PageRank 算法
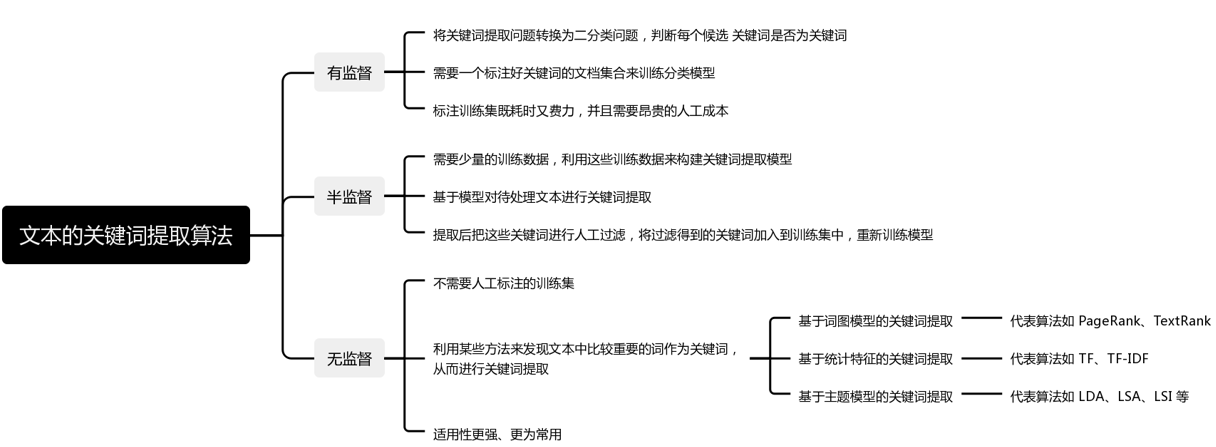
基于词图模型的关键词提取算法主要有 PageRank 和 TextRank。
PageRank 是 TextRank 算法的思想基础,TextRank 是 PageRank 在文本上的应用。
来源:
Google 创始人拉里·佩奇和谢尔盖·布林于 1997 年构建早期的搜索系统原型时提出的链接分析算法,通过计算网页链接的数量和质量来粗略估计网页的重要性。
应用:
该算法创立之初即应用在谷歌的搜索引擎中,是谷歌搜索的核心算法,对网页进行排名,从而解决互联网网页的价值排序问题。
核心思想 :
链接数量 :如果一个网页被很多其他网页链接到,说明这个网页比较重要,也就是 PageRank 值会相对较高。
链接质量 :如果一个 PageRank 值很高的网页链接到一个其他的网页,那么被链接到的网页的 PageRank 值会相应地因此而提高。
基本原理:
可以将整个万维网看作一张有向图,网页构成了图中的节点。任务是从图中挖掘每个节点的权重作为其重要性的度量。一个节点如果由很多个其他节点指向它,那么这个节点应该就很重要。同样,如果有多个高权重的节点指向某一节点,且这个节点指向外部的链接数很少,那么这个被链接的点显然非常重要。
S(vi) 是网页 i 的重要性(PR 值),初始为1。
d 是阻尼系数,一般设置为 0.85。
In(vi) 表示节点 vi 的前驱节点集合。
Out(vj) 表示节点 vj 的后继节点集合;
|Out(vj)| 是集合中元素的个数。
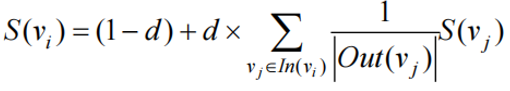
算法流程:
①给每个网页一个 PageRank 值(简称 PR 值)。
②通过(投票)算法不断迭代,直至达到平稳分布为止。
案例分析:
如图所示,有 A、B、C 三个页面,假设三者的初始 PR 值都是 1,d=0.85,计算每个网页的权重。
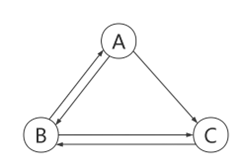
计算权重:
PR(A) = 0.15 + 0.85 * ( PR(B) / 2 )
= 0.15+0.85 * 0.5
= 0.575
PR(B) = 0.15 + 0.85 * ( PR(A) / 2+ PR( C) )
= 0.15+0.85 * 1.5
= 1.425
PR( C) = 0.15 + 0.85 * ( PR(B) / 2+ PR(A) /2)
= 0.15+0.85 * 1
= 1
所以网页 B 是图中最重要的节点。
TextRank 算法
TextRank 算法是一种基于图的、用于处理文本的排序算法。
来源:
由 PageRank 算法改进而来,区别:PageRank 算法根据网页之间的链接关系来构建网络,而 TextRank 算法是根据词之间的共现关系来构建网络。即:TextRank 算法以词作为节点,以共现关系建立起节点之间的链接,每个词的外链来源于该词前后固定大小窗口的所有词。
应用:
TextRank 算法最早用于文档的自动摘要,基于句子维度的分析,利用 TextRank 对每个句子进行打分,挑选出分数最高的 n 个句子作为文档的关键句,以达到自动摘要的效果。 后来,该算法利用一篇文档内部的词语之间的共性信息(语义)来抽取关键词,能够从一个给定的文本中抽取出关键词、关键词组,并用抽取式的自动摘要方法抽取出关键句。
核心思想:
TextRank 算法将文档看做词语的网络,该网络中的链接表示词语之间的语义关系。
①如果一个单词在很多单词边上都会出现,说明这个单词比较重要。
②一个 TextRank 值很高的单词边上的单词,TextRank 值会相应的因此而提高。
算法原理:
PageRank 算法构造的网络是有向无权图,而 TextRank 算法构造的网络是无向有权图。 除了考虑链接句的重要性之外,还考虑两个句子之间的相似性。计算每个句子给它链接句的贡献时,不是通过平均分配的方式,而是通过计算权重占总权重的比例来分配。这里的权重即指句子之间的相似度,可通过编辑距离、余弦相似度等来进行计算。
TextRank 算法构建一张关系图来表达文本、词语以及其他实体。词语、词语集合、整个句子等都可以作为图中的顶点,在这些顶点之间建立联系(如词序关系、语义关系、内容相似度等),就能够构建一张合适的关系图。
基于 PageRank 计算权重的公式,TextRank 算法改写为如下公式来计算权重 :
参数说明:
d :阻尼系数,取值范围为 0 ~ 1;代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。
In(vi) :指向节点 vi 的所有单词集合。
:分子表示词 vj 链接到 vi 的权重;分母表示节点 vj 指向的所有链接的权重和。
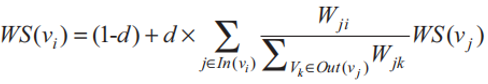
当 TextRank 应用到关键词提取时,与应用在自动摘要中时有两点不同 :
(1)单词之间 的关联是没有权重的 ;将得分平均贡献给每个链接的词。
(2)每个单词并不是与文本中所有词都有链接。(专家学者提出窗口的概念,在窗口中的词相互间都有链接关系。得到链接关系就 可以套用 TextRank 的公式,对每个词的得分进行计算,最后选择得分最高的 n 个词作为 文档的关键词。)
算法流程:
使用 TextRank 算法提取关键词和关键词组的具体步骤如下 :
①将原文本分割成句子。
②对每个句子进行分词,并做词性标记,然后去除停用词,只保留指定词性的词(如名词、动词、形容词等)。
③构建词图,节点集合由以上步骤生成的词组成,然后用共现关系构造任意两个节点之间的边:两个节点之间存在边仅当它们对应的词在长度为 K 的窗口中共现,K 表示窗口大小,即最多共现 K 个单词,一般 K 取 2。
④迭代计算各节点的权重,直至收敛,得到各节点重要性的分值。
⑤对各节点的权重进行倒序排序,得到最重要的 N 个单词,作为 top-N 关键词进行输出。
⑥在原文本中标记 top-N 关键词,若它们之间形成了相邻词组,则作为关键词组提取出来。
算法特点:
优点:
● 无监督方式,无需构造数据集训练。
● 算法原理简单,部署简单。
● 继承了 PageRank 的思想,效果相对较好,可以更充分的利用文本元素之间的关系, 综合考虑文本整体的信息来确定哪些词或句子可以更好的表达文本。
缺点:
● 结果受分词、文本清洗影响较大,即对于某些停用词的保留与否,直接影响最终结果。
● 虽然不只利用了词频,但是仍然受高频词的影响,因此,需要结合词性和词频进行筛选,以达到更好效果,但词性标注显然又是一个问题。
注意:其他算法的关键词提取都要基于一个现成的语料库,而 TextRank 算法不需要。
案例分析:
对于 TextRank 的算法,目前已经有很多优秀的开源实现,在此分别利用结巴分词和 TextRank4zh 两种方法去实现 TextRank 算法。
1.采用结巴分词工具的方式实现 TextRank 算法
(1)使用结巴分词工具之前,要先安装 jieba 分词工具。可在终端中使用如下命令进行安装:pip install jieba
(2)导入结巴分词工具包,用 jieba.analyse.extract_tags 函数来提取关键词。
用法 :keywords = jieba.analyse.extract_tags(content, topK=5, withWeight=True, allowPOS=())
参数 :
● content, :待提取关键词的原文本。
● topK :返回关键词的数量,重要性从高到低排序。
● withWeight :是否同时返回每个关键词的权重。
● allowPOS:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词。
import jieba.analyse
str = " 基于词图模型的关键词提取算法 TextRank"
result = jieba.analyse.extract_tags(str,withWeight=True)
print(result)

2.采用 TextRank4zh 的方式实现 TextRank 算法
(1)先安装 textrank4zh 模块。可使用以下命令: pip install textrank4zh
(2)导入 textrank4zh 模块,使用其中的 TextRank4Keyword 可以提取关键词。
另外, 如果想提取关键句也可以使用其中的 TextRank4Sentence。 在关键词提取时,用到两个函数 :analyze 和 get_keywords。
① analyze 函数:对文本进行分析。
② get_keywords 函数:获取最重要的关键词,关键词的数量是 num 个,且每个的长度要大于等于 word_min_len。
from textrank4zh import TextRank4Keyword # 导入相关模块
if __name__ == '__main__': # 定义要提取的文本
text = (" 燕山大学是河北省人民政府、教育部、工业和信息化部、国家国防科技工业局四方共建的全国重点大学,河北省重点支持的国家一流大学和世界一流学科建设高校, 北京高科大学联盟成员。")
tr4w = TextRank4Keyword() # 关键词提取
tr4w.analyze(text=text, lower=True, window=5)
print(' 关键词 :')
for item in tr4w.get_keywords(10, word_min_len=1):
print(item['word'], item['weight'])

TF-IDF 算法
基于统计特征的关键词提取算法:
基本思想:
利用文档中词语的统计信息来抽取适当的关键词,通常将文本经过预处理得到候选词语的集合,然后采用特征值量化的方式从候选集合中得到关键词。
关键: 采用什么样的特征值量化指标。
评估词的重要性的常见指标:
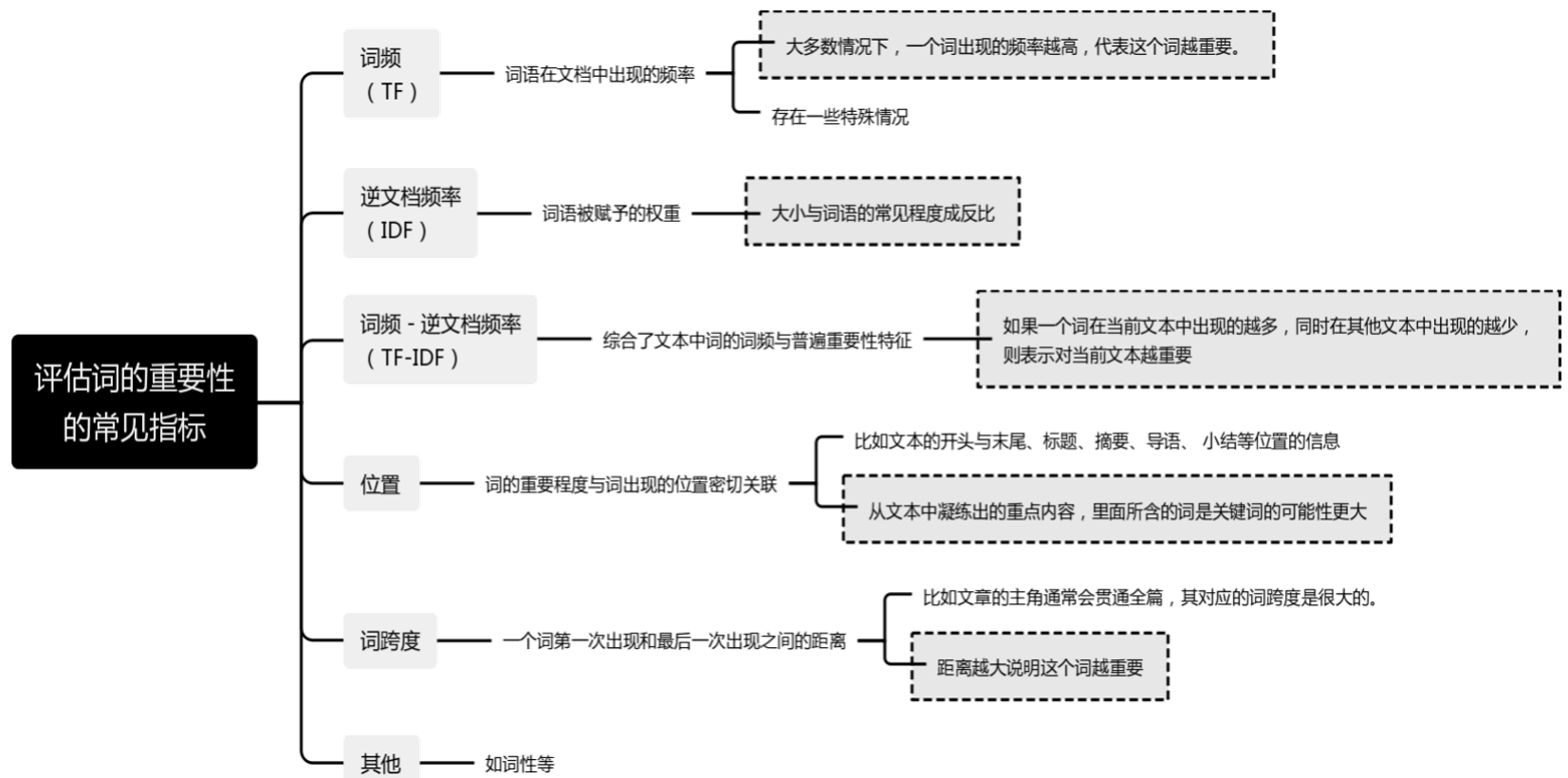
TF-IDF算法:
TF-IDF 是一种统计方法,是一种用于信息检索与文本挖掘的常用加权技术,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性与它在文本中出现的次数成正比关系,与它在语料库中出现的频率成反比关系。
应用:在搜索引擎、关键词提取、文本相似性、文本摘要等领域都有所应用。
基本原理:
1.计算词频TF:
如果某个词在当前文本中出现的频率(TF)高,并且在其他文本 中出现的频率(TF)低,则认为这个词具有很好的类别区分能力,适合用来分类。
计算公式:

2.计算逆文档频率 IDF:
计算 IDF 时需要一个语料库,用来模拟语言的使用环境。如果一个词越频繁出现,则分母越大,逆文档频率 IDF 就越小、越接近 0。分母之所以要加 1,是为了避免分母为 0,即所有文档都不包含该词。
计算公式:
3.计算TF-IDF:
先计算得到 TF 和 IDF,然后可以让二者相乘来计算 TF-IDF。TF-IDF 与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。
计算公式:
算法流程:
(1)对原文本进行分词,做词性标注和去除停用词等数据预处理操作,得到候选关键词。
(2)计算某词语在原文本中的词频 TF。
(3)计算该词语在整个语料库的逆文档频率 IDF。
(4)计算该词语的 TF-IDF 值(TF*IDF),并重复(2)~(4)步骤,得到所有候选关键词的 TF-IDF 值。
(5)对候选关键词的 TF-IDF 值进行倒序排列,得到排名前 Top-N 个词汇作为文本关键词。
算法举例:
假定某本书共有 50w 个词,其中“词向量”共出现 9800 次,“文本”出现 14000 次,“自然语言”出现了 17000 次;假设我们的语料库中共有 10000 个文档,包含“词向量”的文档数为 347 个,包含“文本”的文档数为 621 个,包含“自然语言”的文档数为 440 个。计算这三个词的 TF-IDF。
(1)计算词频。
TF(" 词向量 “)=9800/500000=0.020
TF(” 文本 “)=14000/500000=0.028
TF(” 自然语言 “)=17000/500000=0.034
(2)计算逆文档频率。
IDF(” 词向量 “)=log(10000/(347+1))=1.458
IDF(” 文本 “)=log(10000/(621+1))=1.206
IDF(” 自然语言 “)=log(10000/(440+1))=1.356
(3)计算TF-IDF。
TF-IDF(” 词向量 “)=TF(” 词向量 “)IDF(" 词向量 ")=0.0201.458=0.0292
TF-IDF(” 文本 “)=TF(” 文本 “)IDF(" 文本 ")=0.0281.206=0.0338
TF-IDF(” 自然语言 “)=TF(” 自然语言 ")IDF(" 自然语言 ")=0.0341.356=0.0461
“自然语言”这个词的 TF-IDF 值最大,“文本”次之,“词向量”最小。如果只取一个关键词,则取“自然语言”一词。
算法特点:
优点 :简单快速,提取结果较符合实际情况。
缺点 :
①单纯以词频来衡量一个词的重要性,不够全面。
②未考虑词的位置的影响,出现位置靠前或靠后的词被视为同等重要。
③严重依赖语料库,需要选取高质量且与待处理文本相符的语料库进行训练。
TF-IDF关键词提取案例:
用 TF-IDF 算法实现关键词提取。
Python 第三方工具包 Scikit-learn 提供了 TF-IDF 算法的相关函数。本案例主要用到了sklearn.feature_extraction.text 类的 TfidfTransformer 和 CountVectorizer 函数。
● TfidfTransformer 函数 :用来计算词语的 TF-IDF 权值。其参数 smooth_idf,默认值是 True。若设置为 False,则计算 IDF。
● CountVectorizer 函数 :用来构建语料库中的词频矩阵。
实现步骤:
(1)安装 pandas 和 sklearn。
pip install pandas
pip install sklearn
(2)导入相关模块。
import sys,codecs
import pandas as pd
import numpy as np
import jieba.posseg # 词性标注
import jieba.analyse # 提取关键词
from sklearn import feature_extraction # 文本特征提取
from sklearn.feature_extraction.text import TfidfTransformer # 文本特征提取—TF-IDF权值计算
from sklearn.feature_extraction.text import CountVectorizer # 文本特征提取—特征数值计算
(3)读取样本源文件。定义标记函数,读取语料文件,读取完成后会调用标记函数生成标记文件 flag1。
def create__file(file_path):
f=open(file_path,'w')
f.close
# 读取数据集(语料)
dataFile = './data/sample_data - Copy.csv'
data = pd.read_csv(dataFile)
create__file('./data/flag1')
(4)数据预处理。对读取到的数据进行预处理,包括分词、去停用词和词性筛选。处理完成后生成标记文件 flag2 ,表示预处理部分完成。
注意 :dataPrepos 函数中的词性标注有如下含义 :
● 词性编码为 ‘n’ :表示词性是名词。
● 词性编码为 ‘nz’ :表示词性是其他专有名词。
● 词性编码为 ‘v’ :表示词性是动词。
● 词性编码为 ‘vd’ :表示词性是副动词(直接做状语的动词)。
● 词性编码为 ‘vn’ :表示词性是名动词(具有名词功能的动词)。
● 词性编码为 ‘l’ :表示词性是习用语。
● 词性编码为 ‘a’ :表示词性是形容词。
● 词性编码为 ‘d’ :表示词性是副词。
# 停用词表
stopWord = './data/stopWord.txt'
stopkey = [w.strip() for w in codecs.open(stopWord, 'rb').readlines()]
# 数据预处理操作:分词,去停用词,词性筛选
def dataPrepos(text,stopkey):
l = []
pos = ['n','nz','v', 'vd', 'vn', 'l', 'a', 'd'] # 定义选取的词性
seg = jieba.posseg.cut(text) # 分词
for i in seg:
if i.word not in stopkey and i.flag in pos: # 去停用词 + 词性筛选
l.append(i.word)
return l
create__file('./data/flag2')
(5)构建 TF-IDF 模型,计算 TF-IDF 矩阵。
● 构建词频矩阵,
● 计算语料中每个词语的 TF-IDF 权值,
● 获取词袋模型中的关键词,
● 获取 TF-IDF 矩阵,
● 完成后生成标记文件 flag3。
def get_tfidf(data):
# 1. 构建词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(data) # 词频矩阵,a[i][j]: 表示 j 词在第 i 个文本中的词频
# 2. 统计每个词的 TF-IDF 权值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
# 3. 获取词袋模型中的关键词
word = vectorizer.get_feature_names()
# 4. 获取 TF-IDF 矩阵,a[i][j] 表示 j 词在 i 篇文本中的 TF-IDF 权重
weight = tfidf.toarray()
create__file('./data/flag3')
(6)排序输出关键词,将结果写入文件。计算好每个词的 TF-IDF 权值之后,对权值进行排序,并以“词语,TF-IDF”的格式依次输出。全部输出完毕后生成标记文件 flag4 表示环节完成,然后将结果写入文件 keys_TFIDF.csv 中。
def getKeywords_tfidf(data, stopkey, topk):
idList, titleList, abstractList = data['id'], data['title'], data['abstract']
corpus = [] # 将所有文档输出到一个 list 中,一行就是一个文档
for index in range(len(idList)):
text = '%s。%s' % (titleList[index], abstractList[index]) # 拼接标题和摘要
text = dataPrepos(text, stopkey) # 文本预处理
text = " ".join(text) # 连接成字符串,空格分隔
corpus.append(text)
# 1. 构建词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus) # 词频矩阵 ,a[i][j]: 表示 j 词在第 i 个文本中的词频
# 2. 统计每个词的 TF-IDF 权值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
# 3. 获取词袋模型中的关键词
word = vectorizer.get_feature_names()
# 4. 获取 TF-IDF 矩阵,a[i][j] 表示 j 词在 i 篇文本中的 TF-IDF 权重
weight = tfidf.toarray()
create__file('./data/flag3')
# 5. 打印词语权重
ids, titles, keys = [], [], []
for i in range(len(weight)):
print(u"------- 这里输出第 ", i + 1, u" 篇文本的词语 tf-idf------")
ids.append(idList[i])
titles.append(titleList[i])
df_word, df_weight = [], [] # 当前文章的所有词汇列表、词汇对应权重列表
for j in range(len(word)):
print(word[j], weight[i][j])
df_word.append(word[j])
df_weight.append(weight[i][j])
df_word = pd.DataFrame(df_word, columns=['word'])
df_weight = pd.DataFrame(df_weight, columns=['weight'])
keyword = np.array(word_weight['word']) # 选择词汇列并转成数组格式
word_split = [keyword[x] for x in range(0, topk)] # 抽取前 topK 个词作为关键词
word_split = " ".join(word_split)
keys.append(word_split)
result = pd.DataFrame({"id": ids, "title": titles, "key": keys}, columns=['id', 'title', 'key'])
create__file('./data/flag4')
return result
result = getKeywords_tfidf(data, stopkey, 10)
result.to_csv("./data/keys_TFIDF.csv", index=False)
程序运行后,控制台会分别输出语料文件中每一条文本的所有词语的 TF-IDF 权值。