深度解析布谷鸟过滤器
0 引言
布隆过滤器(Bloom Filter),诞生于UNIX元年(1970年)的一个老牛逼的过滤器,与时间戳同寿,经久不衰老而弥坚,查重性能至今令人非常满意。美中不足的是有一点误判率并且支持删除元素比较困难。44年后,卡内基梅隆大学的Bin Fan等人发了篇文章,标题是《布谷鸟过滤器:雀食吊过布隆》,号称有更好的空间利用率、更高的性能、更低的误判率、对删除操作更好的支持。听起来有点东西,深入文章研究下。
1 相关研究(又名:全靠同行承托)
1.1 布隆过滤器和它的各路变种
1.1.1 标准布隆过滤器
标准布隆过滤器仅支持插入和查找两个操作,并且存在一个假阳率ε,如果希望假阳率更低,那么就需要付出更高的空间代价。
通俗的翻译一下假阳率,这个概念后文可能还会出现。我向布隆过滤器查询,a是否存在,如果返回不存在,那就100%不存在,不接受反驳。如果返回存在,那就要小心了,因为它有ε的概率是错的,实际上a并不存在。当然,我实际工作中使用一般会让ε在0.000001这样很小很小,1亿次错个1百1千次之类的,可以接受。
布隆过滤器的工作原理非常简单,k个随机哈希函数和1个长长的bit数组(初始为全0),插入一个元素时,使用k个哈希函数进行计算,并根据计算结果把bit数组中对应的k个比特位置为1。查询的时候也是同理,进行相应的计算后,查询对应的k个位置是不是都为1,如果都是1,那么说明已存在,否则说明不存在。想必读到这里,已经能领悟到假阳率出现的根源了吧。
在实际生产环境中,我们首先选取一个ε值,例如我用的是0.000001,即百万分之一,与之对应的哈希函数个数k的选取,则需要一点小小的计算:
log 2 1 ε \log_2 \frac1 ε log2ε1
通过一系列的概率极限偏微分方程的计算可以得到这个值,是空间最优的一个解,这里就不做推导了。根据我的ε值可以计算得到,k=20,即我们需要设置20个哈希函数。在最优解下,每个元素需要的存储空间为:
1
ln
2
∗
log
2
1
ε
\frac1 {\ln2}*\log_2 \frac1 ε
ln21∗log2ε1
(注:原论文中采用的系数1.44为近似值,实际公示推导结果为
1
ln
2
\frac 1 {\ln2}
ln21)
则如果需要对n个元素做查重需要的空间如下:
n ∗ 1 ln 2 ∗ log 2 1 ε n*\frac1 {\ln2}*\log_2 \frac1 ε n∗ln21∗log2ε1
显然,单个元素的存储空间只与ε有关,而与元素本身的大小并无关系。根据信息论原理单个元素需要的最小空间为
log
2
1
ε
\log_2 \frac1 ε
log2ε1,布隆过滤器需要的空间仅比信息论最小值高约44%,这样的空间利用率,不可谓不高效。
标准布隆过滤器优点突出,缺点也非常显著,那就是它不支持删除操作。为了解决这一点,有人提出了一种布隆过滤器的扩展,Counting Bloom filters ,我也不知道怎么翻译,就叫计数布隆过滤器吧。
1.1.2 计数布隆过滤器(CBF)
首先思考下为什么标准布隆过滤器不支持删除操作,插入操作是把对应的k位bit置为1,那删除的时候我置为0不就行了?显然是不行的,万一元素B有某一位bit[x]和元素A重复了,那在删除A的过程中,bit[x]就置为0了,那么我再去查找B,就会发现bit[x]=0,B不存在,那就完犊子了,因为我们并没有删除过B。
要解决这一问题也非常简单,无非是因为一个bit位能包含的信息太少了,这个问题加钱就能解决。把每个bit位改成一个计数器,本来bit[x]只能0 ⇒ \rArr ⇒ 1,现在有了计数器,就可以bit[x]+1了,删除的时候bit[x]-1。对于上述A, B元素,bit[x]=2,删除A元素bit[x]=1了,丝毫不会影响到B元素后续的查找。
关于计数器的位数的计算,有点高深,有一步什么斯特林公式的变换完全没看懂,反正4位就很够用了。1个bit位需要对应成一个4位的计数器,所以CBF的空间开销差不多是标准布隆的4倍。
这种计数器的方法可以说是简单粗暴,在空间的使用上也有些奢侈了,显然还有进一步的优化空间。
1.1.3 Blocked Bloom filters
来自卡尔斯鲁厄大学的FELIX PUTZE等人在2007年的研究《Cache-, Hash- and Space-Efficient Bloom Filters》,这个我也没找到啥中文资料,冒昧翻译为分块布隆过滤器,这是标准布隆过滤器的又一变种,它提升的方向是进一步的提高性能。布隆过滤器本身性能已经非常优越了,但仍有某些场景对性能有更极致的追求,例如阿里云对RuntimeFilter进行性能优化的时候就把标准布隆过滤器替换成了Blocked Bloom filters。
性能提升付出的代价是更高的假阳率,多用了一点空间,同时它依然不支持删除操作。
这个变种并不符合我的工作需要,所以没有进行更深入的学习研究,1.1.2提到了CBF对空间的浪费,下面来看下如何对其进行优化提升。
1.1.4 d-left Counting Bloom filters
翻译这活真不是人干的,我绞尽脑汁给它起了个名字:基于多子表均衡左优先存储哈希表的计数布隆过滤器。
要理解这个变种,首先要理解d-left hashing,我自认为翻译的还是到位的,多子表均衡(d)左优先存储(left)哈希表(hashing)。把整个哈希表分成d个从左到右连着的子表,每个子表对应一个不同的哈希函数,当加入一个新元素时,分别计算d个哈希函数,得到d个不同的位置,然后将新元素加入到负载最轻的位置,如果有多个子表负载相同且均为最轻,则默认加入到最左边的子表。同理,进行查找操作时自然也就需要分别进行d次计算和查找。
虽然这种过滤器的名字里依旧包含Counting,但这只是表示它是CBF的变种,实际它已经抛弃了计数器,转而为每个元素存储了一个指纹,而这个指纹,正是使用了d-left hashing进行存储的。需要进行删除操作时,直接从d-left hashing中移除对应的指纹即可。
通过d-left hashing存储指纹的方式,d-left CBF可以比CBF节省约50%的存储空间,亦即标准布隆过滤器的1.5~2倍左右。
d-left CBF和本文将重点介绍的布谷鸟过滤器有很多相似之处,这里暂时按下不表,先看另一种非常流行的过滤器——Quotient filters。
1.1.5 Quotient filters
商过滤器,中文资料也是乏善可陈,因此我辛苦一下,在这里做一个最通俗易懂的中文讲解。
据说商过滤器是诞生于《计算机程序设计艺术(第3卷)》6.4节的习题13,我特地去看了下原题,嗯,劳资题目都看不懂啊!我要有这么难的作业必不可能拿到毕业证书啊!
言归正传,商过滤器只进行一次哈希函数计算,显然比上述的k次d次计算来的效率要更高,另外商过滤器也支持删除操作。这两点就是他相较于标准布隆过滤器的主要优点,没错,标准布隆过滤器就是战斗力计算单位。
首先我们构造一个 3 ∗ 2 r 3*2^r 3∗2rbit位长度的哈希表,给每3位bit对应分配一个槽,即有 2 r 2^r 2r个槽,构造好之后我们暂且把他放在一边,等会儿再说怎么用。
然后我们来对一个元素x进行以下3次运算:
① 对元素x进行一次哈希函数的运算,这里记为
f
(
x
)
f(x)
f(x);
② 对
f
(
x
)
f(x)
f(x)做一次除法运算,取其商
f
q
(
x
)
=
⌊
f
(
x
)
/
2
r
⌋
f_q(x)=\lfloor f(x)/2^r\rfloor
fq(x)=⌊f(x)/2r⌋;
③ 对
f
(
x
)
f(x)
f(x)做一次模运算,得到余数
f
r
(
x
)
=
f
(
x
)
m
o
d
f
q
(
x
)
f_r(x)=f(x) \mod {f_q(x)}
fr(x)=f(x)modfq(x);
假定8个元素,分别进行上述运算后,得到下面这样一组值,接下来我们把这组值填入到之前构造的哈希表中。
| f f f | f q f_q fq | f r f_r fr |
|---|---|---|
| A | 1 | a |
| B | 1 | b |
| C | 3 | c |
| D | 3 | d |
| E | 3 | e |
| F | 4 | f |
| G | 6 | g |
| H | 6 | h |
填入结果如下图所示
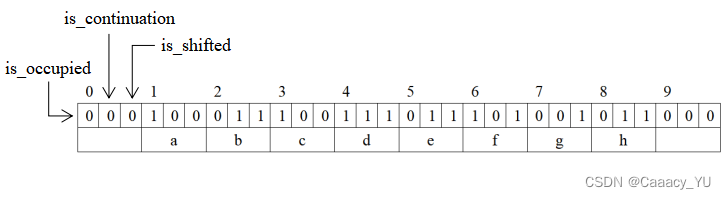
表格上方的0~9数字,用于表示每个槽的索引,根据商
f
q
f_q
fq的值,将
f
r
f_r
fr填入与
f
q
f_q
fq对应的索引中。如第一个放入的A,商为1,则把a填入到索引为1的槽内,第二个放入B的时候,发现商也是1,而索引1的槽已经被A占用了,那就往后顺延一格,存入索引为2的槽内。C的商为3,则存入索引为3的槽内,DEFGH同理往后顺延。
前文我们说过,给每3位bit对应分配一个槽,槽存储了 f r f_r fr的值,3位bit则另有他用。这3位bit分别表示:
- is_occupied: 是否被正确的占据了。重点不是这个槽有没有被占据,而是有没有被正确的占据,即有没有与槽位索引对应的商值。如A的商是1,那么槽位1就被正确的占据了。再看槽位6,G的商是6,而这个槽位已经被F占了,但槽位6仍然是拥有一个与它对应的商值的,虽然G不在槽位6,槽位6的is_occupied依然是1;
- is_continuation: 是否连续的。以DE为例,他们的商值都是3,因为槽位3已经被C占据,他们被迫往后顺延,这种情况我们称DE对于C而言是连续,因此DE的is_continuation值均为1。而F的商值是6,和CDE就不再连续了,所以F这个槽位的is_continuation值为0;
- is_shifted: 是否被移动了。主语是当前槽位内的值。如B,根据商值它应该放在槽位1,但被迫往后顺延到了槽位2,因此它的is_shifted值为1。C则原本就在槽位3,is_shifted为0,DEFGH都是同理,被迫往后顺延了,因此is_shifted都是1;
1.2 对比总结
| 过滤器类型 | 空间消耗 | 查找开销 | 删除支持 |
|---|---|---|---|
| 标准布隆过滤器 | 1 | k | no |
| 分块布隆过滤器 | 1x | 1 | no |
| 计数布隆过滤器 | 3x ~ 4x | k | yes |
| d-left CBF | 1.5x ~ 2x | d | yes |
| 商过滤器 | 1x ~ 1.2x | ⩾ \geqslant ⩾ 1 | yes |
| 布谷鸟过滤器 | ⩽ \leqslant ⩽ 1x | 2 | yes |
注:k和d在上文中都有提及,不再解释;1x表示比1多一点点,3x ~ 4x表示为1的3~4倍左右;
相关的一些过滤器变种在这里就介绍完了,关于布谷鸟过滤器的深入研究,将在下篇中继续。