前言
在实现容器化的初期,计划使用 Ceph 作为容器的存储。都说存储是虚拟化之母,相对容器来说,存储也起到了至关重要的作用。
选用 Ceph 作为容器化存储理由如下:
- 方便后期横向扩展;
- Ceph能够同时支持快存储、对象存储、文件存储,容器使用块存储,后期也会用到对象存储来取代 OSS 服务。
基于以上理由,采用 Ceph 分布式存储应该是个不错的选择。容器化第一步从 存储 开始。
Ceph 官方文档(英文):Intro to Ceph — Ceph Documentation
Ceph 官方文档(中文):http://docs.ceph.org.cn/start/intro/
Ceph 简介
不管你是想为 云平台 提供 Ceph 对象存储或块设备,还是想部署一个 Ceph 文件系统 ,所有 Ceph 存储集群的部署都始于一个个 Ceph节点、网络和 Ceph存储集群。
创建Ceph 存储,至少需要以下服务:
- 一个Ceph Monitor
- 两个OSD守护进程
而运行 Ceph 文件系统客户端时,则必须要有元数据服务器(Metadata Server) ,使用 Ceph 作为文件系统这种需求场景应该不会很多,而本次的容器化项目也不会涉及到 文件系统存储,因此不深究

Ceph OSDs:Ceph OSD 守护进程(Ceph OSD)的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 集群设定有2个副本时,至少需要2个OSD守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,但你可以调整副本数)。
可以这样理解:Ceph 是通过一个个 OSD 来存储数据的,Ceph 默认的OSD 是3个,但是可以手动设置为2个,最少2个才能使集群达到健康可用的状态,并且使用 OSD 可以实现数据的高可用。
Monitors:Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
可以这样理解:Monitor 就是Ceph 的一个监视器,Ceph 在存储数据的时候,各项数据指标都会记录显示出来。至于什么 PG / CURSH 后面会讨论到。
Ceph 把客户端数据保存为存储池内的对象。通过使用 CRUSH 算法, Ceph 可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个 OSD 守护进程持有该归置组。 CRUSH 算法使得 Ceph 存储集群能够动态地伸缩、再均衡和修复。
官方文档一句话,将Ceph的原理总结出来,但是对于初次接触Ceph的来说,简直生涩难懂。总结几个关键字:对象、CRUSH 算法、归置组(PG)、动态地伸缩
到此,就需要明白 Ceph 整体的工作原理是怎样的?不然这个疑问会一直围绕着我们。
Ceph 存储原理介绍
通过查询资料,发现胖哥这篇文章写的非常不错,值得反复理解:大话Ceph - CRUSH 那点事儿
【以下理论知识来源胖哥文章及自己的一些理解】
首先抛出一个问题:将一份数据存储到 Ceph 集群中,一共需要几步走?
Ceph 的答案是两步:
- 计算PG,也就是官方文档中的归置组
- 计算OSD
既然提到了计算,那肯定就会有算法,那算法是不是所谓的 CRUSH 呢?
计算PG
首先,要明确Ceph的一个规定:在Ceph 中,一切皆对象。(这里提到了对象,和官方文档吻合,一切皆对象不难理解,同 python一样,一切皆对象)
一下举例来说明了,一切皆对象,无论是视频、照片、文字还是其他格式文件:
不论是视频,文本,照片等一切格式的数据,Ceph统一将其看作是对象,因为追其根源,所有的数据都是二进制数据保存于磁盘上,所以每一份二进制数据都看成一个对象,不以它们的格式来区分他们。
既然是对象,那对象就应该有对象名。而区分2个对象的就是通过 对象名 来区分的。那如果两个对象的文件名一样呢?
现在一开始的问题就变成:把一个对象存储到Ceph 集群中分几步走?
已知:Ceph 集群是有若干服务器,确切的说就是一堆磁盘组成,而在Ceph中 每块磁盘就看作是一个 OSD。
文件又简化为:把一个对象存储到 OSD 中分几步走?
Ceph中的逻辑层
Ceph为了保存一个对象,对上构建了一个逻辑层,也就是池(Pool),这个不难理解,就像虚拟化中的存储池化,用来保存对象,如果把Pool比喻为一个中国象棋棋盘,那么保存一个对象的过程类似于把一粒芝麻放置到棋盘中
简单如图:
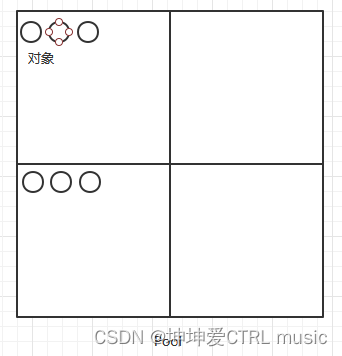
Pool 再一次细分,即将一个 Pool 划分为若干的PG(归置组),这类似于棋盘上的方格,所有方格构成了整个棋盘,也就是说所有的PG构成了一个 Pool
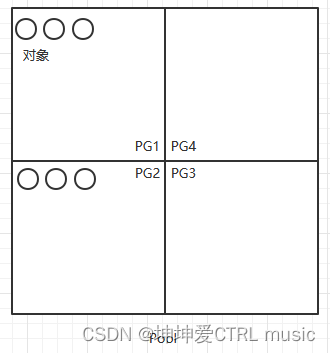
通过这两个图,我们可以总结下:文件是一个个对象,对象则是存储在每个PG里的,而多个PG 构成了Pool
现在问题又来了,对象怎么知道要保存到哪个PG上呢?假定这里我们的 Pool 名叫 rbd,共有 256 个PG,给每个PG 编号分别叫做 0, 1,2, 3, 4
要解决这个问题,首先看目前有什么?
- 不同的对象名
- 不同的PG编号
这里就引入了Ceph的第一个算法:HASH
对于对象名分别为 bar 和 foo 两个对象,对他们的对象名进行计算即可:
- HASH(‘bar’) = 0x3E0A4162
- HASH(‘foo’) = 0x7FE391A0
- HASH(‘bar’) = 0x3E0A4162
HASH算法应该是最常用的算法,对对象名进行HASH后,得到一串十六进制的输出值,也就是说通过HASH我们将一个对象名转化为一串数字,那么上面的第一行和第三行是一样的有什么意义?意义就是对于一个同样的对象名,计算出来的结果永远都是一样的,但是HASH算法的确将对象名计算得出了一个随机数。有了这个随机数,就对这个随机数除以PG总数,比如 256 ,得到的余数一定是落在 1-256 之间的,也就是这 256 个PG中的某一个。
公式:HASH('bar') % PG数
- 0x3E0A4162 % 0xFF ===> 0x62
- 0x7FE391A0 % 0xFF ===> 0xA0
通过上面的计算,对象bar 保存到编号为 0x62 的PG中,对象 foo 保存在编号 0xA0 的PG中。对象 bar 永远都会保存在 PG 0x62中!对象 foo 永远都会保存到PG 0xA0中!
目前,可以总结一个对象是如何存入PG 中的:
对 对象名进行 HASH 取到一个随机数,然后在用这个随机数 对 PG 总数取余,得到的值一定落在 1- PG总数之间,改对象名的数据就会永远的存储在这个PG 中。
所以,自对象名确定了, 那么该对象保存数据的PG也就确定了。
由此衍生出来一个问题,对象名确定唯一性,难道就不管对象数据的大小了吗?
答案是肯定的,也就是Ceph不区分对象的真实大小内容以及任何形式的格式,只认对象名。
这里给出更Ceph一点的说明,实际上在Ceph中,存在着多个pool,每个pool里面存在着若干的PG,如果两个pool里面的PG编号相同,Ceph怎么区分呢? 于是乎,Ceph对每个pool进行了编号,比如刚刚的rbd池,给予编号0,再建一个pool就给予编号1,那么在Ceph里,PG的实际编号是由pool_id+.+PG_id组成的,也就是说,刚刚的bar对象会保存在0.62这个PG里,foo这个对象会保存在0.A0这个PG里。其他池里的PG名称可能为1.12f, 2.aa1,10.aa1等。
Ceph 中的物理层
在逻辑层中,已经知道一个文件是如何存储在Ceph 中PG 里,简单来说就是通过对对象名进行hash 然后对PG总数取余,得到的余数就是对应的PG,然后将数据存储在这个PG归置组里。
接下来看看Ceph里的物理层。若干服务器,服务器上有若干磁盘,通常,Ceph 将一个磁盘看作一个OSD(实际上,OSD是管理磁盘的一个程序),于是物理层由若干OSD组成,我们最终目标是将对象保存到磁盘上,在逻辑层里,对象是保存到PG里的,那么现在的任务就是 打通PG和OSD 之间的隧道。PG相当于一堆余数相同的对象的组合,PG把这一部分对象打了个包,现在我们需要把很多的包平均的安放在各个OSD上,这就是CRUSH 算法所有做的事:CRUSH计算 PG -> OSD的映射关系
此时,加上刚刚逻辑层的对象到PG的算法,可以总结出两个公式:
- 池ID+HASH('对象名') % PG_num --> PG_ID
- CRUSH(PG_ID) --> OSD
在这里采用两种算法,HASH 和 CRUSH ,这两种算法有何差异呢?为什么不能直接用 HASH(PG_ID) 到对应的 OSD 上呢?
CURSH(PG_ID) ==> 改为 HASH(PG_ID) % OSD_num ==> OSD
以下是胖哥的推断:
- 如果挂掉一个OSD,OSD_num=1,于是所有的 PG % OSD_num 的余数都会变化,也就是说这个PG保存的磁盘发生了变化,这最简单的解释就是,这个PG 上的数据要从一个磁盘转移到另一个磁盘上去,一个优秀的存储架构应当在磁盘损坏时使得数据迁移量降到最低,CRUSH 可以做到;
- 如果保存多个副本,我们希望得到多个OSD 结果的输出,HASH只能获得一个,但是CRUSH 可以获得任意多个;
- 如果增加OSD 的数量,OSD_num 增大了,同样导致PG 在OSD之间的胡乱迁移,但是CRUSH 可以保证数据向新增机器均匀的扩散。
总结起来就是 HASH 算法只适合 1 对 1 的映射关系,并且计算的两个值还不能变,因此这里就不适合 PG -> OSD 的映射计算。因此,这里开始引入 CRUSH 算法。
CRUSH 算法
这里不打算详细介绍 CRUSH 源码,只是通过举例的方式来理解 CRUSH 算法。
首先来看要做什么:
- 把已有的PG_ID 映射到OSD上,有了映射关系就可以把一个PG保存到一块磁盘上;
- 如果想要保存三个副本,可以把一个PG映射到三个不同的 OSD 上,这三个 OSD 上保存着一模一样的PG内容。
在来看看有什么:
- 互不相同的PG_ID;
- 如果给OSD也编个号,那么就有了互不相同的 OSD_ID;
- 每个OSD最大的不同的就是它们的容量,即 4T还是800GB的容量,我们将每个OSD的容量又称为OSD的权重(weight),规定4T权重为4,800G为0.8,也就是以 T 位单位的值。
现在的问题转化为:如何将 PG_ID 映射到有各自权重的 OSD 上。这里直接使用 CRUSH 算法中的 straw 算法,翻译过来就是 抽签,说白了就是挑个最长的签,这里的签指的是 OSD 的权重。
那总不能每次都挑选容量最大的OSD吧,这不分分钟都把数据存满那个最大的OSD了吗? 所以在挑之前把这些OSD 搓一搓,这里直接介绍CRUSH 算法:
- CRUSH_HASH( PG_ID, OSD_ID, r ) ===> draw
- ( draw &0xffff ) * osd_weight ===> osd_straw
- pick up high_osd_straw
第一行,我们姑且把r当做一个常数,第一行实际上就做了搓一搓的事情:将PG_ID, OSD_ID和r一起当做CRUSH_HASH的输入,求出一个十六进制输出,这和HASH(对象名)完全类似,只是多了两个输入。所以需要强调的是,对于相同的三个输入,计算得出的draw的值是一定相同的。
这个draw到底有啥用?其实,CRUSH希望得到一个随机数,也就是这里的draw,然后拿这个随机数去乘以OSD的权重,这样把随机数和OSD的权重搓在一起,就得到了每个OSD的实际签长,而且每个签都不一样长(极大概率),就很容易从中挑一个最长的。
说白了,CRUSH希望随机挑一个OSD出来,但是还要满足权重越大的OSD被挑中的概率越大,为了达到随机的目的,它在挑之前让每个OSD都拿着自己的权重乘以一个随机数,再取乘积最大的那个。那么这里我们再定个小目标:挑个一亿次!从宏观来看,同样是乘以一个随机数,在样本容量足够大之后,这个随机数对挑中的结果不再有影响,起决定性影响的是OSD的权重,也就是说,OSD的权重越大,宏观来看被挑中的概率越大。
上面的内容不理解也没关系,这里在简单梳理下PG 选择一个OSD时做的事情:
- 给出一个 PG_ID ,作为 CRUSH_HASH 的输入;
- CRUSH_HASH(PG_ID, OSD_ID, r) 得出一个随机数(重点是随机数,不是HASH);
- 对于所有的OSD用他们的权重乘以每个OSD_ID 对应的随机数,得到乘积;
- 选出乘积最大的OSD;
- 这个PG就会保存到这个OSD上。
通过上面的说明,已经可以解决一个PG映射到多个OSD的问题了, 而常量r,当 r+1,在求一遍随机数,再去乘以每个OSD的权重,再去选出乘积最大的OSD,如果和之前的OSD 编号不一样,那么就选中它,如果和之前的OSD 编号一样的话,那么再把 r+2,再选一次随机数,直到选出我们需要的三个不一样编号的OSD为止!
当然实际选择过程还要稍微复杂一点,我这里只是用最简单的方法来解释CRUSH在选择OSD的时候所做的事情。
CRUSH 算法的应用
理解了上面CRUSH选择OSD的过程,我们就很容易进一步将CRUSH算法结合实际结构,这里给出Sage在他的博士论文中画的一个树状结构图:
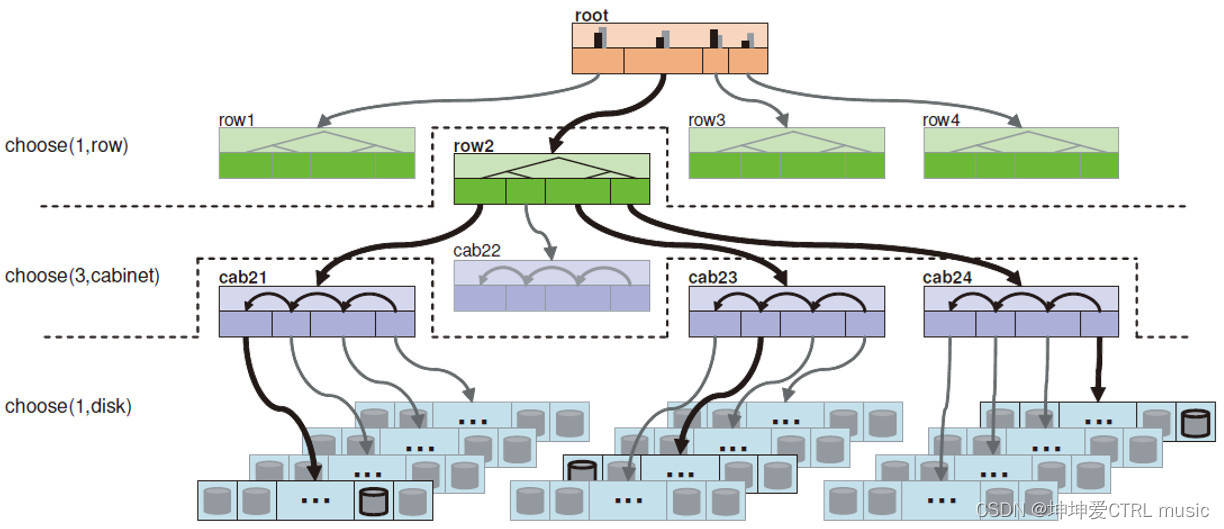
最下面的蓝色长条可以看成一个个主机,里面的灰色圆柱形可以看成一个个OSD,紫色的cabinet可以也就是一个个机柜, 绿色的row可以看成一排机柜,顶端的root是我们的根节点,没有实际意义,你可以把它看成一个数据中心的意思,也可以看成一个机房的意思,不过只是起到了一个树状结构的根节点的作用。
基于这样的结构选择OSD,我们提出了新的要求:
- 一共选出三个OSD;
- 这三个OSD 需要都位于一个row下面;
- 每个cabinet内至多有一个OSD。
这样的要求,如果用上一节的CRUSH 选 OSD 的方法,不能满足二三两个要求,因为 OSD 的分布是随机的。
那么要完成这样的要求,先看看有什么:
- 每个OSD的weight;
- 每个主机也可以有一个weight,这个weight由主机内的所有 OSD 的weight累加而得;
- 每个cabinet的weight由所有主机的weight累加而得,其实就是这个cabinet下的所有OSD的权重值和;
- 同理推得每个row的weight有cabinet累加而得;
- root的weight其实就是所有的OSD的权重之和。
所以在这棵树状结构中,每个节点都有了自己的权重,每个节点的权重由下一层节点的权重累加而得,因此根节点root的权重就是这个集群所有的OSD的权重之和,那么有了这么多权重之后,我们怎么选出那三个OSD呢?
仿照CRUSH 选 OSD 的方法:
- CRUSH从root下的所有的row中选出一个row;
- 在刚刚的一个row下面的所有cabinet中,CRUSH选出三个cabinet;
- 在刚刚的三个cabinet下面的所有OSD中,CRUSH分别选出一个OSD。
因为每个row都有自己的权重,所以CRUSH选row的方法和选OSD的方法完全一样,用row的权重乘以一个随机数,取最大。然后在这个row下面继续选出三个cabinet,再在每个cabinet下面选出一个OSD。
这样做的根本意义在于,将数据平均分布在了这个集群里面的所有OSD上,如果两台机器的权重是16:32,那么这两台机器上分布的数据量也是1:2。同时,这样选择做到了三个OSD分布在三个不同的cabinet上。
那么结合图例这里给出CRUSH算法的流程:
- take(root) ============> [root]
- choose(1, row) ========> [row2]
- choose(3, cabinet) =====> [cab21, cab23, cab24] 在[row2]下
- choose(1, osd) ========> [osd2107, osd2313, osd2437] 在三个cab下
- emit ================> [osd2107, osd2313, osd2437]
这里给出CRUSH算法的两个重要概念:
- BUCKET/OSD:OSD和我们的磁盘一一对应,bucket是除了OSD以外的所有非子节点,比如上面的 cabinet,row,root等都是;
- RULE:CRUSH选择遵循一条条选择路径,一个选择路径就是一个rule。
RULE 一般分为三步走: take -> choose N -> emit.
Take这一步负责选择一个根节点,这个根节点不一定是root,也可以是任何一个Bucket。
choose N 做的就是按照每个 Bucket 的weight 以及每个 choose 语句选出符合条件的 Bucket,并且,下一个 choose 的选择对象为上一步得到的结果。
emit 就是输出最终结果相当于出栈。
Ceph 架构
通过上面对原理的理解,再看下图Ceph架构就很容理解了
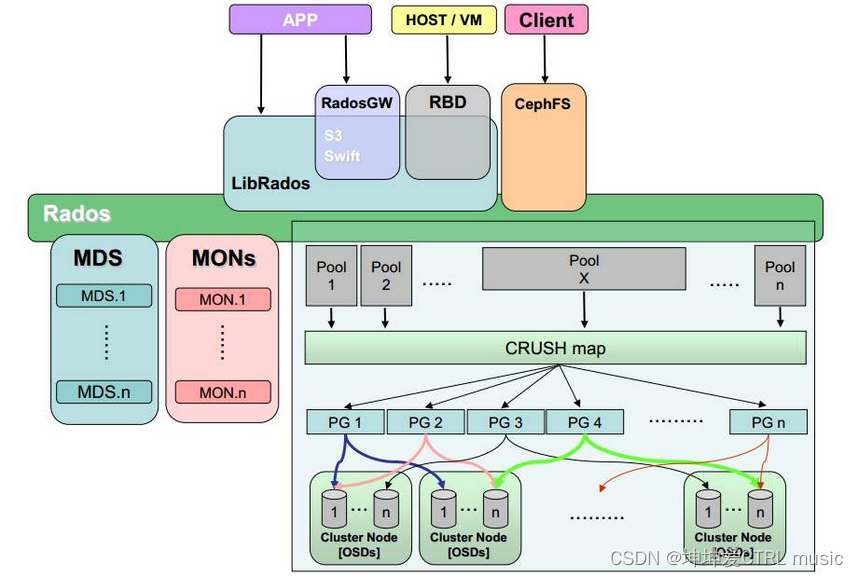
从上往下看:
1. Ceph 对外提供了 4 个接口:
- 应用直接访问RADOS,这个需要通过自行开发调用接口,适合自主开发;
- 对象存储接口,支持(Amazon)S3 和 Swift 的调用方式,适合存储对象存储,如图片、视频等;
- 块存储接口(RBD),主要对外提供块存储,例如提供给虚拟机使用的块设备存储;
- 文件存储(CephFS),类似于NFS 的挂载目录存储。
2. 应用直接访问、对象存储、块存储都是依赖于 LibRados库文件的
3. Ceph将底层是一个RADOS对象存储系统,通过RADOS对象存储系统对外提供服务
4. MDS 元数据节点、MON 管理控制节点、很多的 Pool存储池
5. 在Pool存储池中包含了很多PG归置组,然后通过 CRUSH 算法将PG中的数据存储到各个 OSD 组中。
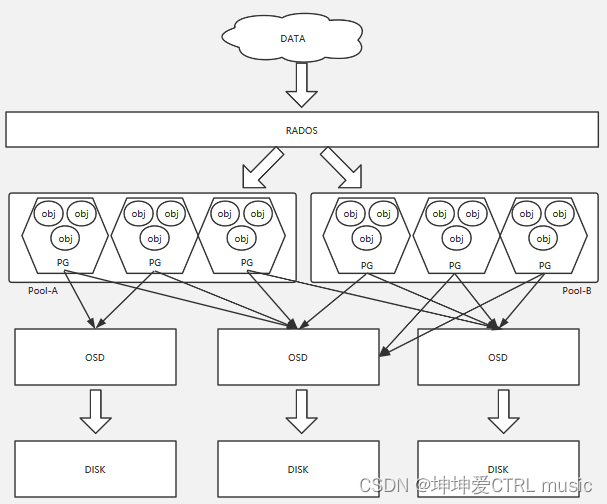
在上面的步骤中,我们需要重点关注第 5 点,上文说过,在 Ceph中,一切皆对象。首先通过将对象名 通过 HASH 算法得到一个16进制的数,再对 Pool中的PG总数取余,得到的余数一定落在 PG总数中的一个节点上,Ceph就将这个对象名的数据存储在这个PG里,然后再通过 CRUSH_HASH(PG_ID, OSD_ID, r) 计算得到一个值,这样就可以将数据落到OSD上,而在Ceph中,OSD 就是磁盘的代名词。通过图示来表示这一过程
Ceph 特点及核心组件
Ceph 特点:
高性能
- 摒弃了传统的集中式存储元数据寻址的方案,采用 CRUSH 算法,数据分布均衡,并行度高;
- 考虑了容灾域的隔离,能够实现各类负载的副本放置规则;
- 能够支持上千个存储节点的规模,支持TB到PB级的数据。
高可用
- 副本数可以灵活控制;
- 支持故障域分隔,数据强一致性;
- 多种故障场景自动进行修复自愈;
- 没有单点故障,自动管理。
高扩展
- 原生分布式去中心化;
- 扩展灵活;
- 随着节点增加而线性增长。
丰富特性
- 支持三种存储接口:块存储、对象存储、文件存储;
- 支持自定义接口,支持多个语言。
核心组件:
Monitor
- 一个Ceph集群需要多个Monitor组成的小集群,用来保存OSD的元数据。
OSD
- OSD 全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD,Ceph最终数据也是由OSD保存到磁盘上的。
MDS
- MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。如果不使用文件存储,则不需要安装。
Object
- Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据。
PG
- PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
RADOS
- RADOS全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
Libradio
- Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
CRUSH
- CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
RBD
- RBD全称RADOS block device,是Ceph对外提供的块设备服务。
RGW
- RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容,如果不使用对象存储则不需要安装。
CephFS
- CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。