上一篇文章中引入了消息队列对秒杀流量做削峰的处理,我们使用的是Kafka,看起来似乎工作的不错,但其实还是有很多隐患存在,如果这些隐患不优化处理掉,那么秒杀抢购活动开始后可能会出现消息堆积、消费延迟、数据不一致、甚至服务崩溃等问题,那么后果可想而知。本篇文章我们就一起来把这些隐患解决掉。
一、批量数据聚合
在SeckillOrder这个方法中,每来一次秒杀抢购请求都往往Kafka中发送一条消息。假如这个时候有一千万的用户同时来抢购,就算我们做了各种限流策略,一瞬间还是可能会有上百万的消息会发到Kafka,会产生大量的网络IO和磁盘IO成本,大家都知道Kafka是基于日志的消息系统,写消息虽然大多情况下都是顺序IO,但当海量的消息同时写入的时候还是可能会扛不住。
那怎么解决这个问题呢?答案是做消息的聚合。之前发送一条消息就会产生一次网络IO和一次磁盘IO,我们做消息聚合后,比如聚合100条消息后再发送给Kafka,这个时候100条消息才会产生一次网络IO和磁盘IO,对整个Kafka的吞吐和性能是一个非常大的提升。其实这就是一种小包聚合的思想,或者叫Batch或者批量的思想。这种思想也随处可见,比如我们使用Mysql插入批量数据的时候,可以通过一条SQL语句执行而不是循环的一条一条插入,还有Redis的Pipeline操作等等。
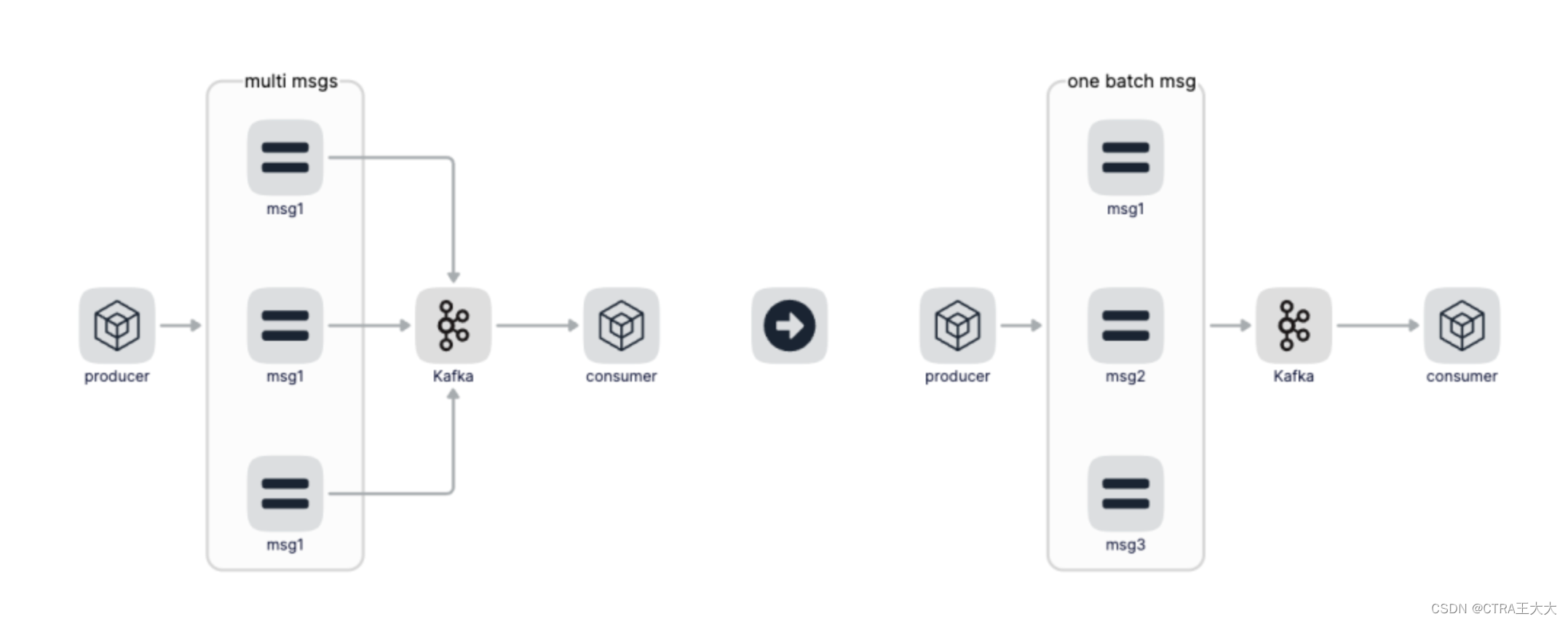
那怎么来聚合呢,聚合策略是啥呢?聚合策略有两个维度分别是聚合消息条数和聚合时间,比如聚合消息达到100条我们就往Kafka发送一次,这个条数是可以配置的,那如果一直也达


![KYOCERA Programming Contest 2023(AtCoder Beginner Contest 305)(A、B、C、D)[施工中]](https://img-blog.csdnimg.cn/0c9e8452f4a04777a1ef883a1c09f0b8.png)