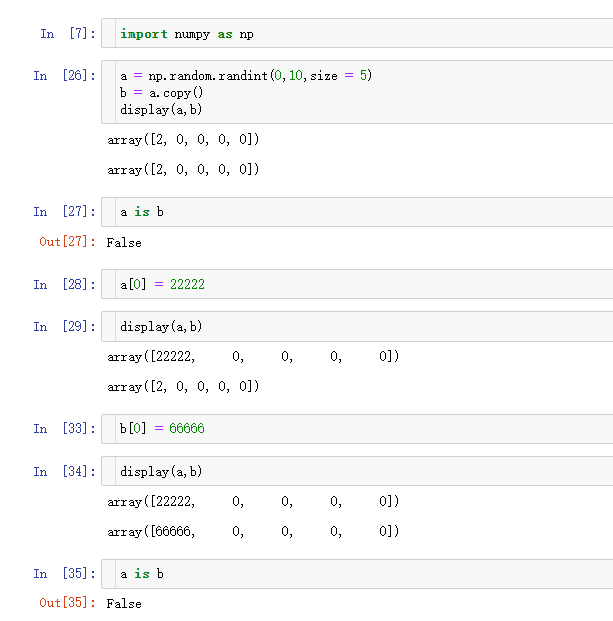
6.NumPy索引、切片和迭代
- 基本索引和切片
import numpy as np
a = np.random.randint(0, 20, size=10)
print(a) # [10 13 4 1 5]
# 取一个值
print(a[0])
# 取多个值
print(a[[0, 1, 3]])
# 切片
print(a[1:3]) # 从索引1切到索引为3(包括前索引不包括后索引)
print(a[:3]) # 从开始位置切到索引3位置
print(a[3:]) # 从索引为3开始切到末尾
print(a[::3]) # 取全部数据,步长为3
print(a[::-1]) # 相当于反转数据
""" 输出
[14 1 14 7 4 10 4 15 6 7]
14
[14 1 7]
[ 1 14]
[14 1 14]
[ 7 4 10 4 15 6 7]
[14 7 4 7]
[ 7 6 15 4 10 4 7 14 1 14]
"""
- 多维数组索引和切片
对于⼆维数组或者⾼维数组,我们可以按照之前的知识来索引,当然也可以传⼊⼀个以逗号隔开的索引列表来选区单个或多个元素
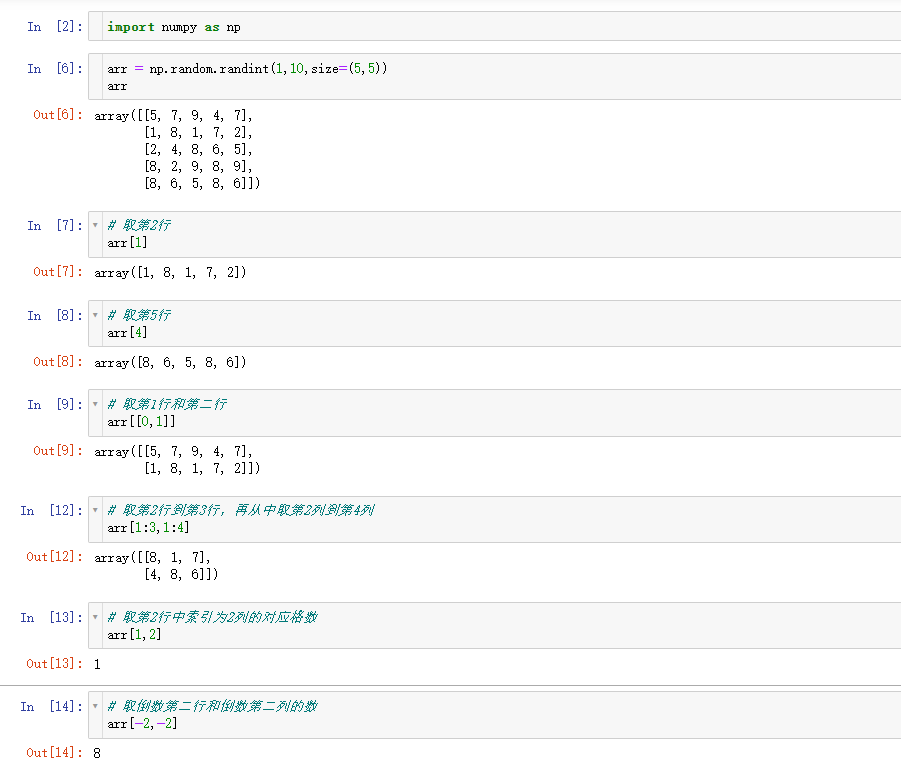
- 切片取值
import numpy as np
a = np.arange(20)
print(a)
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
b = a[3:7]
print(b)
# [3 4 5 6]
b[0] = 33333
print(a)
# [ 0 1 2 33333 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
print(b)
# [33333 4 5 6]
切片时,从返回的数据对比看,切片不是深拷贝,而是浅拷贝
- 花式索引
import numpy as np
a = np.arange(20)
# 花式索引
b = a[[3, 4, 5, 6]]
print(a)
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
print(b)
# [3 4 5 6]
b[0] = 33333
print(a)
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
print(b)
# [33333 4 5 6]
使用花式索引时,从返回的数据对比看,花式索引返回的是深拷贝,不再影响原数值
- 索引常用技巧
import numpy as np
a = np.random.randint(40, 100, size=(12, 3))
print(a)
"""
[[80 61 51]
[88 98 66]
[41 81 86]
[45 50 82]
[44 98 76]
[51 56 93]
[96 61 50]
[77 77 46]
[50 40 94]
[97 48 45]
[64 85 94]
[81 82 80]]
"""
# 找出全部数值中大于等于60的值
cond = a >= 60
print(a[cond])
# [80 61 88 98 66 81 86 82 98 76 93 96 61 77 77 94 97 64 85 94 81 82 80]
# boolean True=1;False=0
print(cond[:])
"""
[[ True True False]
[ True True True]
[False True True]
[False False True]
[False True True]
[False False True]
[ True True False]
[ True True False]
[False False True]
[ True False False]
[ True True True]
[ True True True]]
"""
# 找出每行3列数字都大于60的信息
# 相当于用cond每行的True和False去逐个相乘,如果都为True,赋值给cond_new,从而取出每行中元素都大于60的行
cond_new = cond[:, 0] * cond[:, 1] * cond[:, 2]
print(a[cond_new])
"""
[[88 98 66]
[64 85 94]
[81 82 80]]
"""
7.NumPy形状操作
- 数组变形 - reshape

- 数组转置( 行列互换 ) .T
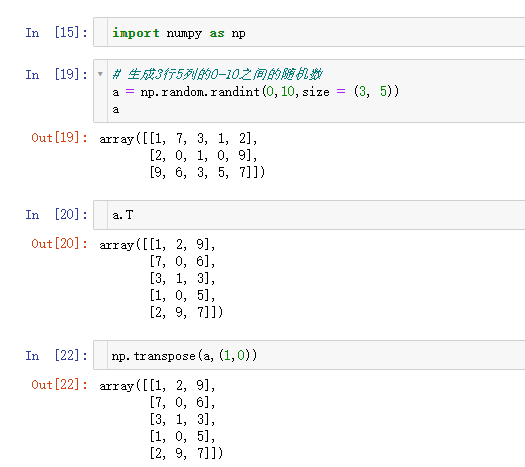
- 数组堆叠合并
import numpy as np
a = np.random.randint(0, 10, size=(2, 3))
b = np.random.randint(0, 10, size=(2, 3))
print(a)
# [[0 5 0]
# [7 6 0]]
print(b)
# [[1 8 2]
# [5 1 8]]
# 水平方向-横向行叠加
# 方法1
c = np.concatenate([a, b], axis=0)
print(c)
# 方法2
print(np.vstack((a, b)))
"""
[[0 5 0]
[7 6 0]
[1 8 2]
[5 1 8]]
"""
# 竖直方向-纵向列叠加
# 方法1
d = np.concatenate([a, b], axis=1)
print(d)
# 方法2
print(np.hstack((a, b)))
"""
[[0 5 0 1 8 2]
[7 6 0 5 1 8]]
"""
- split数组拆分
import numpy as np
a = np.random.randint(0, 15, size=(6, 6))
print(a)
"""
[[ 2 9 7 0 7 13]
[ 2 9 10 8 6 7]
[ 1 8 6 1 8 10]
[14 6 12 9 13 2]
[ 5 2 1 1 13 2]
[ 0 14 8 3 3 12]]
"""
# 等分拆成3份,按照行拆
b = np.split(a, indices_or_sections=3, axis=0)
print(b)
print(np.vsplit(a, indices_or_sections=3))
"""
[array([[ 2, 9, 7, 0, 7, 13],
[ 2, 9, 10, 8, 6, 7]]),
array([[ 1, 8, 6, 1, 8, 10],
[14, 6, 12, 9, 13, 2]]),
array([[ 5, 2, 1, 1, 13, 2],
[ 0, 14, 8, 3, 3, 12]])]
"""
# 等分拆成2份,按照列拆
c = np.split(a, indices_or_sections=2, axis=1)
print(c)
print(np.hsplit(a, indices_or_sections=2))
"""
[array([[ 2, 9, 7],
[ 2, 9, 10],
[ 1, 8, 6],
[14, 6, 12],
[ 5, 2, 1],
[ 0, 14, 8]]),
array([[ 0, 7, 13],
[ 8, 6, 7],
[ 1, 8, 10],
[ 9, 13, 2],
[ 1, 13, 2],
[ 3, 3, 12]])]
"""
# 参数给列表,则根据列表中的索引来进行切片
d = np.split(a, indices_or_sections=[1, 2, 3])
print(d)
"""
[array([[ 2, 9, 7, 0, 7, 13]]),
array([[ 2, 9, 10, 8, 6, 7]]),
array([[ 1, 8, 6, 1, 8, 10]]),
array([[14, 6, 12, 9, 13, 2],
[ 5, 2, 1, 1, 13, 2],
[ 0, 14, 8, 3, 3, 12]])]
"""
8.NumPy广播机制
当两个数组的形状并不相同的时候,我们可以通过扩展数组的⽅法来实现相加、相减、相乘等操作,这种机制叫做⼴播(broadcasting)
- ⼀维数组⼴播
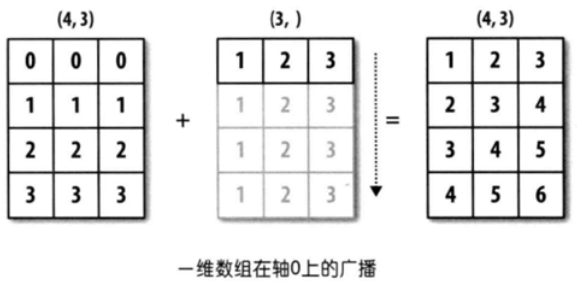
可以简单的理解成一维数组是一条线,二维数组是一个面,现在将一维数组并入到二维中去,那么一条线并入到一个面,那么这条线需要纵向延长成面再与二维面合并,最终目的是为了达到一一对应的效果,才能够做到对应位置的合并。
import numpy as np
arr1 = np.sort(np.array([0, 1, 2, 3] * 3)).reshape(4, 3)
arr2 = np.array([1, 2, 3])
print(arr1)
"""
[[0 0 0]
[1 1 1]
[2 2 2]
[3 3 3]]
"""
print(arr2)
"""
[1 2 3]
"""
print(arr1 + arr2)
"""
[[1 2 3]
[2 3 4]
[3 4 5]
[4 5 6]]
"""
- 二维数组广播
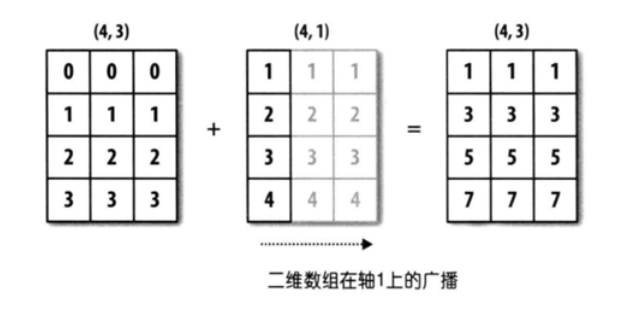
列不够,纵向补齐
import numpy as np
arr1 = np.sort(np.array([0, 1, 2, 3] * 3)).reshape(4, 3)
arr2 = np.array([[1], [2], [3], [4]])
print(arr1)
"""
[[0 0 0]
[1 1 1]
[2 2 2]
[3 3 3]]
"""
print(arr2)
"""
[[1]
[2]
[3]
[4]]
"""
print(arr1 + arr2)
"""
[[1 1 1]
[3 3 3]
[5 5 5]
[7 7 7]]
"""
- 三维数组广播
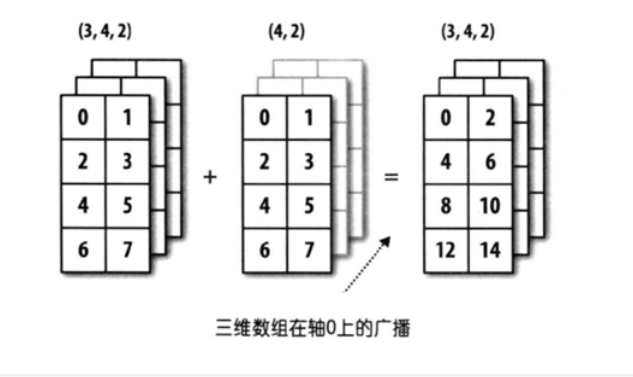
相当于数量份数不等的相加,需要把单份数据复制到份数相同时再相加
import numpy as np
arr1 = np.array([0, 1, 2, 3, 4, 5, 6, 7] * 3).reshape(3, 4, 2)
# arr1为3份4行2列的数组
print(arr1)
"""
[[[0 1]
[2 3]
[4 5]
[6 7]]
[[0 1]
[2 3]
[4 5]
[6 7]]
[[0 1]
[2 3]
[4 5]
[6 7]]]
"""
arr2 = np.array([0, 1, 2, 3, 4, 5, 6, 7]).reshape(4, 2)
# arr2为1份4行2列的数组
print(arr2)
"""
[[0 1]
[2 3]
[4 5]
[6 7]]
"""
print(arr1 + arr2)
"""
[[[ 0 2]
[ 4 6]
[ 8 10]
[12 14]]
[[ 0 2]
[ 4 6]
[ 8 10]
[12 14]]
[[ 0 2]
[ 4 6]
[ 8 10]
[12 14]]]
"""
9.NumPy通用函数
9-1.元素级数字函数
abs、sqrt、square、exp、log、sin、cos、tan,maxinmum、minimum、all、any、inner、clip、round、trace、ceil、floor
import numpy as np
arr = np.array([-1, -2, -3, -4, 4, 9, 16])
print(arr)
# [-1 -2 -3 -4 4 9 16]
print(np.abs(arr))
# 绝对值 [ 1 2 3 4 4 9 16]
print(np.sqrt(arr[4:]))
# 开平方 [2. 3. 4.]
print(np.square(arr))
# 算平方 [ 1 4 9 16 16 81 256]
print(np.min(arr))
# 最小值 -4
print(np.max(arr))
# 最大值 16
arr2 = np.array([666, -45, 0, 1, 1, 124, -999])
print(np.minimum(arr, arr2))
# 逐个对比arr和arr2的元素,列出小的值[ -1 -45 -3 -4 1 9 -999]
print(np.maximum(arr, arr2))
# 逐个对比arr和arr2的元素,列出大的值[666 -2 0 1 4 124 16]
9-2.where函数
where 函数,三个参数,条件为真时选择值的数组,条件为假时选择值的数组
import numpy as np
arr1 = np.array([1, 3, 5, 7, 9])
arr2 = np.array([2, 4, 6, 8, 10])
cond = np.array([True, False, True, True, False])
print(np.where(cond, arr1, arr2))
# [ 1 4 5 7 10]
"""
逐个去查看cond中的值,当cond的值为True时,对应位置取arr1中的值,当cond的值为False时,对应位置取arr2中的值
"""
arr3 = np.random.randint(0, 30, size=20)
# ⼩于25还是⾃身的值,⼤于25设置成NULL值
print(np.where(arr3 < 25, arr3, "NULL"))
# ['3' '19' '11' '18' '11' 'NULL' 'NULL' 'NULL' '20' 'NULL' '10' '23' '12' 'NULL' 'NULL' '15' '22' '5' '13' 'NULL']
9-3.排序方法
np中还提供了排序⽅法,排序⽅法是就地排序,即直接改变原数组
import numpy as np
# 方法1
arr1 = np.array([111, 3, 555, 7, 999])
arr1.sort()
print(np.sort(arr1))
# [ 3 7 111 555 999]
# 方法2 - 通过排序后得到的索引
arr2 = np.array([111, 3, 555, 7, 999])
arr_index = arr2.argsort()
print(arr2[arr_index])
# [ 3 7 111 555 999]
9-4.集合运算函数
import numpy as np
A = np.array([2, 4, 6, 8])
B = np.array([3, 4, 5, 6])
# 交集
print(np.intersect1d(A, B))
# [4 6] (A和B中都有的值)
# 并集
print(np.union1d(A, B))
# [2 3 4 5 6 8] (A或B中只要其中一个数组中有)
# 差集
print(np.setdiff1d(A, B))
# [2 8] (A中有并且B中没有的值)
9-5.数学和统计函数
min、max、mean、median、sum、std、var、cumsum、cumprod、argmin、argmax、
argwhere、cov、corrcoef
import numpy as np
arr1 = np.array([-666, 7, 2, 19, 23, 0, 888, 11, 6, 11])
# 计算最⼩值 -666
print(arr1.min())
# 计算最⼤值的索引 6
print(arr1.argmax())
# 返回⼤于20的元素的索引[[4][6]]
print(np.argwhere(arr1 > 20))
# 计算累加和
print(np.cumsum(arr1))
# [-666 -659 -657 -638 -615 -615 273 284 290 301]
arr2 = np.random.randint(0, 10, size=(4, 5))
print(arr2)
"""
[[3 5 0 1 1]
[0 4 1 5 5]
[2 9 3 9 4]
[5 0 9 1 1]]
"""
# 计算列的平均值
print(arr2.mean(axis=0))
# [2.5 4.5 3.25 4. 2.75]
# 计算⾏的平均值
print(arr2.mean(axis=1))
# [2. 3. 5.4 3.2]
# 协⽅差矩阵
print(np.cov(arr2, rowvar=True))
"""
[[ 4. 0. 2.5 -3.75]
[ 0. 5.5 5.75 -7.25]
[ 2.5 5.75 11.3 -9.1 ]
[-3.75 -7.25 -9.1 14.2 ]]
"""
# 相关性系数
print(np.corrcoef(arr2, rowvar=True))
"""
[[ 1. 0. 0.37185257 -0.49757334]
[ 0. 1. 0.72936896 -0.82037514]
[ 0.37185257 0.72936896 1. -0.71838623]
[-0.49757334 -0.82037514 -0.71838623 1. ]]
"""
10.NumPy线性代数
矩阵相乘最重要的方法是一般矩阵乘积。只有在第一个矩阵的列数(column)和第二个矩阵的行数(row)相同时才有意义 。一般单指矩阵乘积时,指的便是一般矩阵乘积。一个m×n的矩阵就是m×n个数排成m行n列的一个数阵。由于它把许多数据紧凑的集中到了一起,所以有时候可以简便地表示一些复杂的模型




![[附源码]Python计算机毕业设计Django市场摊位管理系统](https://img-blog.csdnimg.cn/242f00509d3844c3922da346bc622052.png)