下面是我写过的一个pytorch_lightning项目的代码框架。关键代码已经省略。
模型构建
import pytorch_lightning as pl
from pytorch_lightning.plugins.io import TorchCheckpointIO as tcio
import torch
from torch import nn
import torch.nn.functional as F
from torch.optim.lr_scheduler import ReduceLROnPlateau
from pathlib import Path
import random
class MyModel(pl.LightningModule):
# 参数省略了
def __init__(self, ... learning_rate=2e-5):
super(MyModel, self).__init__()
...
encoder_layer = nn.TransformerEncoderLayer()
self.encoder = nn.TransformerEncoder(encoder_layer, num_hidden_layers)
...
self.apply(self.init_weights)
def init_weights(self, layer):
if isinstance(layer, (nn.Linear, nn.Embedding)):
if isinstance(layer.weight, torch.Tensor):
layer.weight.data.normal_(mean=0.0, std=self.initializer_range)
elif isinstance(layer, nn.LayerNorm):
layer._epsilon = 1e-12 # 一个小的常数,用于避免除以零误差。默认值为 1e-5
# args是自定义的参数,这里略去
def forward(self, args):
# 层构建也略去
return F.relu(dense_outputs).squeeze(dim=1).exp()
def training_step(self, batch, batch_idx):
inputs, targets = batch
predicts = self(**inputs)
loss = F.l1_loss(predicts, targets, reduction="mean")
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
inputs, targets = batch
predicts = self(**inputs)
loss = F.l1_loss(predicts, targets, reduction="mean")
self.log("val_loss", loss)
for i in range(targets.size(0)):
predict = predicts[i].item()
target = targets[i].item()
print(f"{target} => {predict} ")
print(f"loss = {loss.item()}")
def test_step(self, batch, batch_idx):
inputs, targets = batch
predicts = self(**inputs)
loss = F.l1_loss(predicts, targets, reduction="mean")
for i in range(targets.size(0)):
predict = predicts[i].item()
target = targets[i].item()
print(f"{target} => {predict} ")
print(f"loss = {loss.item()}")
#只要在training_step返回了loss,就会自动反向传播,调用lr_scheduler
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.lr)
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": ReduceLROnPlateau(optimizer, mode="min", factor=0.1, patience=10,
eps=1e-9, verbose=True),
"interval": "epoch",
"monitor": "val_loss",
},
}
数据导入
from torch.utils.data import Dataset, DataLoader
def process_data(input_path: Path) -> List[List]:
class DnaDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
def collate_fn(batch):
xxxx, days = zip(*batch)
inputs = dict()
inputs['xxxx'] = torch.tensor(base_ids, dtype=torch.long)
...
# 构造一个字典
targets = torch.tensor(days).float()
return inputs, targets
-- use in main --
train_data = process_data(work_path / 'train_data.txt')
val_data = process_data(work_path / 'val_data.txt')
train_dataset = DnaDataset(train_data)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True,
collate_fn=collate_fn, drop_last=True, num_workers=64)
val_dataset = DnaDataset(val_data)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False,
collate_fn=collate_fn,drop_last=True, num_workers=64)
训练
import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.callbacks import EarlyStopping
from pytorch_lightning.callbacks import LearningRateMonitor
checkpoint_callback = ModelCheckpoint(
filename="{epoch:04d}-{val_loss:.6f}",
monitor="val_loss", # 监控的变量
verbose=True, # 冗余模式
save_last=True, # 覆盖保存
save_top_k=10, # 保存k个最好的模型
mode="min", # val_loss越小越好
)
# 监控validation_step中的变量,如果不能更优则提前停止训练
early_stop_callback = EarlyStopping(
patience=10, # 持续几个epoch没有提升,则停止训练
min_delta=0.01, # 0.01 最小的该变量,即当监控的量的绝对值变量小于该值,则认为没有新提升
monitor='val_loss',
mode='min',
verbose=True)
lr_monitor = LearningRateMonitor(logging_interval='step')
lr = 2e-04
model = MyModel(hidden_size=HIDDEN_SIZE, learning_rate=lr)
ckpt_file = "weights_last.ckpt"
ckpt_path = work_path / ckpt_file
trainer = pl.Trainer(gpus=2, accelerator='dp',
# resume_from_checkpoint=str(ckpt_path),
gradient_clip_val=2.0,
accumulate_grad_batches=64,
sync_batchnorm=True,
#min_epochs=40,
#max_epochs=2000,
callbacks=[checkpoint_callback, early_stop_callback, lr_monitor])
trainer.fit(model, train_loader, val_loader)
其中,在训练阶段,test_step是不会被调用的。只有训练得差不多了,我们才手动调用。
测试
import pytorch_lightning as pl
from pytorch_lightning.plugins.io import TorchCheckpointIO as tcio
import torch.multiprocessing
from torch.utils.data import Dataset, DataLoader
from pathlib import Path
import random
from model_training import MyModel, DnaDataset, collate_fn, process_data
model = MyModel(hidden_size=HIDDEN_SIZE, learning_rate=lr)
ckpt_path = "xxxx.ckpt"
trainer = pl.Trainer(resume_from_checkpoint=ckpt_path)
# tc = tcio()
# ckpt_dict = tc.load_checkpoint(path=ckpt_path)
# ckpt_dict是一个字典,里面有各种权重数据。如果想看可以看。
test_data = process_data(work_path / 'test_data.txt')
test_dataset = DnaDataset(test_data)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True,
collate_fn=collate_fn, drop_last=True, num_workers=64)
trainer.test(model, dataloaders=test_dataloader)
转化为onnx格式
这里的代码我跑通了,但是打出来的模型跑测试贼慢。我怀疑是模型太复杂了🚬还没想好解决办法,之后解决了再更新。
model = MyModel(hidden_size=HIDDEN_SIZE, learning_rate=lr)
ckpt_path = "last.ckpt"
trainer = pl.Trainer(resume_from_checkpoint=ckpt_path)
tc = tcio()
ckpt_dict = tc.load_checkpoint(path=ckpt_path)
model.load_state_dict(ckpt_dict["state_dict"])
model.eval()
val_data = process_data(work_path / 'val_data.txt')
val_dataset = DnaDataset(val_data)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False,
collate_fn=collate_fn,
drop_last=True, num_workers=64)
# 随便生成1个数据就好。torch.onnx.export实际进行了一次推理
for d in val_loader:
a, b = d
break
import torch.onnx
torch.onnx.export(model, (a["x1"], a["x2"], a["x3"]),
"last.onnx", # 打包后的文件名
# 如果有多个输入,可以通过input_names指明输入变量的名称
input_names=["x1", "x2", "x3"],
)
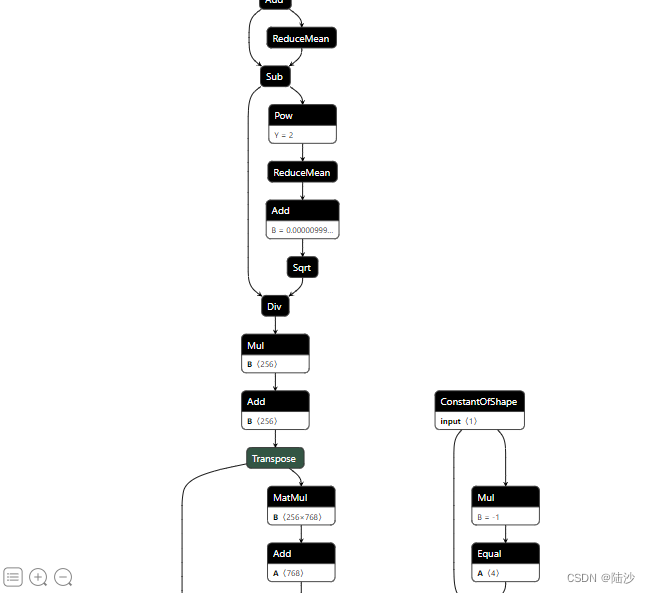
查看模型结构
使用 https://netron.app/,我下载了win10版,打开一个onnx格式的文件,可以看到这样的:


![KYOCERA Programming Contest 2023(AtCoder Beginner Contest 305)(A、B、C、D)[施工中]](https://img-blog.csdnimg.cn/0c9e8452f4a04777a1ef883a1c09f0b8.png)