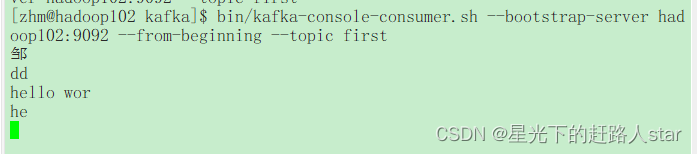1、Kafka概述
1.1 定义
1、Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要是应用于大数据实时处理领域。
2、发布/订阅:消息的发布者不会将信息直接发送给特定的订阅者,而是将发布的信息分为不同的类别,订阅者只接受感兴趣的消息。
3、Kafka最新定义:Kafka是一个开源的分布式事件流平台(Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
1.2 消息队列
目 前企 业中比 较常 见的 消息 队列产 品主 要有 Kafka、ActiveMQ 、RabbitMQ 、RocketMQ 等。
在大数据场景主要采用 Kafka 作为消息队列。在 JavaEE 开发中主要采用 ActiveMQ、RabbitMQ、RocketMQ。
1.2.1 传统消息队列的应用场景
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。
1、消息队列的应用场景——缓冲/消峰
有助于控制和优化数据流经过系统的速度,解决生产消息和消费信息的处理速度不一致的情况。
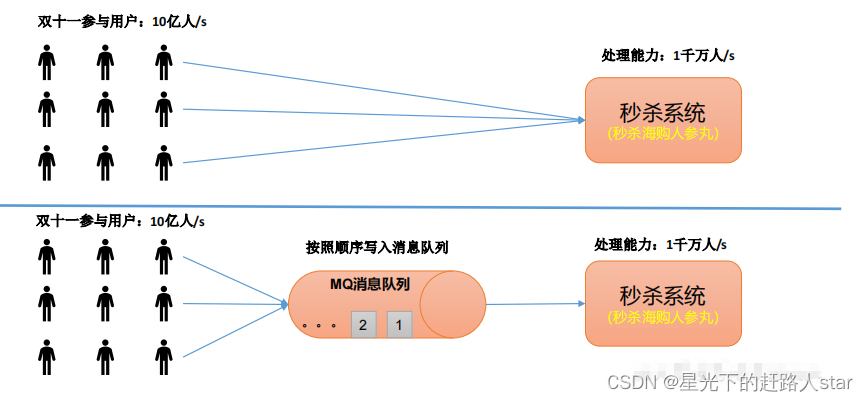
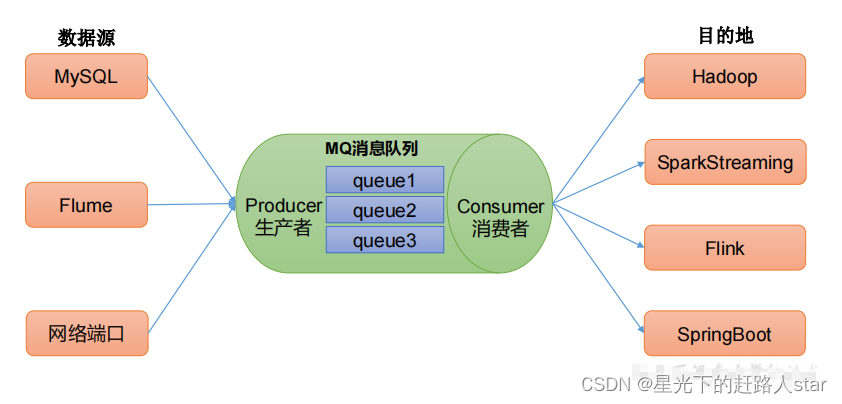
2、消息队列的应用场景——解耦
运行你独立的扩展或修改两边的处理流程,只有确保它们遵守同样的接口约束
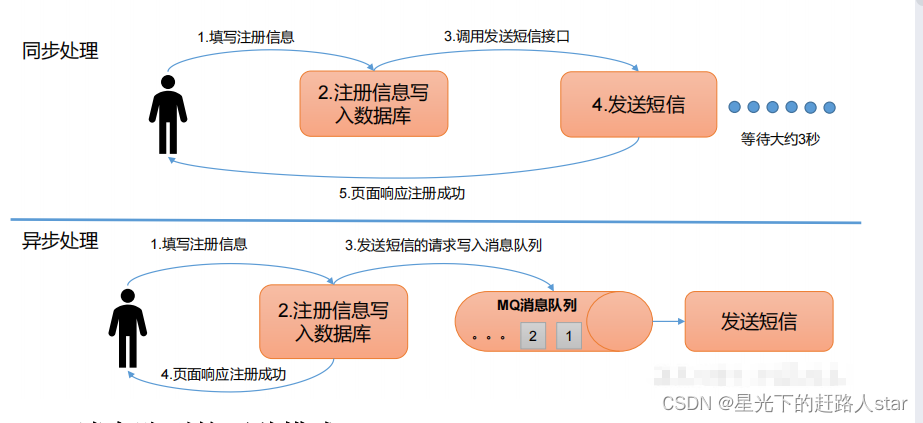
3、消息队列的应用场景——异步通信
允许用户把一个信息放入队列,但并不立即处理它,然后在需要的时候再去处理它们
1.2.2 消息队列的两种模式
1、点对点模式
消费者主动拉取数据,消息收到后清除消息

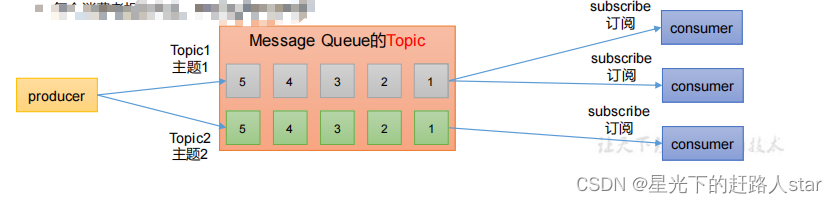
2、发布/订阅模式
可以有多个topic主题(浏览、点赞、收藏、评论等)
消费者消费数据之后,不删除数据
每个消费者互相独立,都可以消费到数据
1.3 Kafka基础架构
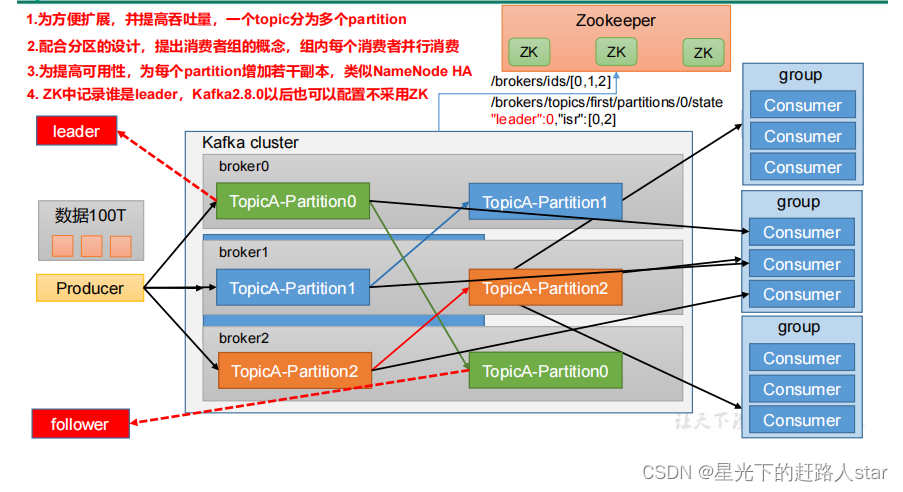
1、producer:消息生产者,就是向Kafka broker发消息的客户端
2、Consumer:消息消费者,向Kafka broker取消息的客户端
3、Consumer Group(CG):消费组,由多个Consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4、Broker:一台Kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
5、Topic:可以理解为一个队列,生产者和消费者面向的都是一个Topic。
6、Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
7、Reolica:副本。一个topic的每个分区都有若干个副本,一个Leader和若干个Follower。
8、Leader:每个分区多个副本的“主”,生产者发生数据的对象,以及消费者消费数据的对象都是Leader。
9、Follower:每个分区多个副本中的“从”,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会成为新的Leader。
2、Kafka快速入门
2.1 安装部署
2.1.1 集群规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| zk | zk | zk |
| kafka | kafka | kafka |
2.1.2 集群部署
0、获取安装包
链接:https://pan.baidu.com/s/1zzgLmW6kz65C5V3E2ENxSg
提取码:zhm6
1、解压安装包(记得到上传的目录下将文件解压)
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
2、修改解压后的文件名称
mv kafka_2.12-3.0.0/ kafka
3、进入到/opt/module/kafka 目录,修改配置文件
#broker 的全局唯一编号,不能重复,只能是数字。
***broker.id=0***
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
***log.dirs=/opt/module/kafka/datas***
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个 topic 创建时的副本数,默认时 1 个副本
offsets.topic.replication.factor=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个 segment 文件的大小,默认最大 1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
***zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka***
4、分发安装包(将安装包发送到其他两个节点)
xsync kafka/
5、分别在 hadoop103 和 hadoop104 上修改配置文件/opt/module/kafka/config/server.properties中的 broker.id=1、broker.id=2
注:broker.id 不得重复,整个集群中唯一
6、配置环境变量
(1)在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
(2)刷新一下环境
source /etc/profile
(3)分发环境变量文件到其他节点,并source。
7、启动集群
(1)先启动Zookeeper集群,然后启动Kafka集群。
zk.sh start
(2)依次在 hadoop102、hadoop103、hadoop104 节点上启动 Kafka。
bin/kafka-server-start.sh -daemon config/server.properties
(8)关闭集群(每个节点都要)
bin/kafka-server-stop.sh
2.1.3 集群一键启动和停止脚本
1、在/home/atguigu/bin 目录下创建文件 kf.sh 脚本文件
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -
daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
};;
esac
2、添加执行权限
chmod +x kf.sh
3、启动集群命令
kf.sh start
4、停止集群命令
kf.sh stop
注意:停止Kafa集群的时候,一定要等kafka所以节点进程全部停止后再停止Zookeeper集群。因为Zookeeper集群当中记录着Kafka集群相关的信息,Zookeeper集群一旦先停止,Kafka集群就没办法再获取停止进行的信息,只能手动杀死Kafka进程了。
2.2 命令行操作
2.2.1 主题命令行操作
1、查看操作主题命令参数
bin/kafka-topics.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server<String: server toconnect to> | 连接的kafka Broker主机名称和端口号 |
| –topic<String: topic> | 操作的topic名称 |
| –create | 创建主题 |
| –delete | 删除主题 |
| –alter | 修改主题 |
| –list | 查看所有主题 |
| –describe | 查看主题详细描述 |
| –partitions<Integer:# of partitions> | 设置分区数 |
| –replication-factor<Integer:replication factor> | 设置分区数 |
| –config<String: name=value> | 更新系统默认的配置 |
| 2、查看当前服务器中的所有topic |
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list

3、创建first topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 1 --replication-factor 3 --topic first

选项说明:
(1)topic:定义topic名
(2)replication-factor:定义副本数
(3)partitions 定义分区数
4、查看first 主题的详情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first

5、修改分区数(分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3

6、再次查看 first 主题的详情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first

7、删除topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first

2.2.2 生产者命令行操作
1、查看操作生产者命令参数
bin/kafka-console-producer.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| –topic <String: topic> | 操作的 topic 名称。 |
| 2、发送消息 |
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
2.2.2 消费者命令行操作
1、查看操作消费者命令参数
bin/kafka-console-consumer.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| –topic <String: topic> | 操作的 topic 名称。 |
| –from-beginning | 从头开始消费 |
| –group <String: consumer group id> | 指定消费者组名称。。 |
| 2、消费消息 | |
| (1)消费first主题中的数据 |
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first

(2)把主题中所有的数据都读取出来(包括历史数据)。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first