👂 Raindrops (Intl. Version) - Katja Krasavice/Leony - 单曲 - 网易云音乐
👂 Rush E (Playable Version) - Sheet Music Boss - 单曲 - 网易云音乐
👂 最美的瞬间 - 真瑞 - 单曲 - 网易云音乐
👂 你可别卷了 - SipSu小口酥/灯灯灯泡/迟亦骁 - 单曲 - 网易云音乐
上篇博客地址:STL入门 + 刷题(上)_千帐灯无此声的博客-CSDN博客
书中题目都是中文,但是做题网站大多数都英文,建议看一句中文看一句英文,来培养英文阅读能力,为日后PAT甲级做准备(强制自己完整阅读完100道英文题目,你的阅读能力会飞跃)
目录
🍉迭代器
🍉2.4.7 bitset
🌳概念
🌳例题 Set Operation
🍉2.4.8 set / multiset
🌳概念
🌳例题1 {A} + {B}
🌳例题2 MANAGER 并行处理
样例解释
思路
坑
AC 代码
🍉2.4.9 map / muitimap
🌳概念
🌳例题1 Hardwood Species 硬木种类
🌳例题2 Double Queue 双重队列
🌳例题3 水果
🍉2.4.10 STL常用函数
1)fill(begin, end, val)
2)sort(begin, end, compare)
3)nth_element(begin, begin + k, end, compare)
4)lower_bound(begin, end, x) / upper_bound(begin, end, x)
5)next_permutation(begin, end) / pre_permutation(begin, end)
🌳例题1 Median 差的中位数
🌳例题2 Who's in the Middle 中位数
🌳例题3 Orders 订单管理
🌳例题4 Anagram 字谜
😄总结
🍉迭代器
迭代器作为这两篇STL的前置知识,在这里讲下
先看这篇(看一半就够了)C++迭代器_Zhc_AuC的博客-CSDN博客
迭代器是类似指针的对象,输出所指向的值需要解引用(*it),比如👇
for(set<int>::iterator it = sum.begin(); it != sum.end(); ++it)
printf("%d ", *it);同时,输出某个成员时,需要在对象和成员之间加 ->,表示“的”的意思
比如 it->first, it->second,表示键和值,比如👇
for(map<string,int>::iterator it=mp.begin();it!=mp.end();it++){
cout<<it->first<<" ";🍉2.4.7 bitset
🌳概念
bit是多位二进制数,状压二进制数
需要头文件#include<bitset>
bitset<1000>s; //定义一个1000位二进制数s基本位运算:~取反,&与,|或,^异或,>>右移,<<左移,==相等比较,!=不等比较
支持[]操作符得到第k位的值,也可s[k] = 1赋值
需要注意的是
最右侧低位为0位,由右向左依次增大,比如1000位二进制数,位序是右->左,0~999
突然发现,引用别人文章,真的省事啊,省的自己再花费大量时间总结一次,提高效率
基本操作
.count() //1的位数
.any() //是否存在1
.none() //全为0
.set() //所有位变1
.set(k) //第k位变1
.set(k,val) //第k位变val
.reset() //所有位变0
.reset(k) //第k位变0, 即s[k] = 0
.flip() //所有位取反
.flip(k) //第k位取反
.size() //位数
.to_ulong() //转换为unsigned long的结果, 超范围就报错
.to_string() //转换为stirng的结果 1,关于位运算
(2条消息) c++之位运算(详解,初学者绝对能看懂)_c++位运算_?!??的博客-CSDN博客
位运算优先级较低,一般加括号 ()
2,关于bitset
【c++STL——第十讲】bit set系列 (常用知识点总结)_#include <bitset>_quicklysleep的博客-CSDN博客
来点GPT总结
总结
STL 中的
bitset是一种特殊类型的数组,它能够存储并操作二进制位。bitset相较于传统的数组有如下好处:
内存占用小
bitset类型变量所占内存不取决于变量长度,而取决于数据类型的大小,因此使用bitset类型能更好地控制内存的使用。高效
对于各种位运算操作,bitset的效率通常比传统数组要高,因为bitset实现时使用了位运算技术, 而且其底层实现采用的是压缩编码思想,所以在进行位操作时更加高效。方便
bitset提供了很多与二进制位有关的操作函数,可以方便地进行二进制位的设置、清除、翻转等操作。使用bitset可以使代码的可读性和可维护性更高,且使代码更不容易出错。安全
bitset类型在访问越界时会报错,这有效避免了程序出现隐患和异常。总之,使用
bitset有利于提高程序的效率、安全性与可读性,尤其适用于需要大量的位运算操作的场景,例如计算机网络、密码学等领域
🌳例题 Set Operation
Set Operation - POJ 2443 - Virtual Judge (vjudge.net)
本题不是多组输入输出,不用考虑清空的问题
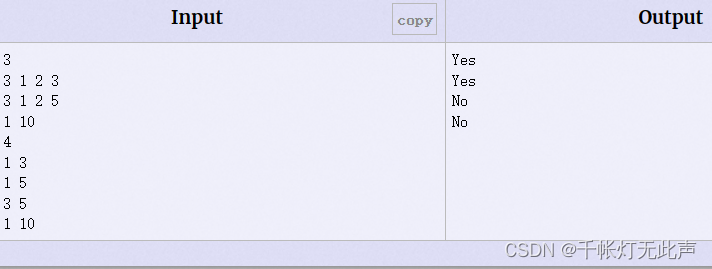
本题查询2个元素是否属于同一个集合(至少1个),所属集合用二进制表示法
初始声明
#include<bitset>
const int maxn = 10010;
bitset<1010>s[maxn];//1010位二进制, 表示集合数量; maxn表示元素最大值👆当你定义了s[maxn],每个s[i]都表示一个二进制数,此时类似二维数组
结合题目s[1] = 0110 --> 表示1属于第1,2个集合
那么举个例子,比如s[2][3] = 1表示2属于第3个集合 (注意索引从0开始)
本题精髓
第 i 个二进制数的第 k 位 == 第 j 个二进制数的第 k 位 == 1
表示元素 i 和元素 j 同属于第 k 个集合,可输出"Yes"
思路
每个元素用一个二进制数,记录所属集合
注意!!最右侧低位为0,也就是右侧下标从0开始,所以1位实际上是第2个位置
例如样例中
1属于第1个集合,所以s[1] = 0010 --> 第1位为1
1属于第2个集合,所以s[1] = 0100 --> 第2位为1
合起来就是 s[1] = 0110 --> 表示1属于第1,2个集合
同理可得
s[2] = 0110, s[3] = 0010, s[5] = 0100, s[10] = 1000(10属于第3个集合)
得到了每个元素,分别属于哪些集合,下一步就要查询
怎么查询呢
与位运算:&
查询1和3是否属于同一集合,只需要计算 s[1] & s[3] = (0110 & 0010) = 0010,统计1的个数,不为0,即可判断属于一个集合,输出"Yes";为0则输出"No"
AC 代码
#include<iostream>
#include<bitset>
#include<cstdio> //scanf(), printf()
using namespace std;
//const int maxn = 10010;
#define maxn 10010
bitset<1010>s[maxn]; //1010位二进制, 表示集合数量; maxn表示元素最大值
int main()
{
int n, m, x, q; //n个集合, 这个集合m个元素, 元素值x
scanf("%d", &n);
//读入n个集合, s[1] == 0110的方式用二进制数保存起来
for(int i = 1; i <= n; ++i) { //第i个集合
scanf("%d", &m);
while(m--) {
scanf("%d", &x);
s[x][i] = 1; //x属于第i个集合
}
}
//q次询问
scanf("%d", &q);
int c, d;
while(q--) {
scanf("%d%d", &c, &d); //c, d是否属于同一集合
if((s[c] & s[d]).count()) //统计位运算与后, 1的个数
printf("Yes\n");
else
printf("No\n");
}
return 0;
}
🍉2.4.8 set / multiset
🌳概念
可以先看看这篇C++ STL set容器完全攻略(超级详细) (biancheng.net)
STL提供4钟关联容器:set, multiset, map, multimap。
关联容器将键 / 值关联在一起,通过键查找值。
这4钟容器都是可反转的经过排序的关联容器,不可指定插入位置,因为要保持有序性。
内部是红黑树实现。
set是有序集合,multiset是多重有序集合。
set键和值统一,键就是值,值就是键,且每个键唯一,不允许重复。
而multiset与set类似,但允许多个值的键相同。
需要#include<set>
set和multiset的迭代器为双向访问。
执行一次 ++ 和 -- 操作的复杂度均为O(logn)
默认升序,也可通过👇第二个模板的参数设置为降序
set<int>a; //升序
set<int, greater<int> >a; //降序,注意greater<int>后有空格
//避免两个符号一起>>,有右移歧义成员函数
size/empty/clear //元素个数 判空 清空
begin/end //开始和结束位置
inset(x) //元素x插入集合
erase(x) //删除所有值为x的元素
erase(it) //删除it迭代器指向的元素
find(x) //查找x在集合的位置,不存在则返回end
count(x) //统计x元素的个数
lower_bound(x) //返回大于等于x的最小元素位置
upper_bound(x) //返回大于x的最小元素位置🌳例题1 {A} + {B}
{A} + {B} - HDU 1412 - Virtual Judge (vjudge.net)
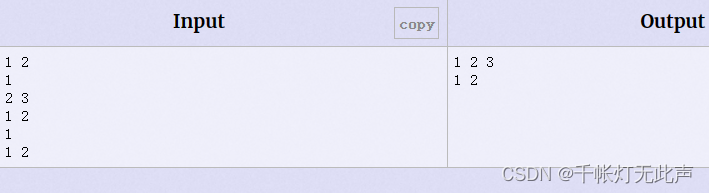
需要注意的是,学到目前为止,STL中支持数组下标访问的(数组表示法),只有vector和deque,其他STL容器都是需要用迭代器访问的
AC 代码
#include<iostream>
#include<cstdio> //scanf(), printf()
#include<set>
using namespace std;
set<int>sum;
int main()
{
int a, b, x;
while(scanf("%d%d", &a, &b) != EOF) { //多组输入
sum.clear(); //每组测试要清空
for(int i = 1; i <= a + b; ++i) {
scanf("%d", &x);
sum.insert(x);
}
//输出合并后的集合
for(set<int>::iterator it = sum.begin(); it != sum.end(); ++it)
printf("%d ", *it);
printf("\n");
}
return 0;
}
下面对迭代器的使用加以记忆
//1
vector<int>::iterator it;
//2
for(set<int>::iterator it = sum.begin(); it != sum.end(); ++it)
//3
...//随便一个容器都能结合迭代器应该🌳例题2 MANAGER 并行处理
MANAGER - POJ 1281 - Virtual Judge (vjudge.net)
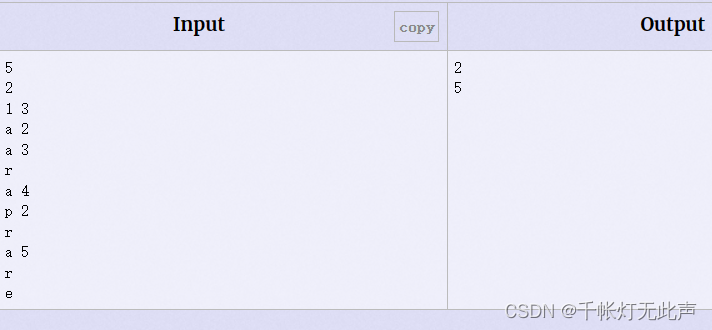
样例解释
一开始没理解输出2,5的时机,原来1 3表示第1次删除时,输出删除的数
第3次删除时,输出删除的数
开头的5没啥用,只是限制系统给的数据大小
考虑到有重复的数据,用multiset

强迫自己去读英文,提高对英文题目的阅读能力😵
下面👇翻译部分句子
翻译(可跳过)
Each process is identified by its cost that is a strictly positive integer in the range 1 .. 10000.
每个进程都有一个成本,1~10000的正整数
The number of processes with the same cost cannot exceed 10000.
具有相同成本的进程数不能超过10000
The queue is managed according to three types of requests, as follows
队列根据下列3钟类型的请求进行管理
- a x - add to the queue the process with the cost x;
- r - remove a process, if possible, from the queue according to the current manager policy;
- p i - enforce the policy i of the manager, where i is 1 or 2. The default manager policy is 1
- 1 - remove the minimum cost process
- 2 - remove the maximum cost process
- e - ends the list of requests.
1,a x -- 成本为x的进程添加到队列
2,r -- 根据当前管理策略,从队列中删除进程
3,p i -- 执行管理策略 i ,i 为1 或 2,1表示删除最小成本进程,2删除最大成本的,默认策略1
4,e -- 结束请求列表
........还是滚去看中文题目吧
代码中补充的点
![]() STL中end()和rbegin()的区别_rbegin() end()_Liar_27的博客-CSDN博客
STL中end()和rbegin()的区别_rbegin() end()_Liar_27的博客-CSDN博客
回到之前讲过的STL通用函数,.begin()指向容器第一个元素的指针,.end()指向容器最后一个元素下一位置的指针
记住是指针,.begin(), .end()都是迭代器(iterator),而.rbegin()和.rend()是逆向迭代器(reverse_iterator),.rbegin()指向最后一个元素,.rend()指向第一个元素前面的位置
区别是,对reverse_iterator执行递增将导致它递减
#include<iostream>
#include<vector>
using namespace std;
int main()
{
int a[5] = {1, 2, 3, 4,5};
vector<int>v(a, a + 5);
//vector<int>::reverse_iterator等价于auto
for(vector<int>::reverse_iterator r_it = v.rbegin(); r_it != v.rend(); ++r_it)
cout << *r_it << " ";//5 4 3 2 1
return 0;
}
思路
1,vis[]标记要输出的是第几个,比如vis[6] == 1,表示删除第6个数时要输出这个数
2,默认策略是,p = 1
3,读入字符,执行对应操作
4,写个删除函数,队列为空输出1;否则判断策略,p == 1,删除最小成本,,否则删除最大成本。如果删除的序号在删除列表中(即vis[i] == 1),则输出成本
还需要注意一个点,题目中,“成本大小在1~10000之间”,“每个进程都有一个成本”,“删除最小(大)成本进程”,意思是一个进程可以对应多个成本,而删除的是进程
所以vis[]数组,声明到10005就行了,每个成本对应的进程都是唯一的,即使100,1000个成本,对应着一个进程,也只需删除一次
坑
坑巨多,不想说了,要不是我有源码一一对照DEBUG,绝对过不了
1,多组输入,我也没看出题目哪里说多组输入了呀,,关键样例也就一组
2,每组输入之间加个空行(读题不仔细 --> The data sets are separated by empty lines.)
3,多组输入,每次要重新初始化,本题初始化有3行
s.clear(); //清空集合
memset(vis, 0, sizeof(vis)); //每组测试都要清空
k = 1, p = 1; //删除第k个数时输出, p策略1或24,关于if, else if, else后的错误,应该改为if, else if, else if
因为复杂情境中,可能存在空格,换行符等等留在缓冲区,这时如果直接else就会存在换行符把这种结果占了
正确
else if(c == 'r')//c == 'r'删除错误
else //c == 'r'删除AC 代码
#include<iostream>
#include<cstdio> //scanf(), printf()
#include<set>
#include<cstring> //memset()
using namespace std;
int vis[10010], k; //标记数组, 成本大小最大10000, k第几次删除
multiset<int>s; //默认升序
//删除函数
void del(int p)
{
if(s.empty()) //集合为空
printf("-1\n");
else if(p == 1) { //删除最小成本
if(vis[k++])
printf("%d\n", *s.begin()); //第一个
s.erase(*s.begin()); //s.erase(x)删除所有等于x的元素
}
else { //删除最大成本
if(vis[k++]) //*解引用指针
printf("%d\n", *s.rbegin()); //最后一个元素
s.erase(*s.rbegin());
}
}
int main()
{
int maxn, num, x, p; //p是1或2策略
while(~scanf("%d%d", &maxn, &num)) { //坑4
//坑3
s.clear(); //清空集合
memset(vis, 0, sizeof(vis)); //每组测试都要清空
k = 1, p = 1; //删除第k个数时输出, p策略1或2
for(int i = 0; i < num; ++i) {
scanf("%d", &x); //第x次删除要输出
vis[x] = 1;
}
char c;
while(scanf("%c", &c)) { //一组测试内的多组输入
if(c == 'e') break;
else if(c == 'a') {
scanf("%d", &x);
s.insert(x); //插入x
}
else if(c == 'p') {
scanf("%d", &x);
p = x;
}
else if(c == 'r')//c == 'r'删除 //坑2
del(p);
}
printf("\n"); //坑1
}
return 0;
}
补充:set / multiset 键和值是统一的
🍉2.4.9 map / muitimap
🌳概念
map的键和值可以是不同类型(与set / multiset区分),键是唯一的,每个键对应一个值
multiset与set类似,但一个键可以对应多个值
map可以当作哈希表使用,它建立了键(关键字)到值的映射
map是键和值一对一映射,multiset是一对多映射
需要头文件#include<map>
关于迭代器
map的迭代器和set类似,支持双向访问(一个iterator,一个reverse_iterator),执行一次++和--操作的时间复杂度是O(logn)
默认升序,也可通过👇第3个模板参数设置为降序
map<string, int>a; //升序
map<string, int, greater<string> >a; //降序其中greater表示用大于符号进行比较
👆上述map模板第1个参数为键的类型,第2个参数为值的类型,第3个参数可选,
表示对键进行排序的比较函数 / 对象
在map中,键和值是一对,可以用make_pair生成一对(键, 值)进行插入
a.insert(make_pair(s, i));输出时,可分别输出第1个元素(键),第2个元素(值)
for(map<string, int>::iterator it = a.begin(); it != a.end(); ++it)
cout<<it->first<<"\t"<<it->second<<endl;解释下👆上面的迭代器,首先迭代器可以理解为类似指针的对象
1,指针引用成员时,要和结构体区分,不用 . 用 ->
成员函数
size/empty/clear //元素个数,判空,清空
begin / end //指向开始 / 结束位置的指针
insert(x) //将元素x插入集合(x为二元组)
erase(x) //删除所有等于x的元素(x为二元组)
erase(it) //删除it指向的元素(it为指向二元组的迭代器)
find(k) //查找键为k的二元组的位置, 若不存在, 返回尾指针 .end()这里加以区分,map不支持数组表示法,但是它可以通过"[]"操作符,直接得到键映射的值
也可赋值操作改变键所映射的值,eg: h[key] = val(类似哈希表)
具体解释下,为什么那么像数组的东西,不是数组表示法👇,它只是map容器的语法糖
h[key] = val;
//等价于
h.insert(make_pair(key, val));
虽然看上去像是数组表示法,实际上只是调用了map容器的insert()函数,并不是真正的数组操作
例如,用map统计字符串出现的次数
map<string, int>mp;
string s;
for(int i = 0; i < n; ++i) {
cin>>s;
mp[s]++; //s就是键, 是类型为string类的字符串
}
cout<<"输入字符串s, 查询该字符串出现的次数: "<<endl;
cin>>s;
cout<<mp[s]<<endl;注意,如果查找的key(键)不存在,则执行 h[key] 后,会自动创建一个二元组 (key, 0) 并返回0
所以进行多次查找后,可能包含很多无用二元组
因此,查找前最好先查询 key(键) 是否存在👇
if(mp.find(s) != mp.end())
cout<<mp[s]<<endl;
else
cout<<"没找到"<<endl;multimap和map类似,但一个键可对应多个值。由于是一对多映射关系,不能使用"[]"操作符
比如👇
multimap<string, int>mp;
string s1("X"), s2("Y"); //等价于string s1 = "X"
mp.insert(make_pair(s1, 44));
mp.insert(make_pair(s1, 55));
mp.insert(make_pair(s1, 66));
mp.insert(make_pair(s2, 30));
mp.insert(make_pair(s2, 20));
mp.insert(make_pair(s1, 10));输出所有关于X国(键为"X")的数据👇
multimap<string, int>::iterator it;
it = mp.find(s1);
for(int k = 0; k < mp.count(s1); k++, it++)
cout<<it->first<<"--"<<it->second<<endl; //键--值🌳例题1 Hardwood Species 硬木种类
Hardwood Species - POJ 2418 - Virtual Judge (vjudge.net)

翻译
1,You are to compute the total fraction of the tree population represented by each species.
计算每个物种占总数的比例
2,No species name exceeds 30 characters.
物种名称不超过30个字符
3,There are no more than 10,000 species and no more than 1,000,000 trees.
物种数不超过1e4,树的数量不超过1e6
4,in alphabetical order 按字母表顺序
5,Print the name of each species represented in the population
打印种群中每个物种的名称(也就是输出键)
6,followed by the percentage of the population it represents, to 4 decimal places.
紧跟着占种群的百分比,保留小数点后4位
思路
1,读入包含空格的string类字符串,getline(cin, s),头文件#include<string>
---- 当然,如果需要读入包含空格的char s[n],只需要cin.get(str, n)
2,利用map键和值一对一的关系,每次遇到键s,值就+1,也就是mp[s]++
3,记得保留4位小数
4,要懂得迭代器访问map中的值的方法
AC 代码
自己调试时,输入完毕后,需要输入EOF来结束输入,可以在Windows下按下Ctrl+Z
#include<iostream>
#include<map>
#include<string> //getline()
using namespace std;
map<string, int>mp; //按字典序就是升序
int main()
{
string s; //每行读入的字符串
int cnt = 0; //统计树木总数
while(getline(cin, s)) {
mp[s]++; //s是键, mp[s]是键对应的值
cnt++;
}
for(map<string, int>::iterator it = mp.begin(); it != mp.end(); ++it)
{
cout<<it->first<<" ";
//printf("%s ", it->first.c_str()); //方法2
printf("%.4f\n", it->second * 100.0 / cnt); //键对应的值 * 100 / 总数
}
return 0;
}
%.4f表示输出格式为保留4位小数的浮点数 一开始写成%.4d了...
🌳例题2 Double Queue 双重队列
Double Queue - POJ 3481 - Virtual Judge (vjudge.net)
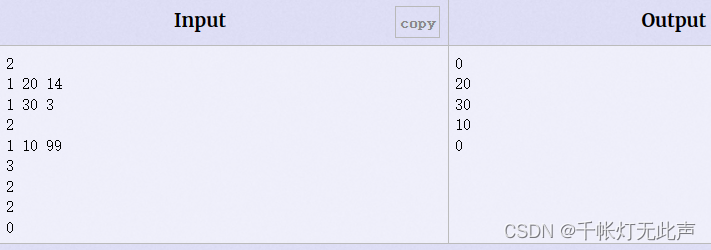
2 -- 删除最高优先级,等待列表为空,输出0
1 20 14 -- 加入客户20,客户20的优先级为14(键20,值14)
1 30 3 -- 加入客户30,优先级3
2 -- 删除最高优先级的 20-14(键值对),输出键(即客户标识符)20
1 10 99 -- 加入键值对10-99
3 -- 删除最低优先级的30-3,输出30
2 -- 删除最高优先级的10-99,输出10
2 -- 删除最高的...为空,输出0
翻译
不看英文了,还是先赶进度,否则暑假搞不定就得开学熬了
思路
1,本题包括插入,删除最大优先,最小优先3种操作,由于map本身按第1元素(键)升序,所以将优先级作为键即可
这种根据输入数字的不同,执行对应操作的,用switch比较好
坑
1,迭代器操作时,如果要指针it回到最后一个元素下一位的前一个,要用
it = --mp.end(),而不是it = mp.end()--,没有这种用法,会导致非法操作
map<int, int>::iterator it; //迭代器
it = --mp.end();2,题目分析要清楚,哪个是键,哪个是值,输入1后,后面的两个数字分别代表客户和优先级,而队列是按照优先级排序的,结合map按照键排序,所以优先级作为键,也就是
1 20 14和1 30 3里,14和3作为键输入,所以顺序要反过来
AC 代码
代码第10行可以用auto关键字代替迭代器,但是POJ判题系统太古老了,没人维护,所以...
代码第17,18行等价,[]操作符,相当于insert二元组
#include<iostream>
#include<map>
#include<cstdio> //scanf(), printf()
using namespace std;
map<int, int>mp;
int main()
{
//auto it = mp.begin(); //等价于下面, 但是需要初始化
map<int, int>::iterator it; //迭代器
int x, a, b;
while(scanf("%d", &x) && x) { //&& x保证输入0时循环结束
switch(x) {
case 1: //插入
scanf("%d%d", &a, &b);
//mp.insert(make_pair(b, a));
mp[b] = a; //[]操作符, 等价于insert
break;
case 2: //删除最大值并输出
if(mp.empty()) printf("0\n");
else {
it = --mp.end(); //坑1, 要前缀--
printf("%d\n", it->second);
mp.erase(it); //迭代器作为参数
}
break;
case 3:
if(mp.empty()) printf("0\n");
else {
it = mp.begin(); //指向第一个元素
printf("%d\n", it->second); //先输出值, 即客户
mp.erase(it); //再删除
}
break;
}
}
return 0;
}
🌳例题3 水果
水果 - HDU 1263 - Virtual Judge (vjudge.net)
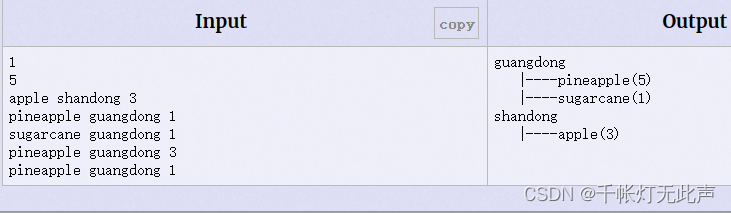
注意,每组测试之间,一个空行,最后一组之后没有空行
其次,不论产地还是水果名,都按字典序排序,也就是map默认的升序
思路
利用map的有序性和映射关系轻松解决~
定义一个2层嵌套的map,定义时就要嵌套
第1元素(键)是产地,第二元素(值)是map,这个map记录水果名和销售数量👇
map<string, map<string, int> >mp; //二维map1,这个二维map可以用mp[place][name]统计销售数量,mp[place]表示一个map(二维map的值也是map),mp[place][name]表示一维map的值(销售数量)
2,统计销售数量,mp[place][name] += num
3,按顺序输出
这里要声明2个map的迭代器,一个一维,一个二维
坑
为了避免声明为全局的二维map,map要声明在局部,也就是int main {}里,而且,还得声明在多组测试的while(n--)里,否则WA
补充
解释一下第24行
map<string, map<string, int> >::iterator it1; //迭代器
map<string, int>::iterator it2;for(it2 = it1->second.begin(); it2 != it1->second.end(); ++it2)it1是指向二维map的迭代器(可以理解为指针),it2是指向一维map的指针
it1->second表示二维map的值,也就是一维map本身,所以it1->second.begin()就是指向map容器第一个元素的指针,it1->second.end()就是指向map容器最后一个元素下一位置的指针
AC 代码
它好像没卡结尾的空行,多一行少一行都AC
#include<iostream>
#include<map>
using namespace std;
int main()
{
int n, m, num;
string place, name;
cin>>n;
while(n--) {
map<string, map<string, int> >mp; //声明在局部, 而且是while循环里
cin>>m;
//产地 水果 销量 读入map
for(int i = 0; i < m; ++i) {
cin>>place>>name>>num;
mp[name][place] += num; //+=
}
map<string, map<string, int> >::iterator it1; //迭代器
map<string, int>::iterator it2;
for(it1 = mp.begin(); it1 != mp.end(); ++it1) {
cout<<it1->first<<endl;
for(it2 = it1->second.begin(); it2 != it1->second.end(); ++it2)
cout<<" |----"<<it2->first<<"("<<it2->second<<")"<<endl;
}
if(n != 1) cout<<endl;
}
return 0;
}
🍉2.4.10 STL常用函数
以下函数包含在头文件#include<algorithm>
min(x, y);
max(x, y);
swap(x, y); //交换2个元素
find(begin, end, x); //返回指向[begin, end)第1个值为x的元素指针, 没找到返回end()
count(begin, end, x); //返回指向[begin, end)值为x的元素数量, 返回值为整数
reverse(begin, end); //翻转一个序列
random_shuffle(begin, end); //随机打乱一个序列
unique(begin, end); //连续相同元素压缩为一个元素, 返回去重后尾指针, 一般先排序后去重
fill(begin, end, val); //[begin, end)每个元素都设置为val
sort(begin, end, compare); //排序, 首地址 尾地址 比较函数 默认升序
stable_sort(begin, end, compare); //稳定排序 保持相等元素相对位置
//[begin, end)第k小的元素左边都<=它,右边都>=它
nth_element(begin, begin + k, end, compare);
lower_bound(begin, end, x); //通过二分查找 找到第一个 >=x 的元素 返回指针
upper_bound(begin, end, x); //找到第一个 >x 的元素 返回指针
next_permutation(begin, end); //按字典序下一排列
pre_permutation(begin, end); //按字典序的上一个排列补充
1)fill(begin, end, val)
1,不可以用#include<cstring>的memset()初始化一个int型数组为1,只有初始化为0或-1
因为memset(a, 1, sizeof(a)); 相当于将每个元素都赋值为
0000 0001 0000 0001 0000 0001 0000 0001,即将0000 0001分别填充到4字节中
而bool数组可以赋值为true,因为布尔数组每个元素只占1字节
memset(a, 0, sizeof(a)); //初始化为0
memset(a, -1, sizeof(a)); //初始化为-1
memset(a, 0x3f, sizeof(a)); //初始化为最大值0x3f3f3f3f
memset(a, 0xcf, sizeof(a)); //初始化为最小值0xcfcfcfcf需要注意,动态数组作为函数参数,需要用👇的方法,来赋初值
memset(a, 0x3f, n * sizeof(int));同样,如果是double类型数组填充极值,需要👇
fill(a, a + n, 0x3f3f3f3f);2)sort(begin, end, compare)
1,默认升序
2,自定义比较函数
3,利用functional标准库
需要头文件#include<functional>
equal_to<Type> //等于
not_equal_to<Type> //不等于
greater<Type> //大于
greater_equal<Type> //大于或等于
less<Type> //小于
less_equal<Type> //小于或等于
sort(begin, end, less<data-type>()) //升序
sort(begin, end, greater<data-type>()) //降序比如👇
#include<iostream>
#include<algorithm> //sort()
#include<functional> //greater<int>()
using namespace std;
int main()
{
int a[10] = {7,4,5,23,2,73,41,52,28,60};
sort(a, a + 10, greater<int>()); //降序
for(int i = 0; i < 10; ++i)
cout<<a[i]<<" ";
return 0;
}73 60 52 41 28 23 7 5 4 23)nth_element(begin, begin + k, end, compare)
该函数使区间[begin, end)第k(k从0开始)小的元素处在第k个位置,左边小于等于它,右边大于等于它。当加上最后一个参数cmp为greater<int>()时,第k大的元素处在第k位置,左边大,右边小
#include<iostream>
#include<algorithm> //nth_element()
using namespace std;
void print(int a[], int n)
{
for(int i = 0; i < n; ++i)
cout<<a[i]<<" ";
cout<<endl;
}
int main()
{
int a[7] = {6,2,7,4,20,15,5};
nth_element(a, a + 2, a + 7);
print(a, 7);
int b[7] = {6,2,7,4,20,15,5};
nth_element(b, b + 2, b + 7, greater<int>());
print(b, 7);
return 0;
}
第一行,5第2小(0开始),处于索引2的位置,左边<=5,右边>=5
第二行,7第2大,处于索引2的位置,左边>=7,右边<=7
4 2 5 6 20 15 7
15 20 7 6 4 5 24)lower_bound(begin, end, x) / upper_bound(begin, end, x)
都是用二分查找,在有序 数组中,查找第一个满足条件的元素
-- 升序数组中
lower_bound()从数组[begin, end)找第一个>=x的元素,返回地址,不存在就返回end()
upper_bound()找第一个>x的元素....
-- 降序数组中
返回来,就是lower找第一个<=,upper找第一个<
#include<iostream>
#include<algorithm> //lower_bound / upper_bound(begin, end, x)
using namespace std;
void print(int a[], int n)
{
for(int i = 0; i < n; ++i)
cout<<a[i]<<" ";
cout<<endl;
}
int main()
{
int a[6] = {6,2,7,4,20,15};
sort(a, a + 6); //a + 6是最后一个元素下一位的地址
print(a, 6);
//lower_bound返回指向第1个大于等于7元素的迭代器
//数组名a表示数组首地址, 地址 - 地址得到偏移量, 也就是下标
int pos1 = lower_bound(a, a + 6, 7) - a; //第一个大于等于7
int pos2 = upper_bound(a, a + 6, 7) - a; //第一个大于7
cout<<pos1<<" "<<a[pos1]<<endl; //下标 元素值
cout<<pos2<<" "<<a[pos2]<<endl;
sort(a, a + 6, greater<int>()); //降序排序
print(a, 6);
int pos3 = lower_bound(a, a + 6, 7, greater<int>()) - a;
int pos4 = upper_bound(a, a + 6, 7, greater<int>()) - a;
cout<<pos3<<" "<<a[pos3]<<endl; //下标 元素值
cout<<pos4<<" "<<a[pos4]<<endl;
return 0;
}
2 4 6 7 15 20
3 7
4 15
20 15 7 6 4 2
2 7
3 6
5)next_permutation(begin, end) / pre_permutation(begin, end)
next_permutation()是求按字典序排序的下一个排列的函数(难懂的话,看看👇代码)
可以得到全排列
pre_permutation()是求按字典序排序的上一个排列的函数
1,int 类型next_permutation
#include<iostream>
#include<algorithm> //next_permutation()
using namespace std;
int main()
{
int a[3];
a[0] = 1, a[1] = 2, a[2] = 3;
do{
cout<<a[0]<<" "<<a[1]<<" "<<a[2]<<endl;
}while(next_permutation(a, a + 3)); //记得分号
//如果存在a之后的排列, 返回true
//如果a是最后一个排列且没有后继, 返回false
//每执行一次 a就变成它的后继
return 0;
}
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
若改成👇
//只对前2个元素排序
while(next_permutation(a, a + 2));
//输出
1 2 3
2 1 3
//只对第1个元素排序
while(next_permutation(a, a + 1));
//输出
1 2 3若排列本来就最大,没有后继,则在next_permutation()执行后,对排列进行字典升序排序,相当于循环
#include<iostream>
#include<algorithm> //next_permutation()
using namespace std;
int main()
{
int a[3];
a[0] = 3, a[1] = 2, a[2] = 1;
next_permutation(a, a + 3);
cout<<a[0]<<" "<<a[1]<<" "<<a[2]<<endl;
return 0;
}
1 2 3
2)char类型的next_permutation()
想获得全排列, 先升序排好, 然后初始就是字典序最小的情况
#include<iostream>
#include<algorithm> //next_permutation()
#include<cstring> //strlen()
using namespace std;
int main()
{
char a[205];
cin>>a;
//想获得全排列, 先升序排好, 然后初始就是字典序最小的情况
sort(a, a + strlen(a)); //对输入的字符串进行字典升序排序
char *first = a; //首地址
char *last = a + strlen(a); //最后一个元素下一位置地址
do{
cout<<a<<endl;
}while(next_permutation(first, last));
return 0;
}
369
369
396
639
693
936
963
3)string类型next_permutation()
#include<iostream>
#include<algorithm> //next_permutation()
#include<cstring> //strlen()
using namespace std;
int main()
{
string s;
while(cin>>s && s != "#") { //多组测试 -- 输入#结束循环
sort(s.begin(), s.end()); //先按字典序升序, 也就是全排列第1个排列
cout<<s<<endl; //输出全排列第1个排列
while(next_permutation(s.begin(), s.end()))
cout<<s<<endl; //输出后续排列
}
return 0;
}
83
38
83
pdf
dfp
dpf
fdp
fpd
pdf
pfd
#
4)自定义优先级的next_permutation() ---
关于代码中tolower()函数👇
#include <cctype>
#include <iostream>
using namespace std;
int main() {
char c1 = 'A', c2 = 'b', c3 = '9';
cout << (char) tolower(c1) << endl;
cout << (char) tolower(c2) << endl;
cout << (char) tolower(c3);
return 0;
}
a
b
9👇自定义代码
#include<iostream>
#include<algorithm> //next_permutation()
#include<cstring> //strlen()
using namespace std;
int cmp(char a, char b) { //'A'<'a'<'B'<'b'<...<'Z'<'z'
if(tolower(a) < tolower(b))
return tolower(a) < tolower(b);
else
return a < b;
}
int main()
{
string s;
while(cin>>s && s != "#") { //输入#结束循环
sort(s.begin(), s.end(), cmp);
cout<<s<<endl; //输出全排列第1个排列
while(next_permutation(s.begin(), s.end(), cmp))
cout<<s<<endl; //输出后续排列
}
return 0;
}
aAcb
Aabc
Aacb
Abac
Abca
Acab
Acba
aAbc
aAcb
abAc
abcA
acAb
acbA
bAac
bAca
baAc
bacA
bcAa
bcaA
cAab
cAba
caAb
cabA
cbAa
cbaA
#
🌳例题1 Median 差的中位数
Median - POJ 3579 - Virtual Judge (vjudge.net)
一道加深对二分理解的好题
梳理思路
let us calculate the difference of every pair of numbers
“让我们计算每一对数字的差值”(每一对,和顺序无关,是组合数)
依题意,中位数,当差的个数m是奇数,显然是第(m + 1) / 2小的数
如果是偶数(even),就是第m / 2小的数,考虑到int向下取整,所以统一为(m + 1) / 2
比如差有6个,1 2 3 4 5 6,那么中位数就是3,而不是4
比如差有7个,1 2 3 4 5 6 7,那么中位数显然是4
👆看题,不要自己瞎玩,题目给定了中位数就是m / 2,所以别自己瞎玩了,做不对的
题目范围Xi <= 1e9,3 <= N <= 1e5,所以本题不应该用数组把所有差的结果保存下来,复杂度O(n^2),N^2 <= 1e10,Time Limit 1秒会超时,老实用二分求中位数吧(由题可知,差值是可以相同的)
由于题目中出现C(N, 2),补充一下组合数和排列数的知识
组合数是指从 n 个不同元素中取出 m 个元素(m≤n)的排列数,它用 C(n,m) 表示。
组合数的计算公式为:
C(n,m) = n! / (m! * (n-m)!)
1,We can get C(N,2) differences through this work
“我们能得到C(N, 2)个差值”
C(n, 2) = n*(n-1) / 2个差值,C(n, 2)表示从n个数中2个数,构成|Xi - Xj|
所以差的数量m = (n * (n - 1)) / 2
所以中位数是第(m / 2 + 1)小的数,k = ( n * (n - 1) / 2 + 1 ) / 2
--------------------------------------------------
关于代码中lower_bound()的解释
#include<algorithm>下的lower_bound(begin, end, x);返回的是指向该位置的指针,是个地址
具体意思是:
从数组begin位置到end - 1位置,二分查找第1个大于等于x的元素,找到后返回该函数地址
cnt+=n-(lower_bound(a,a+n,a[i]+val)-a);a[k] - a[i] >= val -- -- 对于每一个a[i],都统计多少个数与a[i]的差大于等于val,考虑到数组已经排序,二分也需要数组有序作为基础,显然可以用lower_bound直接统计
a[k] >= a[i] + val,所以lower_bound(a, a + n, a[i] + val)找到第1个>=a[i] + val的地址位置
再减去数组首地址,就得到了该数a[k]的下标
关于数组中地址相减就能得到下标的解释(下标0开始)
&a[k] - a 之所以可以得到下标 k,是因为它计算了 a[k] 的地址与数组首元素的地址之间的指针差值,并将其除以了 sizeof(int)
再用n - k,元素个数 - 下标,就得到了对a[i]来说,差值>=val的元素个数
用for循环遍历一遍a[],即可得到整个数组中差值>=val的数,有cnt对
AC 代码
#include<iostream>
#include<algorithm> //lower_bound(), sort()
#include<cstdio> //scanf()
using namespace std;
#define LL long long
#define maxn 100010
LL n, k, i, mid, ans, a[maxn]; //k为差值总数的中位数
//cnt>k, 返回1
bool check(LL val)
{
LL cnt = 0; //差值>=val的总对数, 记得初始化
for(int i = 0; i < n; ++i)
cnt += n - (lower_bound(a, a + n, a[i] + val) - a);
return cnt > k; //差值>=val的总数超过差值总数的一半
}
int main()
{
while(~scanf("%lld", &n)) {
//k = (n * (n - 1) / 2 + 1) / 2; //错误, 憋瞎玩
k = n * (n - 1) / 4; //差值中位数
for(i = 0; i < n; ++i)
scanf("%lld", &a[i]);
sort(a, a + n); //二分前提
//二分
LL l = 0, r = a[n - 1] - a[0]; //r表示差值最大值
while(l <= r) { //mid表示可能的差值中位数
mid = (l + r) >> 1; //右移运算符, 表示 / 2
if(check(mid)) { //左边界要右移
ans = mid;
l = mid + 1;
}
else
r = mid - 1;
}
cout<<ans<<endl;
}
return 0;
}
🌳例题2 Who's in the Middle 中位数
Who's in the Middle - POJ 2388 - Virtual Judge (vjudge.net)
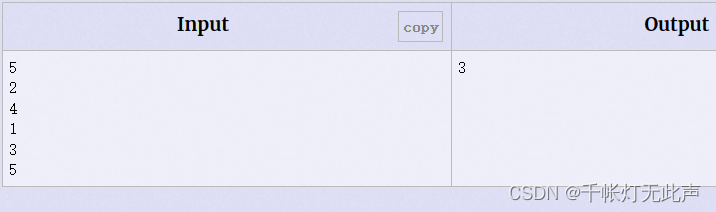
本题比上一题简单...只是找中位数🤦
当然,排序后再输出中位数,比代码2的nth_element慢一点
AC 代码1
#include<iostream>
#include<algorithm>
#include<cstdio>
using namespace std;
int a[10010];
int main()
{
int n;
scanf("%d", &n);
for(int i = 0; i < n; ++i)
scanf("%d", &a[i]);
sort(a, a + n);
cout<<a[n / 2];
return 0;
}
AC 代码2
书里还给了对nth_element的使用
#include<algorithm>下的nth_element(begin, begin + k, end, compare)
使区间[begin, end)第k(k从0开始)小的元素处在第k个位置,最后一个参数compare如果是greater<int>(),则使[begin, end)第k大.....
#include<iostream>
#include<algorithm>
#include<cstdio>
using namespace std;
const int maxn = 10010;
int a[maxn];
int main()
{
int n;
scanf("%d", &n);
for(int i = 0; i < n; ++i)
scanf("%d", &a[i]);
int mid = n >> 1; //nth_element(a + l, a + k, a + r)求[l, r)区间上第k小
nth_element(a, a + mid, a + n);
cout<<a[mid];
return 0;
}
🌳例题3 Orders 订单管理
Orders - POJ 1731 - Virtual Judge (vjudge.net)
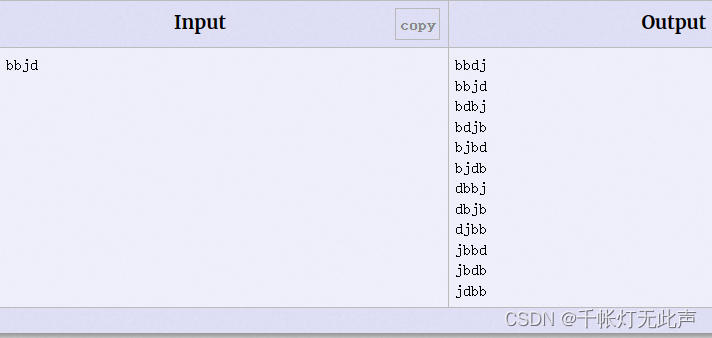
翻译
1,All the kinds having labels starting with the same letter are stored in the same warehouse (i.e. in the same building) labelled with this letter
标签是同一个字母开头的货物,存储在同一个仓库,并用该字母标记
2,Each order requires only one kind of goods
每个订单只需要一种货物
3,processes the requests in the order of their booking
按照预定的顺序处理请求
4,Compute all possible ways of the visits of warehouses for the stores manager to settle all the demands piece after piece during the day
计算所有可能的访问仓库的方式,以便一个一个地解决问题
5,Each kind of goods is represented by the starting letter of its label
每种货物用订单首字母表示
6,The number of orders doesn't exceed 200
订单数量200以内
7,Each ordering of warehouses is written in the output file only once on a separate line and all the lines containing orderings have to be sorted in an alphabetical order
仓库每组排序输出占1行,所有行按字母顺序排序输出
就是输出字母的全排列
我决定用书里的next_permutation()函数和dfs分别尝试一次
next_permutation()是求按字典序排序的下一个排列的函数
while() 可以得到全排列
pre_permutation()是求按字典序排序的上一个排列的函数
WA 代码1
实际上不是WA,只是POJ不支持C++11
#include<iostream>
#include<algorithm> //next_permutation(), sort()
using namespace std;
int main()
{
string s;
cin>>s;
sort(s.begin(), s.end()); //字符串按字典序升序
cout<<s<<endl; //输出全排列的第1个
while( next_permutation(s.begin(), s.end()) )
cout<<s<<endl;
return 0;
}
AC 代码1
#include<iostream>
#include<algorithm> //next_permutation(), sort()
#include<cstring> //strlen()
#include<cstdio> //scanf()
using namespace std;
int main()
{
char s[300];
scanf("%s", s);
int len = strlen(s);
sort(s, s + len);
printf("%s\n",s); //输出全排列的第1个
while( next_permutation(s, s + len) )
printf("%s\n",s);
return 0;
}
关于我一开始用cin读取char[]字符串,wrong answer的事,因为👇
使用 scanf("%s", s)读入字符串,不会包含空格等分隔符,而且不会读取换行符,所以后面的 while 循环可用。而 cin.get(s, 300) 在读取字符串时可以包含空格等分隔符,但是它会读取换行符,因此 while 循环里的第一次执行只会输出空字符串,从而导致答案错误
AC 代码2
采用dfs输出全排列
#include<iostream>
#include<algorithm> //sort()
#include<cstring> //strlen()
#include<cstdio> //scanf()
using namespace std;
char s[300];
char csgo[300]; //存放结果
int len, book[300];
void print()
{
for(int i = 0; i < len; ++i)
cout<<csgo[i];
cout<<endl;
}
void dfs(int step)
{
if(step >= len) {
print();
return;
}
char pre = '\0'; //空字符
for(int i = 0; i < len; ++i) {
if(!book[i] && s[i] != pre) {
csgo[step] = s[i]; //注意这里是step
book[i] = 1; //标记
pre = s[i];
dfs(step + 1); //递归
book[i] = 0; //取消标记
}
}
}
int main()
{
scanf("%s", s);
len = strlen(s);
sort(s, s + len); //升序
dfs(0);
return 0;
}
关键在于第25行和28行
if(!book[i] && s[i] != pre) {
pre = s[i];gpt上的一点解释
1,从 0 到 len-1 枚举每个字符,找到第一个未被标记的字符。如果这个字符不等于 pre,就将这个字符加入到 csgo 数组的 step 位置,然后标记这个字符,表示已经被使用过了。接着,将 pre 赋值为当前字符,然后进入下一层递归
2,在一个递归函数内部,i 的值会根据之前的递归函数的计算结果来重新赋值,而不是重新从 0 开始计数。因此,prev 变量可以将上一个递归函数的值传递给下一个递归函数
🌳例题4 Anagram 字谜
Anagram - POJ 1256 - Virtual Judge (vjudge.net)
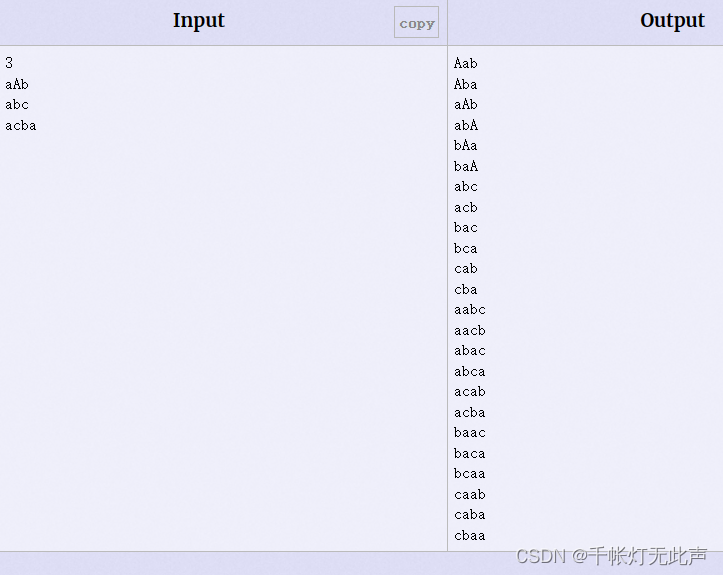
关键
题目中An upper case letter goes before the corresponding lower case letter
“大写字母应该在小写字母之前”,这是区别于上一题的地方
参考前面知识点提到的(4)自定义next_permutation
So the right order of letters is 'A'<'a'<'B'<'b'<...<'Z'<'z'.
补充
涉及next_permutation()和tolower()函数,可以翻回去看看
关于代码中tolower()函数👇类似的,还有toupper()函数
#include <cctype>
#include <iostream>
using namespace std;
int main() {
char c1 = 'A', c2 = 'b', c3 = '9';
cout << (char) tolower(c1) << endl;
cout << (char) tolower(c2) << endl;
cout << (char) tolower(c3);
return 0;
}
a
b
9AC 代码
有个坑,代码第22行,第一次排序,也要用cmp,否则你就得不到第一组序列,debug半小时😓
#include<iostream>
#include<algorithm> //sort()
#include<cstring> //strlen()
#include<cstdio> //scanf()
using namespace std;
bool cmp(char a, char b) //'A' < 'a' < 'B' < 'b' ...升序
{
if(tolower(a) != tolower(b)) //不同字母, 转化为小写后比较
return tolower(a) < tolower(b);
else
return a < b; //同一字母, 本来就'A' < 'a'升序, 按原来就好
}
int main()
{
char s[20];
int n;
scanf("%d", &n);
while(n--) {
scanf("%s", s); //数组名就是首地址, 不需要取地址符&
sort(s, s + strlen(s), cmp); //排序也要cmp, 才能得到第一组的组合
printf("%s\n", s);
while(next_permutation(s, s + strlen(s), cmp))
printf("%s\n", s);
}
return 0;
}
最后
最后放2个看过的博客
STL 中的常见实用库函数(适合初学算法者阅读)(持续更新中)_stl库函数_H-rosy的博客-CSDN博客
STL 算法 - OI Wiki (oi-wiki.org)
😄总结
期末周,忙忙碌碌,身边都是提前2周开始复习,满怀信心,轻轻松松的同学
估计他们三门数学都能上90吧,就不和他们竞争了
想起今天看到一篇很搞笑的文章,标题是《趁着寒假舍友不在,偷偷学习》
🤣