C语言 编译和链接
- 引言
- 翻译环境
- 运行环境
- 声明
- 一、预定义符号
- 二、#define 符号
- 1. #define 定义标识符
- 2. #define 定义宏
- 宏带来的陷阱
- 宏的两个特殊的使用场景
- ① 使用 #,把一个宏参数变成对应的字符串
- ② 使用 ##,将两个宏参数合并成一个符号
- 宏参数的使用
- 3. #define 定义宏和函数的区别
- 4. #undef
- 三、头文件包含
- 嵌套头文件
引言
在 ANSI C 的任何一种实现中,存在两个不同的环境。
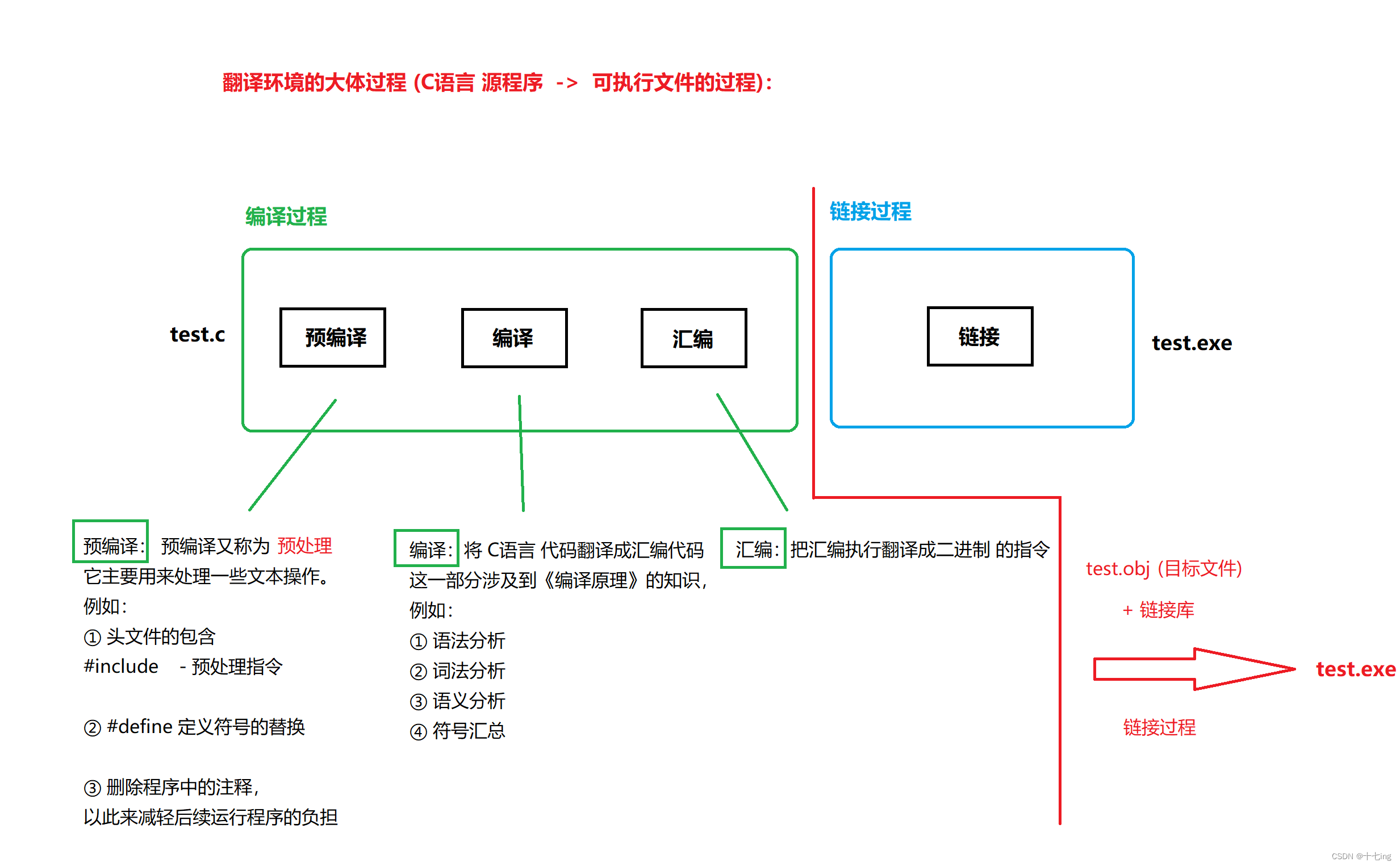
第一种是翻译环境,在这个环境中,源代码被转换为可执行的二进制指令。
翻译环境即我们日常使用编译器,将一个 " test.c " 的文件最终变成一个 " text.exe " 的可执行文件的一个过程。
第二种是运行环境,它用于实际执行代码。
运行环境一般是由操作系统对 " test.exe " 可执行文件进行解析执行的结果。
翻译环境
一图说明翻译环境 (C语言 源程序转换成可执行文件的过程):
运行环境
程序执行的过程:
① 一般来说,程序先是被操作系统载入到内存中。在独立的环境中,程序的载入也可能是通过可执行代码置入只读内存来完成。
② 程序运行开始,接着便调用 main 函数。
③ 操作系统开始执行程序代码。这个时候程序将使用一个运行时堆栈,用来存储函数的局部变量和返回地址。程序同时也可以使用静态 (static) 内存,存储于静态内存中的变量在程序的整个执行过程一直保留它们的值。
④ 终止程序。操作系统正常终止 main 函数,也有可能是意外终止。
声明
由于翻译环境中的编译、汇编涉及到过多的汇编代码知识。运行环境涉及到了的操作系统的知识。所以它们不在本篇博客讨论范围内,那么本篇博客的后续内容,我将只展开讨论 C语言 预编译的过程和其对应的一些细节。
一、预定义符号
__FILE__ // 进行编译的源文件
__LINE__ // 文件当前的行号
__DATE__ // 文件被编译的日期
__TIME__ // 文件被编译的时间
__STDC__ // 如果编译器遵循 ANSI C,其值为 1,否则未定义
二、#define 符号
1. #define 定义标识符
#include <stdio.h>
#define MAX 100
#define STR "hello world"
int main() {
int n = MAX;
// 预处理后变成:int n = 100;
char arr[] = STR;
// 预处理后变成:char arr[] = "hello world";
printf("%d\n", n);
printf("%s\n", arr);
return 0;
}
// 输出结果:
// 100
// hello world
2. #define 定义宏
#include <stdio.h>
#define MAX(x,y) (x>y?x:y)
int main() {
int a = 10;
int b = 20;
int n = MAX(a, b);
// 预处理后变成:int n = (a>b?a:b);
printf("%d\n", n);
return 0;
}
// 输出结果:20
宏带来的陷阱
程序清单1:
#include <stdio.h>
#define SQL(x) x*x
int main() {
int n = 9;
int result1 = SQL(n);
// 预处理后变成:result1 = n*n;
int result2 = SQL(n + 1);
// 预处理后变成:int result2 = n+1*n+1;
printf("%d\n", result1 );
printf("%d\n", result2);
return 0;
}
// 输出结果:
// 81
// 19
从上面的第二个输出结果来看,宏带来了运算符优先问题。由于 #define 在定义宏的时候,是直接对参数进行替换的。所以我们第二个预期为 " 100 " 的结果,最终变成了 19.
程序清单2:
我们可以利用加括号的方式,来解决优先级的运算符的问题。
#include <stdio.h>
#define SQL(x) ((x)*(x))
int main() {
int n = 9;
int result1 = SQL(n);
// int result1 = ((n)*(n));
int result2 = SQL(n + 1);
// int result2 = ((n+1)*(n+1));
printf("%d\n", result1);
printf("%d\n", result2);
return 0;
}
// 输出结果:
// 81
// 100
宏的两个特殊的使用场景
① 使用 #,把一个宏参数变成对应的字符串
#include <stdio.h>
#define PRINT(N) printf("the value of "#N" is %d\n", N)
int main() {
int a = 10;
PRINT(a);
// 预处理后变成:printf("the value of ""a"" is %d\n", a);
int b = 20;
PRINT(b);
// 预处理后变成:printf("the value of ""b"" is %d\n", b);
return 0;
}
// 输出结果:
// the value of a is 10
// the value of b is 20
② 使用 ##,将两个宏参数合并成一个符号
#include <stdio.h>
#define MERGE(str1, str2) str1##str2
int main() {
int class_room = 123;
printf("%d\n", MERGE(class_, room));
// 预处理后变成:printf("%d\n", class_room);
return 0;
}
// 输出结果:123
宏参数的使用
#include <stdio.h>
#define MAX(a, b) ( (a) > (b) ? (a) : (b) )
int main() {
int x = 5;
int y = 8;
int z = MAX(x++, y++);
// int z = ((x++) > (y++) ? (x++) : (y++));
// -> int z = ((5++) > (8++) ? (x++) : (y++)); // x=6, y=9
// -> int z = ((6) > (9) ? (x++) : (9++));
// -> int z = 9++; // x=6, y=10, z=9
printf("x=%d y=%d z=%d\n", x, y, z);
return 0;
}
// 输出结果:x=6 y=10 z=9
从上面的程序来看,原本我们是想求两个数中最大的一个数值,但由于自增所带来改变自身值的问题,导致宏参数在宏使用的时候,被修改了。这就间接地导致了上面的 x、y、z 的值也被修改了。
所以,我们可以得出结论: 当宏参数在宏的定义中出现超过一次的时候,如果宏参数影响本身的值,那么后续在使用这个宏的时候就可能出现不可预测的后果。按照当前的程序来看还好些,如果自增自减用的再复杂一些,你很难想象底层是怎么参与运算的。
3. #define 定义宏和函数的区别
| #define 定义宏 | 函数 | |
|---|---|---|
| 执行速度 | 更快 | 相对宏的速度较慢,函数调用和函数返回都需要开销 |
| 调试 | 宏不能够调试 | 函数可以调试 |
| 递归 | 宏不能够递归 | 函数可以递归 |
| 命名 | 一般宏的名字全部大写 | 函数名不需要全部大写 |
4. #undef
#undef 用于移除一个宏定义,如下面的 error 注释 上面的一行,就是移除了 MAX 这个宏。之后再次使用的时候,就没有 MAX 这个定义了。
#include <stdio.h>
#define MAX(x,y) (x>y?x:y)
#define MIN -100
int main() {
int a = 10;
int b = 20;
int n = MAX(a, b);
// int n = (a>b?a:b);
printf("%d\n", n);
#undef MAX
int n = MAX(a, b); // error
return 0;
}
三、头文件包含
在引言的地方,我提到了 #include 头文件包含属于预编译的过程,它其实也是进行了相关的文本替换。但 C语言 的头文件分为两种,第一种是和库相关的库文件;第二种是本地文件包含。
如下面的程序:
注释1 为库文件包含,查找头文件的时候是直接去标准路径下去查找,如果找不到就提示编译错误。
注释2 为本地文件包含,查找策略:先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。如果找不到就提示编译错误。
#include <stdio.h> // 1
#include "function.h" // 2
嵌套头文件
#include "function.h"
#include "function.h"
#include "function.h"
如上所示,如果我们在程序中重复引入头文件,就会在预编译的情况下,带来重复的文本替换。例如上面引入了三个头文件,那么在预编译时,就会存在三个同样的文本替换,这也被称为嵌套了头文件。
如果预编译期间存在重复的文本内容,在后续的编译过程中,一定存在效率的降低。那么,如何解决头文件的重复引入呢?
① 使用条件编译解决:
#ifndef __TEST_H__
#define __TEST_H__
#endif
② 使用 #pragma:
#pragma once