文章目录
- 一、数据帧 - DataFrame
- (一)DataFrame概述
- (二)将RDD转成DataFrame
- 二、数据集 - Dataset
- (一)Dataset概述
- (二)将RDD转成DataSet
- (三)DataFrame与Dataset的关系
- 三、简单使用Spark SQL
- (一)了解SparkSession
- (二)准备工作
- 1、准备数据文件
- 2、启动Spark Shell
- (三)加载数据为Dataset
- 1、读文件得数据集
- 2、显示数据集内容
- 3、显示数据集模式
- (四)给数据集添加元数据信息
- 1、定义学生样例类
- 2、导入隐式转换
- 3、将数据集转换成学生数据集
- 4、对学生数据集进行操作
- (1)显示数据集内容
- (2)打印数据集模式
- (3)对数据集进行投影操作
- (4)对数据集进行过滤操作
- (5)对数据集进行统计操作
- (6)对数据集进行排序操作
- (7)重命名数据集字段
- (五)将数据集转为数据帧
- 1、将数据集转为数据帧
- 2、对学生数据帧进行操作
- (1)显示数据帧内容
- (2)显示数据帧模式信息
- (3)对数据帧进行投影操作
- (4)对数据帧进行过滤操作
- (5)对数据帧进行统计操作
- (6)对数据帧进行排序操作
- (7)重命名数据帧字段
- (六)基于数据帧进行SQL查询
- 1、基于数据帧创建临时视图
- 2、使用spark对象执行SQL查询
- (1)查询全部表记录
- (2)显示数据表结构
- (3)对表进行投影操作
- (4)对表进行选择操作
- (5)对表进行统计操作
- (6)对表进行排序操作
- (7)重命名数据表字段
- 四、练习
一、数据帧 - DataFrame
(一)DataFrame概述
DataFrame是Spark SQL提供的一个编程抽象,与RDD类似,也是一个分布式的数据集合,但与RDD不同,DataFrame的数据都被组织到有名字的列中,就像关系型数据库中的表一样。在Spark 1.3.0版本之前,DataFrame被称为SchemaRDD。此外,多种数据都可以转化为DataFrame,例如Spark计算过程中生成的RDD、结构化数据文件、Hive中的表、外部数据库等。
(二)将RDD转成DataFrame
DataFrame在RDD的基础上添加了数据描述信息(Schema,模式,即元信息),因此看起来更像是一张数据库表。
一个RDD中有5行数据
将RDD转成DataFrame
使用DataFrame API结合SQL处理结构化数据比RDD更加容易,而且通过DataFrame API或SQL处理数据,Spark优化器会自动对其优化,即使写的程序或SQL不高效,也可以运行得很快。
二、数据集 - Dataset
(一)Dataset概述
Dataset是一个分布式数据集,Spark 1.6中添加的一个新的API。相对于RDD,Dataset提供了强类型支持,在RDD的每行数据加了类型约束。而且使用Dataset API同样会经过Spark SQL优化器的优化,从而提高程序执行效率。
(二)将RDD转成DataSet
一个RDD中有5行数据
将RDD转换为Dataset
(三)DataFrame与Dataset的关系
在Spark中,一个DataFrame所代表的是一个元素类型为Row的Dataset,即DataFrame只是Dataset[Row]的一个类型别名。
三、简单使用Spark SQL
(一)了解SparkSession
Spark Shell启动时除了默认创建一个名为sc的SparkContext的实例外,还创建了一个名为spark的SparkSession实例,该spark变量可以在Spark Shell中直接使用。
从Spark2.0以上版本开始, Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能。
SparkSession只是在SparkContext基础上的封装,应用程序的入口仍然是SparkContext。SparkSession允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序,支持从不同的数据源加载数据,并把数据转换成DataFrame,然后使用SQL语句来操作DataFrame数据。
(二)准备工作
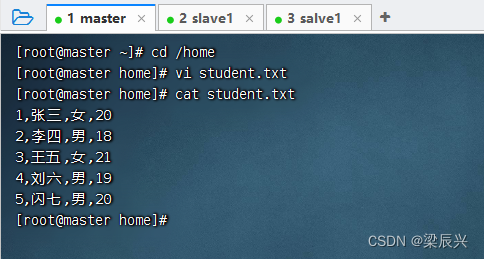
1、准备数据文件
1,张三,女,20
2,李四,男,18
3,王五,女,21
4,刘六,男,19
5,闪七,男,20
在/home目录里创建student.txt文件
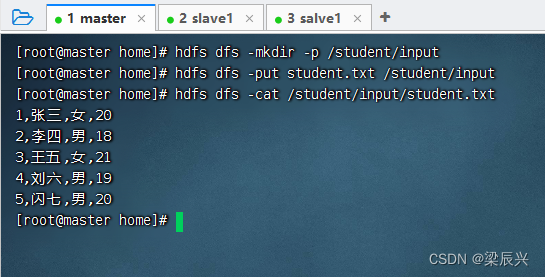
将student.txt上传到HDFS的/student/input目录
2、启动Spark Shell
启动Spark Shell,执行命令:spark-shell --master spark://master:7077
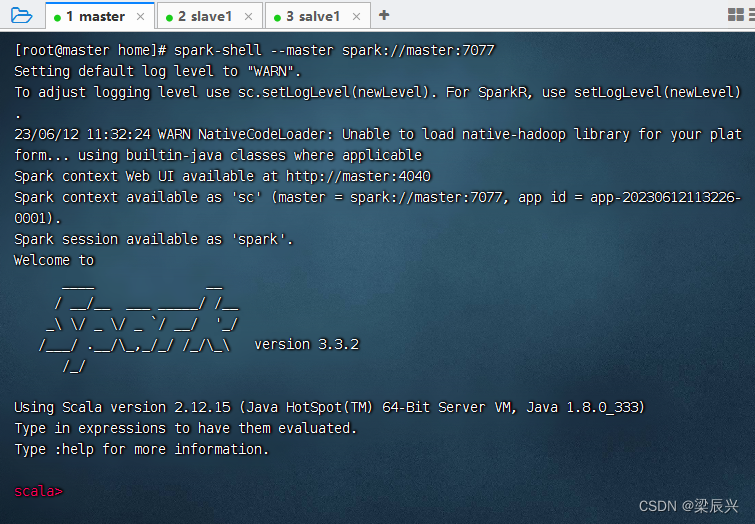
(三)加载数据为Dataset
1、读文件得数据集
调用SparkSession对象的read.textFile()可以读取指定路径中的文件内容,并加载为一个Dataset
执行命令:val ds = spark.read.textFile("hdfs://master:9000/student/input/student.txt")

从变量ds的类型可以看出,textFile()方法将读取的数据转为了Dataset。除了使用textFile()方法读取文本内容外,还可以使用csv()、jdbc()、json()等方法读取CSV文件、JDBC数据源、JSON文件等数据。(csv: comma separated value)
2、显示数据集内容
执行命令:ds.show

可以看出,Dataset将文件中的每一行看作一个元素,并且所有元素组成了一列,列名默认为value。
3、显示数据集模式
执行命令:ds.printSchema
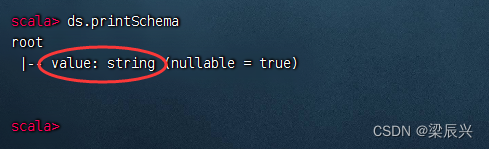
这样的单列数据集显得太粗糙,应该加点元数据信息,让它更精细化。
(四)给数据集添加元数据信息
1、定义学生样例类
定义一个样例类Student,用于存放数据描述信息(Schema)
执行命令:case class Student(id: Int, name: String, gender: String, age: Int)

基于样例类创建对象很简单,不需要new关键字,只需要传入相应参数即可创建对象
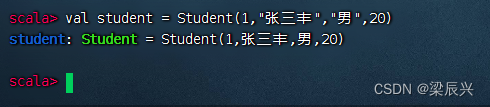
2、导入隐式转换
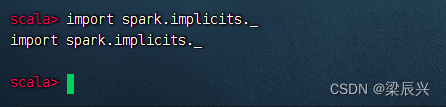
导入SparkSession的隐式转换,以便后续可以使用Dataset的算子
执行命令:import spark.implicits._ (_表示implicits包里所有的类,类似于Java里的*)
3、将数据集转换成学生数据集
调用Dataset的 map() 算子将每一个元素拆分并存入Student 样例对象
执行命令 :paste 进入粘贴模式,然后执行红框类的命令
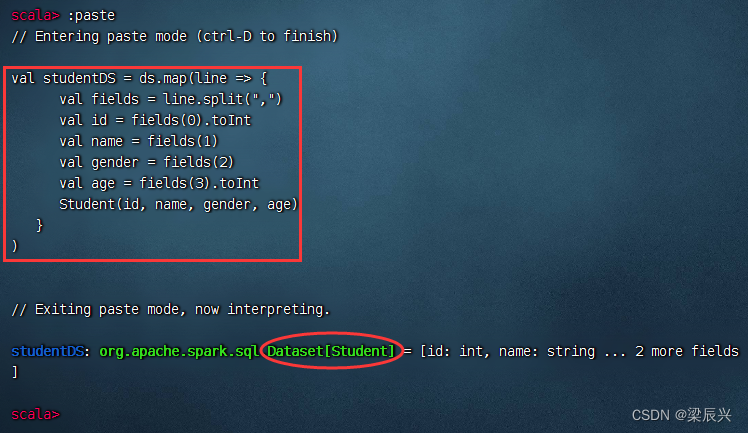
val studentDS = ds.map(line => {
val fields = line.split(",")
val id = fields(0).toInt
val name = fields(1)
val gender = fields(2)
val age = fields(3).toInt
Student(id, name, gender, age)
}
)
4、对学生数据集进行操作
(1)显示数据集内容
执行命令:studentDS.show

可以看到,studentDS中的数据类似于一张关系型数据库的表。
(2)打印数据集模式
执行命令:studentDS.printSchema

(3)对数据集进行投影操作
显示学生的姓名和年龄字段,执行命令:studentDS.select(“name”, “age”).show
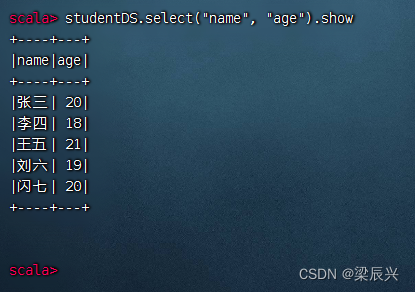
对应的SQL语句:select name, age from student
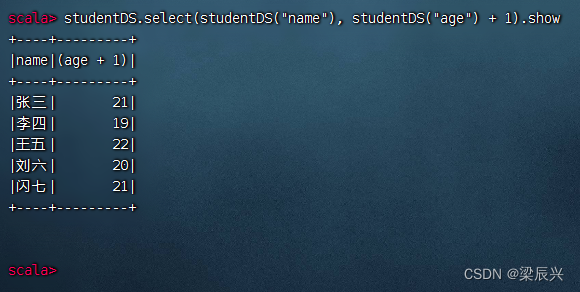
执行命令:studentDS.select(studentDS(“name”), studentDS(“age”) + 1).show
执行命令:studentDS.select(studentDS(“name”).as(“姓名”), (studentDS(“age”) + 1).as(“年龄”)).show(给字段取别名)
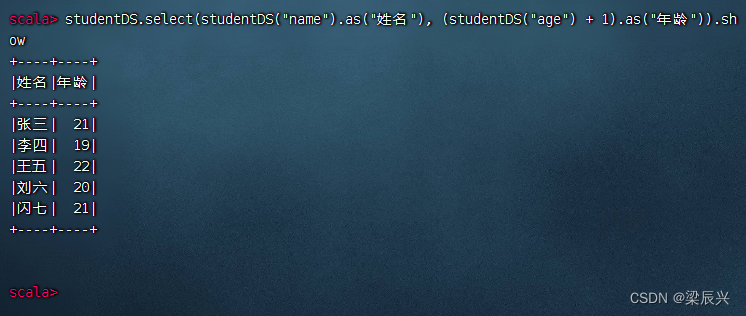
相当于SQL语句:select name as 姓名, age + 1 as 年龄 from student;
(4)对数据集进行过滤操作
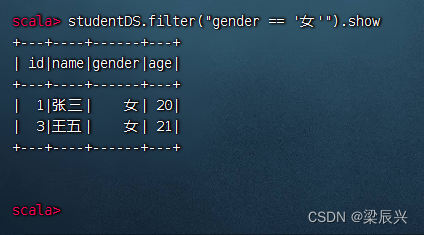
显示女生记录,执行命令:studentDS.filter(“gender == ‘女’”).show
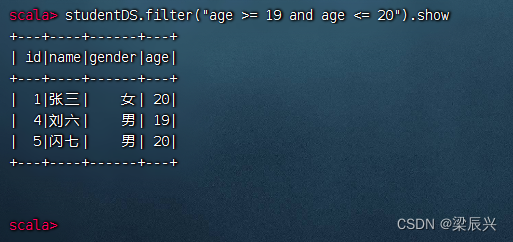
显示年龄在[19, 20]之间的记录,执行命令:studentDS.filter(“age >= 19 and age <= 20”).show
如果条件是age <19 or age > 20,那么两个数据集ds1与ds2就应该求并集:ds1.union(ds2)
| 逻辑运算 | 集合运算 |
|---|---|
| not | 补集 - complement |
| and | 交集 - intersection |
| or | 并集 - union |
(5)对数据集进行统计操作
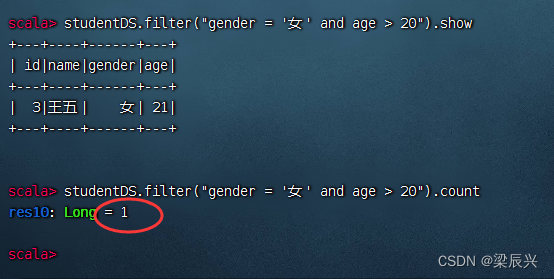
求20岁以上的女生人数
分组统计男女生总年龄,执行命令:studentDS.groupBy(“gender”).sum(“age”).show
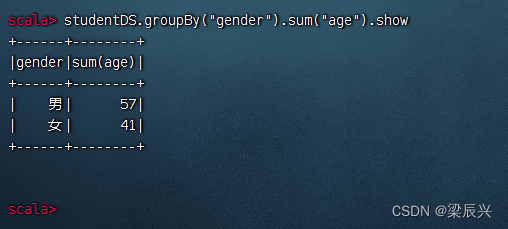
相当于SQL语句:select gender, sum(age) from student group by gender;
分组统计男女生平均年龄:执行命令:studentDS.groupBy(“gender”).avg(“age”).show
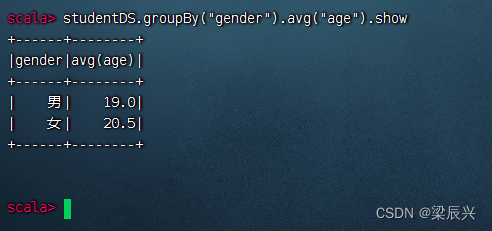
相当于SQL语句:select gender, avg(age) from student group by gender;
分组统计男女生最大年龄,执行命令:studentDS.groupBy(“gender”).max(“age”).show
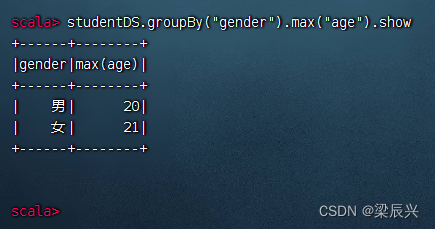
相当于SQL语句:select gender, max(age) from student group by gender;
分组统计男女生最小年龄,执行命令:studentDS.groupBy(“gender”).min(“age”).show
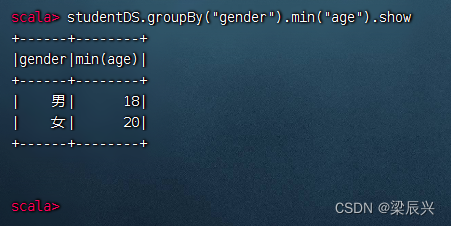 相当于SQL语句:select gender, min(age) from student group by gender;
相当于SQL语句:select gender, min(age) from student group by gender;
(6)对数据集进行排序操作
按年龄升序排列,执行命令:studentDS.sort(“age”).show

相当于SQL语句:select * from student order by age; (默认是asc - ascending)
按年龄降序排列,执行命令:studentDS.sort(studentDS(“age”).desc).show

按年龄降序排列,执行命令:studentDS.sort(desc(“age”)).show

相当于SQL语句:select * from student order by age desc; (desc - descending)
先按性别升序排列,再按年龄降序排列,执行命令:studentDS.sort(asc(“gender”), desc(“age”)).show
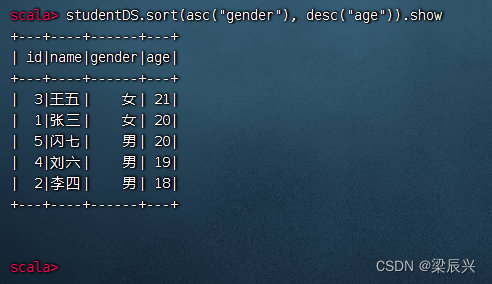
对应的SQL语句:select * from student order by gender asc, age desc;
(7)重命名数据集字段
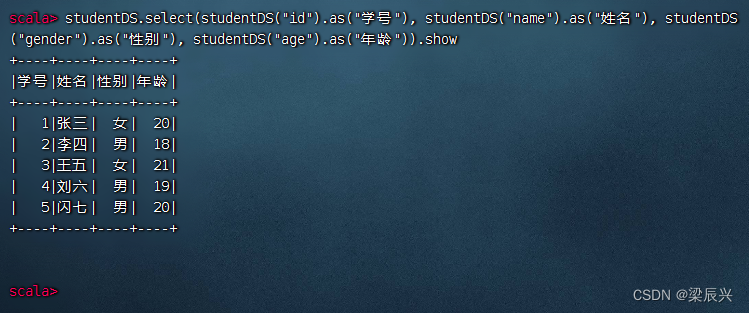
执行命令:studentDS.select(studentDS(“id”).as(“学号”), studentDS(“name”).as(“姓名”), studentDS(“gender”).as(“性别”), studentDS(“age”).as(“年龄”)).show
(五)将数据集转为数据帧
Spark SQL查询的是DataFrame中的数据,因此需要将存有元数据信息的Dataset转为DataFrame。调用Dataset的toDF()方法,将存有元数据的Dataset转为DataFrame。
1、将数据集转为数据帧
将学生数据集转为学生数据帧,执行命令:val studentDF = studentDS.toDF()

2、对学生数据帧进行操作
(1)显示数据帧内容
显示学生数据帧内容,执行命令:studentDF.show

(2)显示数据帧模式信息
打印学生数据帧模式信息,执行命令:studentDF.printSchema

(3)对数据帧进行投影操作
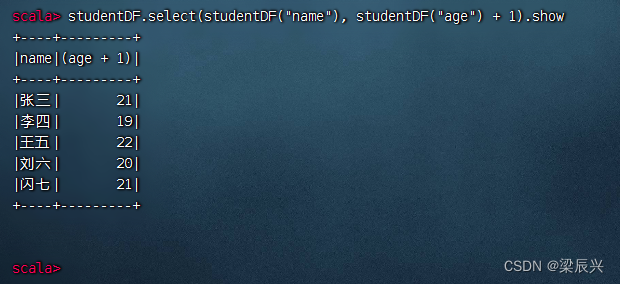
显示学生数据帧姓名与年龄字段,年龄加1,执行命令:studentDF.select(studentDF(“name”), studentDF(“age”) + 1).show
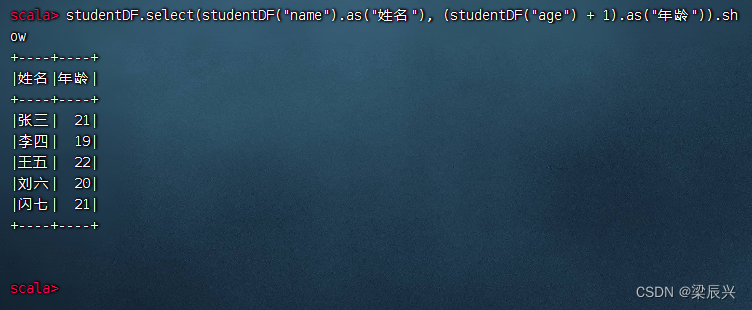
执行命令:studentDF.select(studentDF(“name”).as(“姓名”), (studentDF(“age”) + 1).as(“年龄”)).show (给字段取别名)
(4)对数据帧进行过滤操作
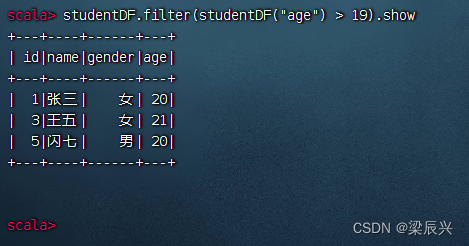
查询年龄在19岁以上的记录,执行命令:studentDF.filter(studentDF(“age”) > 19).show
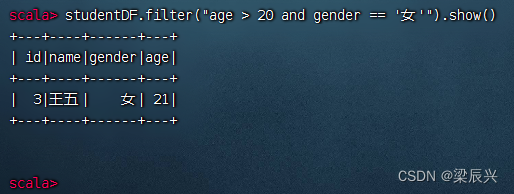
查询20岁以上的女生记录,执行命令:studentDF.filter(“age > 20 and gender == ‘女’”).show()
(5)对数据帧进行统计操作
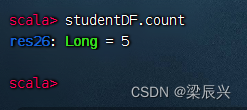
统计学生数据帧总记录数,执行命令:studentDF.count
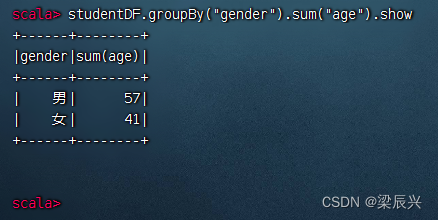
分组统计男女生总年龄,执行命令:studentDF.groupBy(“gender”).sum(“age”).show
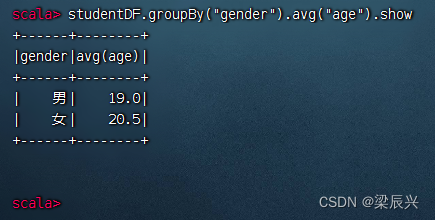
分组统计男女生平均年龄,执行命令:studentDF.groupBy(“gender”).avg(“age”).show
分组统计男女生最大年龄,执行命令:studentDF.groupBy(“gender”).max(“age”).show
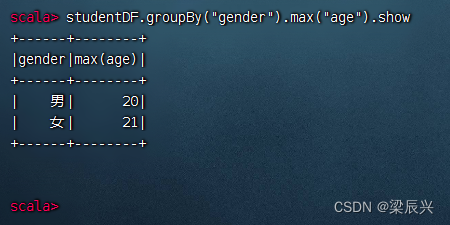
分组统计男女生最小年龄,执行命令:studentDF.groupBy(“gender”).min(“age”).show
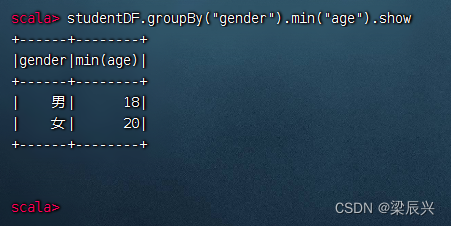
分组统计男女生人数,执行命令:studentDF.groupBy(“gender”).count.show
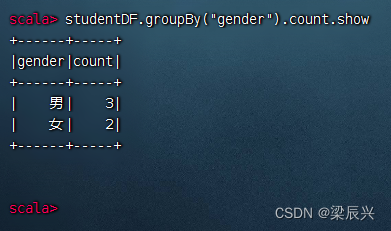
(6)对数据帧进行排序操作
对年龄升序排列,执行命令:studentDF.sort(“age”).show
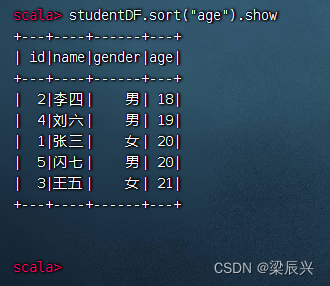 对年龄降序排列,执行命令:studentDF.sort(desc(“age”)).show
对年龄降序排列,执行命令:studentDF.sort(desc(“age”)).show

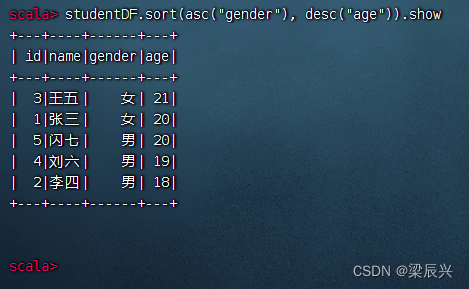
先按性别升序,再按年龄降序,- 执行命令:studentDF.sort(asc(“gender”), desc(“age”)).show
(7)重命名数据帧字段
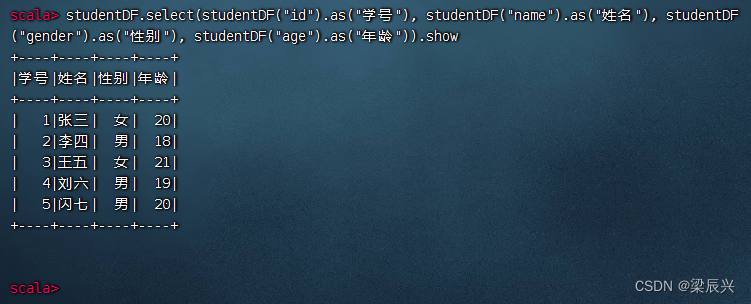
执行命令:studentDF.select(studentDF(“id”).as(“学号”), studentDF(“name”).as(“姓名”), studentDF(“gender”).as(“性别”), studentDF(“age”).as(“年龄”)).show
直接对数据帧进行操作,其实并不是很方便,因此,我们需要基于数据帧创建临时视图,然后对于临时视图就可以进行SQL操作,那样就会十分方便。
(六)基于数据帧进行SQL查询
1、基于数据帧创建临时视图
基于学生数据帧studentDF,创建一个临时视图student,就可以对student视图进行SQL操作
执行命令:studentDF.createTempView(“student”)
如果临时视图存在,使用这个命令就会报错,此时,执行命令:studentDF.createOrReplaceTempView(“student”),就不会报错
如果指定的视图不存在,那就创建,如果存在,那就替换。
2、使用spark对象执行SQL查询
在Spark Shell环境里,系统已经创建了名为spark的SparkSession对象
spark.sql()方法用于执行一个SQL查询,返回结果是一个数据帧
(1)查询全部表记录
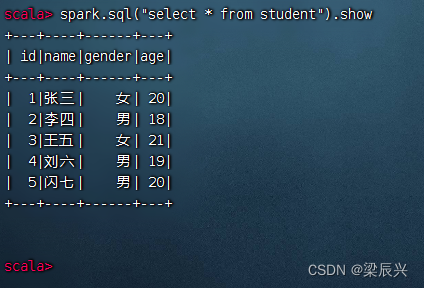
执行命令:spark.sql(“select * from student”).show
(2)显示数据表结构
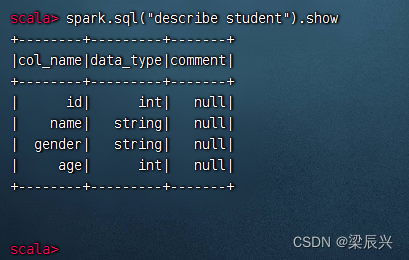
执行命令:spark.sql(“describe student”).show
(3)对表进行投影操作
执行命令:spark.sql(“select name, age + 1 from student”).show
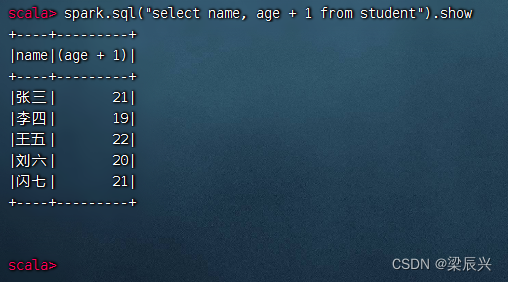
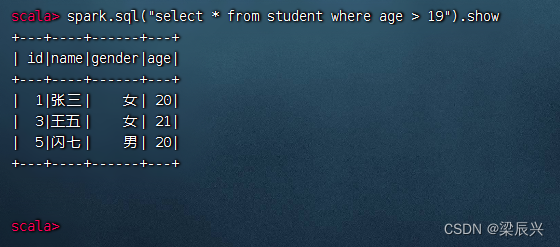
(4)对表进行选择操作
查询年龄在19岁以上的记录,执行命令:spark.sql(“select * from student where age > 19”).show
查询20岁以上的女生记录,执行命令:spark.sql(“select * from student where age > 20 and gender = ‘女’”).show
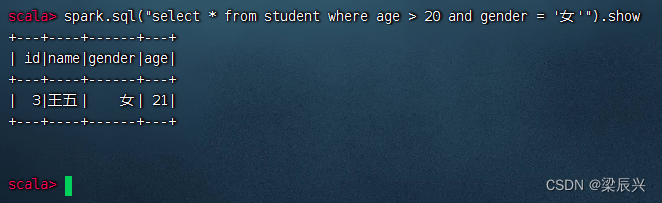
(5)对表进行统计操作
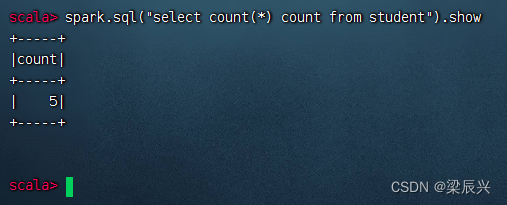
查询学生表总记录数,执行命令:spark.sql(“select count() count from student").show
 分组统计男女生总年龄,执行命令:spark.sql(“select gender, sum(age) from student group by gender”).show
分组统计男女生总年龄,执行命令:spark.sql(“select gender, sum(age) from student group by gender”).show
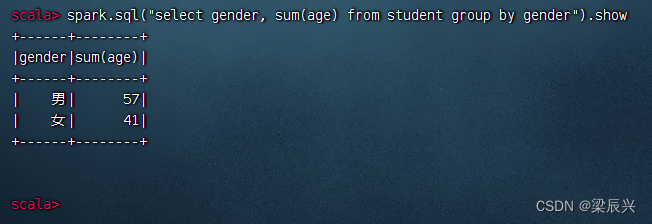
分组统计男女生平均年龄,执行命令:spark.sql(“select gender, avg(age) from student group by gender”).show

分组统计男女生最大年龄,执行命令:spark.sql(“select gender, max(age) from student group by gender”).show
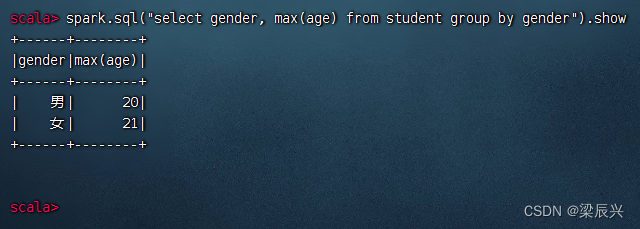
分组统计男女生最小年龄,执行命令:spark.sql(“select gender, min(age) from student group by gender”).show

分组统计男女生人数,执行命令:spark.sql("select gender, count() count from student group by gender”).show
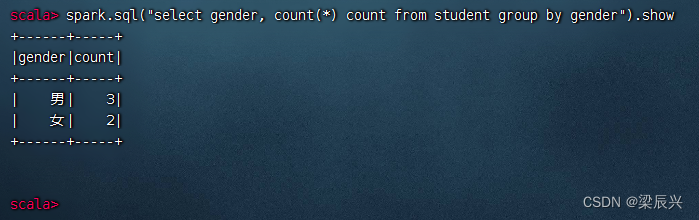
(6)对表进行排序操作
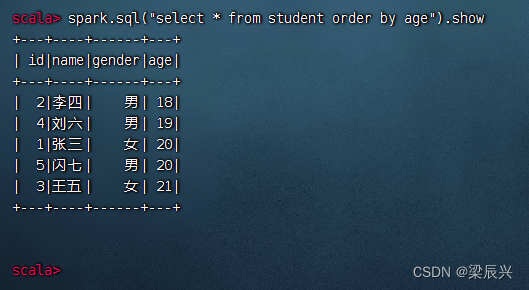
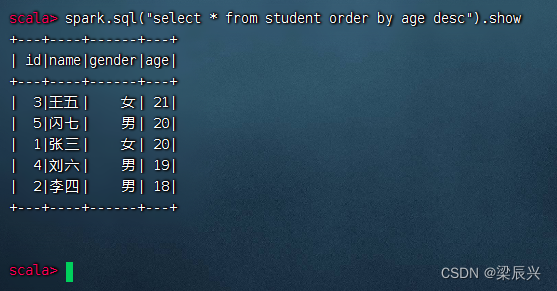
按年龄升序排列,执行命令:spark.sql(“select * from student order by age”).show
 按年龄降序排列,执行命令:spark.sql(“select * from student order by age desc”).show
按年龄降序排列,执行命令:spark.sql(“select * from student order by age desc”).show
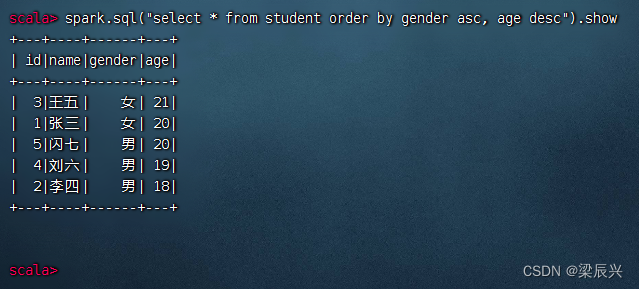
先按性别升序,再按年龄降序,执行命令:spark.sql(“select * from student order by gender asc, age desc”).show
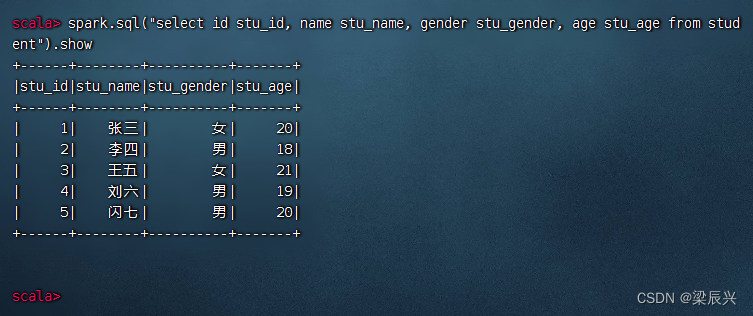
(7)重命名数据表字段
执行命令:spark.sql(“select id stu_id, name stu_name, gender stu_gender, age stu_age from student”).show
执行命令:spark.sql(“select id 学号, name 姓名, gender 性别, age 年龄 from student”).show(),无法解析中文别名

四、练习
成绩表,包含四个字段(姓名、语文、数学、英语),只有三条记录
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张钦林 | 78 | 90 | 76 |
| 陈燕文 | 95 | 88 | 98 |
| 卢志刚 | 78 | 80 | 60 |
在/home里创建scores.txt文件
将scores.txt文件上传到HDFS上指定目录
基于scores.txt文件,创建scoreDF数据帧
基于scoreDF数据帧进行下列操作
(1)显示数据帧内容
(2)显示数据帧模式信息
(3)对数据帧进行投影操作
(4)对数据帧进行过滤操作
(5)对数据帧进行统计操作
(6)对数据帧进行排序操作
(7)重命名数据帧字段
基于scoreDF数据帧创建临时表score
基于score数据表进行下列操作
(1)查询全部表记录
(2)显示数据表结构
(3)对表进行投影操作
(4)对表进行选择操作
(5)对表进行统计操作
(6)对表进行排序操作
(7)重命名数据表字段






![KYOCERA Programming Contest 2023(AtCoder Beginner Contest 305)(A、B、C、D)[施工中]](https://img-blog.csdnimg.cn/0c9e8452f4a04777a1ef883a1c09f0b8.png)